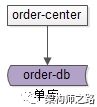
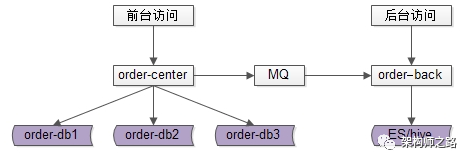
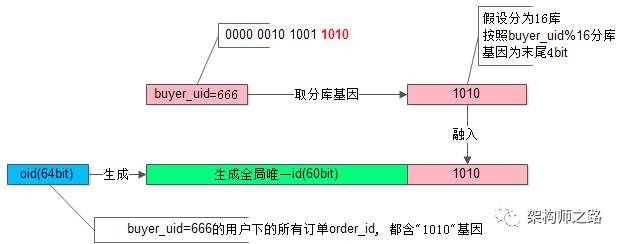
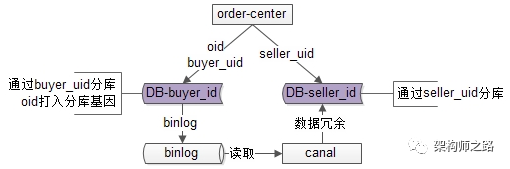
订单中心,1亿数据架构,这次服了架构师之路关注共 3637字,需浏览 8分钟 ·2020-08-28 16:57 订单中心,是互联网业务中,一个典型的“多key”业务,即:用户ID,商家ID,订单ID等多个key上都有业务查询需求。随着数据量的逐步增大,并发量的逐步增大,订单中心这种“多key”业务,架构应该如何设计,有哪些因素需要考虑,是本文将要系统性讨论的问题。什么是“多key”类业务?所谓的“多key”,是指一条元数据中,有多个属性上存在前台在线查询需求。订单中心是什么业务,有什么典型业务需求?订单中心是一个非常常见的“多key”业务,主要提供订单的查询与修改的服务,其核心元数据为:Order(oid, buyer_uid, seller_uid, time, money, detail…);其中:(1)oid为订单ID,主键;(2)buyer_uid为买家uid;(3)seller_uid为卖家uid;(4)time, money, detail, …等为订单属性;数据库设计上,一般来说在业务初期,单库,配合查询字段上的索引,就能满足元数据存储与查询需求。(1)order-center:订单中心服务,对调用者提供友好的RPC接口;(2)order-db:对订单进行数据存储,并在订单,买家,卖家等字段建立索引;随着订单量的越来越大,数据库需要进行水平切分,由于存在多个key上的查询需求,用哪个字段进行切分呢?(1)如果用oid来切分,buyer_uid和seller_uid上的查询则需要遍历多库;(2)如果用buyer_uid或seller_uid来切分,其他属性上的查询则需要遍历多库;总之,很难有一个万全之策,在展开技术方案之前,先一起梳理梳理查询需求。任何脱离业务需求的架构设计,都是耍流氓。订单中心,典型业务查询需求有哪些?第一类,前台访问,最典型的有三类需求:(1)订单实体查询:通过oid查询订单实体,90%流量属于这类需求;(2)用户订单列表查询:通过buyer_uid分页查询用户历史订单列表,9%流量属于这类需求;(3)商家订单列表查询:通过seller_uid分页查询商家历史订单列表,1%流量属于这类需求;前台访问的特点是什么呢?吞吐量大,服务要求高可用,用户对订单的访问一致性要求高,商家对订单的访问一致性要求相对较低,可以接受一定时间的延时。第二类,后台访问,根据产品、运营需求,访问模式各异:(1)按照时间,价格,商品,详情来进行查询;后台访问的特点是什么呢?运营侧的查询基本上是批量分页的查询,由于是内部系统,访问量很低,对可用性的要求不高,对一致性的要求也没这么严格,允许秒级甚至十秒级别的查询延时。这两类不同的业务需求,应该使用什么样的架构方案来解决呢?要点一:前台与后台分离的架构设计。如果前台业务和后台业务共用一批服务和一个数据库,有可能导致,由于后台的“少数几个请求”的“批量查询”的“低效”访问,导致数据库的cpu偶尔瞬时100%,影响前台正常用户的访问(例如,订单查询超时)。前台与后台访问的查询需求不同,对系统的要求也不一样,故应该两者解耦,实施“前台与后台分离”的架构设计。前台业务架构不变,站点访问,服务分层,数据库水平切分。后台业务需求则抽取独立的web/service/db来支持,解除系统之间的耦合,对于“业务复杂”“并发量低”“无需高可用”“能接受一定延时”的后台业务:(1)可以去掉service层,在运营后台web层通过dao直接访问数据层;(2)可以不需要反向代理,不需要集群冗余;(3)可以通过MQ或者线下异步同步数据,牺牲一些数据的实时性;(4)可以使用更契合大量数据允许接受更高延时的“索引外置”或者“HIVE”的设计方案;关于前台与后台分离的架构设计,在《用户中心,1亿数据架构,这次服了》一文中有更为细致的分析,便不再展开。解决完了后台业务的访问需求,那前台的oid,buyer_uid,seller_uid如何来进行数据库水平切分呢?要点二:多个维度的查询较为复杂,对于复杂系统设计,应该逐个击破。假设没有seller_uid,应该如何击破oid和buyer_uid的查询需求?订单中心,假设只有oid和buyer_uid上的查询需求,就蜕化为一个“1对多”的业务场景,对于“1对多”的业务,水平切分应该使用“基因法”。要点三:基因法,是解决“1对多”业务,数据库水平切分的常见方案。什么是分库基因?通过buyer_uid分库,假设分为16个库,采用buyer_uid%16的方式来进行数据库路由,所谓的模16,其本质是buyer_uid的最后4个bit决定这行数据落在哪个库上,这4个bit,就是分库基因。什么是基因法分库?在订单数据oid生成时,oid末端加入分库基因,让同一个buyer_uid下的所有订单都含有相同基因,落在同一个分库上。如上图所示,buyer_uid=666的用户下了一个订单:(1)使用buyer_uid%16分库,决定这行数据要插入到哪个库中;(2)分库基因是buyer_uid的最后4个bit,即1010;(3)在生成订单标识oid时,先使用一种分布式ID生成算法生成前60bit(上图中绿色部分);(4)将分库基因加入到oid的最后4个bit(上图中粉色部分),拼装成最终64bit的订单oid(上图中蓝色部分);通过这种方法保证,同一个用户下的所有订单oid,都落在同一个库上,oid的最后4个bit都相同,于是:(1)通过buyer_uid%16能够定位到库;(2)通过oid%16也能定位到库;关于“一对多”业务,以及“基因法”,在《帖子中心,1亿数据架构,这次服了》一文中有更为细致的分析,便不再展开。假设没有oid,应该如何击破buyer_uid和seller_uid的查询需求?订单中心,假设只有buyer_uid和seller_uid上的查询需求,就蜕化为一个“多对多”的业务场景,对于“多对多”的业务,水平切分应该使用“数据冗余法”。如上图所示:(1)当有订单生成时,通过buyer_uid分库,oid中融入分库基因,写入DB-buyer库;(2)通过线下异步的方式,通过binlog+canal,将数据冗余到DB-seller库中;(3)buyer库通过buyer_uid分库,seller库通过seller_uid分库,前者满足oid和buyer_uid的查询需求,后者满足seller_uid的查询需求;数据冗余的方法有很多种:(1)服务同步双写;(2)服务异步双写;(3)线下异步双写(上图所示,是线下异步双写);要点四:数据冗余,是解决“多对多”业务,数据库水平切分的常见方案。不管哪种方案,因为两步操作不能保证原子性,总有出现数据不一致的可能,高吞吐分布式事务是业内尚未解决的难题,此时的架构方向,是最终一致性,并不是完全保证数据的一致,而是尽早的发现不一致,并修复不一致。要点五:最终一致性,是高吞吐互联网业务一致性的常用实践。保证冗余数据最终一致的常见方案有三种:(1)冗余数据全量定时扫描;(2)冗余数据增量日志扫描;(3)冗余数据线上消息实时检测;关于“多对多”业务,数据冗余多种方案,数据冗余保证最终一致性多种方案,在《好友中心,1亿数据架构,这次服了》一文中有更为细致的分析,便不再展开。那如果oid/buyer_uid/seller_uid同时存在呢?综合上面的解决方案即可:(1)如果没有seller_uid,“多key”业务会蜕化为“1对多”业务,此时应该使用“基因法”分库:使用buyer_uid分库,在oid中加入分库基因;(2)如果没有oid,“多key”业务会蜕化为“多对多”业务,此时应该使用“数据冗余法”分库:使用buyer_uid和seller_uid来分别分库,冗余数据,满足不同属性上的查询需求;(3)如果oid/buyer_uid/seller_uid同时存在,可以使用上述两种方案的综合方案,来解决“多key”业务的数据库水平切分难题;要点总结一:前后台差异化需求,可使用前台与后台分离的架构设计;二:对于复杂系统设计,应该逐个击破;三:基因法,是解决“1对多”业务,数据库水平切分的常见方案;四:数据冗余,是解决“多对多”业务,数据库水平切分的常见方案;五:最终一致性,是高吞吐互联网业务一致性的常用实践。相关文章:《用户中心,1亿数据架构,这次服了》《帖子中心,1亿数据架构,这次服了》《好友中心,1亿数据架构,这次服了》任何脱离业务的架构设计都是耍流氓,共勉。如果你喜欢这种讲技术的方式,扫码一起玩。有方法论,能落地,视频讲架构 浏览 38点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 百度订单系统架构浅析苏三说技术0一文搞懂业务架构、应用架构、技术架构、数据架构!你好,我是王路情,一个坚持早上5点起床,阅读1小时书籍的创业者,提供软件设计、数据科学与人工智能的服务。请问有什么需要我帮助的吗?感恩遇见,共赢未来。“有效的企业架构(Enterprise Architecture,EA)画出美好蓝图,对企业的生存和成功具有决定性的作用,是企业通过IT获得竞争优势的数据规划架构设计数据D江湖0真实业务订单 拆单 架构与实战逆锋起笔0京东到家订单中心 Elasticsearch 演进历程Java技术驿站0数据治理与数据中台架构数据D江湖0一文看懂:什么是业务架构、数据架构、应用架构和技术架构点这里👇星标关注,获取最新资讯!导言IDCFTOGAF(The Open Group Architecture Framework)是一个广泛应用的企业架构框架,旨在帮助组织高效地进行架构设计和管理。而TOGAF的核心就是由我们熟知的四大架构领域组成:业务架构、数据架构、应用架构和技术架构。所以今天数据湖存储架构选型程序源代码0日订单量达到100万单后,我们做了订单中心重构有关SQL0数据湖 | 大数据存储架构峰会:数据湖技术论坛HBase技术社区0点赞 评论 收藏 分享 手机扫一扫分享分享 举报
 下载APP
下载APP