
【React】1087你不知道的 React Virtual DOM

什么是 Virtual DOM ?
在前端技术蓬勃发展的上古时代,前端开发主要是一些静态页面,使用 ajax、jQuery 等命令式的完成一些对 DOM 的操作,而伴随着前端工程化的不断发展,涌现了诸如 angular、react 等一系列 MVVM 模式的前端框架,这些框架公有的特点就是不再关心具体 DOM 的操作,而是把重点放在了基于数据状态的操作,一旦数据更改,跟它绑定的那个地方的 DOM 也会跟着变化。这种声明式的开发方式极大的增加了开发体验,更好的帮助我们完成组件复用、逻辑解耦等。
借助于上面提到的前端框架,我们不用再主动的对 DOM 进行操作,框架在背后已经替我们做了,我们只需要关心应用的数据即可。而Virtual DOM(虚拟 DOM)的概念就是在此期间由于其在React框架中的使用而变得流行起来。那么到底什么是Virtual DOM呢?
引用 react 官网上的介绍:
Virtual DOM 是一种编程概念。在这个概念里, UI 以一种理想化的,或者说“虚拟的”表现形式被保存于内存中,并通过如 ReactDOM 等类库使之与“真实的” DOM 同步。这一过程叫做协调。
这种方式赋予了 React 声明式的 API:您告诉 React 希望让 UI 是什么状态,React 就确保 DOM 匹配该状态。这使您可以从属性操作、事件处理和手动 DOM 更新这些在构建应用程序时必要的操作中解放出来。
总结来说,理解 Virtual DOM 的含义主可以从以下几点出发:
虚拟 DOM 并不是真实的 DOM,它跟原生 DOM 本质上没什么关系。 本质上 Virtual DOM 对应的是一个 JavaScript 对象,它描述的是视图和应用状态之间的一种映射关系,是某一时刻真实 DOM 状态的内存映射。 在视图显示方面,Virtual DOM 对象的节点跟真实 DOM Tree 每个位置的属性一一对应。 我们不再需要直接的操作 DOM,只需要关注应用的状态即可,操作 DOM 的事情有框架替我们做了。

为什么要用 Virtual DOM ?
我们经常会说到真实的 DOM 操作代价昂贵,操作频繁还会引起页面卡顿影响用户体验,而虚拟 DOM 就是为了解决这个浏览器性能问题才被创造出来。
在介绍 Virtual DOM 有什么好处以及为什么要使用它之前,我们先来了解下为什么会说 DOM 操作是耗费性能的?
操作 DOM 是耗费性能的
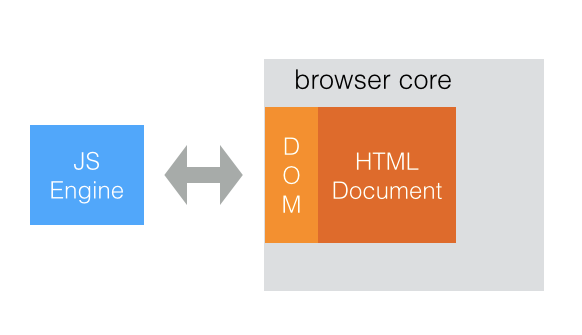 首先我们要明白一点,DOM 并不属于 JavaScript 语言的一部分,它是 JavaScript 的运行平台(浏览器)提供的,比如在 nodejs 中就没有 DOM。浏览器中的 DOM 对应的是 HTML 页面中的元素节点,它本身和 JS 对象没有什么关联,但是 webkit 渲染引擎和 JS 引擎之间通过 V8 Binding 在 V8 内部会把原生 DOM 对象映射为 JS 对象,我们称之为 Wrapper objects(包装对象)。因此,我们平时在写代码时,操作 DOM 对象就是操作的这种包装对象,和操作 JS 对象是一样的。下图为浏览器和 JS 引擎的关系(以 Chrome 和 V8 举例,其他浏览器也大同小异)。
首先我们要明白一点,DOM 并不属于 JavaScript 语言的一部分,它是 JavaScript 的运行平台(浏览器)提供的,比如在 nodejs 中就没有 DOM。浏览器中的 DOM 对应的是 HTML 页面中的元素节点,它本身和 JS 对象没有什么关联,但是 webkit 渲染引擎和 JS 引擎之间通过 V8 Binding 在 V8 内部会把原生 DOM 对象映射为 JS 对象,我们称之为 Wrapper objects(包装对象)。因此,我们平时在写代码时,操作 DOM 对象就是操作的这种包装对象,和操作 JS 对象是一样的。下图为浏览器和 JS 引擎的关系(以 Chrome 和 V8 举例,其他浏览器也大同小异)。
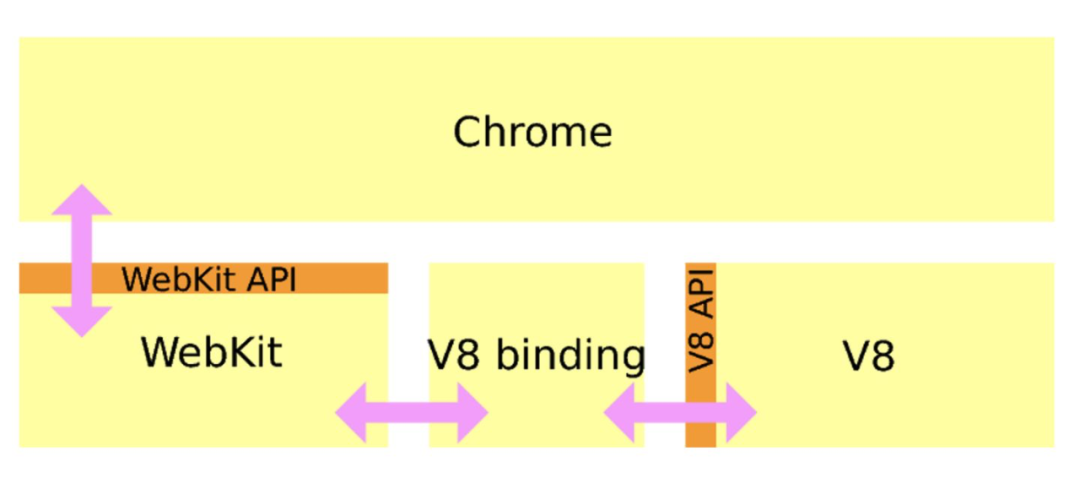
由于 JS 是可操纵 DOM 的,如果在修改这些元素属性同时渲染界面(即 JS 线程和渲染线程同时运行),那么渲染线程前后获得的元素数据就可能不一致了。因此为了防止渲染出现不可预期的结果,浏览器设置 渲染线程 与 JS 引擎线程 为互斥的关系,当 JS 引擎执行时渲染线程会被挂起,GUI 更新则会被保存在一个队列中等到 JS 引擎线程空闲时立即被执行。
因此我们在操作 DOM 时,任何 DOM API 调用都要先将 JS 数据结构转为 DOM 数据结构,再挂起 JS 引擎线程并启动渲染引擎线程,执行过后再把可能的返回值反转数据结构,重启 JS 引擎继续执行。这种两个线程之间的上下文切换势必会很耗性能。
另外很多 DOM API 的读写都涉及页面布局的 重绘(repaint)和回流(reflow),这会更加的耗费性能。
综上所述,单次 DOM API 调用性能就不够好,频繁调用就会迅速积累上述损耗,但我们又不可能不去操作 DOM,因此解决问题的本质是要 减少不必要的 DOM API 调用。
Virtual DOM 有什么优势?
很多人一谈到 Virtual DOM 的优势就会说 “原生 DOM 操作太慢了,virtual DOM 更快些”,首先我们要认识到一点:没有任何框架可以比纯手动的优化 DOM 操作更快,因为框架的 DOM 操作层需要应对任何上层 API 可能产生的操作,它的实现必须是普适的。框架的意义在于为你掩盖底层的 DOM 操作,让你用更声明式的方式来描述你的目的,从而让你的代码更容易维护。
React 也从来没有说过 “React 比原生操作 DOM 快”。并不是说 Virtual DOM 操作一定是比原生 DOM 操作快,这和具体的页面模板大小和数据的变动量都有关系的 但是相比于操作 DOM,原生的 js 对象操作起来的确是会更快、更简单。
React.js 相对于直接操作原生 DOM 最大的优势在于 batching 和 diff。为了尽量减少不必要的 DOM 操作, Virtual DOM 在执行 DOM 的更新操作后,不会直接操作真实 DOM,而是根据当前应用状态的数据,生成一个全新的 Virtual DOM,然后跟上一次生成 的 Virtual DOM 去 diff,得到一个 Patch,这样就可以找到变化了的 DOM 节点,只对变化的部分进行 DOM 更新,而不是重新渲染整个 DOM 树,这个过程就是 diff。还有所谓的batching就是将多次比较的结果合并后一次性更新到页面,从而有效地减少页面渲染的次数,提高渲染效率。batching 或者 diff, 说到底,都是为了尽量减少对 DOM 的调用。简要的示意图如下:
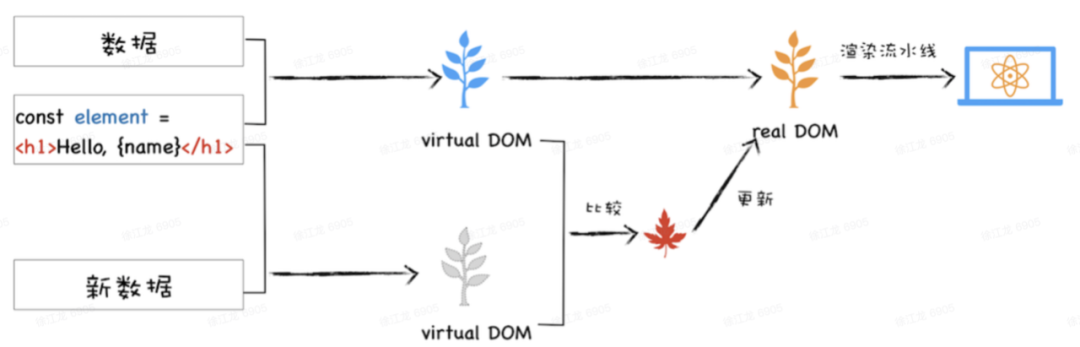
因此总结下关于 Virtual DOM 的优势有哪些:
为函数式的 UI 编程方式打开了大门,我们不需要再去考虑具体 DOM 的操作,框架已经替我们做了,我们就可以用更加声明式的方式书写代码。 减少页面渲染的次数,提高渲染效率。 提供了更好的跨平台的能力,因为 virtual DOM 是以 JavaScript 对象为基础而不依赖具体的平台环境,因此可以适用于其他的平台,如 node、weex、native 等。
附上知乎上尤雨溪 对于 Virtual DOM 的优势的回答[1]
Virtual DOM 是如何实现的
引用 React 官网关于 Virtual DOM 的一段话:
与其将 “Virtual DOM” 视为一种技术,不如说它是一种模式,人们提到它时经常是要表达不同的东西。在 React 的世界里,术语 “Virtual DOM” 通常与React 元素[2]关联在一起,因为它们都是代表了用户界面的对象。而 React 也使用一个名为 “fibers” 的内部对象来存放组件树的附加信息。上述二者也被认为是 React 中 “Virtual DOM” 实现的一部分。
下面的部分我们就来分别看看 ReactElement 和 Fiber 是什么东西。
ReactElement
我们前面说了本质上 Virtual DOM 对应的是一个 JavaScript 对象,那么 React 是如何通过一个 js 对象将 Virtual DOM 和真实 DOM 对应起来的呢?这里面的关键就是 ReactElement。
ReactElement 即 react 元素,描述了我们在屏幕上所看到的内容,它是构成 React 应用的最小单元。比如下面的 jsx 代码:
const element = <h1 id="hello">Hello, world</h1>
上面的代码经过编译后其实生成的代码是这样的:
React.createElement("h1", {
id: "hello"
}, "Hello, world");
执行 React.createElement 函数,会返回类似于下面的一个 js 对象,这个对象就是我们所说的 React 元素:
const element = {
type: 'h1',
props: {
id: 'hello',
children: 'hello world'
}
}
React 元素也可以是用户自定义的组件:
function Button(props) {
return <button style={{ color }}>{props.children}</button>;
}
const buttonComp = <Button color="red">点击我</Button>
编译后的代码如下:
React.createElement("Button", {
color: "red"
}, "点击我");
因此我们就可以说 React 元素其实就是一个普通的 js 对象(plain object),这个对象用来描述一个 DOM 节点及其属性 或者组件的实例,当我们在 JSX 中使用 Button 组件时,就相当于调用了React.createElement()方法对组件进行了实例化。由于组件可以在其输出中引用其他组件,当我们在构建复杂逻辑的组件时,会形成一个树形结构的组件树,React 便会一层层的递归的将其转化为 React 元素,当遇见 type 为大写的类型时,react 就会知道这是一个自定义的组件元素,然后执行组件的 render 方法或者执行该组件函数(根据是类组件或者函数组件的不同),最终返回 描述 DOM 的元素进行渲染。
我们来看下 React 源码中关于 ReactElement 和 createElement 方法的实现:
var ReactElement = function (type, key, ref, self, source, owner, props) {
var element = {
// This tag allows us to uniquely identify this as a React Element
$typeof: REACT_ELEMENT_TYPE,
// Built-in properties that belong on the element
type: type,
key: key,
ref: ref,
props: props,
// Record the component responsible for creating this element.
_owner: owner
};
// do somethings ....
return element;
}
function createElement(type, config, children) {
var propName; // Reserved names are extracted
var props = {};
var key = null;
var ref = null;
var self = null;
var source = null;
if (config != null) {
if (hasValidRef(config)) {
ref = config.ref;
{
warnIfStringRefCannotBeAutoConverted(config);
}
}
if (hasValidKey(config)) {
key = '' + config.key;
}
self = config.__self === undefined ? null : config.__self;
source = config.__source === undefined ? null : config.__source; // Remaining properties are added to a new props object
for (propName in config) {
if (hasOwnProperty.call(config, propName) && !RESERVED_PROPS.hasOwnProperty(propName)) {
props[propName] = config[propName];
}
}
} // Children can be more than one argument, and those are transferred onto
// the newly allocated props object.
//....
return ReactElement(type, key, ref, self, source, ReactCurrentOwner.current, props);
从上面的源码中可以看出:
ReactElement 是通过 createElement 函数创建的。 createElement 函数接收 3 个参数,分别是 type, config, children
type 指代这个 ReactElement 的类型,它可以是 DOM 元素类型,也可以是 React 组件类型。 config 即是传入的 元素上的属性组成的对象。 children 是一个数组,代表该元素的子元素。
为了更加清楚的表示,我们通过在控制台打印出整个 ReactElement 对象来看看它的真实的结构:
<div className="box" id="name" key="uniqueKey" ref="boxRef">
<h1>header</h1>
<div className="content">content</div>
<div>footer</div>
</div>
它最终会生成下面这样的一个对象:

$$typeof 是一个常量 REACT_ELEMENT_TYPE,所有通过 React.createElement 生成的元素都有这个值,用来表示这是一个 React 元素。它还有一个取值,通过 createPortals 函数生成的 $$typeof 值就是 REACT_PORTAL_TYPE。 key 和 ref 从 config 对象中作为一个特殊的配置,被单独抽取出来,放在 ReactElement 下。 props 包含了两部分,第一部分是去除了 key 和 ref 的 config,第二部分是 children 数组,数组的成员也是通过 React.createElement 生成的对象。 _owner 就是 Fiber,这个我们后面会讲到。
通过上面这些属性,React 就可以用 js 对象把 DOM 树上的结构信息、属性信息轻易的表达出来了。
React Fiber
Stack reconciler
React 15 及更早的 reconciler 架构可以分为两层:
Reconciler(协调器): 负责找出变化的组件,通常将这时候 的 reconciler 称为 stack reconciler。 Renderer(渲染器): 负责将变化的组件渲染到页面上。 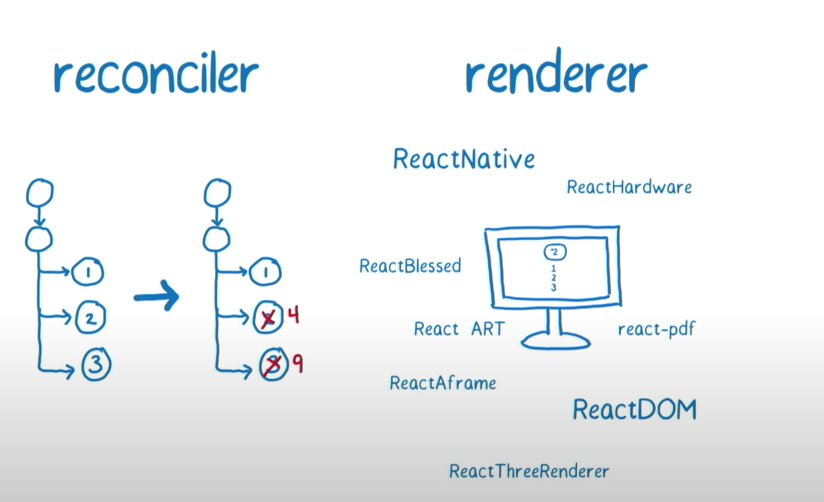
每当有状态更新时,Reconciler会做如下工作:
调用函数组件、或 class 组件的 render 方法,将返回的 JSX 转化为 Virtual DOM。 将 Virtual DOM 和上次更新时的 Virtual DOM 对比。 通过对比找出本次更新中变化的 Virtual DOM 通知 Renderer 将变化的 Virtual DOM 渲染到页面上,由于 React 支持跨平台,所以不同平台有不同的 Renderer。
它的工作流程很像是函数调用的方式,一旦 setState 之后,便开始从父节点开始递归的进行遍历,找出 Virtual DOM 的不同。在将所有的 Virtual DOM 遍历完成之后,React 才能给出当前需要更新的 DOM 信息。这个过程是个同步的过程。对于一些特别庞大的组件来说,js 执行会占据很长的主线程时间,这样会导致页面响应速度变慢,出现卡顿等现象,尤其是在动画显示上,很可能会出现丢帧的现象。
那么为什么 Stack reconsiler 会导致丢帧呢?我们来看一下一帧都做了什么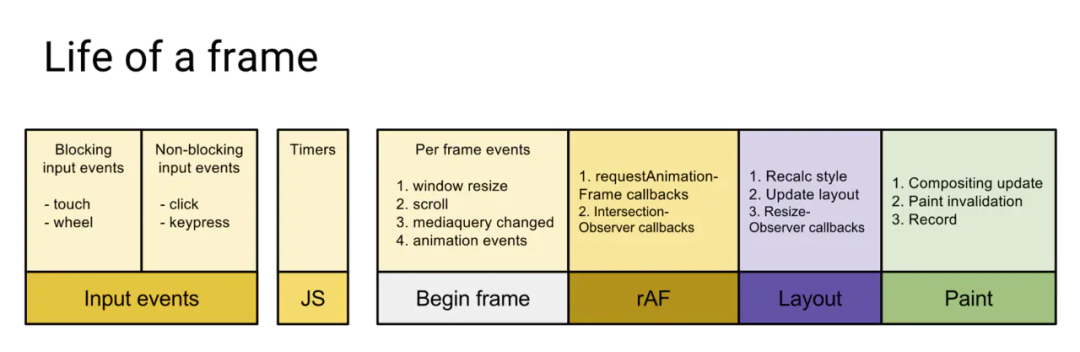
在上面的图中,我们可以看出一帧包括了用户的交互行为的处理、js 的执行、requestAnimationFrame 的调用、layout 布局、paint 页面重绘等工作,假如某一帧里面要执行的任务不多,在不到 16ms(1000/60=16)的时间内就完成了上述任务的话,页面就会正常显示不会出现卡顿的现象,但是如果一旦 js 执行时间过长,超过了 16ms,这一帧的刷新就没有时间执 layout 和 paint 部分了,就可能会出现页面卡顿的现象。
Fiber reconciler
我们仔细考虑,其实对于视图来说,同步的改变并不是一种好的解决方案,主要有以下几点考虑:
并不是所有的状态更新都需要立即同步显示,比如可视范围之外的部分的更新。 不同类型的更新的优先级是不一样的,比如对用户输入的响应一般是要比 ajax 请求的响应优先级高的。 理想情况下,对于某些高优先级的操作,应该是可以打断低优先级的操作执行的,比如用户输入时,页面的某个评论还在 reconciliation,应该优先响应用户输入。
为了解决上面的 stack reconciler 中固有的问题,react 团队重写了核心算法 --reconciliation[3],即 fiber reconciler(两者之间效果对比更直观的感受可以看下这个demo[4])。fiber reconciler 的架构在原来的基础上增加了 Scheduler(调度器)的概念:
Scheduler(调度器): 调度任务的优先级,高优任务优先进入Reconciler。
上面我们在讲一帧的过程的时候提到,假如某一帧里面要执行的任务不多,在不到 16 ms 的时间内就完成了任务,那么这一帧就有空闲时间,我们就可以利用这个空闲时间用来执行低优先级的任务,浏览器有个 api 叫requestIdleCallback,就是指在浏览器的空闲时段内调用的一些函数的回调。React 实现了功能更完备的 requestIdleCallbackpolyfill,这就是Scheduler。除了在空闲时触发回调的功能外,Scheduler还提供了多种调度优先级供任务设置。Scheduler 主要决定应该在何时做什么,它在接收到更新后,首先看看有没有其它高优先级的更新需要先执行,如果有就先执行高优先级的任务,等到空闲期再执行此次更新;如果没有则将此次任务交给 reconciler 。
Fiber Nodes
还记得前面在讲 ReactElement 时在控制台打印出的对象里面有个 _owner 对象吗,它就是我们说到的 Fiber 节点。当一个 React Element 第一次被转换为 fiber 节点的时候, React 将会从 React Element 中提取数据并在在createFiberFromTypeAndProps[5]函数中创建一个新的 fiber 节点。Fiber 的主要目标是使 React 能够利用调度。具体来说,我们需要能够
暂停工作,稍后回来 给不同类型的工作分配优先级 重用之前已经完成的工作 当工作不再需要时取消
为了做到这一点,我们首先需要一种将工作分解为单元的方法。从某种意义上说,这就是 Fiber。Fiber 代表一种工作单位。React 会为每个得到的 React Element 创建 fiber,这些 fiber 节点被连接起来组成 fiber tree。每个 fiber 对应一个 React Element,保存了该元素的类型、对应的 DOM 节点、本次更新中的该元素改变的状态、要执行的任务(删除、插入、更新)等信息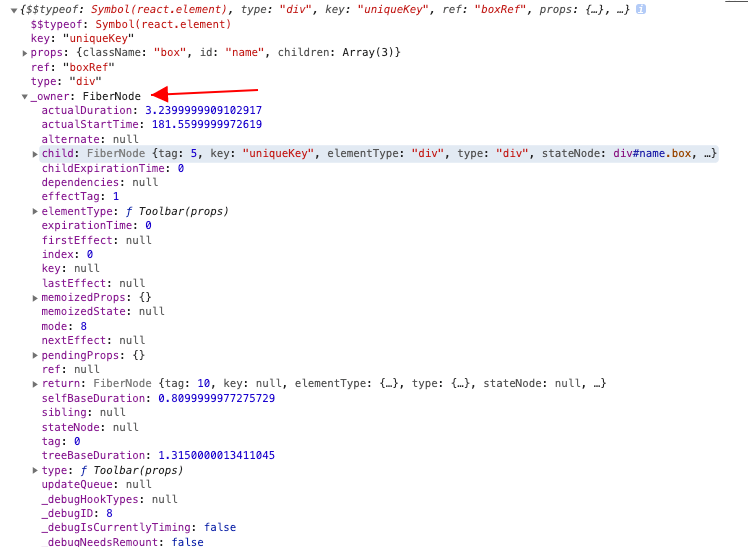
我们看一下 React 源码中 FiberNode 构造函数的部分:
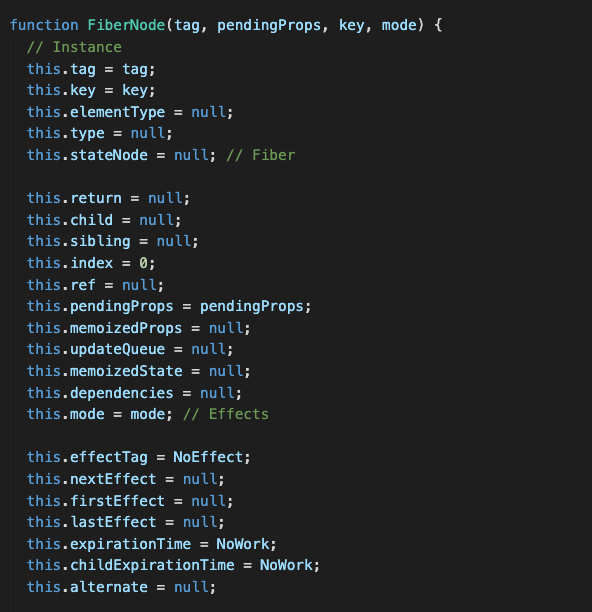
type 和 key 与 React 元素的用途相同,React 通过它们来判断 Fiber 是否可以重复使用。
stateNode 是 Fiber 对应的真实 DOM 节点。
多个 fiber 节点中是怎么连接形成 fiber tree 的呢?主要靠以下三个属性:
return:指向父级 Fiber 节点; child:指向子级 fiber 节点; sibling:指向右边第一个兄弟 fiber 节点; 
在 React Fiber 中,一次更新过程会分成多个分片完成,所以完全有可能一个更新任务还没有完成,就被另一个更高优先级的更新过程打断,这时候,优先级高的更新任务会优先处理完,而低优先级更新任务所做的工作则会完全作废,然后等待机会重头再来。因为一个更新过程可能被打断,所以 React Fiber 一个更新过程被分为两个阶段(Phase):第一个阶段Reconciliation Phase****和第二阶段Commit Phase。在第一阶段 Reconciliation Phase,React Fiber 会找出需要更新哪些 DOM,这个阶段是可以被打断的;但是到了第二阶段 Commit Phase,那就一鼓作气把 DOM 更新完,绝不会被打断。
双缓冲 Fiber tree
在 React 中最多会同时存在两棵fiber tree。当前屏幕上显示内容对应的fiber tree称为current fiber tree,正在内存中构建的fiber tree称为workInProgress fiber tree。current fiber tree 中的 Fiber 节点被称为 current fiber,workInProgress fiber tree 中的 Fiber 节点被称为 workInProgress fiber,他们通过 alternate 属性连接。
currentFiber.alternate === workInProgressFiber;
workInProgressFiber.alternate === currentFiber;
React 应用的根节点通过current指针在不同fiber tree的rootFiber间切换来实现fiber tree的切换。双缓冲具体指的是当workInProgress fiber tree构建完成交给Renderer渲染在页面上后,应用根节点的current指针指向workInProgress fiber tree,此时workInProgress fiber tree就变为current fiber tree。每次状态更新都会产生新的workInProgress fiber tree,通过current与workInProgress的替换,完成 DOM 更新。这样做的好处是:
能够复用内部对象(fiber) 节省内存分配、GC 的时间开销
总结
前面我们了解了 ReactElement 和 React Fiber,现在总结一下整个 Virtual DOM 的工作流程。
初始化渲染,调用函数组件、或 class 组件的 render 方法,将 JSX 代码编译成 ReactELement 对象,它描述当前组件内容的数据结构。 根据生产的 ReactELement 对象构建 Fiber tree,它包含了组件 schedule、reconciler、render 所需的相关信息。 一旦有状态变化,触发更新,Scheduler 在接收到更新后,根据任务的优先级高低来进行调度,决定要执行的任务是什么。 接下来的工作交给 Reconciler 处理,Reconciler 通过对比找出变化了的 Virtual DOM ,为其打上代表增/删/更新的标记,当所有组件都完成 Reconciler 的工作,才会统一交给Renderer。 Renderer 根据 Reconciler 为 Virtual DOM 打的标记,同步执行对应的 DOM 更新操作。
Diff 算法
在调用 React 的 render() 方法,会创建一棵由 React 元素组成的树。在下一次 state 或 props 更新时,相同的 render() 方法会返回一棵不同的树。React 需要基于这两棵树之间的差别来进行比较,这个比较的过程就是俗称的 diff 算法,换成前面我们讲的 React Fiber 的概念来说,就是将当前组件与该组件在上次更新时对应的 Fiber node 比较,将比较的结果生成新的 Fiber 节点。为了方便理解,我们列举下这个更新的 DOM 节点在某一时刻会有这么几个概念与其相关:
current Fiber:如果该 DOM 节点已在页面中,current Fiber 代表该 DOM 节点对应的 Fiber node。 workInProgress Fiber: workInProgress Fiber 代表了正在内存中构建的 Fiber 节点,如果该 DOM 节点即将在本次更新中渲染到页面中,则 workInProgress Fiber 代表该 DOM 节点对应的 Fiber 节点,就是最后更新的结果。 ReactElement 对象:即前面讲到的 Class 组件 render 方法或者调用函数组件的结果经过 React.createElement 生成的对象。
Diff 算法的本质就是对比 1 和 3,生成 2。
Diff 策略
React 文档中提到,即使在最前沿的算法中[6],将前后两棵树完全比对的算法的复杂程度为 O(n 3 ),其中 n 是树中元素的数量。如果在 React 中使用了该算法,那么展示 1000 个元素所需要执行的计算量将在十亿的量级范围。这个开销实在是太过高昂,显然无法满足性能要求,于是 React 在以下两个假设的基础之上提出了一套 O(n) 的启发式算法:
只对同级元素进行 Diff,如果某一个节点在一次更新中跨域了层级,React 不会复用该节点,而是重新创建生成新的节点。 两个不同类型的元素会产生出不同的树,如果元素由 div 变为 p,React 会销毁 div 及其子孙节节点,并新建 p 及其子孙节点。 开发者可以通过 key prop 来暗示哪些子元素在不同的渲染下能保持稳定; 
如上图所示,React 只会对相同颜色框内的 DOM 节点进行比较,即同一个父节点下的所有子节点。当发现节点已经不存在,则该节点及其子节点会被完全删除掉,不会用于进一步的比较。这样只需要对树进行一次遍历,便能完成整个 DOM 树的比较。当有下面的情况时(A 节点直接被整个移动到 D 节点下)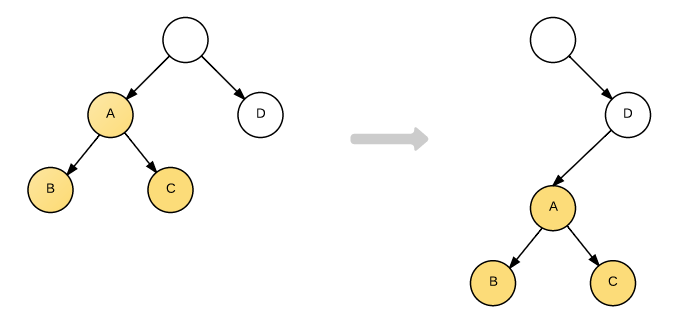
因为 React 只会对同级节点进行比较,这时候 React 发现的是 A 节点不见了,就会直接销毁 A 节点,在 D 节点那里发现多了一个新的子节点 A,则会创建一个新的 A 节点作为子节点。
上面的例子是对于在不同层级的节点的比较,对于同一层级的节点,React 引入了 key 属性来来给每一个节点添加唯一标识,这样 React 就能匹配到原有的节点,提高转换效率,如下面的例子:
// 更新前
<ul>
<li key="2015">Duke</li>
<li key="2016">Villanova</li>
</ul>
// 更新后
<ul>
<li key="2014">Connecticut</li>
<li key="2015">Duke</li>
<li key="2016">Villanova</li>
</ul>
如果没有 key 值,React 会重新创建每一个子元素,因为在比较 ul 的第一个子元素时发现两者不同,即开始重建,但当子元素拥有 key 时,React 使用 key 来匹配原有树上的子元素以及最新树上的子元素,现在 React 知道只有带着 '2014' key 的元素是新元素,带着 '2015' 以及 '2016' key 的元素仅仅移动了。
所以我们在写代码时遇到列表渲染的时候,一定要记得给列表的每一项加上 key 属性,这个 key 不需要全局唯一,但在列表中需要保持唯一。
Diff 算法的实现
我们从 Diff 的入口函数 reconcileChildFibers 出发,该函数会根据 newChild(即 ReactElement 对象)类型调用不同的处理函数。其中几个参数的含义如下:
newChild:即当前更新新生成的 ReactElement 对象。 returnFiber:代表当前 Diff 的 节点的父级 Fiber 节点,也就是上次更新时的 Fiber 节点。 currentFirstChild:即与 newChild 进行 diff 的节点,也是 returnFiber 的第一个子节点。
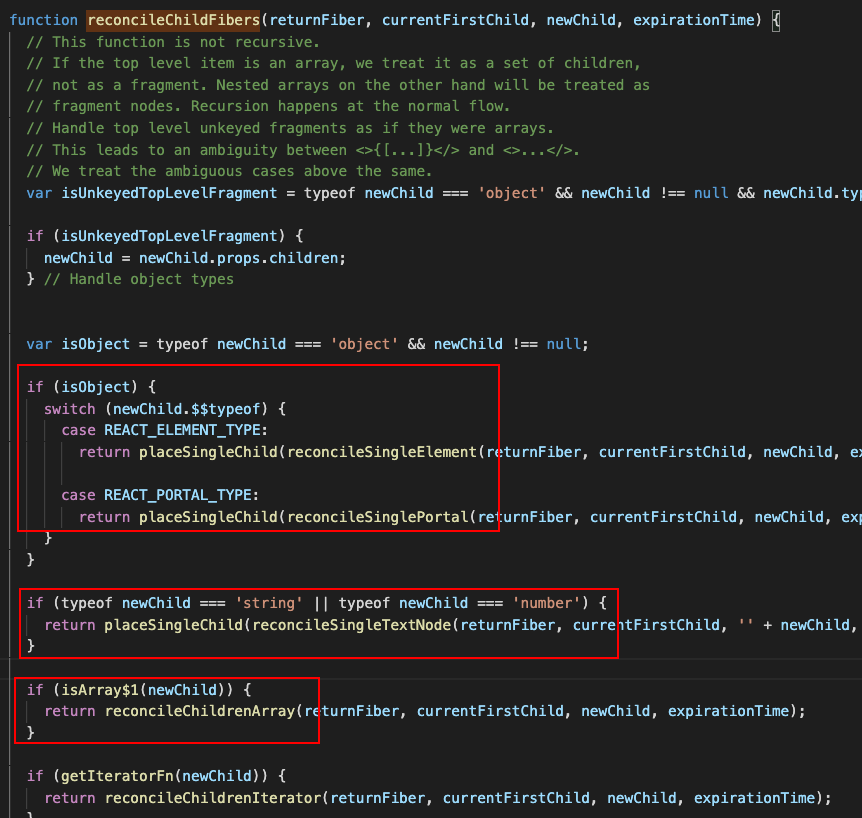
我们可以从同级的节点数量将 Diff 分为两类:
当 newChild 类型为 object、number、string,代表同级只有一个节点 当 newChild 类型为 Array,同级有多个节点
单节点 Diff
对于单个节点,我们以类型 object 为例,会进入 reconcileSingleElement 函数里,这个函数主要做了以下事情:

reconcileSingleElement 方法的部分代码如下:
function reconcileSingleElement(
returnFiber: Fiber,
currentFirstChild: Fiber | null,
element: ReactElement
): Fiber {
const key = element.key;
let child = currentFirstChild;
// 首先判断是否存在对应DOM节点
while (child !== null) {
// 上一次更新存在DOM节点,接下来判断是否可复用
// 首先比较key是否相同
if (child.key === key) {
// key相同,接下来比较type是否相同
switch (child.tag) {
// ...省略case
default: {
if (child.elementType === element.type) {
// type相同则表示可以复用
// 返回复用的fiber
return existing;
}
// type不同则跳出循环
break;
}
}
// 代码执行到这里代表:key相同但是type不同
// 将该fiber及其兄弟fiber标记为删除
deleteRemainingChildren(returnFiber, child);
break;
} else {
// key不同,将该fiber标记为删除
deleteChild(returnFiber, child);
}
child = child.sibling;
}
// 创建新Fiber,并返回 ...省略
}
多节点 Diff
当 ReactElement 的 children 属性不是单一节点的话,如下面结构:
<ul>
<li key="0">0</li>
<li key="1">1</li>
<li key="2">2</li>
<li key="3">3</li>
</ul>
此时它返回的对象的 children 是包含 4 个对象的数组:
{
$typeof: Symbol(react.element),
key: null,
props: {
children: [
{$typeof: Symbol(react.element), type: "li", key: "0", ref: null, props: {…}, …}
{$typeof: Symbol(react.element), type: "li", key: "1", ref: null, props: {…}, …}
{$typeof: Symbol(react.element), type: "li", key: "2", ref: null, props: {…}, …}
{$typeof: Symbol(react.element), type: "li", key: "3", ref: null, props: {…}, …}
]
},
ref: null,
type: "ul"
}
这种情况下,reconcileChildFibers的newChild参数类型为Array,对应的处理函数是reconcileChildrenArray里的newChildren,在比较时,和newChildren里的每一个child比较的是current fiber,即newChildren[0]与fiber比较,newChildren[1]与fiber.sibling比较。
多节点 diff 的情况比较多比较复杂,大致可以分为以下几个方面:
节点更新
节点属性变化 节点类型变化
节点增加或减少 节点位置发生变化
React 团队发现,在日常开发中,相较于新增和删除,更新组件发生的频率更高。所以 Diff 会优先判断当前节点是否属于更新。基于以上原因,Diff 算法的整体逻辑会经历两轮:
第一轮遍历:处理更新的节点。 第二轮遍历:处理剩下的不属于更新的节点。
第一轮遍历的步骤如下:
遍历 newChildren,将 newChildren[i] 与 oldFiber 比较,判断 DOM 节点是否可复用。 如果可复用,i++,继续比较 newChildren[i] 与 oldFiber.sibling,可以复用则继续遍历。 如果不可复用,立即跳出整个遍历,第一轮遍历结束。 如果 newChildren 遍历完(即 i === newChildren.length - 1)或者 oldFiber 遍历完(即 oldFiber.sibling === null),跳出遍历,第一轮遍历结束。
第一轮遍历结束后,有以下几种结果:
newChildren 与 oldFiber 同时遍历完:这说明新旧节点数量一样,只是组件发生了更新。此时 Diff 结束。 newChildren 没遍历完,oldFiber 遍历完:这说明旧的节点遍历完了,但是还有新加入的节点,我们只需要遍历剩下的 newChildren 为生成的 workInProgress fiber 依次标记上 Placement。 newChildren 遍历完,oldFiber 没遍历完:这说明本次更新比之前的节点数量变少了,有节点被删除了,所以要遍历剩下的 oldFiber,依次标记 Deletion。 newChildren 与 oldFiber 都没遍历完:这意味着有节点在这次更新中改变了位置,这时候需要通过 key 来标记节点是否移动。
等上面所有的节点都遍历完成后,都已经打上了增/删/更新的标记,此时就生成了 workInProgress Fiber,剩下的工作就是交个 renderer 处理了。
参考资料
尤雨溪 对于 Virtual DOM 的优势的回答: https://www.zhihu.com/question/31809713/answer/53544875
[2]React 元素: https://zh-hans.reactjs.org/docs/rendering-elements.html
[3]reconciliation: https://reactjs.org/docs/reconciliation.html
[4]demo: https://claudiopro.github.io/react-fiber-vs-stack-demo/
[5]createFiberFromTypeAndProps: https://github.com/facebook/react/blob/769b1f270e1251d9dbdce0fcbd9e92e502d059b8/packages/react-reconciler/src/ReactFiber.js#L414
[6]最前沿的算法中: http://grfia.dlsi.ua.es/ml/algorithms/references/editsurvey_bille.pdf
作者:Escape
来源:字节前端 ByteFE