
令人“细思极恐”的Faster-R-CNN

极市导读
每次回顾Faster R-CNN,都会发现一些没有注意到的细节。本文从编码实现的角度来解析 Faster R-CNN,先对网络的前向(forward)过程进行阐述,了解清楚Faster R-CNN是如何进行预测。然后详细阐述了Faster R-CNN的训练过程,主要解析了RPN和RoIHead的训练过程。>>加入极市CV技术交流群,走在计算机视觉的最前沿
前言
每次回顾Faster R-CNN的相关知识(包括源码),都会发现之前没有注意到的一些细节,从而有新的收获,既惊恐又惊喜,可谓“细思极恐”!
Faster R-CNN可以算是深度学习目标检测领域的祖师爷了,至今许多算法都是在其基础上进行延伸和改进的,它的出现,可谓是开启了目标检测的新篇章,其最为突出的贡献之一是提出了 "anchor" 这个东东,并且使用 CNN 来生成region proposal(目标候选区域),从而真正意义上完全使用CNN 来实现目标检测任务(以往的架构会使用一些传统视觉算法如Selective Search来生成目标候选框,而 CNN仅用来提取特征或最后进行分类和回归)。
Faster R-CNN 由 R-CNN 和 Fast R-CNN发展而来,R-CNN是第一次将CNN应用于目标检测任务的家伙,它使用selective search算法获取目标候选区域(region proposal),然后将每个候选区域缩放到同样尺寸,接着将它们都输入CNN提取特征后再用SVM进行分类,最后再对分类结果进行回归,整个训练过程十分繁琐,需要微调CNN+训练SVM+边框回归,无法实现端到端。
Fast R-CNN则受到 SPP-Net 的启发,将全图(而非各个候选区域)输入CNN进行特征提取得到 feature map,然后用RoI Pooling将不同尺寸的候选区域(依然由selective search算法得到)映射到统一尺寸。另外,它用Softmax替代SVM用于分类任务,除最后一层全连接层外,分类和回归任务共享了网络权重。
而Faster R-CNN相对于其前辈Fast R-CNN的最大改进就是使用RPN来生成候选区域,摒弃了selective search算法,即完全使用CNN解决目标检测任务,同时整个过程都能跑在GPU上,之前selective search仅在CPU上跑,是耗时的一大瓶颈。
本文从编码实现的角度来解析 Faster R-CNN,先对网络的前向(forward)过程进行阐述,再回过头来看训练的细节,这样便于更好地理解。
源码是一位大佬写的,基于Pytorch框架,是Faster R-CNN的精炼版,作为学习和参考来说相当不错,我自己也撸了一遍,这里也附上大佬源码的链接:Faster R-CNN 精炼版。
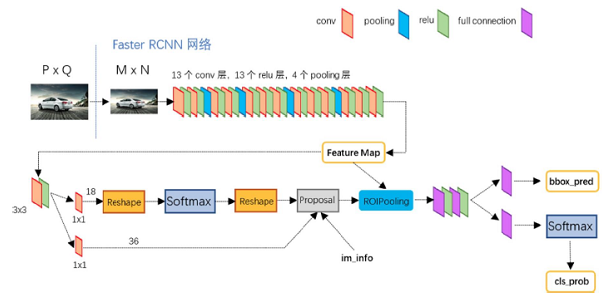
一. Overview
除去复杂的理论知识不谈,从编程的角度来看,Faster R-CNN做的事情其实就是,“穷举”一张图片可能出现物体的位置,生成矩形框(计算位置和大小),计算这些框中出现物体的概率,选择概率高的,然后调整这些矩形框的位置与大小,并去除重叠度高的,最终得到一个个包含物体的矩形框。
如下为整体框架结构,结合上述过程来看,主要是三部分,Extrator进行特征提取、RPN 生成候选框、RoIHead对候选框进行分类并调整目标预测框的位置与大小。
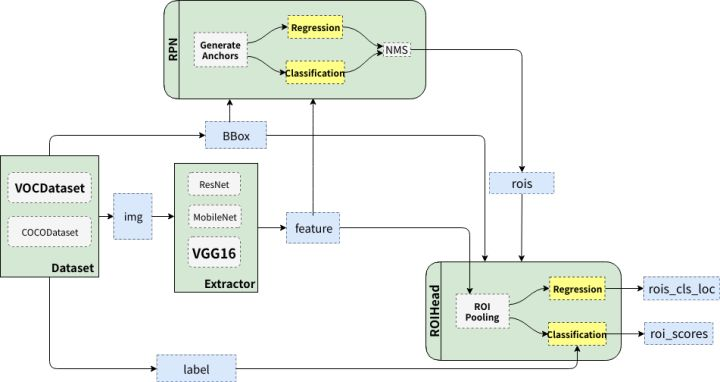
二. 特征提取
最初的Faster R-CNN使用了预训练的VGG16作为backbone进行特征提取,实现方法是加载预训练模型,抽取并分离前面的卷积层和后面的全连接层,固定卷积层中部分层的权重,用作特征提取,而全连接层则给 RoIHead 用作分类和回归。

Feature Extractor 实现!
三. RPN(Region Proposal Network)
RPN 能够获得包含物体的区域,网络的后续部分便可基于这些区域做进一步的检测。
1. 使用anchor“穷举”目标物体所在区域
这里先介绍下anchor,这东东有点抽象,中文翻译是“锚”,让人容易觉得这是一个点,实际它是可能包含目标物体的矩形框。在目标检测任务中,通常会为每个像素点预设一个或多个面积大小和宽高比例不同的anchor,以此使得图像上密集铺满了许许多多anchor,从而覆盖到包含物体的所有位置区域。
backbone提取的特征图(记作 fm)相对于网络的输入图像尺寸缩小了16倍。因此,fm 中的1个像素点就相当于输入图像的16个像素点,或者说,fm中的1x1区域覆盖了输入图像的16x16区域。这样,fm中的每个像素点都对应地覆盖了输入图像的区域。
不难想象,如果一个像素点仅对应一个anchor,难免会覆盖不到或者覆盖不全目标物体。因此,Faster R-CNN 对每个点对应的anchor进行了尺寸缩放和形变,前者对应矩形面积,后者对应矩形长宽比例,每种尺寸对应3种长宽比,共设置3种尺寸,3种尺寸分别是128x128、256x256、512x512,3种长宽比分别是 1:1、1:2、2:1,这样一来,一个点就对应9个anchor,其中每个 anchor 的形状和大小都不完全相同。
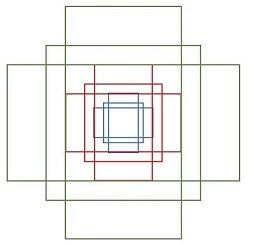
具体的实现方法是,先计算fm中的一个点(通常是左上角)对应的9个anchor的中心点坐标和长宽,其它点对应的anchor则通过平移计算得出。
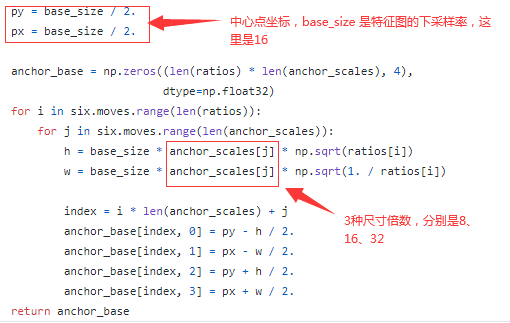
特征图左上角的像素点对应的9个anchor位置
不知道诸位客观发现了没,在上图计算anchor_base坐标时,有可能出现负数!比如对于特征图左上角的那个点(0,0),其作为anchor中心点,由于下采样了16倍,那么就对应于输入图像16x16的区域,于是映射到输入图像上anchor中心点就是(8,8)。
考虑anchor尺寸倍数为8且长宽比为1:1的情况,此时anchor面积为(16x8) x (16x8)=128x128,长宽各为128,但中心点却是(8,8),按此计算,左上角点坐标就是 (8 - 128/2, 8-128/2) = (-56, -56)。莫方,在以下第3小节讲解生成RoI的部分会涉及这部分的处理。

2. 在每个特征点上计算分类与回归结果
这里的分类是二分类,仅仅区分前景和背景,具体做法是,先将 fm 进行3x3卷积,进一步提取特征,然后使用1x1卷积将通道数映射到18=9x2,对应9个anchor的两个类别,然后再将通道这个维度分割多一个维度,使得最后一维是2,代表前景和背景,最后使用softmax计算概率。
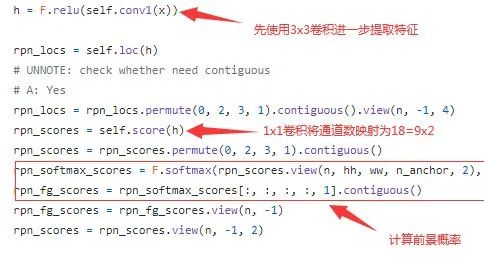
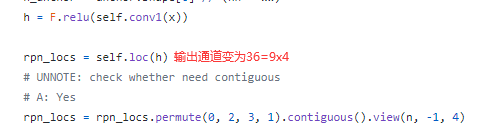
回归的做法是使用1x1卷积将通道数映射到36=9x4,对应9个anchor的位置与大小。注意,这里回归的4个量分别是矩形框中心点与anchor中心点横、纵坐标的位移 以及 矩形框长宽与 anchor 长宽的比例。
3.对分类与回归结果进行后处理,生成 RoI(Region of Interest)
这部分是One-Stage的最后阶段,也称作 Proposal Creator(Proposal Layer),会对RPN输出的分类和回归结果进行后处理(如NMS等),得到网络认为包含物体的区域,称为感兴趣的候选区域——RoI。
至此,其实已经完成了检测任务,因为已经得到了包含物体的区域(bbox),只不过没有对物体类别进行细分,仅区分了前、背景。另外,由于anchor的位置和大小是人工预设的,且用于训练的样本有限,因此此处得到的检测结果可能并不够精准。
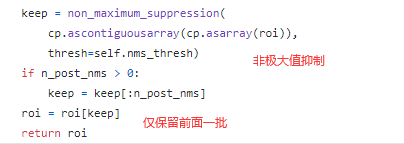
具体做法是,先将回归得到的候选区域的宽、高限制在输入图像尺寸范围内以及剔除尺寸过小(小于16x16,因为特征图中一个像素点就已经代表了输入图像16x16的区域。
下图中的scale是输入网络中的图像与原图之间的缩放系数)的,然后将它们按前景概率排序,保留前面的一批(训练时是12000,预测时是6000),接着使用非极大值抑制进一步剔除掉可能重复的,最后从剔除后的结果中保留剩下的一批(训练时是2000,预测时是300)。

四. RolHead
RPN 生成的 RoI 仅仅区分了前景和背景,并没有区分出物体的具体类别。因此,RoIHead 就是对 RoI 进一步分类,并且调整矩形框的位置和大小,使得预测结果更精细。
1. RoI Pooling
顾名思义,就是对 RoI 进行池化操作,具体做法是将每个RoI缩放到特征图尺寸范围内对应的区域,然后将RoI平均划分为同样数量的子区域(bin),对每个bin实施(最大/平均)池化操作,这样就使得每个bin都映射为一个像素值,由于不同尺寸的RoI都划分了同样数量的bin,因此最终使得所有RoI都变为同样大小,这里是7x7(也就是对每个RoI都划分了7x7个bin)。
RPN 生成的 RoI 尺寸是对应于输入图像的,为了后面接全连接层生成预测结果,因此需要使用RoI Pooling将不同尺寸的各个RoI都映射至相同大小。
这里提出 RoI Pooling 会产生的问题:
1.1 两次量化损失
在将RoI映射至特征图尺寸范围的过程中,下采样取整操作(比如200x200的区域经16倍下采样后映射为12 x 12)会产生一次量化损失;接着,假设最终需要生成的尺寸大小为nxn,则需将RoI划分nxn个bin,在这个划分过程中又会产生一次量化损失(比如对12x12大小的RoI划分成7x7个bin,每个bin的平均尺寸是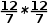 ,那么就会造成有些bin的大小是
,那么就会造成有些bin的大小是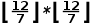 ,而另一些bin的大小则是
,而另一些bin的大小则是 ),于是后来就有人提出如RoI Align和Precise RoI Pooling等方法进行改进,这里就不展开叙述了。
),于是后来就有人提出如RoI Align和Precise RoI Pooling等方法进行改进,这里就不展开叙述了。
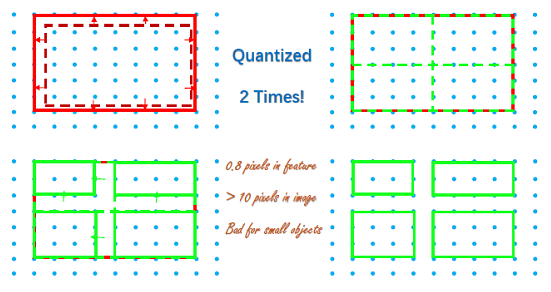
1.2 只有少数点的loss在反向传播中贡献了梯度
由于每个bin都由其中像素值最大的一点代表,因此在这部分的反向传播中,每个bin只有一个点的loss贡献了梯度,忽略了大部分点。

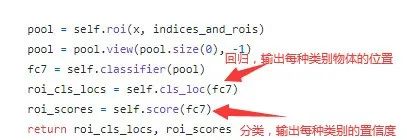
2. RoI 分类与回归
将RoI Pooling后的结果展开(flatten)成 vector,输入全连接层进行分类和回归,对应输出的神经元个数分别为物体类别数(记为n_classes)以及每个类别物体对应的bbox(n_classes x 4)。
注意,这里回归的结果是预测框中心点相对于正样本RoIs(在后文训练部分会讲解如何筛选正样本)中心点坐标的位移以及两者长宽的比例,并且是归一化(减去均值除以标准差)后的结果。
五. 后处理生成预测结果
RoIHead的输出还不是预测结果的最终形态,为了产生最终的预测结果,还需要做一些后处理。
具体做法是,将网络输出缩放至原图尺寸,注意是原图,不是输入网络的图像,在原图与输入图像之间是有缩放操作的。
接着对回归的结果去归一化(乘标准差加均值),结合RoIs的位置和大小计算出bbox的位置(左上角坐标和右下角坐标),并且裁剪到原图尺寸范围内。
然后,选择置信度大于阀值的矩形框,最后再使用非极大值抑制(NMS)剔除重叠度高的bbox得到最终的结果。

注意,这里在进行置信度筛选以及NMS时是分别对每个物体单独类别实施的,不包括背景类(下图range()从1开始)。
那么就可能会发生这样的情况:一个RoI对应不同类别的预测结果都被保留下来(要知道RoIHead的输出是每个RoI在不同类别上的分类和回归结果),这里可以说是Faster R-CNN优于YOLOv1的地方,因为YOLOv1的一个格子仅能预测一个物体,但同时Faster R-CNN单独在各个类别进行NMS势必会影响推断速度,所以说从这方面看这里也是弱于YOLOv1的地方。
速度与质量,鱼与熊掌皆不可得~

六. 训练
通过以上部分,相信朋友们已经清楚了Faster R-CNN是如何进行预测的了,但是,我们还没有开始将它是如何训练的,只有进行了有效的训练,模型才能产生可靠的预测结果,重头戏来咯!
训练的部分主要包含三个:Backbone、RPN 以及 RoIHead。Backbone 通常会采用在ImageNet上预训练的权重然后进行微调,因此这里主要解析RPN和RoIHead的训练过程,最初的实现将这两部分开训练,后来的大多数实现已使用联合训练的方式。
1. 筛选anchor样本,指导RPN训练
由于anchor数量太多,因此需要筛选部分anchor样本用于指导RPN训练。anchor总样本是Backbone输出特征图上每点对应的9个anchor,从中进行筛选目标样本,具体做法是:
1). 将坐标值不在输入图像尺寸范围内的anchor的标签记为-1;
2). 将与ground truth(gt)的IoU小于0.3的anchor作为负样本,标签记为0;
3). 将与每个gt的IoU最大的anchor作为正样本,标签记为1;
4). 将与gt的IoU不小于0.7的anchor作为正样本,标签记为1;
5). 限制正样本与负样本总数为256个,正负样本比为1:1,若其中某一类样本超过128个,则随机从中选择多出的样本将其标签记为-1;
6). 仅将标签为0和1的样本用于训练,忽略标签为-1的anchor

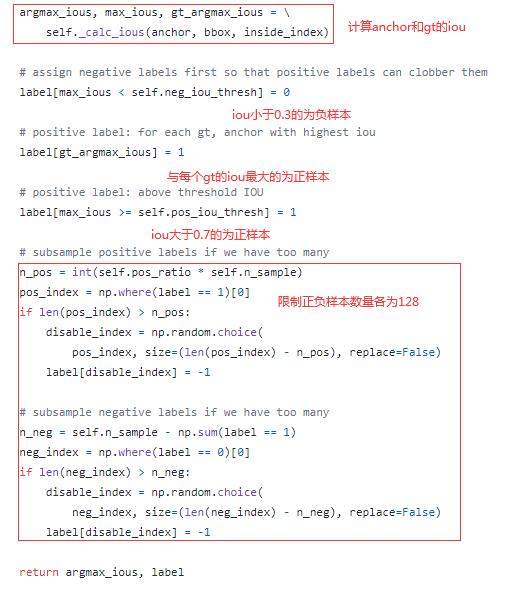
正样本和负样本用作计算分类损失,而回归的损失仅对正样本计算。注意,这里回归的目标是gt相对于正样本anchor中心点坐标的位移以及两者长宽的比例,正因如此,前面部分谈到过RPN回归的结果是候选区域相对于anchor中心点坐标的位移以及两者长宽的比例。
这种方式是将预测结果和gt都与anchor做比较,训练目标是让预测结果与anchor的差别和gt与anchor的差别一致。
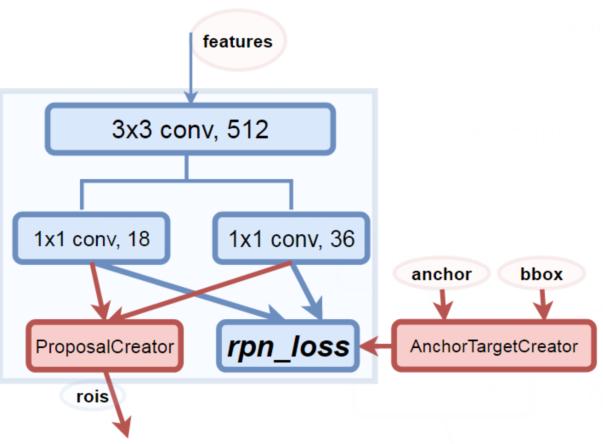
最后总结下,RPN会在特征图每点都输出9x2个分类结果和9x4个回归结果,分别与每点的9个anchor的分类标签和回归标签对应(RPN是二分类,仅区分前、背景),但并不是会对每个点都计算损失,最多仅有256个点会参与损失计算。
因为通过上述可知,仅有256个anchor样本供训练使用,而其中还可能有多个anchor对应到一个特征像素点上。注意下,这部分的训练是与ProposalCreator并行的分支,并不是拿ProposalCreator的输出进行训练!
另外,这里有个问题引发了我的思考:在前文讲RPN部分的第1节中,我们提到计算anchor坐标时可能出现负数,那么在筛选训练样本时它们就势必会被剔除掉。
如果我们将计算时anchor的坐标clip到输入图像尺寸范围内,那么就有可能引入更多有效的训练样本,甚至是优质样本,提高召回率是肯定的,精确率的话是不是也有可能提高?
2. 筛选RoI样本,指导检测器训练
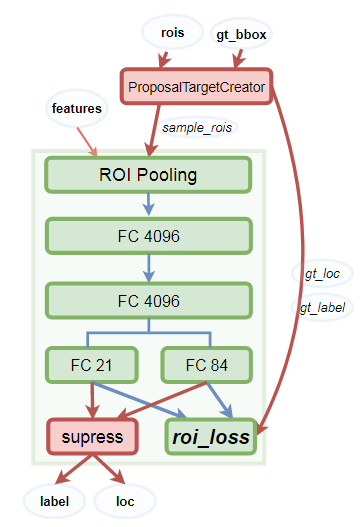
这部分是从Proposal Creator (RPN中的Proposal Layer)产生的RoIs中筛选出128个目标样本,其中正负样本比为1:3,用于指导检测器(RoIHead)的训练。
具体方法是,计算每个RoI与每个gt的IoU,若某个RoI与所有gt计算所得的最大IoU不小于0.5,则为正样本,并记录下与此对应的gt,打上相应的类别标签,同时限制正样本数量不超过32个。
相对地,若某个RoI与所有gt的最大IoU小于0.5,则标记为负样本,类别标签为0,同时限制负样本数量不超过96个,正负样本的类别标签用作指导分类训练。最后,计算gt相对于RoI样本的中心点坐标位移和两者长宽比,并且归一化(减均值除标准差),用于指导回归训练。
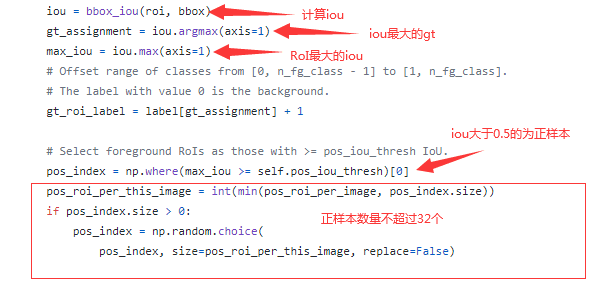
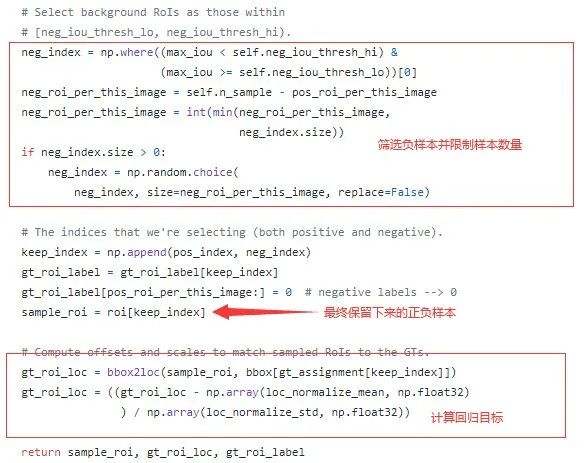
在实际的代码实现中,将GT也一并加入了RoIs样本中:
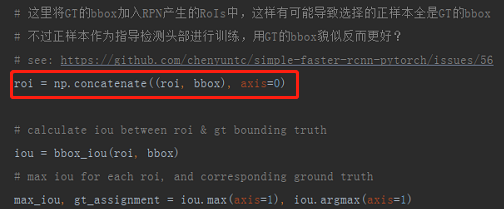
仔细想想,感觉挺有道理,因为RoIs来源于RPN的输出,而RPN的结果并不一定可靠,特别是在训练初期,几乎就是随机输出,可能连一个正样本都没有,加入GT一方面弥补了正样本数量的不足,另一方面还提供了更优质的正样本,怎么说它也是GT啊,还有比它更正的么!?
另外,虽然RoIs众多,但仅有128个样本进行了训练,训练时仅将这128个训练样本(Proposal Target Creator的输出)输入到RoIHead,而测试时则是将RPN(Proposal Creator)的输出直接输入到RoIHead。
最后注意下,RPN的回归目标是没有归一化的,而RoIHead的有。
3. Loss函数的设计
这里使用了两种loss函数,CrossEntropy Loss(交叉熵损失) 用于分类,Smooth L1 Loss 用于回归,注意在RPN和RoIHead中,回归损失均只针对正样本计算。
这里,Smooth L1 Loss 的实现有个技巧,通过给正负样本设置不同的损失权重,其中负样本权重为0,正样本权重为1,这样就可以忽略负样本的回归损失。
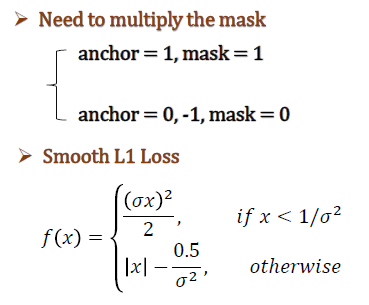
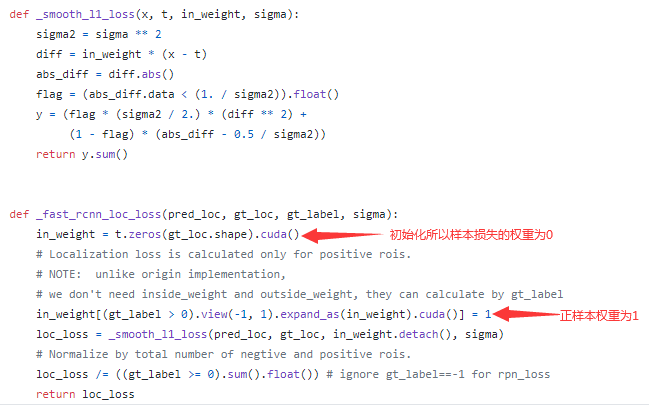
通过上图可看到,在计算回归损失的均值时,分母将负样本(标签为0)数量也算上了,为何呢?明明只计算了正样本的回归损失啊.. 现在,“明明”就来告诉你!
可以拿RPN中loss的计算举例,其实,loss的原公式是这样的:
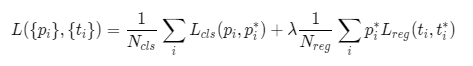
其中,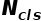 表示mini-batch中采集的样本数量(RPN中默认为256个),
表示mini-batch中采集的样本数量(RPN中默认为256个),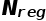 表示anchor位置的数量,即feature map中特征点的数量(约2400个),λ是平衡参数,相当于加权(大于一时给回归loss加权,小于1时给分类加权),论文中默认为10。
表示anchor位置的数量,即feature map中特征点的数量(约2400个),λ是平衡参数,相当于加权(大于一时给回归loss加权,小于1时给分类加权),论文中默认为10。
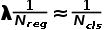 ,于是就用
,于是就用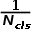 代替
代替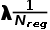 了。
了。所以,在计算回归损失的时候,系数的分母就使用正负样本的总数了。
七. KeyPoints
1. Anchor 与 RoI 傻傻分不清楚?
它们都是矩形框,通常以(左上角坐标、右下角坐标)或者(中心点坐标、长、宽)表示。不同的是,anchor是预设的可能覆盖目标物体的区域,而RoI是网络产生的更为可靠的目标候选区域。
可以这么看,anchor 是“死”的,是人为设置的(当然,后来的一些算法框架能够通过聚类得出anchor,如YOLO),通过穷举它来尽可能覆盖目标物体。因此需要网络通过训练来进一步筛选和调整,产生RoI。在RoIHead部分,可认为RoIs充当了anchor的作用。
另外,在Faster R-CNN的实现中,anchor和RoI的尺寸对应的是网络的输入图像,而原图像和输入图像之间做了尺寸缩放,如以下代码部分可看到一个'scale'变量,在预测的时候注意需要把结果根据缩放系数转换对应到原图上。
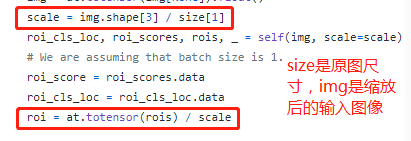
输入图像与原图之间进行了缩放
2. 回归结果为何不是bbox的坐标?
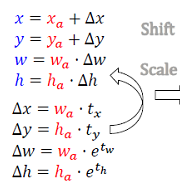
本文一直强调,无论是在RPN还是RoIHead中,回归结果都不是bounding box的坐标,而是相对(正样本anchor、RoI)中心点坐标的位移和长宽比。为方便叙述,这里把两者分别称之为offset和scale。
直观地看,直接回归bounding box的坐标更方便,免去了传参(RPN中需要传入anchor,RoIHead中需要传入RoI)与坐标计算。
但是,如果回归的是坐标,那么在计算损失时,大尺寸bbox的坐标误差占的比重可能就会比小尺寸bbox之间的坐标误差大得多,从而使得模型更偏向于学习大bbox,从而导致小目标的检测效果不佳。

那么如何计算offset和scale呢?拿上图RPN的例子来说,对于预测框(蓝色框),offset等于其中心点与anchor(红色框)中心点坐标差除以anchor边长,scale等于两者的长宽比,并且使用log函数,log函数的作用也是一定程度上抑制了大bbox之间的误差占比盖过小bbox(拉近了大、小bbox之间的误差水平),gt(绿色框)的计算方法类似。
在训练过程中,如果我们希望预测框接近于gt,那么它们与anchor之间的offset和scale都应该尽可能接近,于是将gt与anchor的offset与scale作为回归的目标。
转换成坐标的时候,基于上述公式逆向计算即可。
3.3 个 Creator 分别做了什么?
Anchor Target Creator:对特征图上每点对应的anchor样本进行筛选(尺寸、IoU、样本数量),为 RPN提供256个训练样本,正负样本比为1:1,此处是二分类;
Proposal Creator:对RPN产生的RoI进行筛选(尺寸、置信度、数量、NMS),产生大约2000个RoIs;
Proposal Target Creator:从Proposal Creator产生的RoIs中筛选(数量和IoU)128个目标样本以指导检测头部(RoIHead)训练,正负样本比为1:3,此处是多分类。
Anchor Target Creator 和 Proposal Target Creator 仅在训练过程中使用,而 Proposal Creator 在训练和测试过程中都会用到,但它们都不涉及反向传播,因此这部分在不同深度学习框架上可以方便地通过numpy迁移实现。
4.4 个损失的作用是什么?
• RPN分类损失:区分anchor是前景还是背景,从而让模型能够学会区分前景和背景;
• RPN回归损失:调整anchor的位置和形状,使其更接近于gt;
• RoI分类损失:区分RoI属于哪个物体类别(这里是21类,包括背景);
• RoI回归损失:调整RoI的位置和形状,使其更接近于gt、预测结果更精细。
由上述可知,其实在RPN输出的时候,就已经完成了“检测”任务,即能够把目标物体框出来,只不过没有对这些物体类别进行细分而已,并且框出来的位置可能不够精准。而RoIHead可看作是对RPN结果的调优。
结语
从整体框架上来看,Faster R-CNN主要包含Feature Extractor(特征提取)、RPN(产生候选区域)、RoIHead(检测器)三部分,理论看似简单,但是代码实现起来真不容易。
自己在学习Faster R-CNN的时候,看了不少资料,也做了相关笔记,但觉得没有真正学懂,有些点总是记不牢,不能够在脑海里很好地复现。于是就决定撸一遍源码,这样之后总算是踏实下来了。
作为深度学习目标检测领域中具有重大意义的算法,手撸一遍源码还是很有必要的,如果只是知道它的原理,那么并不真正代表会了,一个知识点你听懂了和你能够把它复现甚至改进是完全两码事,实践才是检验成果的硬道理!
作者简介
CW,广东深圳人,毕业于中山大学(SYSU)数据科学与计算机学院,毕业后就业于腾讯计算机系统有限公司技术工程与事业群(TEG)从事Devops工作,期间在AI LAB实习过,实操过道路交通元素与医疗病例图像分割、视频实时人脸检测与表情识别、OCR等项目。
目前也有在一些自媒体平台上参与外包项目的研发工作,项目专注于CV领域(传统图像处理与深度学习方向均有)。
推荐阅读
