
从零实现爬虫和情感分类模型(一)

文 | Giant
编 | NLP情报局
大家好,我是Giant,这是我的第3篇文章。
日常生活中,我们去吃饭、观影会提前上网刷评论,然后再选择好评高的餐厅或电影。
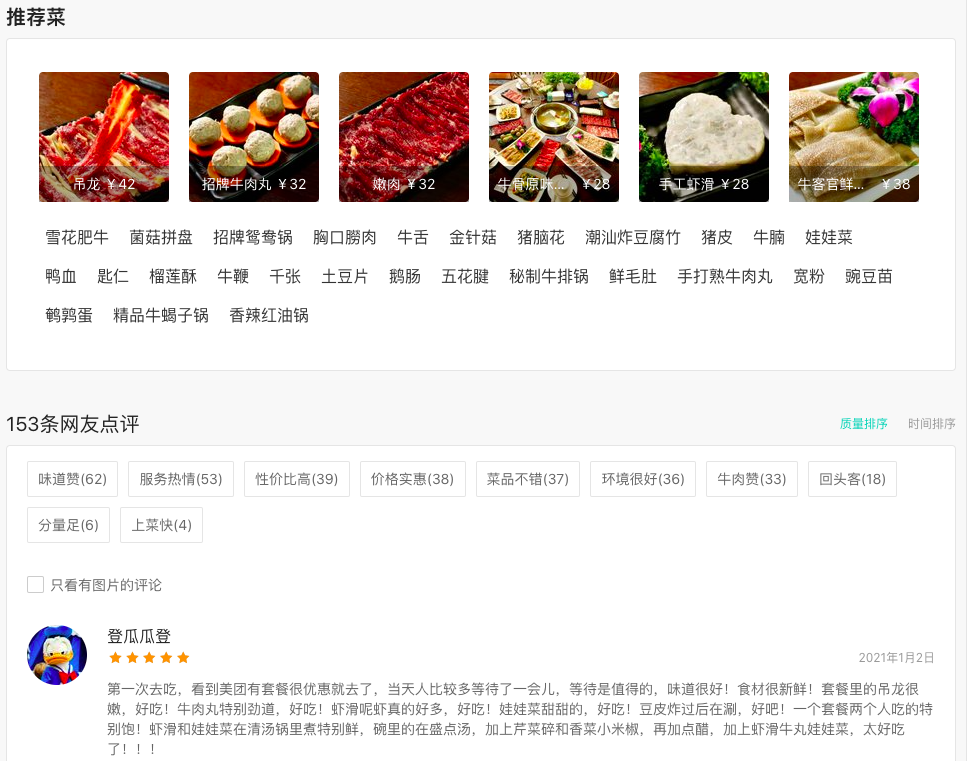
看新闻时,我们也会点击感兴趣的新闻类别(体育、财经等),再结合标题有选择地阅读。

情感分析、新闻归类都是自然语言处理—文本分类任务的经典应用。本文我们将从0实现一个餐厅评论评分系统。具体分4个模块介绍:
python怎么装最方便? 如何用python实现爬虫? 数据处理三剑客使用技巧 如何实现情感分类模型?
开源代码:
https://github.com/yechens/RestaurantCrawler
python怎么装最方便?
python是一种非常流行的编程语言,语法简洁却功能强大,安装方式很多。Mac和Ubuntu等系统已经预装好了最新版本的python。
但我还是强烈推荐你安装Anaconda套装。它是一个开源的python发行版本,包含180多个工具包,其中很多工具包对于机器学习研究非常重要。一次安装可以“一劳永逸”。
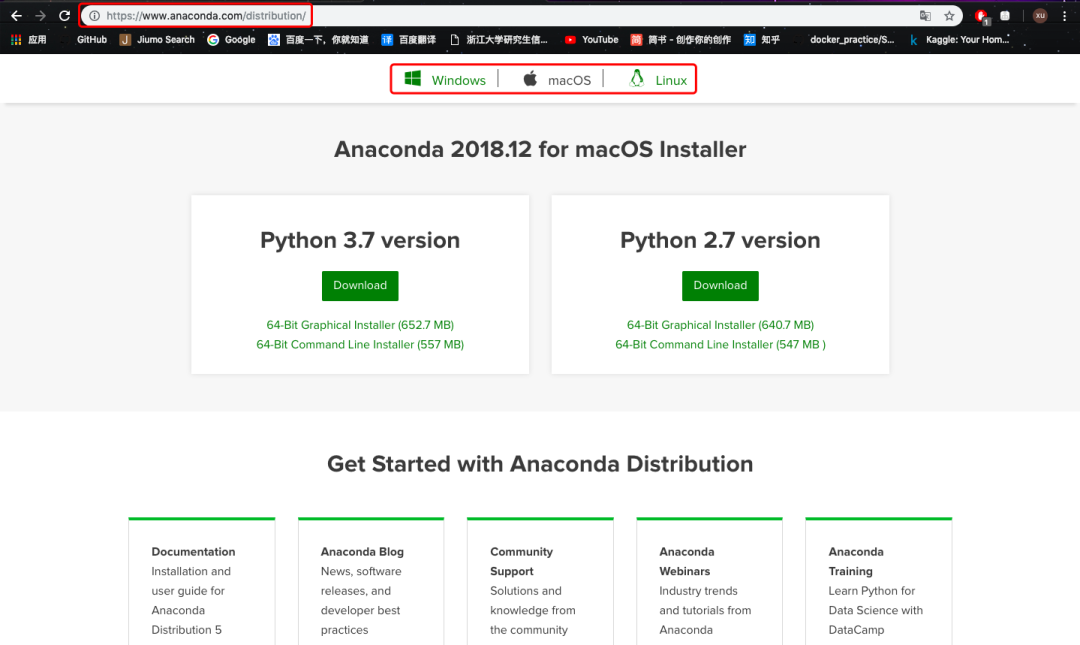
进入Anaconda官网的下载页面,可以根据你的系统下载最新版本的conda。如果想下载历史版本,可以参考[1]。
之后根据中文提示一步步安装即可,非常方便。
安装完成后,进入系统终端(Windows下称“命令提示符”),用conda创建一个虚拟环境,这样可以和系统中原有的python环境相隔离。
conda create -n py36 python=3.6 # 创建指定py版本的虚拟环境conda env list # 查看虚拟环境source activate py36 # 激活
这里我们创建了一个python3.6版本的虚拟环境,然后激活进入:

python最基础的环境搭建到这儿全部完成啦。
如何用python实现爬虫
我们的目标是实现一个餐厅评分系统,核心数据是各大餐厅的评论语料。如何获得呢?
最简单的方法,是去各大点评网站上查看餐厅的评论信息,然后手工复制、粘贴到Excel。但这样费时费力,效率极低。能不能让计算机帮助我们自动搜集各个店铺的评论数据呢?
当然可以!这就是网络爬虫。

整个互联网相当于一张大图,各个网站是图中的节点。爬虫正是模拟人的行为,利用计算机自动遍历各个节点,访问页面并抓取信息。这里的信息包括图片、文字、视频、脚本等等。此外,我们要记载哪个网页下载过了,以免重复。
相比真实用户访问,爬虫有2个明显优势:
自动进行,无需人工干预 并发量大,访问效率高
而读者之所以经常听到爬虫和python挂钩,是因为脚本语言python非常适合写爬虫代码。
有多简单呢?核心只有三行代码:
import requestsr = requests.get(url="http://www.baidu.com")content = r.content
requests库会自动向我们指定的网页链接(百度)发起http请求,并将爬取结果返回到变量content中。
爬虫背后涉及了浏览器的工作原理。对此感兴趣的读者,可以阅读参考文献[2]。
这“两行代码”是最简单的一种情况,爬取到的内容也只是百度首页的源码;但实际开发爬虫的核心内容,已经呈现在这两行代码里了。
Scrapy简介
在本项目中,我使用了一个比requests库稍复杂的工具Scrapy,它是python最火的爬虫框架,结构化的设计可以让开发人员方便的自定义项目需求。
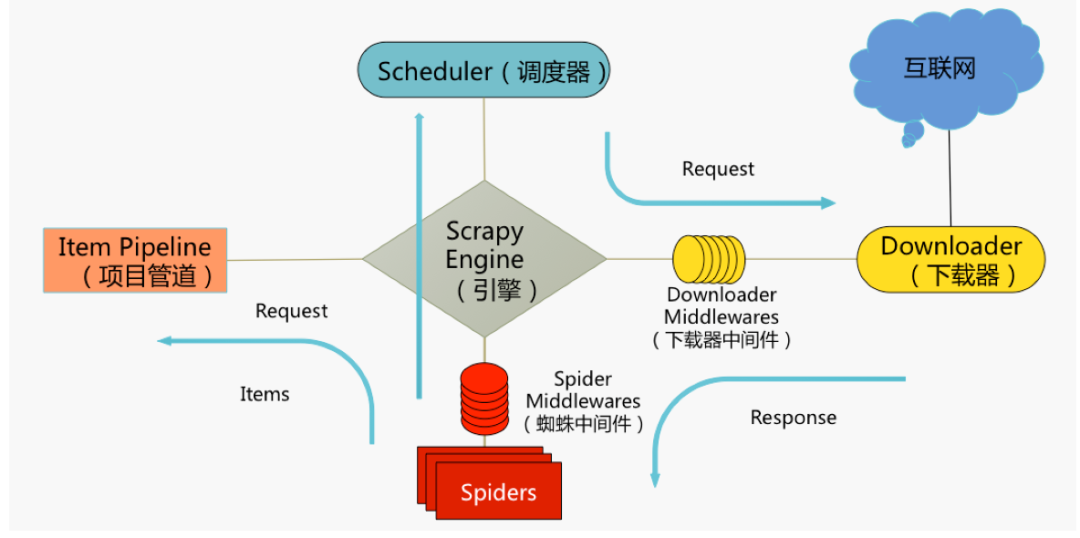
框架核心内容可以用这张图来概述,图中包括Scrapy5大组件:
Scrapy Engine(引擎)
爬虫的“大脑”,是整个爬虫的调度中心Scheduler(调度器)
初始的爬取URL和后续在页面中获取的待爬取的URL将放入调度器中,等待爬取。同时调度器会自动去除已经下载过的URL。
Downloader(下载器)
获取指定页面的数据并提供给引擎和spiderSpiders(爬虫类)
用户编写的分析爬取结果(response)并从中提取内容的类Items(实体类)
处理Spiders提取出来的内容(items)典型处理包括:清洗、验证、持久化(存入数据库)
Scrapy主体内容先介绍到这,参考文献[3]、[4]、[5]为读者准备了学习这个框架的更多资料。
爬取餐厅评论
接下来进入实战环节:利用python、Scrapy实现各大城市餐厅评论信息的自动爬取。
借助之前下载的conda工具,进入虚拟环境后我们用一行代码完成scrapy安装:
conda install scrapy为了方便演示,这儿只爬取杭州、北京等5大城市各1000家餐馆的200条评论,一共约100w条数据。想爬取更多内容,读者略微修改开源代码中的内容即可。
创建项目
我们先创建一个新的Scrapy项目:
scrapy startproject MeiTuanRestaurant该命令将会创建包含以下内容的MeiTuanRestaurant目录:
scrapy.cfg: 项目的配置文件MeiTuanRestaurant/: 项目的python模块。之后您将在此加入代码MeiTuanRestaurant/items.py: 项目中的item文件MeiTuanRestaurant/pipelines.py: 项目中的pipelines文件MeiTuanRestaurant/settings.py: 项目的设置文件MeiTuanRestaurant/spiders/: 放置spider代码的目录
cd进入MeiTuanRestaurant目录,随后我们在spiders目录下创建一个存放“爬虫类”的py文件:
scrapy genspider meituan meituan.commeituan.py中生成了爬虫类MeituanSpider,我们在其中指定需要爬取的页面入口、解析爬取结果并存放到数据库中等操作。
我在meituan.py做了简单的修改,并定义了一些新函数。
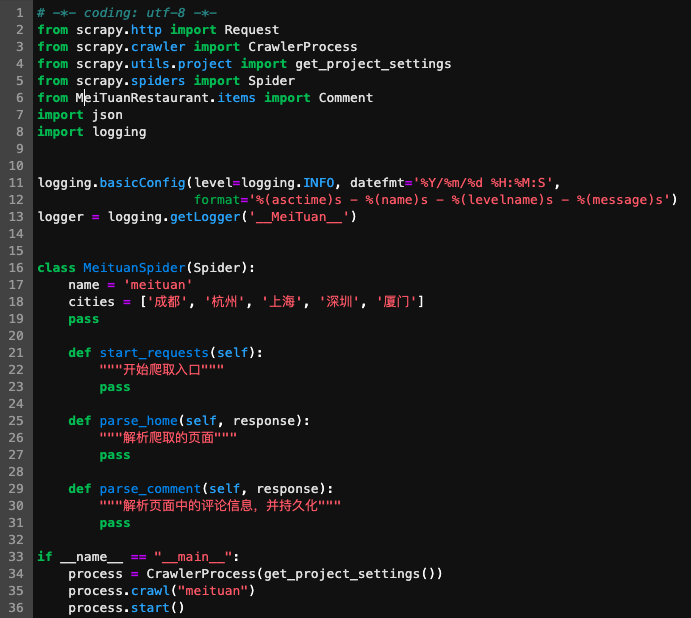
函数参数“response”中存储了页面解析后的结果,我们可以从中提取出想要的内容,例如当前页面(page)、评论信息等。
完善爬虫
随后,我们指定好爬取的页面url,并填写函数内容。本项目中,我们通过构造api接口,提取json格式的数据。
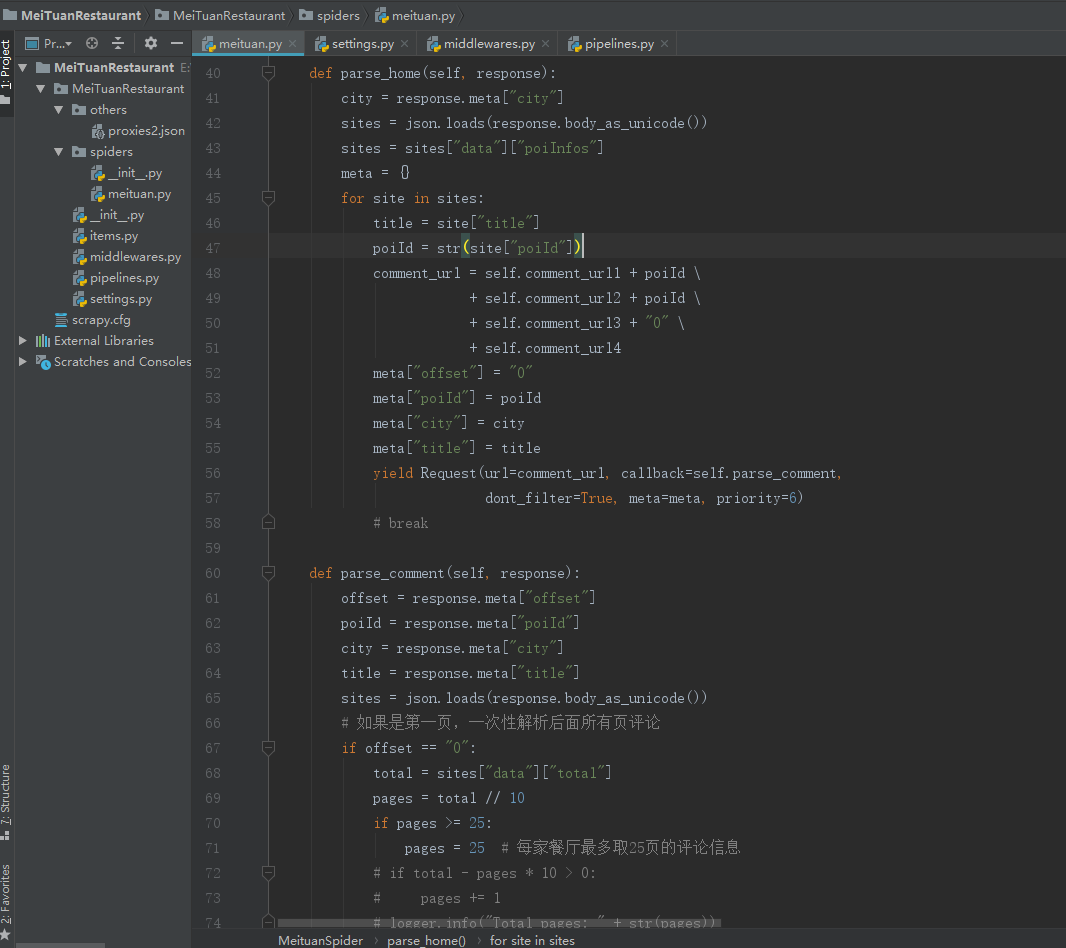
此外,我们需要在settings.py中进行相关配置,常见操作有将爬虫伪装成浏览器、设置下载延时、配置数据库等等。
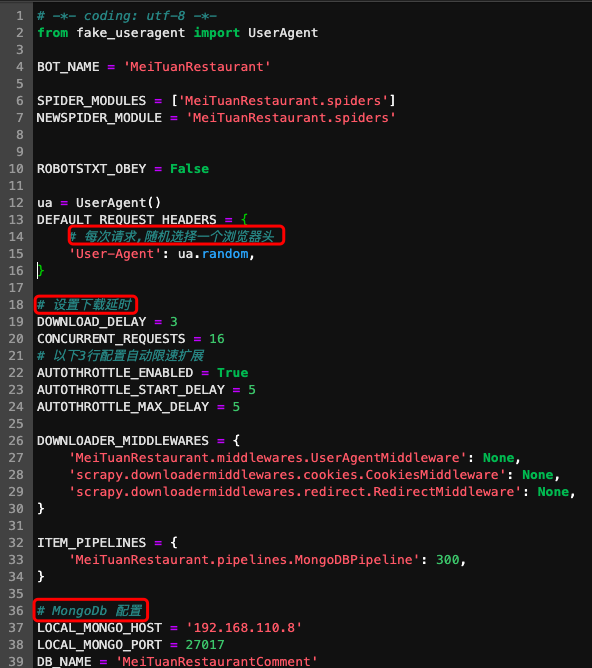
item.py中建立了评论的对象类,包含了样本的所有属性。例如一条评论可以有城市、标题、内容、星级4个特征。
启动爬虫
打开终端进入项目所在路径(MeiTuanRestaurant路径下),运行以下命令:
scrapy crawl meituan启动后可以看到爬虫开始卖力爬取各个餐厅的评论信息啦。
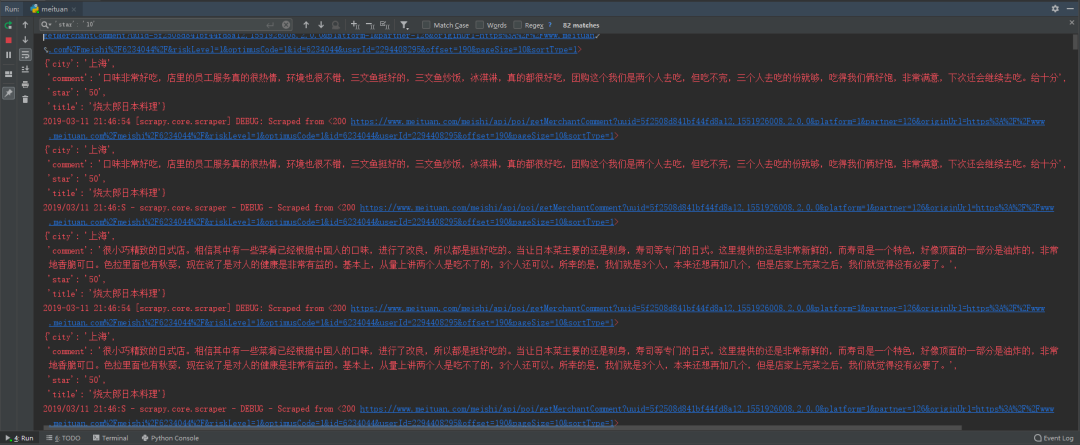
数据持久化
为了将爬取到的内容及时保存,我把评论数据存储到非结构化数据库mongodb中。

如果觉得速度太慢,还可以尝试分布式架构(如scrapy-redis),加快爬虫爬取速度。
总结
本文实现了“从零实现爬虫和情感分类模型”的第一部分:搭建环境、实现爬虫。单机约2-3天可以完成百万级的评论信息自动爬取(如果遇到ip被封,需要设置代理池继续伪装爬虫)。
在下一篇文章中,我们将分析数据处理和模型训练的实用技巧!
推 荐 阅 读

[1] Anaconda历史版本: https://repo.continuum.io/archive/
[2] 图解浏览器的基本工作原理: https://zhuanlan.zhihu.com/p/47407398
[3] Scrapy官方文档: https://scrapy.org/
[4] 《Python爬虫开发与项目实战》: https://www.jqhtml.com/down/716.html
[5] 构建单机千万级别的微博爬虫系统: https://github.com/LiuXingMing/SinaSpider
由于微信平台算法改版,订阅号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们帮我们点【在看】。星标具体步骤:
(1)点击页面最上方“NLP情报局”,进入主页
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦
感谢支持❤️
原创不易,有收获的话请分享、点赞、在看三选一吧🙏