
TiDB 探索 | 一栈式 X 规模化 X 多元化:PingCAP 马晓宇谈 TiDB HTAP 演进之路
本文根据 PingCAP DevCon 2021 上 PingCAP HTAP 产品负责人马晓宇的分享整理而成,介绍了 TiDB 在 HTAP 领域探索的过去、现在和未来。
数据库为何而建

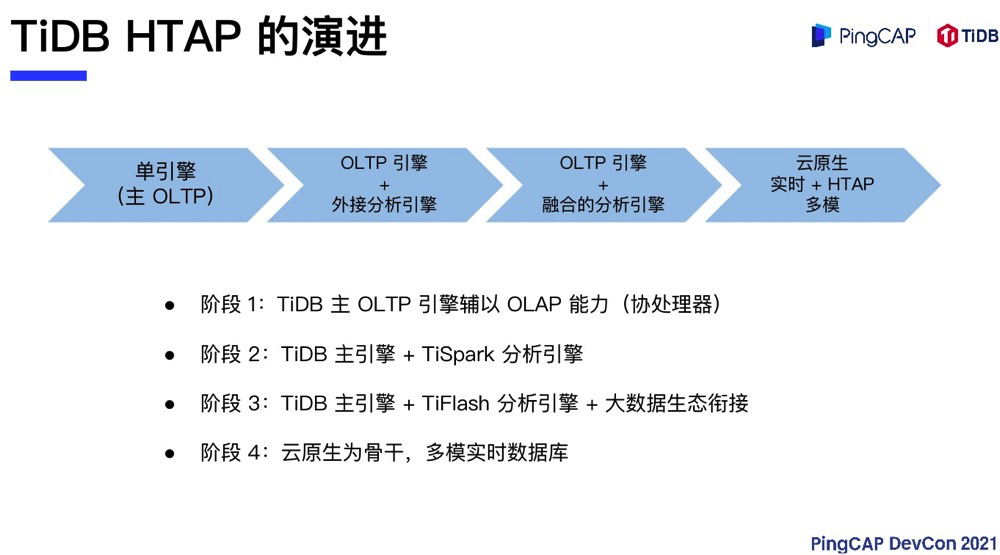
TiDB HTAP 的演进之路
现在 TiDB 的 HTAP 走到哪里了呢?从最早开始,TiDB 是一个单引擎,主 OLTP,辅以 OLAP。那个时候 HTAP 的 OLAP 部分是协处理器,也就是说每个 TiKV 会分担一部分 OLAP 的处理,比如说可以把所有的聚合推到 TiKV,每个 TiKV 分别以分片的方式去聚合部分数据,然后再向 TiDB 去做汇总,可以比较快地实现类似多维聚合这样的需求。
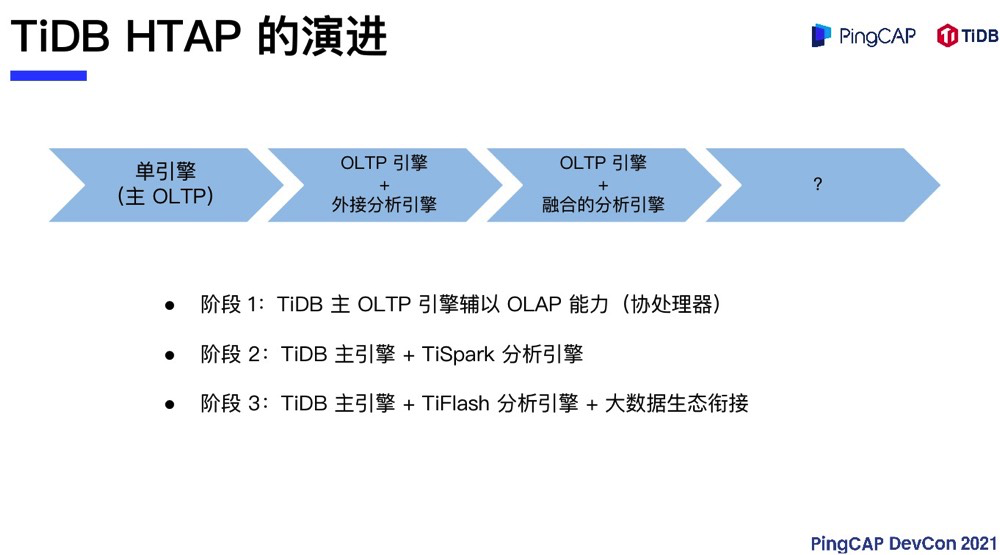
到了第二阶段,我们发现光有聚合其实是不够的,必须还要有处理复杂计算的引擎。那个时候公司人也不多,我们就选择借助其他外部的引擎。TiSpark 这套引擎就是借助 Apache Spark 连接 TiKV 存储引擎,可以用 Spark 的分布式计算器直接去读取 TiKV 的分布式存储引擎来完成 HTAP 的使命。在这个场景中,我们以一个 OLTP 引擎加一部分协处理器的功能,再辅以外部的分析引擎来完成 HTAP 功能。
第三段也就是现在的状态,TiDB 拥有 OLTP 的主引擎,有一个 TiFlash 分析引擎。TiFlash 实时从交易引擎同步数据以达到实时分析的目的,并且可以实现一致性的数据读取。TiFlash 这套分析引擎的速度也完全可以与业界各种专项的分析引擎媲美。另外,通过大数据生态圈的衔接,例如借助 TiSpark,TiDB 同样可以获得更多外部引擎的能力加持。第四阶段,TiDB 的HTAP 要走向何方?这个我们等到最后再讲。
TiDB 5.0 HTAP 的特性和场景

举个例子,我们在发版之前会模拟用户场景进行测试,在交易引擎上不断地进行高频的转帐模拟,同时我们会在分析引擎上做对帐。在连续长时间的测试中,但凡有一次数据对不上,产品的发版是会停止的。TiDB 的 HTAP 引擎确保了在任何交易发生的时候,分析引擎是可以完整地读到最新而且是一致的数据。现实中有很多对数据一致性有非常高要求的场景,比如说银行,假设有一个财务系统,不断的有财务数据进来,需要通过 TiFlash 或者通过 OLAP 引擎去做对账,这个场景 TiFlash 是完全可以胜任的。
另外,TiDB 的 HTAP 和很多其他产品有非常显著的区别。市场上有些 HTAP 产品采用融合引擎的架构,在同一组资源上通过精巧的资源调度的方式来实现,在不同的引擎之间进行作业隔离。但是,从工业界的角度看,不管业务隔离做得有多精巧,其实都没有办法匹敌 TiDB HTAP 用两套资源分别去执行 OLTP 和 OLAP。可以说 TiDB HTAP 在资源和业务隔离层面的设计,在业界是非常优秀的。
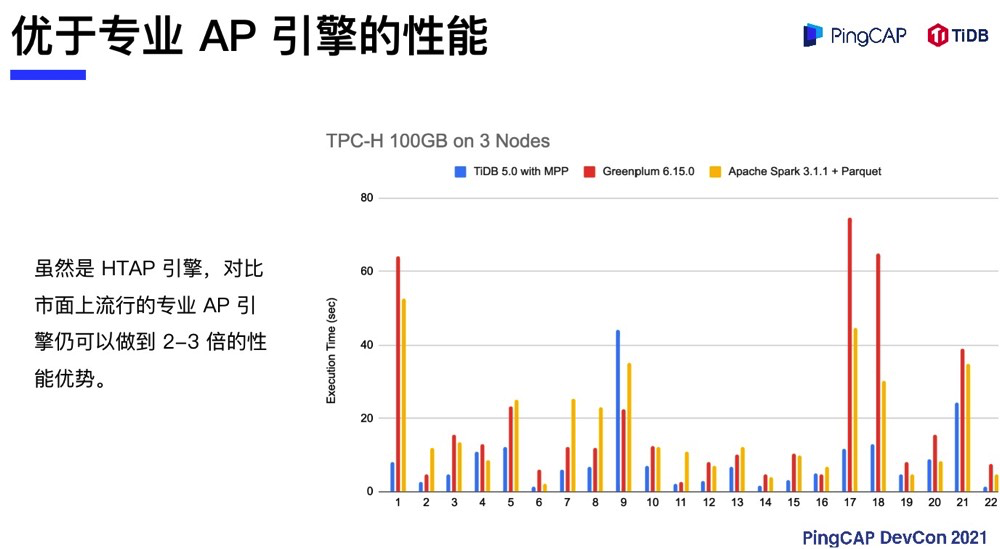
虽然 TiFlash 不是一个专门为 OLAP 而设计的引擎,但是经过实际场景的 TPC-H 测试,TiFlash 相对于业界比较流行的 OLAP 分析框架具备更快的处理能力。对比 Greenplum 最新版、Apache Spark 3.1.1 以及 Parquet,TiFlash 在开启 MPP 的情况下整体的处理性能有 2-3 倍的优势。
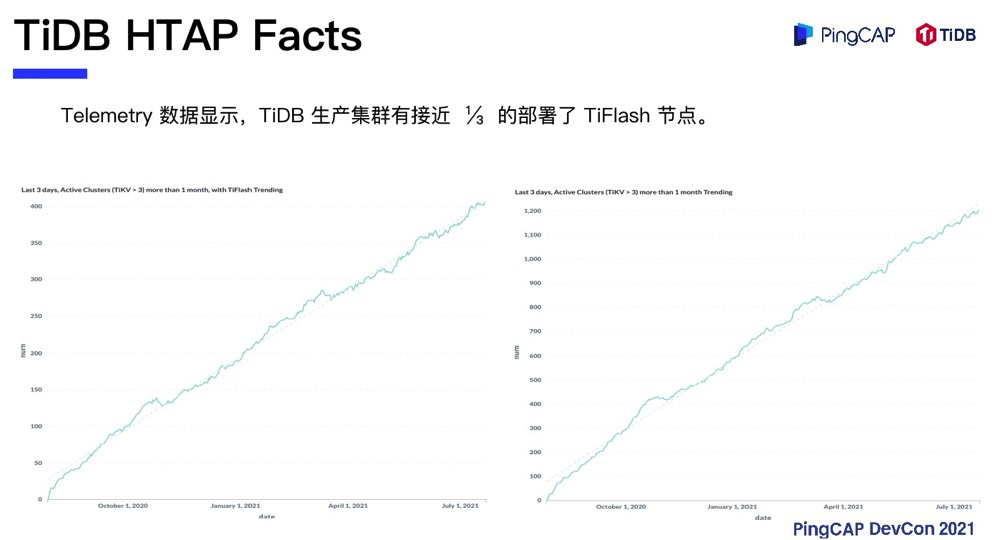
从 TiFlash 发布至今,通过 Telemetry 数据分析,我们发现在 TiDB 生产规格的集群中(TiKV大于三个节点且运行超过一个月),已经有接近三分之一的用户部署了 TiFlash 节点。
这些用户是如何使用 TiFlash 的?从调研的结果看,大致有以下三种典型的应用场景:
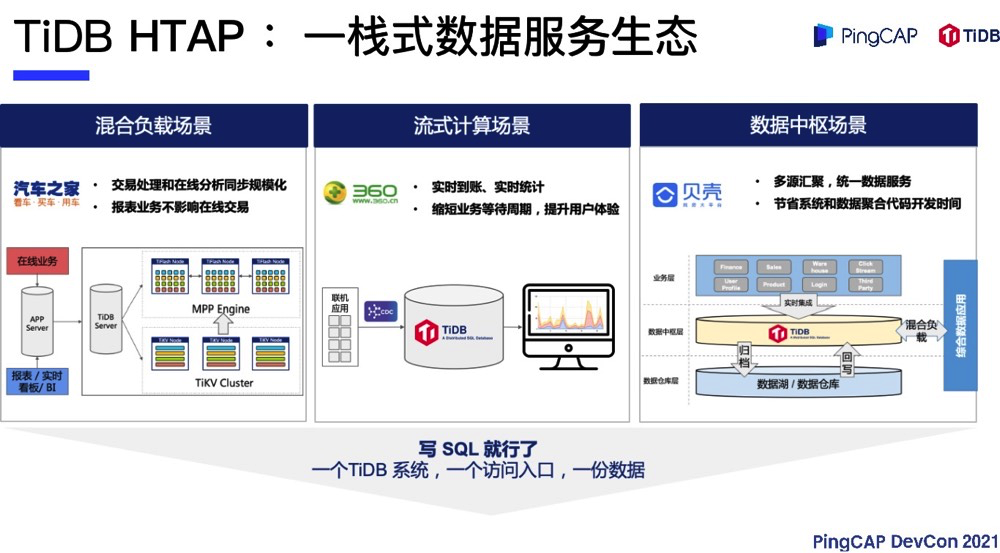
第一种是 OLTP和 OLAP 混合负载场景。比如说企业的 ERP 应用,或者是类似于经营分析系统,需要做实时报表,OLTP 负载使用 TiDB,报表和实时看板使用 TiFlash,这是一个最经典的混合架构的应用。
第二种是流式计算场景。我们发现 TiDB 的用户和 Flink 的用户有比较高的重合度,这些用户使用 Flink 对 CDC 进行加工,比如说平宽表或者做预聚合,然后把这些数据落到 TiFlash 或者落到 TiDB 里面。为什么 TiDB 是一个很好的承载体?首先 TiDB 是可扩展的,它既有行,又有列,并且支持实时更新,所以对 Flink 来说是一个很好的落地点。落地之后,除了 Flink 本身可以计算指标和看板,也可以通过落地的数据做一个轻量级的实时 ETL,形成一个实时数仓,最后在 TiDB 里面去展示各种各样的报表。
另外一种是数据中枢场景,这个场景涉及面比较广。很多用户在使用 TiDB 之前已经有了 Hadoop,等其他大数据分析或数仓类架构。在和这些数据栈并存的时候,用户把 TiDB 作为业务层和离线层之间的数据中枢层,提供对数据的实时访问和实时的收纳。数据会从 CDC 实时集成到 TiDB,TiDB 也可以分批地归档到离线层的数据湖和数据仓库。在数据中枢层,TiDB 可以直接提供实时报表,也可以提供跨不同业务线的数据采集和数据访问。以上是 TiDB HTAP 三种比较典型的用法。
以云原生为骨干,走向多模和实时

第二个是云原生,以 TiDB Cloud 为核心的联邦平台。为什么 Cloud 和 HTAP 会相关呢?假设现在的数据库是多模的,可以同时承载 OLTP 和 OLAP 的不同业务。那么在云上,可以为用户提供一个超级大的池子,这个池子的部署和运维都会非常方便,可以把用户不同的业务线都汇聚到这个池子,不管是说 OLTP 直接放到 TiDB 上,还是说数据中台直接放到 TiDB 上。另外,存算分离之后,可以把 TiDB 计算引擎单独提供出来,然后再配合 Foreign Data Wrapper 这种方式来提供联邦查询,通过 TiDB 和其他数据生态进行连接,还可以用外部引擎来补充 TiDB 原生引擎暂时没有提供的功能,比如 Machine Learning,TiDB HTAP 也可以借助 TiSpark 等大数据生态引擎来处理。
从多模的角度看,HTAP 本身就是一个多模的基础,现在 TiDB 本身就是一个数据生态,除了OLTP、OLAP,其实也有 KV。另外 TiDB 社区也会发起其他引擎项目,例如之前 Hackathon 中倒排索引的项目,类似这些也会逐步加到我们的 Roadmap 中。
TiDB HTAP 希望达到的是什么?OLTP 是所有数据的源头,也就是万里长征的入口。我们希望将万里长征入口把握在 TiDB 这边,以 HTAP 能力支撑敏捷和实时的分析体验,以流和物化视图能力拓展实时数仓边界。云化适合的能力,推进从在线到离线之间的串联。最后,以大数据生态和联邦查询的方式把整个体系同步到一起。TiDB HTAP 始终希望为用户提供统一的一站式体验。
