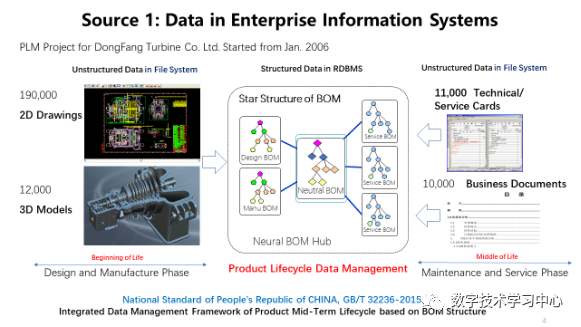
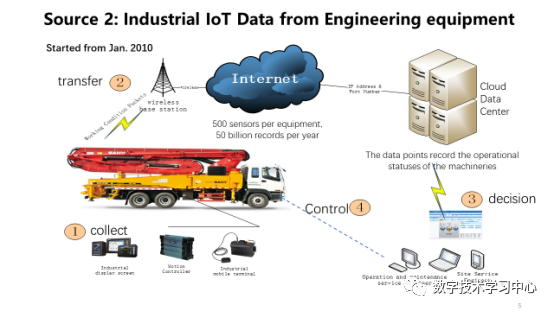
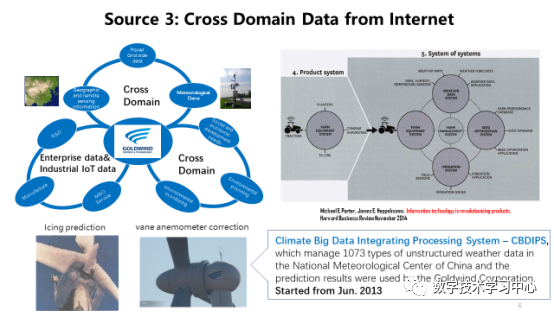
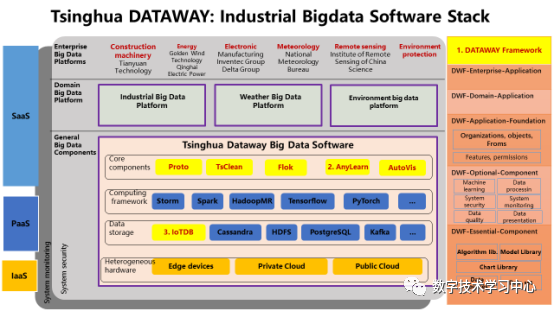
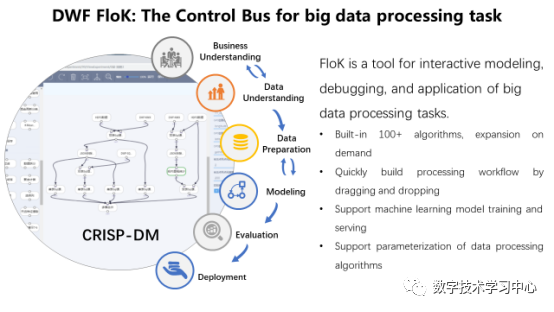
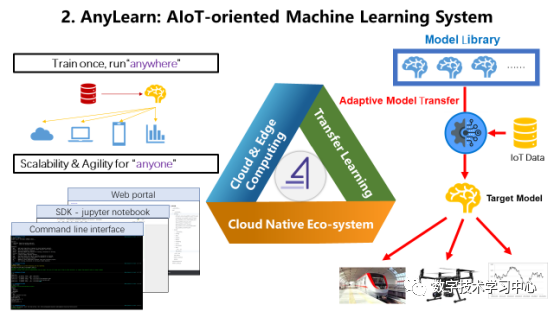
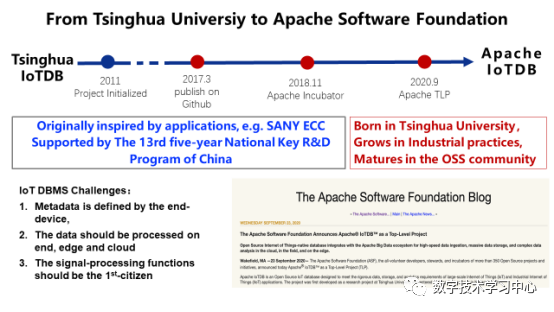
ApacheCON Asia 2021清华大学软件学院王建民:工业大数据软件与开源创新数据派THU关注共 5311字,需浏览 11分钟 ·2021-11-30 03:33 演讲人简介 王建民教授,清华大学软件学院院长、大数据系统软件国家工程实验室执行主任、清华大学大数据研究中心常务副主任,工业大数据系统与应用重点北京市重点实验室主任。国家工业互联网战略咨询专家委员会委员。主要研究领域:大数据与知识工程,包括非结构化数据管理、业务过程与产品生命周期管理、数字版权与系统安全技术、数据库测试技术等。 以下内容节选、翻译自王建民老师于2021年8月在ApacheCON Asia 2021年会会场所做的《工业大数据软件与开源创新》英文主题演讲:很荣幸与各位分享我们在清华大学工业大数据软件研究和开源实践方面的工作。如今,大数据已经不是一个新词了,中国有很多互联网行业的领导者,比如阿里巴巴、腾讯、百度、华为,他们都是大数据领域的强势参与者,并且大多数是面向消费者的。但是,如果我们仔细观察中国经济,就会发现中国在大数据应用的一些主要领域内仍存在滞后——例如制造业、建筑业、运输业等。当下,这些行业面临着两大挑战:缺乏对先进大数据技术有深刻理解的人才,以及现今提供的技术水平不足以解决他们手中的具体问题。然而,大数据同样拥有许多新的关注领域,如人工智能、机器学习、数据科学等。我们的使命是为这些行业进行大数据技术和应用方面的创新。根据2011年麦肯锡全球机构发布的大数据报告显示,制造业的数据量甚至超过了金融业。工业大数据从何而来?第一个数据源是企业信息系统,如CAD系统、PDM和PLM系统、ERP和CRM系统等(这些系统在上世纪六十年代就开始被企业所使用了)。第二个数据源是始于21世纪之初的工业物联网,如飞机、风力发电机等。工业物联网数据又称机器设备数据或工况数据,构成了工业大数据的主体。第三种数据源是来自互联网的跨领域数据,如气象、地理和环境数据,这些数据在当今的人工智能时代很容易得到。工业大数据的第一数据源是企业信息系统。企业信息系统中的数据包含非结构化数据,如二维工程图纸、三维零件模型、服务卡、业务文档等,它们通常存储在文件系统中;与此同时也包含结构化数据,如物料清单和零件项、产品非结构化数据的元数据及其文件路径,它们被存储在关系DBMS中。依据PLM(Product Lifecycle Management,产品生命周期管理)理论,产品的设计和制造阶段也称生命周期的开始阶段(Beginning of the Life, 下文简称BOL),产品的维护和服务阶段也称生命周期的中期阶段(Middle of the Life,下文简称MOL)。为了满足BOL数据与MOL数据之间的双向连接要求,我们引入了中性BOM(Bill of Materials,产品结构清单)结构,将设计制造阶段的BOM与服务阶段BOM有效协调在一起。中性BOM降低了不同生命周期BOM之间的关联复杂度,在企业中得到了广泛应用(如东方汽轮机有限公司等),并被作为国家标准进行发布。工业大数据的第二个数据源是来自工程设备或机械设备的工业物联网数据。为了使设备高效运行,我们需要尽可能多地收集、存储和分析工况数据。原设备制造商(如三一重工、中联重科)在机器中嵌入了许多传感器。以挖掘机为例,其在建筑工地工作时,传感器收集数据并通过Wifi和5G网络将数据发送到云数据中心。这些数据记录了机器设备的运行状态。例如,当设备从一个工地移动到另一个工地时,我们会收集它们的速度、位置和燃料消耗量等数据;当设备工作时,我们收集底盘角度、泵压力等数据。假设一台设备平均有500个传感器,那么这10000台工程设备每年就会产生500多亿条记录。如今,物联网数据已经成为工业大数据的主体,未来也依旧会在工业大数据的总量中占据主导地位。第三种数据源是来自互联网和第三方的跨域数据。根据迈克尔·波特的文章,信息技术正在革新工业产品。在未来,大部分产品将接入互联网,成为智能产品。例如,农业设备系统将与天气数据系统、种子优化系统和灌溉系统协同工作,这就意味着来自互联网和第三方系统的数据将与企业数据和工业物联网数据进行集成和聚合。2013年6月起,我们与中国国家气象中心合作建立了气候大数据集成处理系统。目前,它管理着1073种非结构化实时天气数据,其预测结果已被金风公司所使用——通过预测结冰时间并校正风机叶片对风角的数值,让风力发电机得以平稳运行并产生更多的电力。正如我们所看到的,工业大数据有三个来源:企业信息系统、工业物联网和互联网,可用于四种应用场景:场景一,监控和告警。工业物联网数据和跨域数据可用于设备工作状态和社会事件的监控,并可监控异常报警,甚至对其进行闭环控制。场景二,查询和搜索。ERP、PLM、SCM等企业信息系统中积累的数据具有较高的价值密度,是工业大数据的主数据。一方面,这些数据用于企业日常运营中的数据查询和搜索任务。另一方面,在企业信息系统数据作为主数据的基础之上,工业物联网数据和跨域数据被组织在一起,形成工业数据湖。场景三,加工与报表,也就是商业智能(Business Intelligence,下文简称BI)应用。存储在数据湖的工业原始数据需要经过加工转换(将一个数据集转换为另一个数据集),通常被转换为关键绩效指标(KPI)。处理结果将作为报告进行交付,这就是典型的BI应用场景。场景四,决策与预测、人工智能应用。如果说BI应用只是完成了数据集之间的转化工作,那么AI应用所做的就是从数据集中提取知识——尤其是训练数据集。如今,机器学习是人工智能应用的主流。因此,深度学习或迁移学习生成的神经网络可以应用于决策和预测工作。在以上的四大应用场景中,工业大数据生命周期可被划分为收集、管理、处理、分析和应用五个阶段。而在具体的工业大数据应用中,这五个阶段可能相互交错的。工业大数据软件栈与大数据生命周期和DIKW金字塔(Data-to-Information-to-Knowledge-to-Wisdom Model,即数据-信息-知识-智慧)是一致的。考虑到数据五个阶段的生命周期以及在四个场景下的应用,我们提出了一种新的大数据软件架构——清华数为(Tsinghua Dataway)。其中,我们研发了一些针对工业大数据需求的项目(下图中的浅黄色方框),如IoTDB、TsClean、Flok、AnyLearn、AutoVis等等。由于时间有限,我将和大家分享其中的三个。第一个是数为框架(DWF),这是一个用于数据密集型应用程序的快速开发平台。它有两个目的:第一个是快速开发,我们采用模型驱动的架构来改变我们实现应用程序的方式——从传统的硬编码升级到轻量级配置,使得初级工程师也能够以低代码的方式来创建应用程序;第二个是大数据密集型应用程序,这意味着它有一个能让不同的大数据组件(比如Hadoop和Spark)易于协作的底层模型,并将这些组件整合到应用程序中,因此用户可以将这个框架作为数据总线、控制总线和交互总线来使用。DWF FloK是大数据处理的控制总线,负责管理大数据软件组件之间的工作流程。众所周知,CRISP-DM作为公认的工业大数据分析范式共包含有6步:业务理解、数据理解、数据准备、建模、评估、部署。Flok支持通过拖拽操作符快速构建(依照上述分析范式的)数据处理工作流,并拥有180多种内置算法。第二个是AnyLearn,它是一个面向人工智能的机器学习系统,也是一个云原生的系统。Anylearn是为工业领域的专家用户构建的,他们拥有丰富的行业知识,但不是机器学习方面的专家。Anylearn有多种用户友好的GUI界面,如交互式Web界面,Jupyter Notebook和命令行。此外,论是在云上还是在边缘上,Anylearn都能让生产环境中部署模型变得很容易。最后,Anylearn将迁移学习能力作为其固有功能,适用于行业中众多类似场景。Anylearn提供了面向不同领域的算法库,比如天气预报、风力预测以及我们团队研发的迁移学习框架。Anylearn还为工业物联网场景提供了可在安卓和实时Linux操作系统上运行的Anylearn边缘推理引擎,ML模型的推理结果可以与状态图合并(例如,将业务规则和来自实时监控的传感器数据进行合并)。我们在实验室搭建了一个由Anylearn和IoTDB支持的风力预测试验台,传感器就安装在我们学院东配楼楼顶。它通过一个由太阳能供电的树莓派用IoTDB收集传感器数据,利用Anylearn作为引擎提供风力预测服务。风力预测的机器学习模型是在云端训练的。 第三个是一个时序数据库管理系统——IoTDB。这个数据库有三个不同的使用场景。首先,它可以用作终端设备中的一个数据文件,我们提供了高压缩率和简单的写读系统。其次,它可以作为车间级或工厂级的数据库来使用。用作集中控制场景时功能更强大,如资产监控和处理。最后,IoTDB原生支持Spark和Hadoop等大数据分析框架,使得行业更容易开展产业大数据分析,尤其是基于云计算的行业互联网应用。IoTDB项目于2011年启动,起源于帮助三一重工升级其三一企业控制中心系统(ECC),该系统监控全球超过100,000台设备。当时ECC系统将设备数据存储在关系数据库中。然而,系统的性能不满足如车载混凝土泵锁定和柴油被盗检测等应用的需求。在分析研究了这个应用后,我们发现有以下3个主要挑战,1)在工业物联网应用场景中,时间序列的元数据是由终端设备定义的,即新的时间序列可能不需要经过后端注册即可出现。2)在工业物联网场景中,我们应该尽可能接近现场处理数据,这与L0到L4工厂层次结构一致。3)来自于工业互联网的数据通常是关于机器运行状况的数据,信号处理功能会被频繁应用于这类物联网数据集。从2015年开始,我们正式启动IoTDB的新版本开发;2017年我们在GitHub上开源了代码;2018年11月,Apache软件基金会接受IoTDB作为孵化器项目;20个月后,Apache IoTDB成为ASF的顶级项目。为什么要开源?如今,开源已经成为了软件行业及研究领域的创新范式。我们可以回想谷歌研发的安卓——一个移动操作系统,TensorFlow——一个端到端的机器学习开源平台,前者改变了移动互联网世界,而后者使模型易于搭建和部署。此外,开源是高校对外进行技术输出的一种有效手段,例如Spark——用于大规模数据处理的统一分析引擎,Ray——高性能分布式执行框架,它们都来自加州大学伯克利分校。最后,开源对新一代软件人才来说是一种教育平台,在这里他们可以接触到来自现实生活应用的需求,培养出他们在学校里学不到的开发技能。说到开源的选择,为什么选择Apache?因为如果只是把代码公布在Github上,可能最多就是自己玩一玩这个项目。众所周知,Apache软件基金会在过去20年中获得了诸多成就,然而对我们更重要的是Apache的文化。比起代码,他们更相信的是社区——这意味着一个健康的社区比良好的代码更重要。而且,AFS有很好的行为规范,尊重社区中的每一个人。下面我来介绍一下我们的开源实践,我负责教授高年级本科生的数据库课程已经有20年的时间,这个课程的目标是理解关系数据模型、SQL语言、数据库设计方法、DBMS(数据库管理系统)结构及其实现。本课程的项目作业之一是开发一个小型数据库管理系统。我鼓励学生从开源项目(以前在使用HSQL)中学习,并尽最大努力为他们所学习的开源项目做出贡献。此外,在我们学院,软件工程是一门非常重要的学科,这需要较强的实践能力和实践经验。学生参与开源项目之后,会很好地理解敏捷开发的本质和SCRUM项目管理理念。他们还通过单元测试、集成测试和持续集成测试,积累了有关测试驱动的软件开发框架的经验。当他们把代码贡献给社区时,还会用Sonar等检查程序,并在源代码中找出问题。开源平台是一个非常重要的软件工程培训环境。在清华大学软件学院,我们鼓励学生和教师为开源软件项目做出贡献。自2018年起,我们学生奖学金的评选标准有了变化:不仅强调论文发表,还考虑学生对开源项目的贡献,如为项目提交代码(pull requests)、bug修复、提出新想法并被项目采纳等。此外,我们还通过举办开源会议及分享会、高校间项目合作及演讲等方式,积极宣传开源文化。在演讲的最后,我想强调的是:我们的使命是创新工业大数据技术和软件工具以快速方便地创建应用。我们相信无论在中国还是全世界,工业大数据软件及其应用在未来都是一项长期的工作;清华数为软件栈是我们对这个方向的初步探索,也是我们开源之旅的起点。最后,我希望大家关注我们的“清华数为“项目,并邀请大家参与到Apache IoTDB项目的开发建设中来。来源:数学技术学习中心编辑:栗可昱 浏览 80点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 2021 年最佳开源软件榜单C语言题库02021年度最佳开源软件盘点捷达02021 年年度最佳开源软件!简说Python02021 年年度最佳开源软件!Java高效学习0PackOne大数据软件栈部署与管理工具PackOne 致力于实现主流大数据软件在云端的快速弹性部署。通过对云 API 和 Apache APackOne大数据软件栈部署与管理工具PackOne致力于实现主流大数据软件在云端的快速弹性部署。通过对云API和ApacheAmbariAPI的联合调用,完成Hadoop、Spark、NiFi、PiFlow、Kylin、MongoDB、2021年度最佳开源软件榜单出炉!Hollis02021 年 GitHub 最佳开源软件榜单码农有道公众号0Tinypug创新社区软件温馨提示:该项目为开源软件,已停止维护。 Tinypug创新社区软件温馨提示:该项目为开源软件,已停止维护。点赞 评论 收藏 分享 手机扫一扫分享分享 举报




 下载APP
下载APP