
天秀!小伙用Python表演马老师闪电五连鞭!

11月份的头条,是属于马保国的。
一位69岁的老同志,惨遭年轻人偷袭,不讲武德。

看看把老同志欺负的...
要不是马老师讲仁义讲道德,甩手就是一个五连鞭。

哈哈哈,所以本期我们就用Python给马保国老师做一个闪电五连鞭动态词云图。
词云数据来自B站,使用stylecloud词云库绘制。
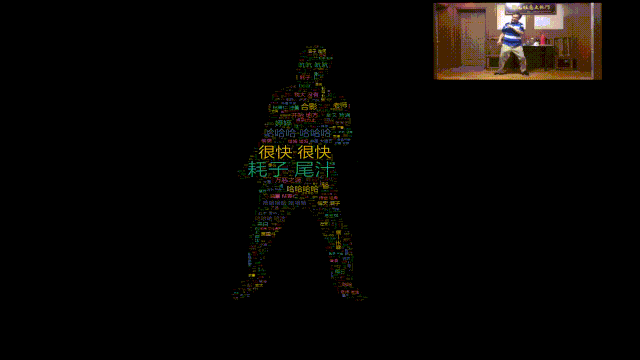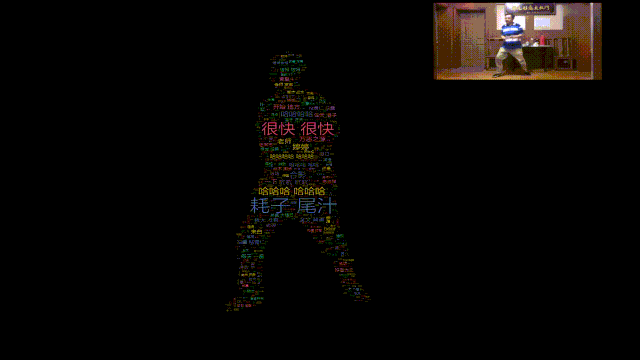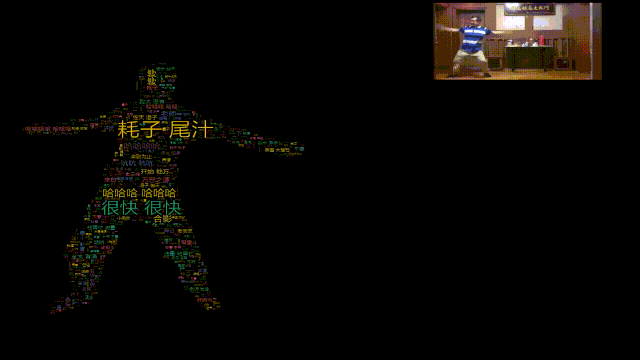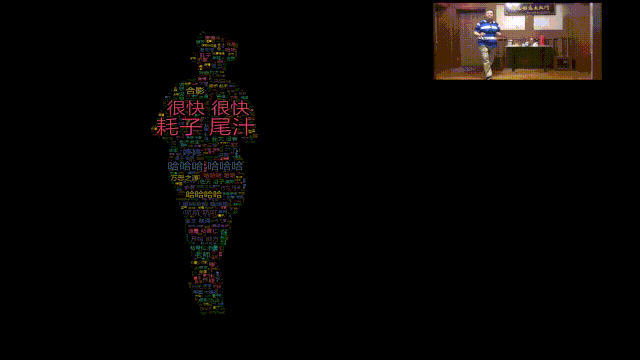
主要参考百度AI Studio上的一个开源项目,使用PaddleSeg对人像进行分割。
年轻小F,不讲武德。这样好吗,耗子尾汁。
/ 01 / 弹幕数据获取
没从B站上直接爬取,使用第三方库bilibili_api。
这是一个用Python写的调用Bilibili各种API的库,范围涵盖视频、音频、直播、动态、专栏、用户、番剧等。
地址:https://passkou.com/bilibili_api/docs/
使用video模块下面的两个方法,可以获取11月每天的视频弹幕。
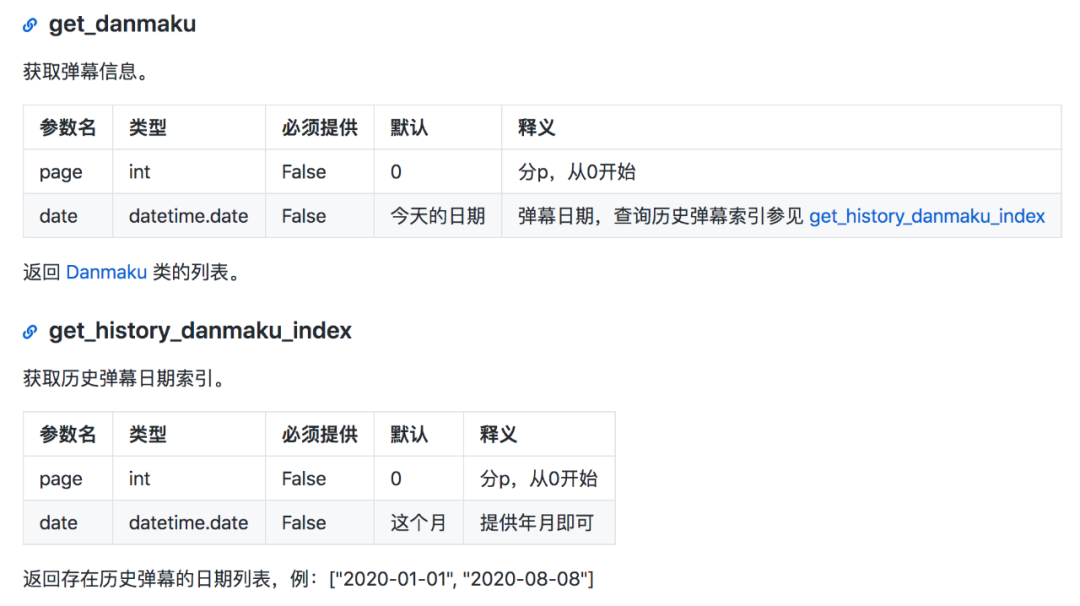
首先需要获取SESSDATA和CSRF(bili_jct)的值。
谷歌浏览器可以通过下图查看,域名选择bilibili.com。
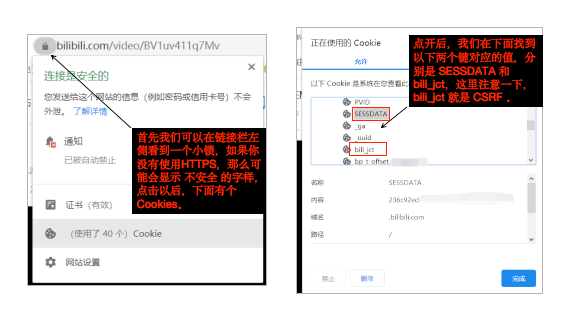
以点击量为排序,选取排行第一的视频获取弹幕。没想到马老师老早就火了,耗子尾汁。
点击排名第一的视频,然后在浏览器的访问栏获取BV号,BV1HJ411L7DP。
获取弹幕代码如下。
from bilibili_api import video, Verify
import datetime
# 参数
verify = Verify("你的SESSDATA值", "你的bili_jct值")
# 获取存在历史弹幕的日期列表
days = video.get_history_danmaku_index(bvid="BV1HJ411L7DP", verify=verify)
print(days)
# 获取弹幕信息,并保存
for day in days:
danmus = video.get_danmaku(bvid="BV1HJ411L7DP", verify=verify, date=datetime.date(*map(int, day.split('-'))))
print(danmus)
f = open(r'danmu.txt', 'a')
for danmu in danmus:
print(danmu)
f.write(danmu.text + '\n')
f.close()
得到结果。
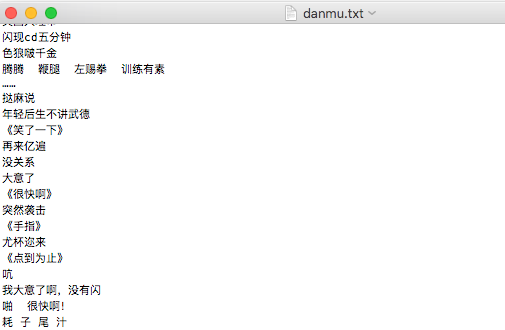
我大E了啊,没有闪。
使用jieba对弹幕数据进行分词处理。
import jieba
def get_text_content(text_file_path):
'''
获取填充文本内容
'''
text_content = ''
with open(text_file_path, encoding='utf-8') as file:
text_content = file.read()
# 数据清洗,只保存字符串中的中文,字母,数字
text_content_find = re.findall('[\u4e00-\u9fa5a-zA-Z0-9]+', text_content, re.S)
text_content = ' '.join(jieba.cut(str(text_content_find).replace(" ", ""), cut_all=False))
print(text_content)
return text_content
text_content = get_text_content('danmu.txt')
选取马保国原版素材视频,B站上有高清的。
地址:https://www.bilibili.com/video/BV1JV41117hq
参考网上的资料,运行如下代码即可下载B站视频。
from bilibili_api import video, Verify
import requests
import urllib3
# 参数
verify = Verify("你的SESSDATA值", "你的bili_jct值")
# 获取下载地址
download_url = video.get_download_url(bvid="BV1JV41117hq", verify=verify)
print(download_url["dash"]["video"][0]['baseUrl'])
baseurl = 'https://www.bilibili.com/video/BV1JV41117hq'
title = '马保国'
def get_video():
urllib3.disable_warnings()
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8'
}
headers.update({'Referer': baseurl})
res = requests.Session()
begin = 0
end = 1024 * 1024 - 1
flag = 0
temp = download_url
filename = "./" + title + ".flv"
url = temp["dash"]["video"][0]['baseUrl']
while True:
headers.update({'Range': 'bytes=' + str(begin) + '-' + str(end)})
res = requests.get(url=url, headers=headers, verify=False)
if res.status_code != 416:
begin = end + 1
end = end + 1024 * 1024
else:
headers.update({'Range': str(end + 1) + '-'})
res = requests.get(url=url, headers=headers, verify=False)
flag = 1
with open(filename, 'ab') as fp:
fp.write(res.content)
fp.flush()
if flag == 1:
fp.close()
break
print('--------------------------------------------')
print('视频下载完成')
filename = "./" + title + ".mp3"
url = temp["dash"]["audio"][0]['baseUrl']
while True:
headers.update({'Range': 'bytes=' + str(begin) + '-' + str(end)})
res = requests.get(url=url, headers=headers, verify=False)
if res.status_code != 416:
begin = end + 1
end = end + 1024 * 1024
else:
headers.update({'Range': str(end + 1) + '-'})
res = requests.get(url=url, headers=headers, verify=False)
flag = 1
with open(filename, 'ab') as fp:
fp.write(res.content)
fp.flush()
if flag == 1:
fp.close()
break
print('音频下载完成')
记得添加SESSDATA和CSRF(bili_jct)的值
/ 02 / PaddleSeg人像分割
基于百度AI Studio的项目,项目地址:
https://aistudio.baidu.com/aistudio/projectdetail/1176398
首先下载解压安装PaddleSeg相关依赖包。
# 下载PaddleSeg
git clone https://hub.fastgit.org/PaddlePaddle/PaddleSeg.git
cd PaddleSeg/
# 安装所需依赖项
pip install -r requirements.txt
通常去「GitHub」上下载东西,速度都比较慢,可以使用加速链接。
这里的fastgit.org一加,下载速度就能从几十K飙升到几兆每秒。
# 新建文件夹
mkdir work/videos
mkdir work/texts
mkdir work/mp4_img
mkdir work/mp4_img_mask
mkdir work/mp4_img_analysis
新建一些文件夹,主要用来存放相关文件的。
这里可以将之前爬取到的视频和音频放置在videos中。
先对素材视频进行抽帧,就是获取视频每帧的图片。
def transform_video_to_image(video_file_path, img_path):
'''
将视频中每一帧保存成图片
'''
video_capture = cv2.VideoCapture(video_file_path)
fps = video_capture.get(cv2.CAP_PROP_FPS)
count = 0
while (True):
ret, frame = video_capture.read()
if ret:
cv2.imwrite(img_path + '%d.jpg' % count, frame)
count += 1
else:
break
video_capture.release()
filename_list = os.listdir(img_path)
with open(os.path.join(img_path, 'img_list.txt'), 'w', encoding='utf-8') as file:
file.writelines('\n'.join(filename_list))
print('视频图片保存成功, 共有 %d 张' % count)
return fps
input_video = 'work/videos/Master_Ma.mp4'
fps = transform_video_to_image(input_video, 'work/mp4_img/')
一共是获取到了564张图片。
然后使用PaddleSeg将所有的视频图片,进行人像分割,生成mask图片。
# 生成mask结果图片
python 你的路径/PaddleSeg/pdseg/vis.py \
--cfg 你的路径/work/humanseg.yaml \
--vis_dir 你的路径/work/mp4_img_mask
使用模型进行预测,其中humanseg.yaml文件是作者提供的,可以进行图像分割。
预训练模型deeplabv3p_xception65_humanseg,需下载解压安装放在PaddleSeg/pretrained_model下。
由于预训练模型较大,就不放网盘上了,直接访问下面这个链接即可下载。
# 下载预训练模型deeplabv3p_xception65_humanseg
https://paddleseg.bj.bcebos.com/models/deeplabv3p_xception65_humanseg.tgz
记得需要将humanseg.yaml文件中的路径信息,修改成你自己的路径。
运行上面那三行命令,最后就会生成564张mask文件。
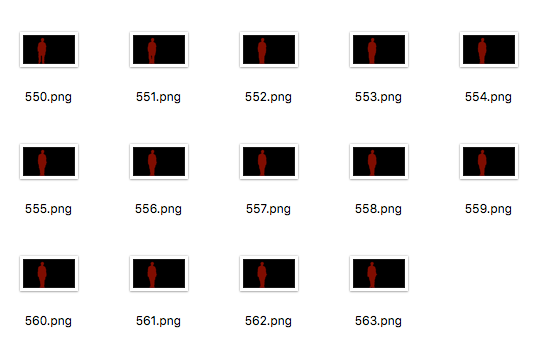
/ 03 / 词云生成
使用stylecloud词云库生成词云,使用字体方正兰亭刊黑。
def create_wordcloud():
for i in range(564):
file_name = os.path.join("mp4_img_mask/", str(i) + '.png')
# print(file_name)
result = os.path.join("work/mp4_img_analysis/", 'result' + str(i) + '.png')
# print(result)
stylecloud.gen_stylecloud(text=text_content,
font_path='方正兰亭刊黑.TTF',
output_name=result,
background_color="black",
mask_img=file_name)
因为stylecloud库无法自定义词云图片,所以小F修改了它的代码。
给gen_stylecloud添加了mask_img这个参数,最终作用在gen_mask_array这个函数上。
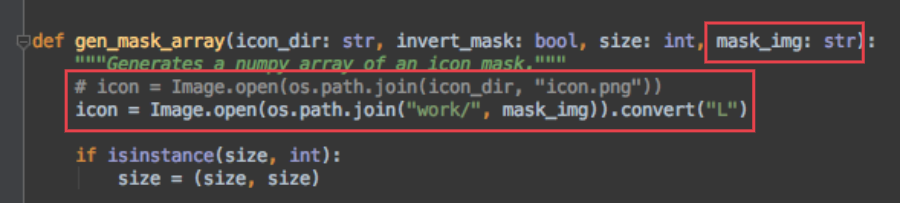
如此就能将mask图片转化成词云图!
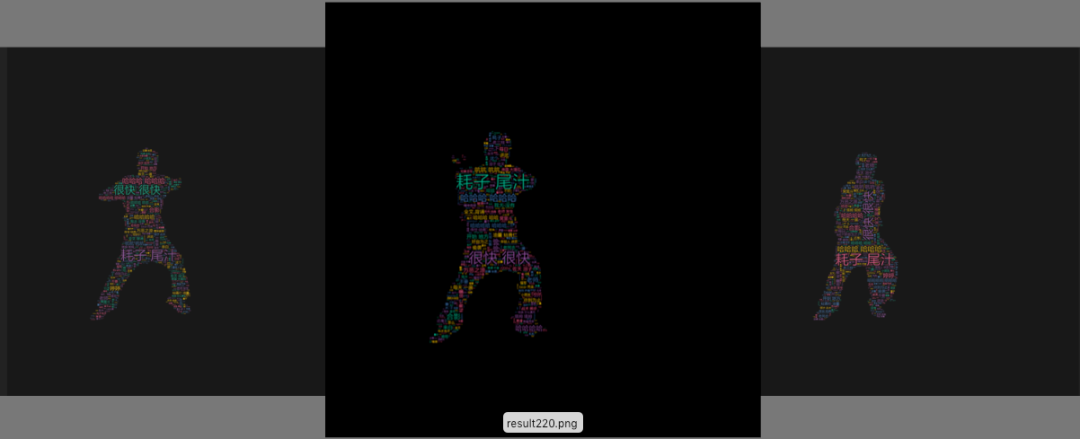
将这些词云图片合并成视频。
def combine_image_to_video(comb_path, output_file_path, fps=30, is_print=False):
'''
合并图像到视频
'''
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
file_items = [item for item in os.listdir(comb_path) if item.endswith('.png')]
file_len = len(file_items)
# print(comb_path, file_items)
if file_len > 0:
print(file_len)
temp_img = cv2.imread(os.path.join(comb_path, file_items[0]))
img_height, img_width, _ = temp_img.shape
out = cv2.VideoWriter(output_file_path, fourcc, fps, (img_width, img_height))
for i in range(file_len):
pic_name = os.path.join(comb_path, 'result' + str(i) + ".png")
print(pic_name)
if is_print:
print(i + 1, '/', file_len, ' ', pic_name)
img = cv2.imread(pic_name)
out.write(img)
out.release()
combine_image_to_video('work/mp4_img_analysis/', 'work/mp4_analysis.mp4', 30)
使用ffmpeg对视频进一步的处理,裁剪+重叠。
# 视频裁剪
ffmpeg -i mp4_analysis_result.mp4 -vf crop=iw:ih/2:0:ih/5 output.mp4
# 视频重叠
ffmpeg -i output.mp4 -i viedeos/Master_Ma.mp4 -filter_complex "[1:v]scale=500:270[v1];[0:v][v1]overlay=1490:10" -s 1920x1080 -c:v libx264 merge.mp4
# 添加音频
ffmpeg -i merge.mp4 -i videos/Master_Ma.mp4 -c:v copy -c:a copy work/mp4_analysis_result2.mp4 -y
# 生成gif图
ffmpeg -ss 00:00:22 -t 3 -i merge.mp4 -r 15 a.gif
ffmpeg的安装及使用就得靠大伙自己百度啦~
视频结果如下。
到这里了,不给小F来个赞吗,来,炫,来偷吸,我这...
好了,到此本期的实践就结束了。
相关代码及文件已上传:https://pan.baidu.com/s/1mGUK7-ecFqKN4BmY1ccONw 密码:y6f8
感兴趣的小伙伴也可以动手试一试。
这里需要注意,在使用PaddleSeg进行人像分割和生成词云图,这期间耗费的时间比较多,慢慢等就好了。
还有就是可以自己修改一下stylecloud库的代码,自定义一下mask_img图片的大小以及颜色。
这两项小F是没有修改的,所以生成的图片是512×512尺寸,导致最后视频需要裁剪。
颜色主要是将mask图片变成白底的图片,小F这里是黑底的。
可以通过图片灰度二值化的方法。
import cv2
# 灰度图
img = cv2.imread('work/mp4_img_mask/240.png', 0)
# 二值化
ret, thresh = cv2.threshold(img, 30, 255, cv2.THRESH_BINARY_INV)
# 显示
cv2.imshow("img", thresh)
# 保存图片
cv2.imwrite('0.png', thresh)
cv2.waitKey(0)
cv2.destroyAllWindows()
就能得到白底的png图,符合stylecloud词云图的要求。

如此便可以绘制出白底彩色文字的词云图。