
Flink 在伴鱼的实践:如何保障数据的准确性
随着伴鱼业务的快速发展,离线数据日渐无法满足运营同学的需求,数据的实时性要求越来越高。之前的实时任务是通过实时同步至 TiDB 的数据,利用 TiDB 进行微批计算。随着越来越多的实时场景涌现出来,TiDB 已经无法满足实时数据计算场景,计算和查询都在一套集群中,导致集群压力过大,可能影响正常的业务使用。根据业务形态搭建实时数仓已经是必要的建设了。伴鱼实时数仓主要以 Flink 为计算引擎,搭配 Redis ,Kafka 等分布式数据存储介质,以及 ClickHouse 等多维分析引擎。
伴鱼实时作业应用场景
基于平台提供了稳定的环境 (统一调度方式,统一管理,统一监控等)。我们构建了一些实时服务,通过服务化的方式去支持各个业务方。
实时数仓:数据同步,业务数据清洗去重,相关主题业务数据关联拼接,以及数据聚合提炼等,逐步构建多维度,多覆盖面的实时数仓体系。
实时特征平台:实时数据提取,计算,以及特征回写。
简单介绍下:目前数据在伴鱼内的流动架构图:
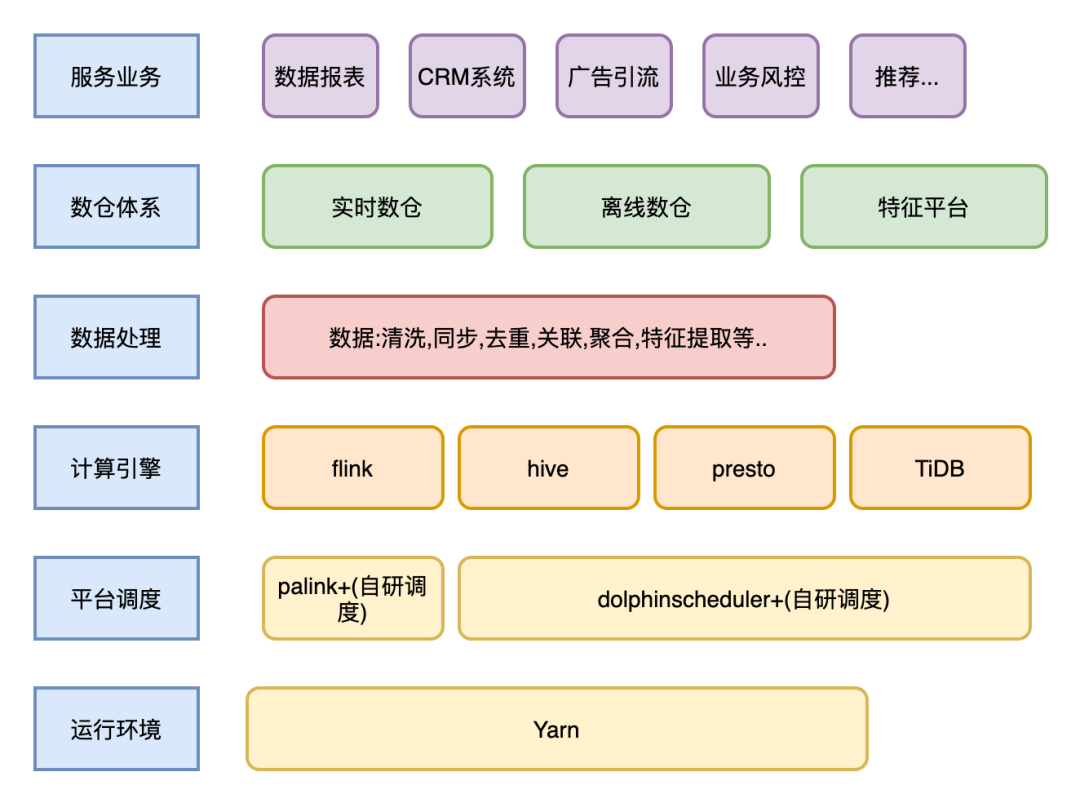
下面主要介绍伴鱼实时数仓的建设体系:
ODS 层数据平台统一进行数据解析处理, 写入 Kafka 。
DWD 比较关键,会将来自同一业务域数据表对应的多条数据流,按最细粒度关联成一条完整的日志,并关联相应维度,描述一个完整事实。
DWS 将每个小业务域数据按相同维度进行聚合,写入 TiDB 和 ClickHouse 。在 TiDB ,ClickHouse ,再次进行关联,形成跨业务域聚合数据。供业务和分析人员使用。
如图:
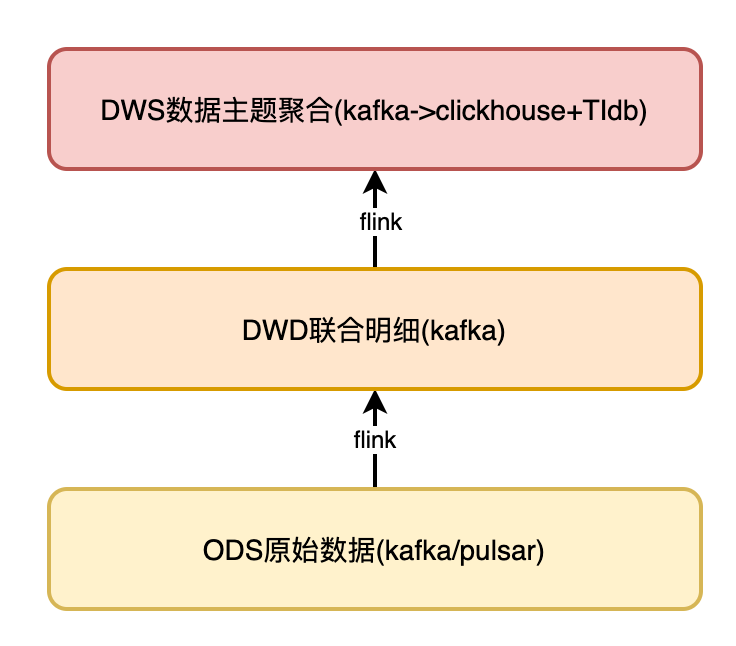
DWD 层复杂场景数据处理方案
数据从 ODS 层采集后,数据的处理和加工主要集中在 DWD 层,我们的场景中面临了很多复杂的加工逻辑,本章重点对 DWD 层数据处理方案进行详细的阐述。
1. 数据的去重
由于伴鱼内部业务大面积使用 MongoDB ,MongoDB 本身存储的是半结构化的数据,它不具有固定的 schema 。在同步 Mongo 的 oplog 时,实时数仓的 dwd 层并不需要所有字段参与,我们只会抽取日常使用率相对较高的字段进行表建设。这就可能由于不相干的数据发生变化,我们也会收到一条相同的数据记录。例如在对用户订单金额进行分类分析时,如果用户订单地址发生了变化,我们同样也会收到一条业务日志,因为我们并不关注地址维度,所以这条日志是无用的重复数据。这种未经处理的数据是不方便 BI 工程师直接使用的,甚至直接影响计算结果的准确性。所以我们针对这种非 Append-only 数据,我们进行了定制化的日志格式。在经由平台方解析后的 binlog 或者 oplog ,我们仍然定制化加入了一些元数据信息,用来让 BI 工程师更好的理解这条数据进入实时计算引擎时,对应的时间点到底发生了什么事情,这件实事到底是否参与计算。所以,我们加入了 metadata_table (原始表名), metadata_changes(修改字段名) , metadata_op_type (DML 类型) ,metadata_commit_ts (修改时间戳) 等字段,辅助我们对业务上认为的重复数据,做更好的过滤。
如图:

2. join 场景
实时计算相较于离线不同,因为数据具有一过性,流过的数据,如果不做特殊记录,很难在找回,从而降低了实时作业准确性,这是实时计算的一个痛点问题,这个问题主要表现在多流关联时,数据难以关联准确,下面叙述一下在伴鱼内部,多流 join 的场景是如何解决的。数据关联常用的 inner join ,left join 。inner join 近似可以看做 left join + where 的操作。
从时间角度来讲分为:
两条实时数据流相关联。
实时流与过去发生的事实数据相关联。
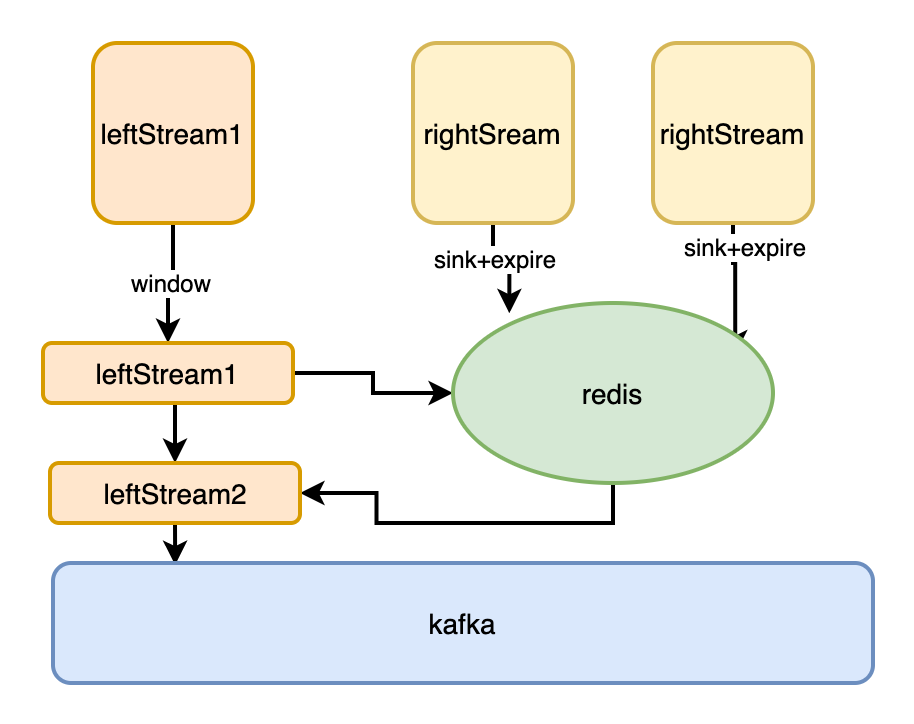
两条实时数据流相关联
利用 Redis 基于内存,支持单位时间大量 QPS ,快速访问的特性:
首先我们应观察一定范围内数据,观察数据在时间维度上的乱序情况. 设定数据延迟的时间和数据缓存时间。
伴鱼的服务都相对较稳定,数据乱序最多就是秒级差异,我们通常选择数据量相对大的流做主流,对主数据流加窗口等待 (窗口时间不必太长,如 10s), 右边数据流将数据写入 Redis 缓存 (分钟级),当主流的窗口到期,确保右边流数据以及缓存在 Redis 中了。实现在 Flink job 内部多 Operator 之间的内存共享。这种方式的优点是:足够简单,通用 ; Flink job 无需维护业务状态,job 轻量化、运行稳定。缺点是,随着数据量的上升,以及 job 的增多,会对 Redis 集群造成较大压力。
如图:
Flink 作业内部,提供了完整的 user-state 状态管理,包括状态初始化,状态更新,状态快照,以及状态恢复等:
将数据 leftStream 与 rightStream 分别打上不同的 tag ,将 leftStream 与 rightStream 用 contect 算子联合在一起。对 join 的条件进行 group by 操作,相同分组的数据,在 precess 算子内进行数据的 state 缓存与输出。下游得到的即为能关联上的数据。
对状态操作的同时,调用定时器,比如我们可以按天为单位,每天凌晨设置定时器,清空状态,具体定时器触发策略,看业务场景。
优点: 整个作业所有处理逻辑不依赖其他外部存储系统,均在 Flink 内部计算。
缺点: 如果多个数据流关联,整体作业 code 量较大,开发成本相对较高;数据交由 Flink 状态维护,整个作业内存负载较高,数据量大的情况下,checkpoint 很大,对作业整体稳定运行有影响。
Flink 社区已经认识到多流 join 的痛点问题,提供了区别于离线 sql 的特殊 join 方式:
对 leftStream 与 rightStream 分别注册 Watermark (最好用事件时间)。
将 leftStream 与 rightStream 进行 Interval Join。(在流与流的 join 中, window join 只能关联两个流中对应的 window 中的消息,跨窗口的消息关联不上,所以摒弃。Interval Join 则没有 window 的概念,直接用时间戳作为关联的条件,更具表达力。Interval join 的实现基本逻辑比较简单,主要依靠 TimeBoundedStreamJoin 完成消息的关联,其核心逻辑主要包含消息的缓存,不同关联类型的处理,消息的清理,但实现起来并不简单。一条流中的消息,可能需要和另一条流的多条消息关联,因此流流关联时,通常需要类似如下关联条件:)。
优点: 编码简单;整个作业 state 的修改访问由 Flink 源码自动完成,整体 state 负载与用户手动编码相对较小。
缺点: 特殊 join 方式受场景限制较大。
如图:

Flink Table & SQL 时态表 Temporal Table:
在 Flink 中,从 1.7 开始,提出了时态表 (即 Temporal Table ) 的概念。Temporal Table 可以简化和加速此类查询,并减少对状态的使用 Temporal Table 是将一个 Append-Only 表中追加的行,根据设置的主键和时间 (如上 productID 、updatedAt ),解释成 Chanlog,并在特定时间提供数据的版本。
在使用时态表 ( Temporal Table ) 时,要注意以下问题。
Temporal Table 可提供历史某个时间点上的数据。Temporal Table 根据时间来跟踪版本。Temporal Table 需要提供时间属性和主键。Temporal Table 一般和关键词 LATERAL TABLE 结合使用。Temporal Table 在基于 ProcessingTime 时间属性处理时,每个主键只保存最新版本的数据。Temporal Table 在基于 EventTime 时间属性处理时,每个主键保存从上个 Watermark 到当前系统时间的所有版本。表 Join 右侧 Temporal Table ,本质上还是左表驱动 Join ,即从左表拿到 Key ,根据 Key 和时间 (可能是历史时间) 去右侧 Temporal Table 表中查询。Temporal Table Join 目前只支持 Inner Join。Temporal Table Join 时,右侧 Temporal Table 表返回最新一个版本的数据。
例如:
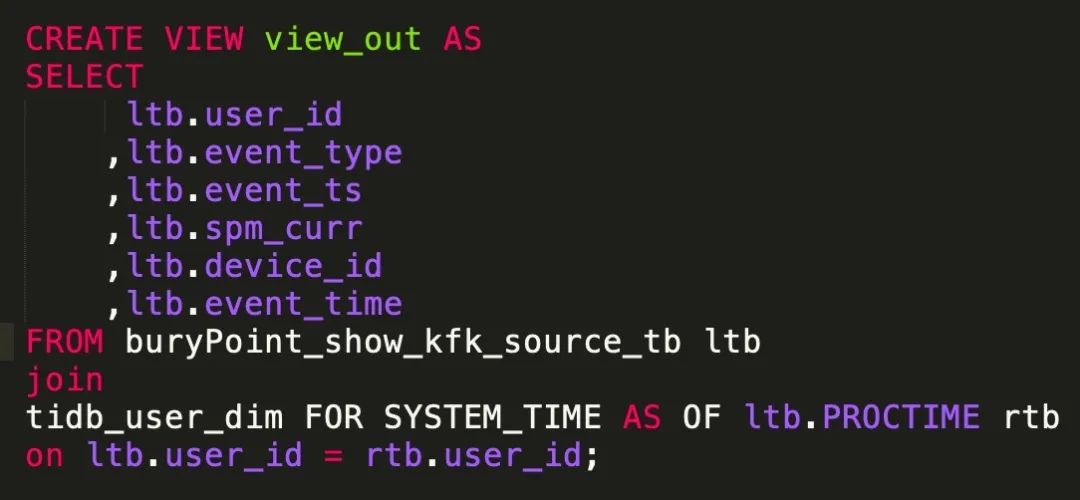
对于关联历史数据
我们首先要分析历史数据的过期性,例如伴鱼业务场景中,用户约课行为和用户在线上课两条数据流关联到的数据,可能相差几天 (用户提前约下周的课程)。此时数据的过期时间就需要我们特殊关系与处理,我们可以精确的计算先发生的事件,它的准确过期时间,例如:例如正式上课时间为三天后,所以,我们可将他们放入 Redis 中缓存 (3+1)*24 h, 以确保用户上课时,他们的约课记录还仍然在我们内存中预热。 如果无法判断出历史数据的过期性。例如在伴鱼的业务场景中,经常会关联用户某个重要行为 (下单) 时,对用的用户等级,以及绑定的教师等细节信息,类似这种常用且重要的维度,我们只能将它们永久缓存在 Redis 中,供事实数据去访问关联。
3. 从数据形态观查 join
从数据 join 的方式来看,共分为三种,一对一,多对一, 多对多三种情形。
对于一对一,多对一,我们只需要用 Redis 或者 state 缓存住单一一方的数据流。 对于多对多的 join 情形:多对多的 join。我们只能将 leftStream 与 rightStream 先 connect 连接起来,天级别的 将数据分别缓存至 Redis 或者 job momery 中。无论 left Steam 还是 right Stream,数据来了都是统一先缓存,去遍历另一方的所有已经到来的数据,输出到下游。 对于多对多的 left join 情形:多对多的 left join 的场景,是比较复杂的,我们也只能将 leftStream 与 rightStream 先 connect 连接起来,将其缓存在 job momery 或者 Redis 中,leftSteam 或者 rightStream 数据来了就先统一先缓存,再去遍历另一方的所有已经到来的数据,输出到下游。只不过此时,对于下游没有 join 上的数据,并不能很好的判断 数据到底是真的没有 join 上,还是因为数据进入 Operator 的时间性的差异,没有 join 上。此时我们会将数据写入 TiDB ,或者 ClickHouse 中,在这种可以基于天级别数据量快速计算的 OLAP 引擎中,对因进入 Operator 算子时间差异而导致没有 join 上的数据进行过滤。 注意如果用 Flink Operator State,需要设置定时器,或者使用 Flink TTL,对 state 定时清理,不然程序会 OOM 。如果使用 Redis ,需要对数据设置失效或者定时调用离线脚本对数据进行删除。
DWS 数据层数据处理方案
我们在离线数仓中通常存放的是跨业务域的粗粒度数。在伴鱼的实时数仓内部,我们也同样是这样存储的。只不过跨业务域的数据之间的关联,我们不在 Flink 实时处理引擎中做计算。而是把它们放到 TiDB 或者 ClickHouse 中做计算了。在 Flink 内存,我们只计算当前业务域的聚合指标,以及会对数据进行 tag 标记,标记出数据是按哪些维度聚合而来,聚合粒度是如何的。(例如时间粒度上,我们通常会以 5min 或者 10min 为小单位对数据进行聚合),如果要查询当天跨业务的联合数据时,会基于 TiDB 或者 ClickHouse 预先定义好视图,在视图内先对当天单个业务域主题内数据先做聚合 sum ,再将不同业务域的数,按提前在数据中标记的维度 tag 进行关联,得到跨业务的聚合指标。
未来与展望
未来我们仍会继续对比 Storm, Spark Streaming, Flink 等多种技术栈产品在使用和性能上的利弊。期待 Flink 生态的丰富,我们会尝试让 Flink CDC,Flink ML,Flink CEP 等一些特性发挥在我们的数仓建设中。 Flink SQL 最近几个版本的迭代也是相当频繁的。由于阿里对 Flink planner 的支持,使 Flink 的批流一体的概念更加趋近于现实,我们会尝试使用 Flink 作为离线数仓的处理引擎,在公司数据组推开 Flink SQL 。 继续完善实时平台对 Flink 任务的监控,以及资源管理的优化。
作者:李震
原文:https://tech.ipalfish.com/blog/2021/06/29/flink_practice/
原文:Flink 在伴鱼的实践:如何保障数据的准确性
来源:伴鱼技术博客
转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。