
送书 | 两百四十多万字,六百章的小说秒爬完
大家好!啃书君。
相信很多人喜欢在空闲的时间里看小说,甚至有小部分人为了追小说而熬夜看,那么问题来了,喜欢看小说的小伙伴在评论区告诉我们为什么喜欢看小说,今天我们手把手教你使用异步协程20秒爬完两百四十多万字,六百章的小说,让你一次看个够。
在爬取之前我们先来简单了解一下什么是同步,什么是异步协程?
同步与异步
同步
同步是有序,为了完成某个任务,在执行的过程中,按照顺序一步一步执行下去,直到任务完成。
爬虫是IO密集型任务,我们使用requests请求库来爬取某个站点时,网络顺畅无阻塞的时候,正常情况如下图所示:
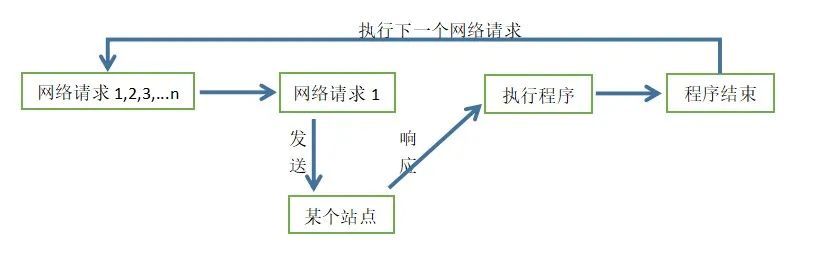
但在网络请求返回数据之前,程序是处于阻塞状态的,程序在等待某个操作完成期间,自身无法继续干别的事情,如下图所示:

当然阻塞可以发生在站点响应后的执行程序那里,执行程序可能是下载程序,大家都知道下载是需要时间的。
当站点没响应或者程序卡在下载程序的时候,CPU一直在等待而不去执行其他程序,那么就白白浪费了CPU的资源,导致我们的爬虫效率很低。
异步
异步是一种比多线程高效得多的并发模型,是无序的,为了完成某个任务,在执行的过程中,不同程序单元之间过程中无需通信协调,也能完成任务的方式,也就是说不相关的程序单元之间可以是异步的。如下图所示:
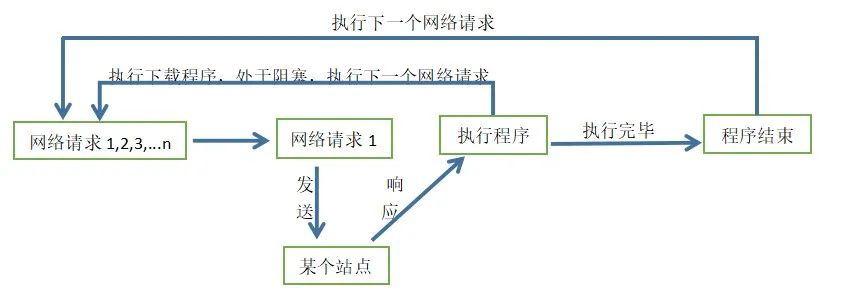
当请求程序发送网络请求1并收到某个站点的响应后,开始执行程序中的下载程序,由于下载需要时间或者其他原因使处于阻塞状态,请求程序和下载程序是不相关的程序单元,所以请求程序发送下一个网络请求,也就是异步。
微观上异步协程是一个任务一个任务的进行切换,切换条件一般就是IO操作;
宏观上异步协程是多个任务一起在执行;
注意:上面我们所讲的一切都是在单线程的条件下实现。
请求库
我们发送网络请求一定要用到请求库,Python从多个HTTP客户端中,最常用的请求库莫过于requests、aiohttp、httpx。
在不借助其他第三方库的情况下,requests只能发送同步请求;aiohttp只能发送异步请求;httpx既能发送同步请求,又能发送异步请求。
接下来我们将简单讲解这三个库。
requests库
相信大家对requests库不陌生吧,requests库简单、易用,是python爬虫使用最多的库。
在命令行中运行如下代码,即可完成requests库的安装:
pip install requests
使用requests发送网络请求非常简单,
在本例中,我们使用get网络请求来获取百度首页的源代码,具体代码如下:
import requests
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36'
}
response=requests.get('https://baidu.com',headers=headers)
response.encoding='utf-8'
print(response.text)
运行部分结果如下图:
首先我们导入requests库,创建请求头,请求头中包含了User-Agent字段信息,也就是浏览器标识信息,如果不加这个,网站就可能禁止抓取,然后调用get()方法发送get请求,传入的参数为URL链接和请求头,这样简单的网络请求就完成了。
这里我们返回打印输出的是百度的源代码,大家可以根据需求返回输出其他类型的数据。
需要注意的是:
百度源代码的head部分的编码为:utf-8,如下图所示:

我们利用requests库的方法来查看默认的编码类型是什么,具体代码如下所示:
import requests
url = 'https://www.baidu.com'
response = requests.get(url)
print(response.encoding)
运行结果为:ISO-8859-1
由于默认的编码类型不同,所以需要更改输出的编码类型,更改方式也很简单,只需要在返回数据前根据head部分的编码来添加以下代码即可:
response.encoding='编码类型'
除了使用get()方法实现get请求外,还可以使用post()、put()、delete()等方法来发送其他网络请求,在这里就不一一演示了,关于更多的requests网络请求库用法可以到官方参考文档进行查看,我们今天主要讲解可以发送异步请求的aiohttp库和httpx库。
asyncio模块
在讲解异步请求aiohttp库和httpx库请求前,我们需要先了解一下协程。
协程是一种比线程更加轻量级的存在,让单线程跑出了并发的效果,对计算资源的利用率高,开销小的系统调度机制。
Python中实现协程的模块有很多,我们主要来讲解asyncio模块,从asyncio模块中直接获取一个EventLoop的引用,把需要执行的协程放在EventLoop中执行,这就实现了异步协程。
协程通过async语法进行声明为异步协程方法,await语法进行声明为异步协程可等待对象,是编写asyncio应用的推荐方式,具体示例代码如下:
import asyncio
import time
async def function1():
print('I am Superman!!!')
await asyncio.sleep(3)
print('function1')
async def function2():
print('I am Batman!!!')
await asyncio.sleep(2)
print('function2')
async def function3():
print('I am iron man!!!')
await asyncio.sleep(4)
print('function3')
async def Main():
tasks=[
asyncio.create_task(function1()),
asyncio.create_task(function2()),
asyncio.create_task(function3()),
]
await asyncio.wait(tasks)
if __name__ == '__main__':
t1=time.time()
asyncio.run(Main())
t2=time.time()
print(t2-t1)
运行结果为:
I am Superman!!!
I am Batman!!!
I am iron man!!!
function2
function1
function3
4.0091118812561035
首先我们用了async来声明三个功能差不多的方法,分别为function1,function2,function3,在方法中使用了await声明为可等待对象,并使用asyncio.sleep()方法使函数休眠一段时间。
再使用async来声明Main()方法,通过调用asyncio.create_task()方法将方法封装成一个任务,并把这些任务存放在列表tasks中,这些任务会被自动调度执行;
最后通过asyncio.run()运行协程程序。
注意:当协程程序出现了同步操作的时候,异步协程就中断了。
例如把上面的示例代码中的await asyncio.sleep()换成time.time(),运行结果为:
I am Superman!!!
function1
I am Batman!!!
function2
I am iron man!!!
function3
9.014737844467163
所以在协程程序中,尽量不使用同步操作。
好了,asyncio模块我们讲解到这里,想要了解更多的可以进入asyncio官方文档进行查看。
aiohttp库
aiohttp是基于asyncio实现的HTTP框架,用于HTTP服务器和客户端。安装方法如下:
pip install aiohttp
aiohttp只能发送异步请求,示例代码如下所示:
import aiohttp
import asyncio
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36'
}
async def Main():
async with aiohttp.ClientSession() as session:
async with session.get('https://www.baidu.com',headers=headers) as response:
html = await response.text()
print(html)
loop=asyncio.get_event_loop()
loop.run_until_complete(Main())
运行结果和前面介绍的requests网络请求一样,如下图所示:
大家可以对比requests网络请求发现,其实aiohttp.ClientSession() as session相当于将requests赋给session,也就是说session相当于requests,而发送网络请求、传入的参数、返回响应内容都和requests请求库大同小异,只是aiohttp请求库需要用async和await进行声明,然后调用asyncio.get_event_loop()方法进入事件循环,再调用loop.run_until_complete(Main())方法运行事件循环,直到Main方法运行结束。
注意:在调用Main()方法时,不能使用下面这条语句:
asyncio.run(Main())
虽然会得到想要的响应,但是会报错:RuntimeError: Event loop is closed错误。
我们还可以在返回的内容中指定解码方式或编码方式,例如:
await response.text(encoding='utf-8')
或者选择不编码,读取图像:
await resp.read()
好了aiohttp请求库我们学到这里,想要了解更多的可以到pypi官网进行学习。
httpx请求库
在前面我们简单地讲解了requests请求库和aiohttp请求库,requests只能发送同步请求,aiohttp只能发送异步请求,而httpx请求库既可以发送同步请求,又可以发送异步请求,而且比上面两个效率更高。
安装方法如下:
pip install httpx
httpx请求库——同步请求
使用httpx发送同步网络请求也很简单,与requests代码重合度99%,只需要把requests改成httpx即可正常运行。
具体示例代码如下:
import httpx
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'
}
response=httpx.get('https://www.baidu.com',headers=headers)
print(response.text)
运行结果如下图所示:
注意:httpx使用的默认utf-8进行编码来解码响应。
httpx请求库——同步请求高级用法
当发送请求时,httpx必须为每个请求建立一个新连接(连接不会被重用),随着对主机的 请求数量增加,网络请求的效率就是变得很低。
这时我们可以用Client实例来使用HTTP连接池,这样当我们主机发送多个请求时,Client将重用底层的TCP连接,而不是为重新创建每个请求。
with模块用法如下:
with httpx.Client() as client: ...
我们把Client作为上下文管理器,并使用with块,当执行完with语句时,程序会自动清理连接。
当然我们可以使用.close()显式关闭连接池,用法如下:
client = httpx.Client()
try:
...
finally:
client.close()
为了我们的代码更简洁,我们推荐使用with块写法,具体示例代码如下:
import httpx
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'
}
with httpx.Client(headers=headers)as client:
response=client.get('https://www.baidu.com')
print(response.text)
其中httpx.Client()as client相当于把httpx的功能传递给client,也就是说示例中的client相当于httpx,接着我们就可以使用client来调用get请求。
注意:我们传递的参数可以放在httpx.Client()里面,也可以传递到get()方法里面。
httpx请求库——异步请求
要发送异步请求时,我们需要调用AsyncClient,具体示例代码如下:
import httpx
import asyncio
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'
}
async def function():
async with httpx.AsyncClient()as client:
response=await client.get('https://www.baidu.com',headers=headers)
print(response.text)
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.run_until_complete(function())
运行结果为:
首先我们导入了httpx库和asyncio模块,使用async来声明function()方法并用来声明with块的客户端打开和关闭,用await来声明异步协程可等待对象response。接着我们调用asyncio.get_event_loop()方法进入事件循环,再调用loop.run_until_complete(function())方法运行事件循环,直到function运行结束。
好了,httpx请求库讲解到这里,想要了解更多的可以到httpx官方文档进行学习,接下来我们正式开始爬取小说。
实战演练
接下来我们将使用requests请求库同步和httpx请求库的异步,两者结合爬取17k小说网里面的百万字小说,利用XPath来做相应的信息提取。
Xpath小技巧
在使用Xpath之前,我们先来介绍使用Xpath的小技巧。
技巧一:快速获取与内容匹配的Xpath范围。
我们可以将鼠标移动到我们想要获取到内容div的位置并右击选择copy,如下图所示:
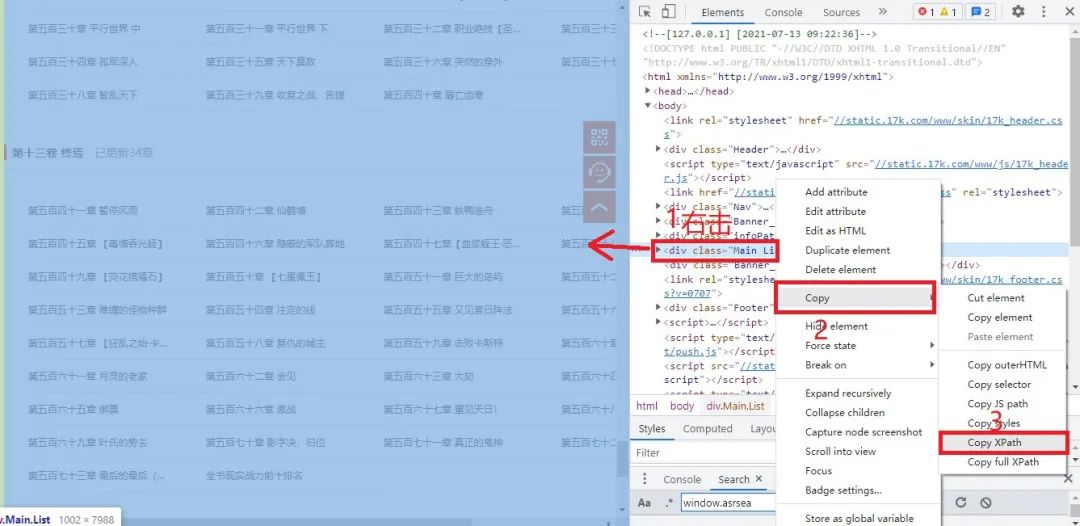
这样我们就可以成功获取到内容匹配的Xpath范围了。
技巧二:快速获取Xpath范围匹配的内容。
当我们写好Xpath匹配的范围后,可以通过Chrome浏览器的小插件Xpath Helper,该插件的安装方式很简单,在浏览器应用商店中搜索Xpath Helper,点击添加即可,如下图所示:
使用方法也很简单,如下图所示:
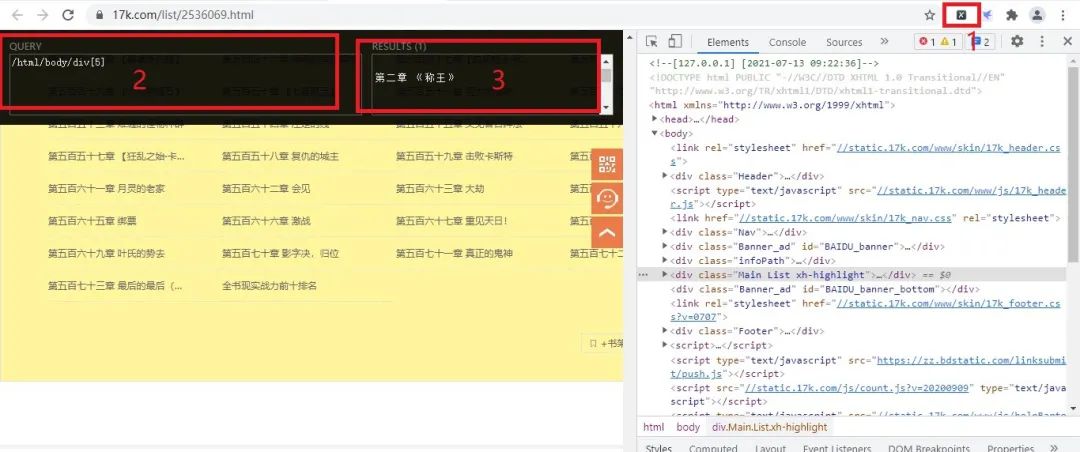
首先我们点击刚刚添加的插件,然后把已经写好的Xpath范围写到上图2的方框里面,接着Xpath匹配的内容将出现在上图3方框里面,接着被匹配内容的背景色全部变成了金色,那么我们匹配内容就一目了然了。
这样我们就不需要每写一个Xpath范围就运行一次程序查看匹配内容,大大提高了我们效率。
获取小说章节名和链接
首先我们选取爬取的目标小说,并打开开发者工具,如下图所示:

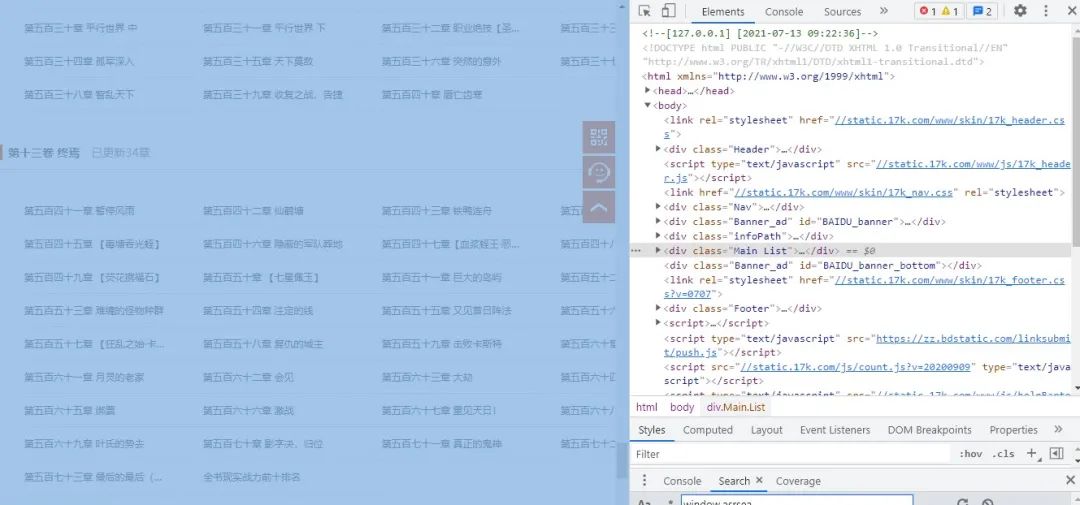
我们通过上图可以发现,<div class="Main List"存放着我们所有小说章节名,点击该章节就可以跳转到对应的章节页面,所以可以使用Xpath来通过这个div来获取到我们想要的章节名和URL链接。
由于我们获取的章节名和URL链接的网络请求只有一个,直接使用requests请求库发送同步请求,主要代码如下所示:
async def get_link(url):
response=requests.get(url)
response.encoding='utf-8'
Xpath=parsel.Selector(response.text)
dd=Xpath.xpath('/html/body/div[5]')
for a in dd:
#获取每章节的url链接
links=a.xpath('./dl/dd/a/@href').extract()
linklist=['https://www.17k.com'+link for link in links]
#获取每章节的名字
names=a.xpath('./dl/dd/a/span/text()').extract()
namelist=[name.replace('\n','').replace('\t','') for name in names]
#将名字和url链接合并成一个元组
name_link_list=zip(namelist,linklist)
首先我们用async声明定义的get_text()方法使用requests库发送get请求并把解码方式改成'utf-8',接着使用parsel.Selector()方法将文本构成Xpath解析对象,最后我们将获取到的URL链接和章节名合并成一个元组。
获取到URL链接和章节名后,需要构造一个task任务列表来作为异步协程的可等待对象,具体代码如下所示:
task=[]
for name,link in name_link_list:
task.append(get_text(name,link))
await asyncio.wait(task)
我们创建了一个空列表,用来存放get_text()方法,并使用await调用asyncio.wait()方法保存创建的task任务。
获取每章节的小说内容
由于需要发送很多个章节的网络请求,所以我们采用httpx请求库来发送异步请求。
主要代码如下所示:
async def get_text(name,link):
async with httpx.AsyncClient() as client:
response=await client.get(link)
html=etree.HTML(response.text)
text=html.xpath('//*[@id="readArea"]/div[1]/div[2]/p/text()')
await save_data(name,text)
首先我们将上一步的获取到的章节名和URL链接传递到用async声明定义的get_text()方法,使用with块调用httpx.AsyncClient()方法,并使用await来声明client.get()是可等待对象,然后使用etree模块来构造一个XPath解析对象并自动修正HTML文本,将获取到的小说内容和章节名传入到自定义方法save_data中。
保存小说内容到text文本中
好了,我们已经把章节名和小说内容获取下来了,接下来就要把内容保存在text文本中,具体代码如下所示:
async def save_data(name,text):
f=open(f'小说/{name}.txt','w',encoding='utf-8')
for texts in text:
f.write(texts)
f.write('\n')
print(f'正在爬取{name}')
老规矩,首先用async来声明save_data()协程方法save_data(),然后使用open()方法,将text文本文件打开并调用write()方法把小说内容写入文本中。
最后调用asyncio.get_event_loop()方法进入事件循环,再调用loop.run_until_complete(get_link())方法运行事件循环,直到function运行结束。具体代码如下所示:
url='https://www.17k.com/list/2536069.html'
loop = asyncio.get_event_loop()
loop.run_until_complete(get_link(url))
结果展示

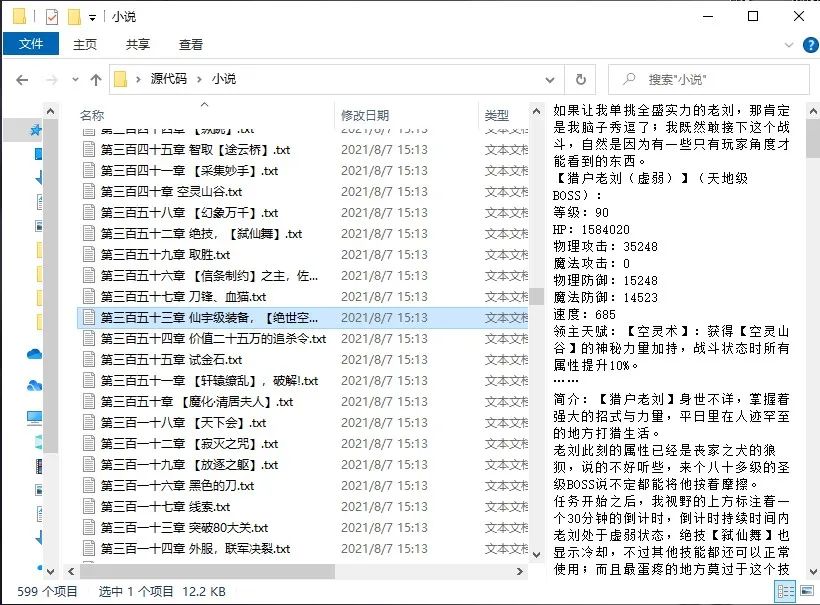
好了,异步爬虫爬取小说就讲解到这里了,感谢观看!!!
送书
又到了每周三的送书时刻,今天给大家带来的是《Python Django Web从入门到项目实战(视频版)》
Python 的 Django 框架是目前流行的一款重量级网站开发框架,具备简单易学、搭建快速、功能强大等特点。
本书从简单的 HTML、CSS、JavaScript 开始介绍,再到 Django 的基础知识,融入了大量的代码案例、重点提示、图片展示,做到了手把手教授。
本书基于 Django 3.0.7 版本、Python 3.8.5 版本、Rest Framework 3.11.1 版本、Vue.js 2.6.10 版本、数据库 MySQL 8.0 版本进行讲解。
本书还提供了一个商业级别的项目案例,采用目前主流的前后端分离开发技术,以便读者可以体验正式项目的开发过程。
熟练掌握本书内容后,读者将达到中级 Web 项目开发工程师的技术水平。


公众号回复:送书 ,参与抽奖(共3本)
点击下方回复:送书 即可!
大家如果有什么建议,欢迎扫一扫二维码私聊小编~
回复:加群 可加入Python技术交流群