
数仓(一)简介数仓,OLTP和OLAP
一、数仓定义
按照传统的定义,数据仓库是一个面向主题的、集成的、非易失的、反映历史变化(随时间变化),用来支持管理人员决策的数据集合。数据仓库是一套数据组织和应用的方法论,是需要很多的支持系统来协助(包含类似数据库这样的存储系统),最后达到支持分析决策的目的。
1、面向主题
关系型数据库
面向事务处理任务,用于记录状态。
数仓
数仓中的数据是按照一定的主题域进行组织,主题是一个抽象的概念,是指用户使用数据仓库进行决策时所关心的重点方面,一个主题通常与多个操作型信息系统相关。每一个主题基本对应一个宏观的分析领域。
比如:银行的数据仓库的主题:客户
关系型数据库
数仓
关系型数据库
数仓
关系型数据库
数仓
关系型数据库
数仓
二、建设数仓的目的
数仓的建设并不是数据存储的最终目的地,而是为数据最终的目的地做好准备:清洗、转义、分类、重组、合并、拆分、统计等等。通过对数据仓库中数据的分析,可以帮助企业,改进业务流程、控制、成本、提高产品质量等。
1、理清数据资产提高排查和开发运维效率
场景:
不知道有什么数据、找谁要数据;
多个系统不同的数据字段的含义
数据如何生成和更新的,数据依赖关系割裂;
2、提高数据质量
场景
字段命名不规范、口径不一致;
条件的过滤和规则等的理解差异带来的算法不一致;
3、数据解耦
场景
上下游依赖混乱
复杂问题耦合在一起
每次从原始数据取数,数据开发周期长
业务数据轻微改动带来的变更过大,无中间表加工
4、解决频繁的临时性需求
场景
报送监管历史数据
临时数据需要交叉
虽然数仓建设能带来诸多的益处,但数仓的建设不是一天建成的,是一个庞大复杂耗时的工程,需要很多支持系统的配合:元数据管理系统、调度系统等,要根据业务发展所处的状态和未来的发展趋势以及分析决策的复杂性等综合来搭建。
总结:
了解数仓的特点;
了解建设数仓的目的意义,能解决什么问题等
还介绍了建立数仓的目的:数仓的建设并不是数据存储的最终目的地,而是为数据最终的目的地做好准备:清洗、转义、分类、重组、合并、拆分、统计等等。通过对数据仓库中数据的分析,可以帮助企业,改进业务流程、控制、成本、提高产品质量等。
下面介绍一下两个重要的数据处理的类型OLTP和OLAP,并通过比对总结,从而更好的理解两种数据处理类型。
三、数据处理“分家”
随着关系型数据库理论的提出,诞生了一系列经典的RDBMS,如DB2、Oracle,SQL Server、MySQL等。随着数据库使用范围的不断扩大,根据操作业务不同类型,被逐步划分为两大处理的类型:
1、处理业务型数据库
主要用于业务支撑。比如:银行往往会使用并维护若干个数据库,这些数据库保存着日常操作数据,如理财购买、核心系统、信用卡数据、内部管理系统等。
2、分析历史数据型数据库
主要用于历史数据分析。这类数据库作为公司的单独数据存储,利用历史数据对公司各主题域进行统计分析。比如:银行对客户AUM统计、对征信的统计评估等。
为什么要分家?
能不能构建一个同样适用于操作和分析的统一数据库?目前的解决方案是不适合!
因为数据之间会"打架";
如果操作型任务和分析型任务抢资源怎么办呢?
同时处理数据怎么保证数据一致性呢?
后面我们会分析这两个类型是完全不一样的操作。即一个是面向操作即OLTP一个是面向分析(主题)即OLAP。
1、函数依赖

完全函数依赖
部分函数依赖
传递函数依赖
第一范式:属性不可切分
第二范式:不能存在"部分函数依赖"

第三范式:不能存在"传递函数依赖"

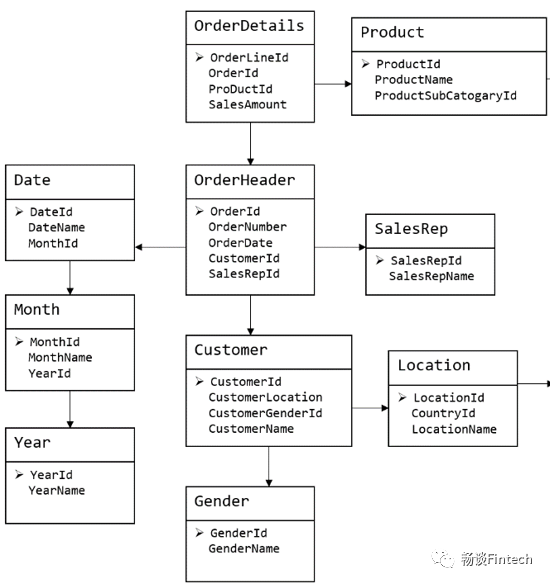
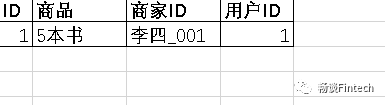
从上面这个建模客户表图中可以看出,物理表数量多,而数据冗余程度低;
数据分布于众多的表中;
这些数据可以更为灵活地被应用,功能性较强;
但是一次修改,需要修改多个表,很难保证数据的一致性;
并且获取数据时候,需要通过join拼接出最后的数据。
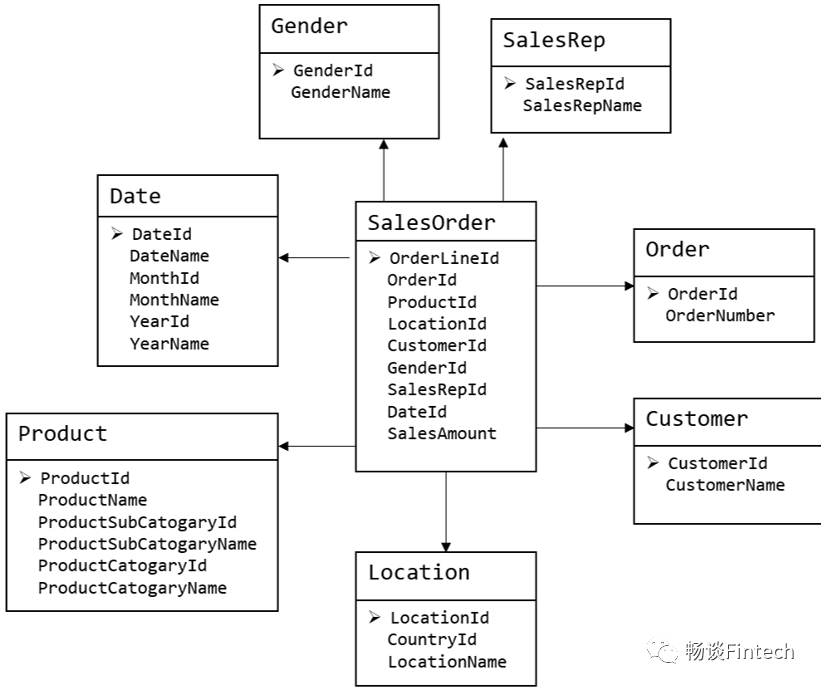
上图为维度模型建模片段,主要应用于 OLAP 系统中; 通常以某一个事实表为中心进行表的组织,主要面向业务,特征是可能存在数据的冗余,但是能方便的得到数据。
了解数据库的三范式 OLTP和OLAP两种数据处理类型; 通过对比加深对OLAP的认知;
>>>>
Q&A
MySQL是作为OLTP数据库使用的。但是也能执行一些OLAP操作,比如里面8.0包括窗口函数,通用表达式和更强大的Join能力,但这不是MySQL擅长的领域。 OLTP和OLAP都是通过SQL来执行,但SQL语句只是描述了我想要什么,而并没有说明应该怎么做(不考虑hint等),即确定最优的执行计划。由于一般OLTP操作比较简单,所涉及的表也少,因此不需要相应的数据库具有强大的执行优化能力。 OLAP类操作需要强大的执行计划产生和优化能力。 当然,如果总数据量较小,那MySQL也是能够应付的。数据量大,需要OLAP解决方案。
数据仓库第4版 DAMA数据管理知识体系指南 华为数据之道