
MySQL索引底层:B+树详解
前言
当我们发现SQL执行很慢的时候,自然而然想到的就是加索引。对于范围查询,索引的底层结构就是B+树。今天我们一起来学习一下B+树哈~
公众号:「捡田螺的小男孩」
树简介、树种类 B-树、B+树简介 B+树插入 B+树查找 B+树删除 B+树经典面试题
树的简介
树的简介
树跟数组、链表、堆栈一样,是一种数据结构。它由有限个节点,组成具有层次关系的集合。因为它看起来像一棵树,所以得其名。一颗普通的树如下:

树是包含n(n为整数,大于0)个结点, n-1条边的有穷集,它有以下特点:
❝❞
每个结点或者无子结点或者只有有限个子结点; 有一个特殊的结点,它没有父结点,称为根结点; 每一个非根节点有且只有一个父节点; 树里面没有环路
一些有关于树的概念:
❝❞
结点的度:一个结点含有的子结点个数称为该结点的度; 树的度:一棵树中,最大结点的度称为树的度; 父结点:若一个结点含有子结点,则这个结点称为其子结点的父结点; 深度:对于任意结点n,n的深度为从根到n的唯一路径长,根结点的深度为0; 高度:对于任意结点n,n的高度为从n到一片树叶的最长路径长,所有树叶的高度为0;
树的种类
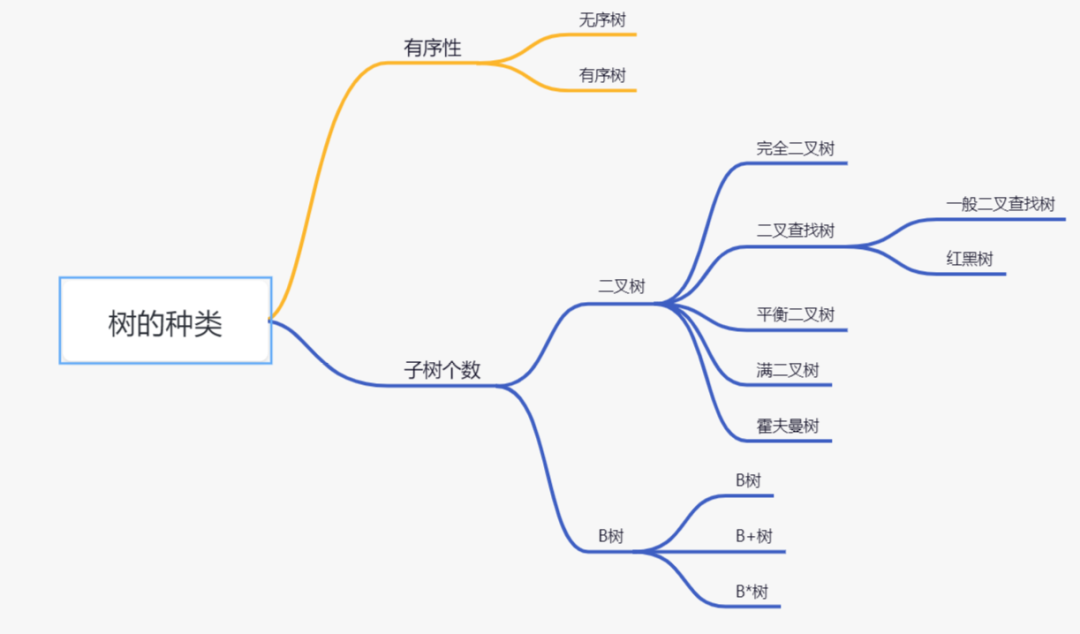
按照有序性,可以分为有序树和无序树:
❝❞
无序树:树中任意节点的子结点之间没有顺序关系 有序树:树中任意节点的子结点之间有顺序关系
按照节点包含子树个数,可以分为B树和二叉树,二叉树可以分为以下几种:
❝❞
二叉树:每个节点最多含有两个子树的树称为二叉树; 二叉查找树:首先它是一颗二叉树,若左子树不空,则左子树上所有结点的值均小于它的根结点的值;若右子树不空,则右子树上所有结点的值均大于它的根结点的值;左、右子树也分别为二叉排序树; 满二叉树:叶节点除外的所有节点均含有两个子树的树被称为满二叉树; 完全二叉树:如果一颗二叉树除去最后一层节点为满二叉树,且最后一层的结点依次从左到右分布 霍夫曼树:带权路径最短的二叉树。 红黑树:红黑树是一颗特殊的二叉查找树,每个节点都是黑色或者红色,根节点、叶子节点是黑色。如果一个节点是红色的,则它的子节点必须是黑色的。 平衡二叉树(AVL):一 棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树
B-树、B+树简介
B-树 简介
B-树,也称为B树,是一种平衡的多叉树(可以对比一下平衡二叉查找树),它比较适用于对外查找。看下这几个概念哈:
❝❞
阶数:一个节点最多有多少个孩子节点。(一般用字母m表示) 关键字:节点上的数值就是关键字 度:一个节点拥有的子节点的数量。
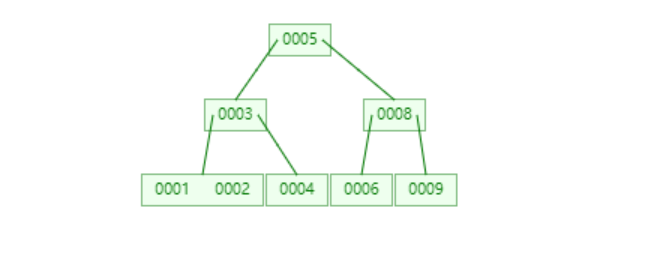
一颗m阶的B-树,有以下特征:
❝❞
根结点至少有两个子女; 每个非根节点所包含的关键字个数 j 满足:⌈m/2⌉ - 1 <= j <= m - 1.(⌈⌉表示向上取整) 有k个关键字(关键字按递增次序排列)的非叶结点恰好有k+1个孩子。 所有的叶子结点都位于同一层。
一棵简单的B-树如下:
B+ 树简介
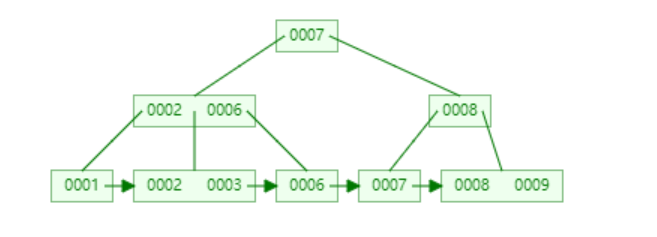
B+树是B-树的变体,也是一颗多路搜索树。一棵m阶的B+树主要有这些特点:
❝❞
每个结点至多有m个子女; 非根节点关键值个数范围:[m/2](注意是这个哈,后面图例写错了) <= k <= m-1 相邻叶子节点是通过指针连起来的,并且是关键字大小排序的。
一颗3阶的B+树如下:
B+树和B-树的主要区别如下:
B-树内部节点是保存数据的;而B+树内部节点是不保存数据的,只作索引作用,它的叶子节点才保存数据。 B+树相邻的叶子节点之间是通过链表指针连起来的,B-树却不是。 查找过程中,B-树在找到具体的数值以后就结束,而B+树则需要通过索引找到叶子结点中的数据才结束 B-树中任何一个关键字出现且只出现在一个结点中,而B+树可以出现多次。
B+树的插入
B+树插入要记住这几个步骤:
1.B+树插入都是在叶子结点进行的,就是插入前,需要先找到要插入的叶子结点。 2.如果被插入关键字的叶子节点,当前含有的关键字数量是小于阶数m,则直接插入。 3.如果插入关键字后,叶子节点当前含有的关键字数目等于阶数m,则插,该节点开始「分裂」为两个新的节点,一个节点包含⌊m/2⌋ 个关键字,另外一个关键字包含⌈m/2⌉个关键值。(⌊m/2⌋表示向下取整,⌈m/2⌉表示向上取整,如⌈3/2⌉=2)。 4.分裂后,需要将第⌈m/2⌉的关键字上移到父结点。如果这时候父结点中包含的关键字个数小于m,则插入操作完成。 5.分裂后,需要将⌈m/2⌉的关键字上移到父结点。如果父结点中包含的关键字个数等于m,则继续分裂父结点。
以一颗4阶的B+树为例子吧,4阶的话,关键值最多3(m-1)个。假设插入以下数据43,48,36,32,37,49,28.
在空树中插入43

这时候根结点就一个关键值,此时它是根结点也是叶子结点。
依次插入48,36

这时候跟节点拥有3个关键字,已经满了
继续插入 32,发现当前节点关键字已经不小于阶数4了,于是分裂
第⌈4/2⌉=2(下标0,1,2)个,也即43上移到父节点。

继续插入37,49,前节点关键字都是还没满的,直接插入,如下:

最后插入28,发现当前节点关键字也是不小于阶数4了,于是分裂,于是分裂,
第 ⌈4/2⌉=2个,也就是36上移到父节点,因父子节点只有2个关键值,还是小于4的,所以不用继续分裂,插入完成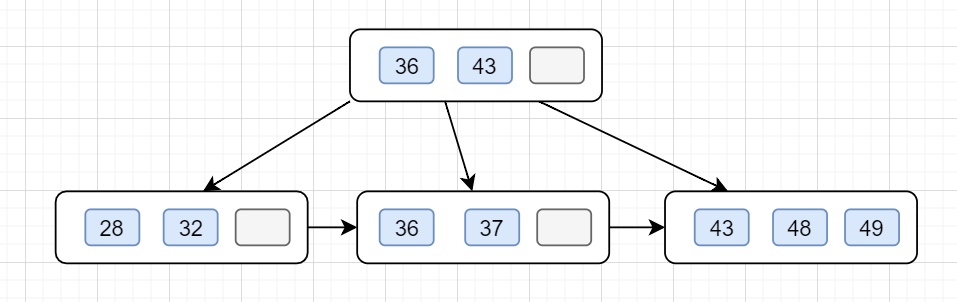
B+树的查找
因为B+树的数据都是在叶子节点上的,内部节点只是指针索引的作用,因此,查找过程需要搜索到叶子节点上。还是以这颗B+树为例吧:

B+ 树单值查询
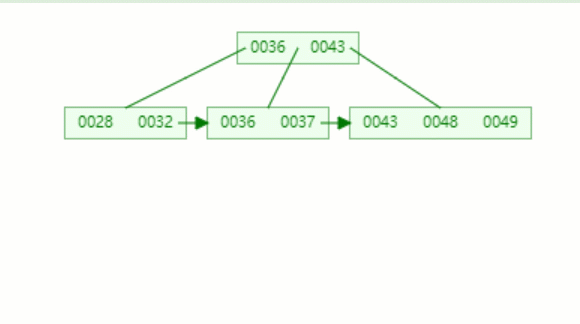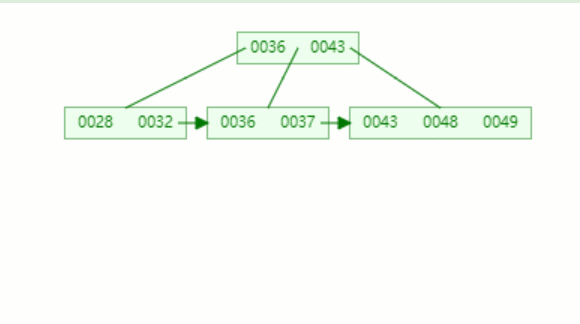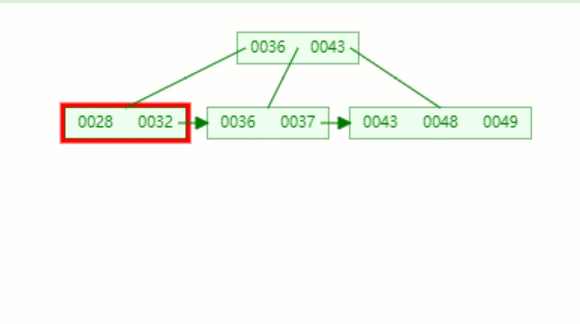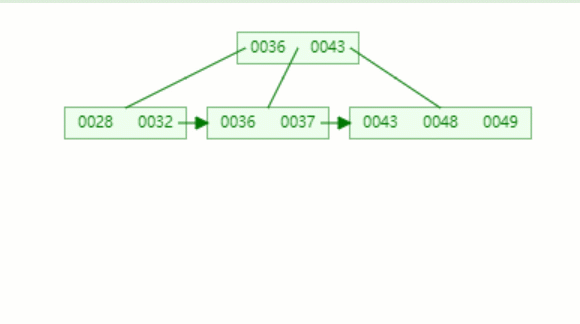
假设我们要查的值为32.
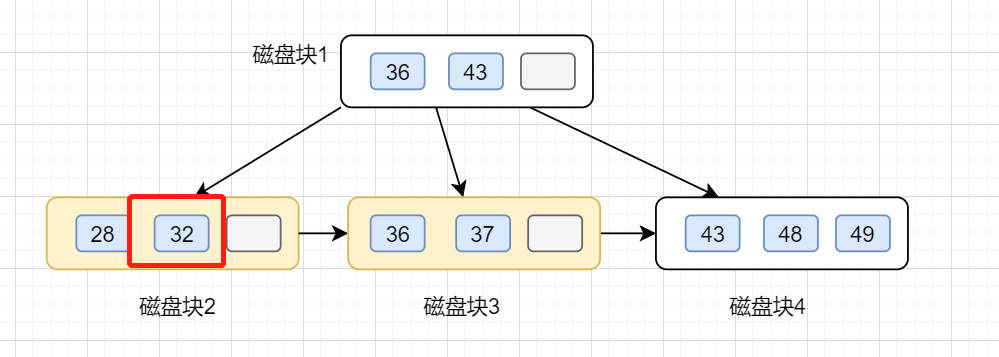
第一次磁盘 I/O,查找磁盘块1,即根节点(36,43),因为32小于36,因此访问根节点的左边第一个孩子节点
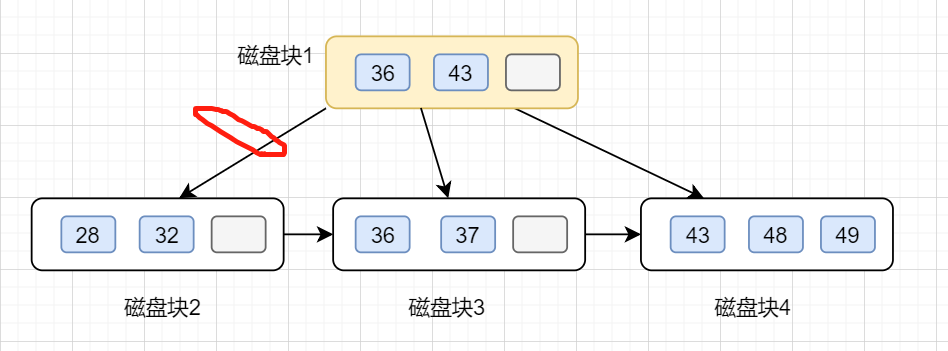
第二次磁盘 I/O, 查找磁盘块2,即根节点的第一个孩子节点,获得区间(28,32),遍历即可得32.
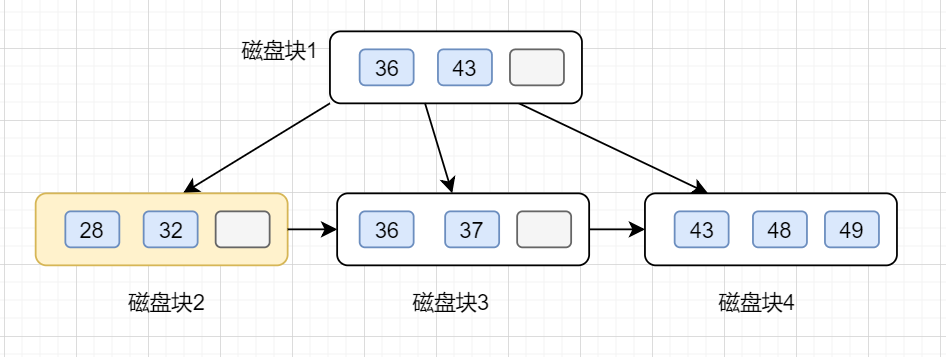
动态图如下:
B+ 树范围查询
假设我们要查找区间 [32,40]区间的值.
第一步先访问根节点,发现区间的左端点32小于36,则访问根节点的第一个左子树(28,32);
第二步访问节点(28,32),找到32,于是开始遍历链表,把[32,40]区间值找出来,这也是B+树比B-树高效的地方。
B+树的删除
B+树删除关键字,分这几种情况
找到包含关键值的结点,如果关键字个数大于⌈m/2⌉-1,直接删除即可; 找到包含关键值的结点,如果关键字个数大于⌈m/2⌉-1,并且关键值是当前节点的最大(小)值,并且该关键值存在父子节点中,那么删除该关键字,同时需要相应调整父节点的值。 找到包含关键值的结点,如果删除该关键字后,关键字个数小于⌈m/2⌉,并且其兄弟结点有多余的关键字,则从其兄弟结点借用关键字 找到包含关键值的结点,如果删除该关键字后,关键字个数小于⌈m/2⌉,并且其兄弟结点没有多余的关键字,则与兄弟结点合并。
如果关键字个数大于⌈m/2⌉,直接删除即可;
假设当前有这么一颗5阶的B+树
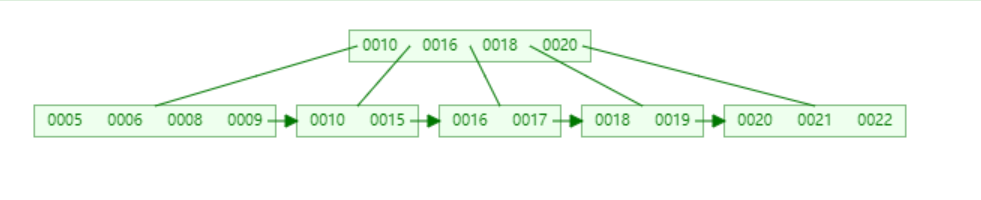
如果删除22,因为关键字个数为3 > ⌈5/2⌉-1=2, 直接删除(⌈⌉表示向上取整的意思)

如果关键字个数大于⌈m/2⌉-1,并且删除的关键字存在于父子节点中,那么需要相应调整父子节点的值

如果删除20,因为关键字个数为3 > ⌈5/2⌉-1=2,并且20是当前节点的边界值,且存在父子节点中,所以删除后,其父子节点也要响应调整。

如果删除该关键字后,关键字个数小于⌈m/2⌉-1,兄弟节点可以借用
以下这颗5阶的B+树,

如果删除15,删除关键字的结点只剩1个关键字,小于⌈5/2⌉-1=2,不满足B+树特点,但是其兄弟节点拥有3个元素(7,8,9),可以借用9过来,如图:

在删除关键字后,如果导致其结点中关键字个数不足,并且兄弟结点没有得借用的话,需要合并兄弟结点
以下这颗5阶的B+树:

如果删除关键字7,删除关键字的结点只剩1个关键字,小于⌈5/2⌉-1=2,不满足B+树特点,并且兄弟结点没法借用,因此发生合并,如下:
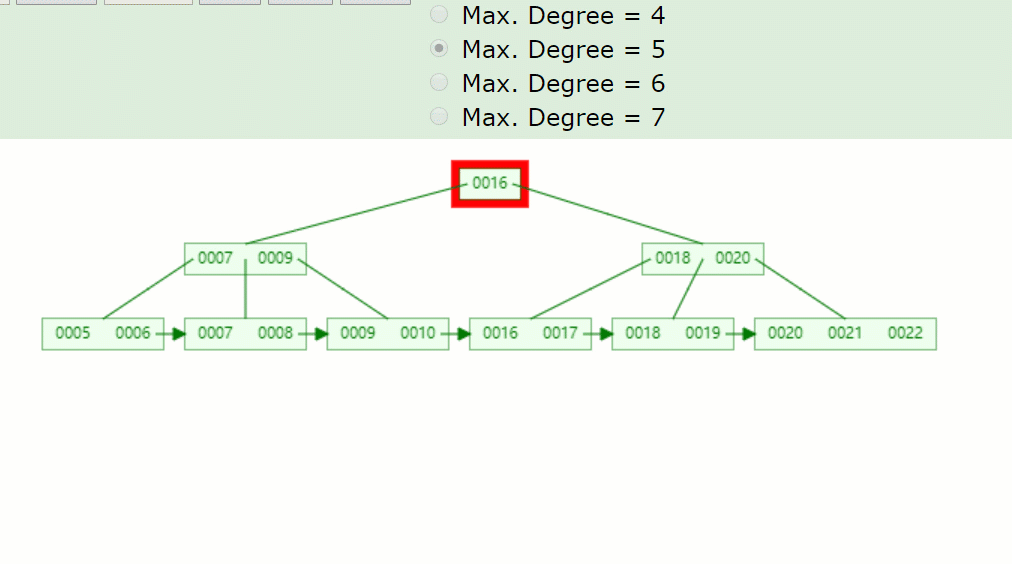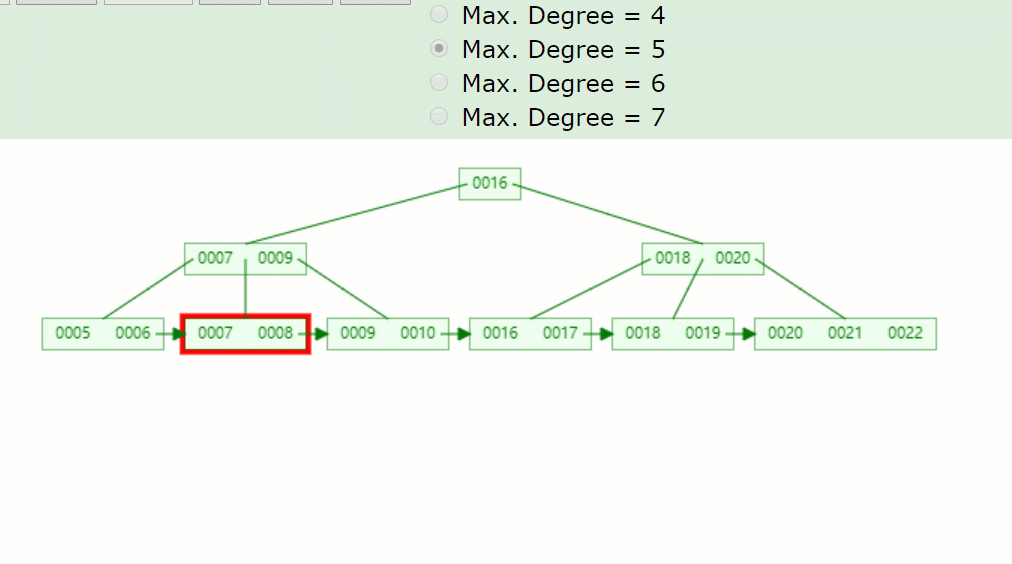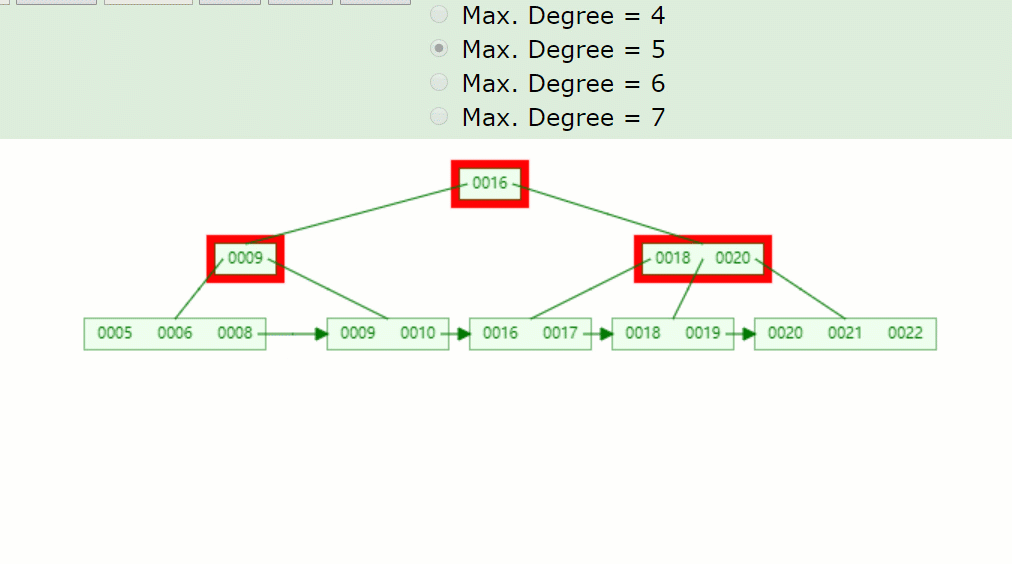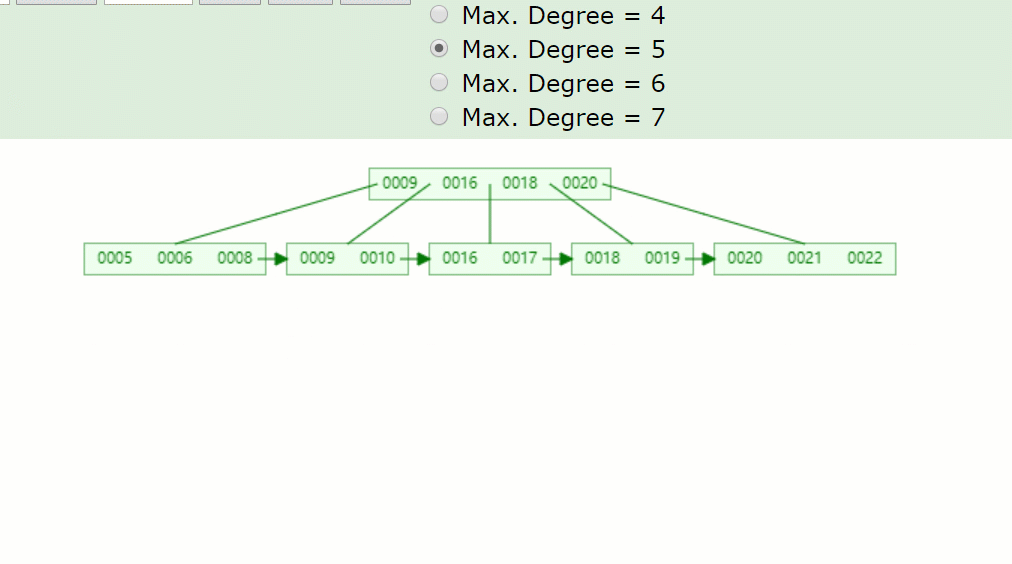
主要流程酱紫:
因为7被删掉后,只剩一个8的关键字,不满足B+树特点(⌈m/2⌉-1<=关键字<=m-1)。 并且没有兄弟结点关键字借用,因此8与前面的兄弟结点结合。 被删关键字结点的父节点,7索引也被删掉了,只剩一个9,并且其右兄弟结点(18,20)只有两个关键字,也是没得借,因此在此合并。 被删关键字结点的父子节点,也和其兄弟结点合并后,只剩一个子树分支,因此根节点(16)也下移了。
所以删除关键字7后的结果如下:

B+树经典面试题
InnoDB一棵B+树可以存放多少行数据? 为什么索引结构默认使用B+树,而不是hash,二叉树,红黑树,B-树? B-树和B+树的区别
InnoDB一棵B+树可以存放多少行数据?
这个问题的简单回答是:约2千万行。
在计算机中,磁盘存储数据最小单元是扇区,一个扇区的大小是512字节。 文件系统中,最小单位是块,一个块大小就是4k; InnoDB存储引擎最小储存单元是页,一页大小就是16k。
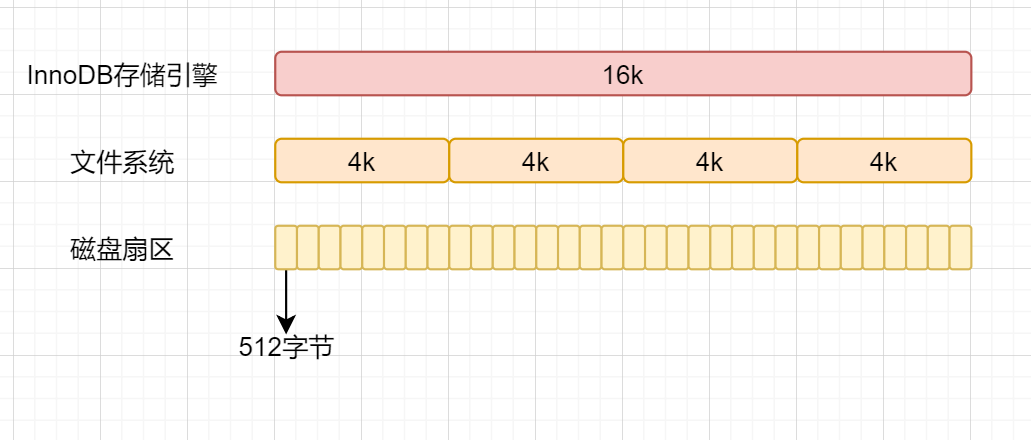
因为B+树叶子存的是数据,内部节点存的是键值+指针。索引组织表通过非叶子节点的二分查找法以及指针确定数据在哪个页中,进而再去数据页中找到需要的数据;

假设B+树的高度为2的话,即有一个根结点和若干个叶子结点。这棵B+树的存放总记录数为=根结点指针数*单个叶子节点记录行数。
如果一行记录的数据大小为1k,那么单个叶子节点可以存的记录数 =16k/1k =16. 非叶子节点内存放多少指针呢?我们假设主键ID为bigint类型,长度为8字节,而指针大小在InnoDB源码中设置为6字节,所以就是8+6=14字节,16k/14B =16*1024B/14B = 1170
因此,一棵高度为2的B+树,能存放1170 * 16=18720条这样的数据记录。同理一棵高度为3的B+树,能存放1170 *1170 *16 =21902400,也就是说,可以存放两千万左右的记录。B+树高度一般为1-3层,已经满足千万级别的数据存储。
为什么索引结构默认使用B+树,而不是B-Tree,Hash哈希,二叉树,红黑树?
简单版回答如下:
Hash哈希,只适合等值查询,不适合范围查询。 一般二叉树,可能会特殊化为一个链表,相当于全表扫描。 红黑树,是一种特化的平衡二叉树,MySQL 数据量很大的时候,索引的体积也会很大,内存放不下的而从磁盘读取,树的层次太高的话,读取磁盘的次数就多了。 B-Tree,叶子节点和非叶子节点都保存数据,相同的数据量,B+树更矮壮,也是就说,相同的数据量,B+树数据结构,查询磁盘的次数会更少。
B-树和B+树的区别
B-树内部节点是保存数据的;而B+树内部节点是不保存数据的,只作索引作用,它的叶子节点才保存数据。 B+树相邻的叶子节点之间是通过链表指针连起来的,B-树却不是。 查找过程中,B-树在找到具体的数值以后就结束,而B+树则需要通过索引找到叶子结点中的数据才结束 B-树中任何一个关键字出现且只出现在一个结点中,而B+树可以出现多次。
参考与感谢
B+树看这一篇就够了[1] B树和B+树的插入、删除图文详解[2] InnoDB一棵B+树可以存放多少行数据?[3]
Reference
B+树看这一篇就够了: https://zhuanlan.zhihu.com/p/149287061
[2]B树和B+树的插入、删除图文详解: https://www.cnblogs.com/nullzx/p/8729425.html
[3]InnoDB一棵B+树可以存放多少行数据?: https://www.cnblogs.com/leefreeman/p/8315844.html