
Java双刃剑之Unsafe类详解


前一段时间在研究juc源码的时候,发现在很多工具类中都调用了一个Unsafe类中的方法,出于好奇就想要研究一下这个类到底有什么作用,于是先查阅了一些资料,一查不要紧,很多资料中对Unsafe的态度都是这样的画风:

其实看到这些说法也没什么意外,毕竟Unsafe这个词直译过来就是“不安全的”,从名字里我们也大概能看来Java的开发者们对它有些不放心。但是作为一名极客,不能你说不安全我就不去研究了,毕竟只有了解一项技术的风险点,才能更好的避免出现这些问题嘛。
下面我们言归正传,先通过简单的介绍来对Unsafe类有一个大致的了解。Unsafe类是一个位于sun.misc包下的类,它提供了一些相对底层方法,能够让我们接触到一些更接近操作系统底层的资源,如系统的内存资源、cpu指令等。而通过这些方法,我们能够完成一些普通方法无法实现的功能,例如直接使用偏移地址操作对象、数组等等。但是在使用这些方法提供的便利的同时,也存在一些潜在的安全因素,例如对内存的错误操作可能会引起内存泄漏,严重时甚至可能引起jvm崩溃。因此在使用Unsafe前,我们必须要了解它的工作原理与各方法的应用场景,并且在此基础上仍需要非常谨慎的操作,下面我们正式开始对Unsafe的学习。
Unsafe 基础
首先我们来尝试获取一个Unsafe实例,如果按照new的方式去创建对象,不好意思,编译器会报错提示你:
Unsafe() has private access in 'sun.misc.Unsafe'
查看Unsafe类的源码,可以看到它被final修饰不允许被继承,并且构造函数为private类型,即不允许我们手动调用构造方法进行实例化,只有在static静态代码块中,以单例的方式初始化了一个Unsafe对象:
public final class Unsafe {
private static final Unsafe theUnsafe;
...
private Unsafe() {
}
...
static {
theUnsafe = new Unsafe();
}
}
在Unsafe类中,提供了一个静态方法getUnsafe,看上去貌似可以用它来获取Unsafe实例:
@CallerSensitive
public static Unsafe getUnsafe() {
Class var0 = Reflection.getCallerClass();
if (!VM.isSystemDomainLoader(var0.getClassLoader())) {
throw new SecurityException("Unsafe");
} else {
return theUnsafe;
}
}
但是如果我们直接调用这个静态方法,会抛出异常:
Exception in thread "main" java.lang.SecurityException: Unsafe
at sun.misc.Unsafe.getUnsafe(Unsafe.java:90)
at com.cn.test.GetUnsafeTest.main(GetUnsafeTest.java:12)
这是因为在getUnsafe方法中,会对调用者的classLoader进行检查,判断当前类是否由Bootstrap classLoader加载,如果不是的话那么就会抛出一个SecurityException异常。也就是说,只有启动类加载器加载的类才能够调用Unsafe类中的方法,来防止这些方法在不可信的代码中被调用。
那么,为什么要对Unsafe类进行这么谨慎的使用限制呢,说到底,还是因为它实现的功能过于底层,例如直接进行内存操作、绕过jvm的安全检查创建对象等等,概括的来说,Unsafe类实现功能可以被分为下面8类:
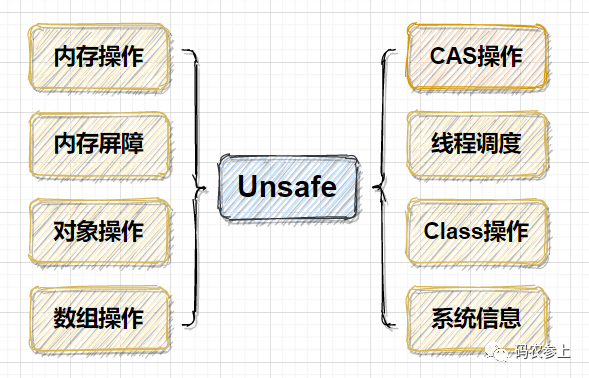
创建实例
看到上面的这些功能,你是不是已经有些迫不及待想要试一试了。那么如果我们执意想要在自己的代码中调用Unsafe类的方法,应该怎么获取一个它的实例对象呢,答案是利用反射获得Unsafe类中已经实例化完成的单例对象:
public static Unsafe getUnsafe() throws IllegalAccessException {
Field unsafeField = Unsafe.class.getDeclaredField("theUnsafe");
//Field unsafeField = Unsafe.class.getDeclaredFields()[0]; //也可以这样,作用相同
unsafeField.setAccessible(true);
Unsafe unsafe =(Unsafe) unsafeField.get(null);
return unsafe;
}
在获取到Unsafe的实例对象后,我们就可以使用它为所欲为了,先来尝试使用它对一个对象的属性进行读写:
public void fieldTest(Unsafe unsafe) throws NoSuchFieldException {
User user=new User();
long fieldOffset = unsafe.objectFieldOffset(User.class.getDeclaredField("age"));
System.out.println("offset:"+fieldOffset);
unsafe.putInt(user,fieldOffset,20);
System.out.println("age:"+unsafe.getInt(user,fieldOffset));
System.out.println("age:"+user.getAge());
}
运行代码输出如下,可以看到通过Unsafe类的objectFieldOffset方法获取了对象中字段的偏移地址,这个偏移地址不是内存中的绝对地址而是一个相对地址,之后再通过这个偏移地址对int类型字段的属性值进行了读写操作,通过结果也可以看到Unsafe的方法和类中的get方法获取到的值是相同的。
offset:12
age:20
age:20
在上面的例子中调用了Unsafe类的putInt和getInt方法,看一下源码中的方法:
public native int getInt(Object o, long offset);
public native void putInt(Object o, long offset, int x);
先说作用,getInt用于从对象的指定偏移地址处读取一个int,putInt用于在对象指定偏移地址处写入一个int,并且即使类中的这个属性是private私有类型的,也可以对它进行读写。但是有细心的小伙伴可能发现了,这两个方法相对于我们平常写的普通方法,多了一个native关键字修饰,并且没有具体的方法逻辑,那么它是怎么实现的呢?
native方法
在java中,这类方法被称为native方法(Native Method),简单的说就是由java调用非java代码的接口,被调用的方法是由非java 语言实现的,例如它可以由C或C++语言来实现,并编译成DLL,然后直接供java进行调用。native方法是通过JNI(Java Native Interface)实现调用的,从 java1.1开始 JNI 标准就是java平台的一部分,它允许java代码和其他语言的代码进行交互。
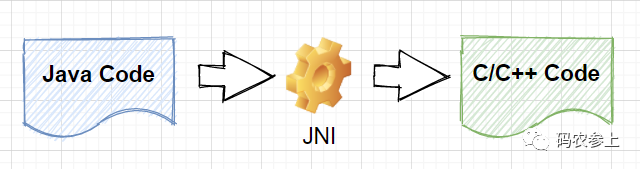
Unsafe类中的很多基础方法都属于native方法,那么为什么要使用native方法呢?原因可以概括为以下几点:
需要用到 java 中不具备的依赖于操作系统的特性,java在实现跨平台的同时要实现对底层的控制,需要借助其他语言发挥作用 对于其他语言已经完成的一些现成功能,可以使用java直接调用 程序对时间敏感或对性能要求非常高时,有必要使用更加底层的语言,例如C/C++甚至是汇编
在juc包的很多并发工具类在实现并发机制时,都调用了native方法,通过它们打破了java运行时的界限,能够接触到操作系统底层的某些功能。对于同一个native方法,不同的操作系统可能会通过不同的方式来实现,但是对于使用者来说是透明的,最终都会得到相同的结果,至于java如何实现的通过JNI调用其他语言的代码,不是本文的重点,会在后续的文章中具体学习。
Unsafe 应用
在对Unsafe的基础有了一定了解后,我们来看一下它的基本应用。由于篇幅有限,不能对所有方法进行介绍,如果大家有学习的需要,可以下载openJDK的源码进行学习。
1、内存操作
如果你是一个写过c或者c++的程序员,一定对内存操作不会陌生,而在java中是不允许直接对内存进行操作的,对象内存的分配和回收都是由jvm自己实现的。但是在Unsafe中,提供的下列接口可以直接进行内存操作:
//分配新的本地空间
public native long allocateMemory(long bytes);
//重新调整内存空间的大小
public native long reallocateMemory(long address, long bytes);
//将内存设置为指定值
public native void setMemory(Object o, long offset, long bytes, byte value);
//内存拷贝
public native void copyMemory(Object srcBase, long srcOffset,Object destBase, long destOffset,long bytes);
//清除内存
public native void freeMemory(long address);
使用下面的代码进行测试:
private void memoryTest() {
int size = 4;
long addr = unsafe.allocateMemory(size);
long addr3 = unsafe.reallocateMemory(addr, size * 2);
System.out.println("addr: "+addr);
System.out.println("addr3: "+addr3);
try {
unsafe.setMemory(null,addr ,size,(byte)1);
for (int i = 0; i < 2; i++) {
unsafe.copyMemory(null,addr,null,addr3+size*i,4);
}
System.out.println(unsafe.getInt(addr));
System.out.println(unsafe.getLong(addr3));
}finally {
unsafe.freeMemory(addr);
unsafe.freeMemory(addr3);
}
}
先看结果输出:
addr: 2433733895744
addr3: 2433733894944
16843009
72340172838076673
分析一下运行结果,首先使用allocateMemory方法申请4字节长度的内存空间,在循环中调用setMemory方法向每个字节写入内容为byte类型的1,当使用Unsafe调用getInt方法时,因为一个int型变量占4个字节,会一次性读取4个字节,组成一个int的值,对应的十进制结果为16843009,可以通过图示理解这个过程:
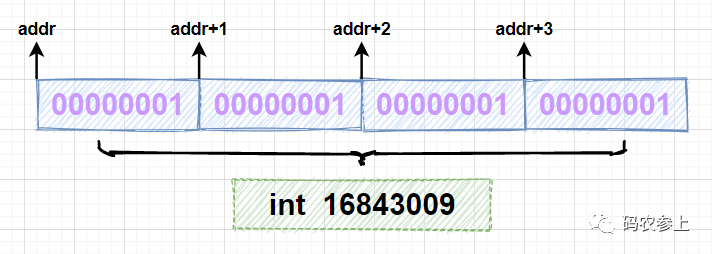
在代码中调用reallocateMemory方法重新分配了一块8字节长度的内存空间,通过比较addr和addr3可以看到和之前申请的内存地址是不同的。在代码中的第二个for循环里,调用copyMemory方法进行了两次内存的拷贝,每次拷贝内存地址addr开始的4个字节,分别拷贝到以addr3和addr3+4开始的内存空间上:

拷贝完成后,使用getLong方法一次性读取8个字节,得到long类型的值为72340172838076673。
需要注意,通过这种方式分配的内存属于堆外内存,是无法进行垃圾回收的,需要我们把这些内存当做一种资源去手动调用freeMemory方法进行释放,否则会产生内存泄漏。通用的操作内存方式是在try中执行对内存的操作,最终在finally块中进行内存的释放。
2、内存屏障
在介绍内存屏障前,需要知道编译器和CPU会在保证程序输出结果一致的情况下,会对代码进行重排序,从指令优化角度提升性能。而指令重排序可能会带来一个不好的结果,导致CPU的高速缓存和内存中数据的不一致,而内存屏障(Memory Barrier)就是通过组织屏障两边的指令重排序从而避免编译器和硬件的不正确优化情况。
在硬件层面上,内存屏障是CPU为了防止代码进行重排序而提供的指令,不同的硬件平台上实现内存屏障的方法可能并不相同。在java8中,引入了3个内存屏障的函数,它屏蔽了操作系统底层的差异,允许在代码中定义、并统一由jvm来生成内存屏障指令,来实现内存屏障的功能。Unsafe中提供了下面三个内存屏障相关方法:
//禁止读操作重排序
public native void loadFence();
//禁止写操作重排序
public native void storeFence();
//禁止读、写操作重排序
public native void fullFence();
内存屏障可以看做对内存随机访问的操作中的一个同步点,使得此点之前的所有读写操作都执行后才可以开始执行此点之后的操作。以loadFence方法为例,它会禁止读操作重排序,保证在这个屏障之前的所有读操作都已经完成,并且将缓存数据设为无效,重新从主存中进行加载。
看到这估计很多小伙伴们会想到volatile关键字了,如果在字段上添加了volatile关键字,就能够实现字段在多线程下的可见性。基于读内存屏障,我们也能实现相同的功能。下面定义一个线程方法,在线程中去修改flag标志位,注意这里的flag是没有被volatile修饰的:
@Getter
class ChangeThread implements Runnable{
/**volatile**/ boolean flag=false;
@Override
public void run() {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("subThread change flag to:" + flag);
flag = true;
}
}
在主线程的while循环中,加入内存屏障,测试是否能够感知到flag的修改变化:
public static void main(String[] args){
ChangeThread changeThread = new ChangeThread();
new Thread(changeThread).start();
while (true) {
boolean flag = changeThread.isFlag();
unsafe.loadFence(); //加入读内存屏障
if (flag){
System.out.println("detected flag changed");
break;
}
}
System.out.println("main thread end");
}
运行结果:
subThread change flag to:false
detected flag changed
main thread end
而如果删掉上面代码中的loadFence方法,那么主线程将无法感知到flag发生的变化,会一直在while中循环。可以用图来表示上面的过程:
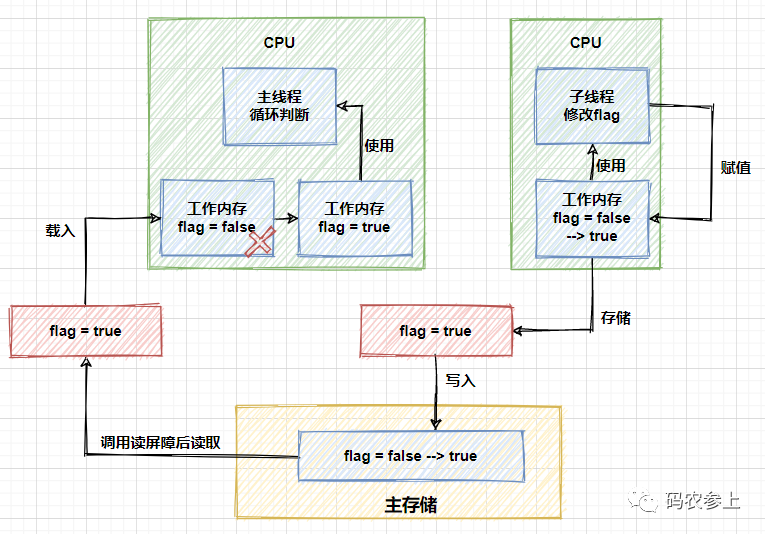
了解java内存模型(JMM)的小伙伴们应该清楚,运行中的线程不是直接读取主内存中的变量的,只能操作自己工作内存中的变量,然后同步到主内存中,并且线程的工作内存是不能共享的。上面的图中的流程就是子线程借助于主内存,将修改后的结果同步给了主线程,进而修改主线程中的工作空间,跳出循环。
3、对象操作
a、对象成员属性的内存偏移量获取,以及字段属性值的修改,在上面的例子中我们已经测试过了。除了前面的putInt、getInt方法外,Unsafe提供了全部8种基础数据类型以及Object的put和get方法,并且所有的put方法都可以越过访问权限,直接修改内存中的数据。阅读openJDK源码中的注释发现,基础数据类型和Object的读写稍有不同,基础数据类型是直接操作的属性值(value),而Object的操作则是基于引用值(reference value)。下面是Object的读写方法:
//在对象的指定偏移地址获取一个对象引用
public native Object getObject(Object o, long offset);
//在对象指定偏移地址写入一个对象引用
public native void putObject(Object o, long offset, Object x);
除了对象属性的普通读写外,Unsafe还提供了volatile读写和有序写入方法。volatile读写方法的覆盖范围与普通读写相同,包含了全部基础数据类型和Object类型,以int类型为例:
//在对象的指定偏移地址处读取一个int值,支持volatile load语义
public native int getIntVolatile(Object o, long offset);
//在对象指定偏移地址处写入一个int,支持volatile store语义
public native void putIntVolatile(Object o, long offset, int x);
相对于普通读写来说,volatile读写具有更高的成本,因为它需要保证可见性和有序性。在执行get操作时,会强制从主存中获取属性值,在使用put方法设置属性值时,会强制将值更新到主存中,从而保证这些变更对其他线程是可见的。
有序写入的方法有以下三个:
public native void putOrderedObject(Object o, long offset, Object x);
public native void putOrderedInt(Object o, long offset, int x);
public native void putOrderedLong(Object o, long offset, long x);
有序写入的成本相对volatile较低,因为它只保证写入时的有序性,而不保证可见性,也就是一个线程写入的值不能保证其他线程立即可见。为了解决这里的差异性,需要对内存屏障的知识点再进一步进行补充,首先需要了解两个指令的概念:
Load:将主内存中的数据拷贝到处理器的缓存中Store:将处理器缓存的数据刷新到主内存中
顺序写入与volatile写入的差别在于,在顺序写时加入的内存屏障类型为StoreStore类型,而在volatile写入时加入的内存屏障是StoreLoad类型,如下图所示:
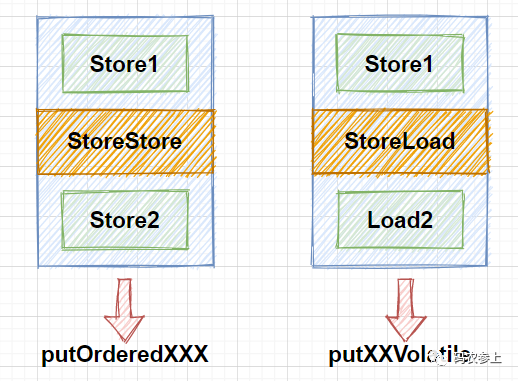
在有序写入方法中,使用的是StoreStore屏障,该屏障确保Store1立刻刷新数据到内存,这一操作先于Store2以及后续的存储指令操作。而在volatile写入中,使用的是StoreLoad屏障,该屏障确保Store1立刻刷新数据到内存,这一操作先于Load2及后续的装载指令,并且,StoreLoad屏障会使该屏障之前的所有内存访问指令,包括存储指令和访问指令全部完成之后,才执行该屏障之后的内存访问指令。
综上所述,在上面的三类写入方法中,在写入效率方面,按照put、putOrder、putVolatile的顺序效率逐渐降低,
b、使用Unsafe的allocateInstance方法,允许我们使用非常规的方式进行对象的实例化,首先定义一个实体类,并且在构造函数中对其成员变量进行赋值操作:
@Data
public class A {
private int b;
public A(){
this.b =1;
}
}
分别基于构造函数、反射以及Unsafe方法的不同方式创建对象进行比较:
public void objTest() throws Exception{
A a1=new A();
System.out.println(a1.getB());
A a2 = A.class.newInstance();
System.out.println(a2.getB());
A a3= (A) unsafe.allocateInstance(A.class);
System.out.println(a3.getB());
}
打印结果分别为1、1、0,说明通过allocateInstance方法创建对象过程中,不会调用类的构造方法。使用这种方式创建对象时,只用到了Class对象,所以说如果想要跳过对象的初始化阶段或者跳过构造器的安全检查,就可以使用这种方法。在上面的例子中,如果将A类的构造函数改为private类型,将无法通过构造函数和反射创建对象,但allocateInstance方法仍然有效。
4、数组操作
在Unsafe中,可以使用arrayBaseOffset方法可以获取数组中第一个元素的偏移地址,使用arrayIndexScale方法可以获取数组中元素间的偏移地址增量。使用下面的代码进行测试:
private void arrayTest() {
String[] array=new String[]{"str1str1str","str2","str3"};
int baseOffset = unsafe.arrayBaseOffset(String[].class);
System.out.println(baseOffset);
int scale = unsafe.arrayIndexScale(String[].class);
System.out.println(scale);
for (int i = 0; i < array.length; i++) {
int offset=baseOffset+scale*i;
System.out.println(offset+" : "+unsafe.getObject(array,offset));
}
}
上面代码的输出结果为:
16
4
16 : str1str1str
20 : str2
24 : str3
通过配合使用数组偏移首地址和各元素间偏移地址的增量,可以方便的定位到数组中的元素在内存中的位置,进而通过getObject方法直接获取任意位置的数组元素。需要说明的是,arrayIndexScale获取的并不是数组中元素占用的大小,而是地址的增量,按照openJDK中的注释,可以将它翻译为元素寻址的转换因子(scale factor for addressing elements)。在上面的例子中,第一个字符串长度为11字节,但其地址增量仍然为4字节。
那么,基于这两个值是如何实现的寻址和数组元素的访问呢,这里需要借助一点在前面的文章中讲过的Java对象内存布局的知识,先把上面例子中的String数组对象的内存布局画出来,就很方便大家理解了:
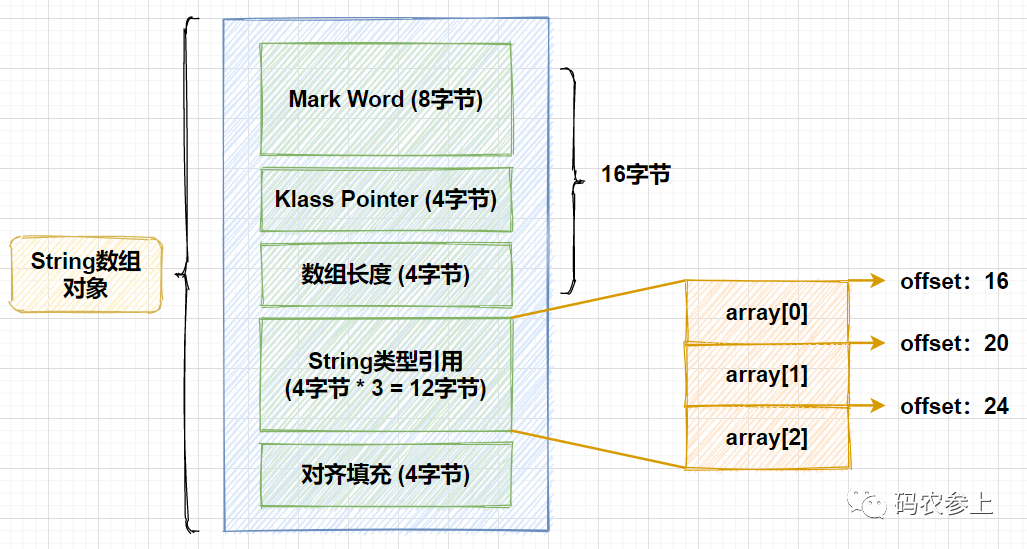
在String数组对象中,对象头包含3部分,mark word标记字占用8字节,klass point类型指针占用4字节,数组对象特有的数组长度部分占用4字节,总共占用了16字节。第一个String的引用类型相对于对象的首地址的偏移量是就16,之后每个元素在这个基础上加4,正好对应了我们上面代码中的寻址过程,之后再使用前面说过的getObject方法,通过数组对象可以获得对象在堆中的首地址,再配合对象中变量的偏移量,就能获得每一个变量的引用。
5、CAS操作
在juc包的并发工具类中大量地使用了CAS操作,像在前面介绍synchronized和AQS的文章中也多次提到了CAS,其作为乐观锁在并发工具类中广泛发挥了作用。在Unsafe类中,提供了compareAndSwapObject、compareAndSwapInt、compareAndSwapLong方法来实现的对Object、int、long类型的CAS操作。以compareAndSwapInt方法为例:
public final native boolean compareAndSwapInt(Object o, long offset,int expected,int x);
参数中o为需要更新的对象,offset是对象o中整形字段的偏移量,如果这个字段的值与expected相同,则将字段的值设为x这个新值,并且此更新是不可被中断的,也就是一个原子操作。下面是一个使用compareAndSwapInt的例子:
private volatile int a;
public static void main(String[] args){
CasTest casTest=new CasTest();
new Thread(()->{
for (int i = 1; i < 5; i++) {
casTest.increment(i);
System.out.print(casTest.a+" ");
}
}).start();
new Thread(()->{
for (int i = 5 ; i <10 ; i++) {
casTest.increment(i);
System.out.print(casTest.a+" ");
}
}).start();
}
private void increment(int x){
while (true){
try {
long fieldOffset = unsafe.objectFieldOffset(CasTest.class.getDeclaredField("a"));
if (unsafe.compareAndSwapInt(this,fieldOffset,x-1,x))
break;
} catch (NoSuchFieldException e) {
e.printStackTrace();
}
}
}
运行代码会依次输出:
1 2 3 4 5 6 7 8 9
在上面的例子中,使用两个线程去修改int型属性a的值,并且只有在a的值等于传入的参数x减一时,才会将a的值变为x,也就是实现对a的加一的操作。流程如下所示:
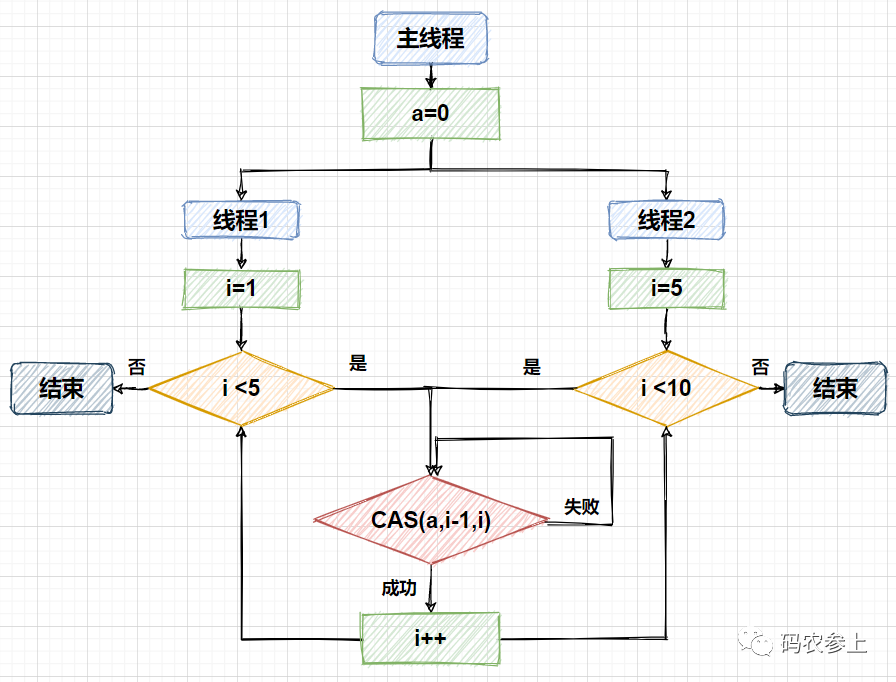
需要注意的是,在调用compareAndSwapInt方法后,会直接返回true或false的修改结果,因此需要我们在代码中手动添加自旋的逻辑。在AtomicInteger类的设计中,也是采用了将compareAndSwapInt的结果作为循环条件,直至修改成功才退出死循环的方式来实现的原子性的自增操作。
6、线程调度
Unsafe类中提供了park、unpark、monitorEnter、monitorExit、tryMonitorEnter方法进行线程调度,在前面介绍AQS的文章中我们提到过使用LockSupport挂起或唤醒指定线程,看一下LockSupport的源码,可以看到它也是调用的Unsafe类中的方法:
public static void park(Object blocker) {
Thread t = Thread.currentThread();
setBlocker(t, blocker);
UNSAFE.park(false, 0L);
setBlocker(t, null);
}
public static void unpark(Thread thread) {
if (thread != null)
UNSAFE.unpark(thread);
}
LockSupport的park方法调用了Unsafe的park方法来阻塞当前线程,此方法将线程阻塞后就不会继续往后执行,直到有其他线程调用unpark方法唤醒当前线程。下面的例子对Unsafe的这两个方法进行测试:
public static void main(String[] args) {
Thread mainThread = Thread.currentThread();
new Thread(()->{
try {
TimeUnit.SECONDS.sleep(5);
System.out.println("subThread try to unpark mainThread");
unsafe.unpark(mainThread);
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
System.out.println("park main mainThread");
unsafe.park(false,0L);
System.out.println("unpark mainThread success");
}
程序输出为:
park main mainThread
subThread try to unpark mainThread
unpark mainThread success
程序运行的流程也比较容易看懂,子线程开始运行后先进行睡眠,确保主线程能够调用park方法阻塞自己,子线程在睡眠5秒后,调用unpark方法唤醒主线程,使主线程能继续向下执行。整个流程如下图所示:
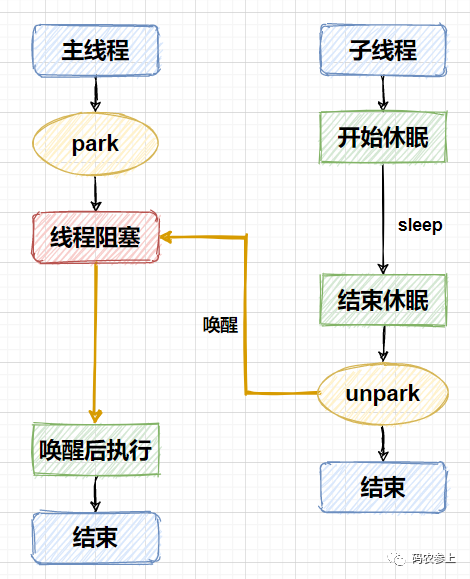
此外,Unsafe源码中monitor相关的三个方法已经被标记为deprecated,不建议被使用:
//获得对象锁
@Deprecated
public native void monitorEnter(Object var1);
//释放对象锁
@Deprecated
public native void monitorExit(Object var1);
//尝试获得对象锁
@Deprecated
public native boolean tryMonitorEnter(Object var1);
monitorEnter方法用于获得对象锁,monitorExit用于释放对象锁,如果对一个没有被monitorEnter加锁的对象执行此方法,会抛出IllegalMonitorStateException异常。tryMonitorEnter方法尝试获取对象锁,如果成功则返回true,反之返回false。
7、Class操作
Unsafe对Class的相关操作主要包括类加载和静态变量的操作方法。
a、静态属性读取相关的方法:
//获取静态属性的偏移量
public native long staticFieldOffset(Field f);
//获取静态属性的对象指针
public native Object staticFieldBase(Field f);
//判断类是否需要实例化(用于获取类的静态属性前进行检测)
public native boolean shouldBeInitialized(Class<?> c);
创建一个包含静态属性的类,进行测试:
@Data
public class User {
public static String name="Hydra";
int age;
}
private void staticTest() throws Exception {
User user=new User();
System.out.println(unsafe.shouldBeInitialized(User.class));
Field sexField = User.class.getDeclaredField("name");
long fieldOffset = unsafe.staticFieldOffset(sexField);
Object fieldBase = unsafe.staticFieldBase(sexField);
Object object = unsafe.getObject(fieldBase, fieldOffset);
System.out.println(object);
}
运行结果:
false
Hydra
在Unsafe的对象操作中,我们学习了通过objectFieldOffset方法获取对象属性偏移量并基于它对变量的值进行存取,但是它不适用于类中的静态属性,这时候就需要使用staticFieldOffset方法。在上面的代码中,只有在获取Field对象的过程中依赖到了Class,而获取静态变量的属性时不再依赖于Class。
在上面的代码中首先创建一个User对象,这是因为如果一个类没有被实例化,那么它的静态属性也不会被初始化,最后获取的字段属性将是null。所以在获取静态属性前,需要调用shouldBeInitialized方法,判断在获取前是否需要初始化这个类。如果删除创建User对象的语句,运行结果会变为:
true
null
b、使用defineClass方法允许程序在运行时动态地创建一个类,方法定义如下:
public native Class<?> defineClass(String name, byte[] b, int off, int len,
ClassLoader loader,ProtectionDomain protectionDomain);
在实际使用过程中,可以只传入字节数组、起始字节的下标以及读取的字节长度,默认情况下,类加载器(ClassLoader)和保护域(ProtectionDomain)来源于调用此方法的实例。下面的例子中实现了反编译生成后的class文件的功能:
private static void defineTest() {
String fileName="F:\\workspace\\unsafe-test\\target\\classes\\com\\cn\\model\\User.class";
File file = new File(fileName);
try(FileInputStream fis = new FileInputStream(file)) {
byte[] content=new byte[(int)file.length()];
fis.read(content);
Class clazz = unsafe.defineClass(null, content, 0, content.length, null, null);
Object o = clazz.newInstance();
Object age = clazz.getMethod("getAge").invoke(o, null);
System.out.println(age);
} catch (Exception e) {
e.printStackTrace();
}
}
在上面的代码中,首先读取了一个class文件并通过文件流将它转化为字节数组,之后使用defineClass方法动态的创建了一个类,并在后续完成了它的实例化工作,流程如下图所示,并且通过这种方式创建的类,会跳过JVM的所有安全检查。
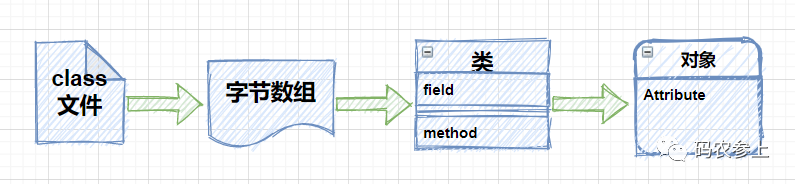
除了defineClass方法外,Unsafe还提供了一个defineAnonymousClass方法:
public native Class<?> defineAnonymousClass(Class<?> hostClass, byte[] data, Object[] cpPatches);
使用该方法可以用来动态的创建一个匿名类,在Lambda表达式中就是使用ASM动态生成字节码,然后利用该方法定义实现相应的函数式接口的匿名类。在jdk15发布的新特性中,在隐藏类(Hidden classes)一条中,指出将在未来的版本中弃用Unsafe的defineAnonymousClass方法。
8、系统信息
Unsafe中提供的addressSize和pageSize方法用于获取系统信息,调用addressSize方法会返回系统指针的大小,如果在64位系统下默认会返回8,而32位系统则会返回4。调用pageSize方法会返回内存页的大小,值为2的整数幂。使用下面的代码可以直接进行打印:
private void systemTest() {
System.out.println(unsafe.addressSize());
System.out.println(unsafe.pageSize());
}
执行结果:
8
4096
这两个方法的应用场景比较少,在java.nio.Bits类中,在使用pageCount计算所需的内存页的数量时,调用了pageSize方法获取内存页的大小。另外,在使用copySwapMemory方法拷贝内存时,调用了addressSize方法,检测32位系统的情况。
总结
在本文中,我们首先介绍了Unsafe的基本概念、工作原理,并在此基础上,对它的API进行了说明与实践。相信大家通过这一过程,能够发现Unsafe在某些场景下,确实能够为我们提供编程中的便利。但是回到开头的话题,在使用这些便利时,确实存在着一些安全上的隐患,在我看来,一项技术具有不安全因素并不可怕,可怕的是它在使用过程中被滥用。尽管之前有传言说会在java9中移除Unsafe类,不过它还是照样已经存活到了jdk16,按照存在即合理的逻辑,只要使用得当,它还是能给我们带来不少的帮助,因此最后还是建议大家,在使用Unsafe的过程中一定要做到使用谨慎使用、避免滥用。

往 期 推 荐 1、最牛逼的 Java 日志框架,性能无敌,横扫所有对手! 2、把Redis当作队列来用,真的合适吗? 3、惊呆了,Spring Boot居然这么耗内存!你知道吗? 4、牛逼哄哄的 BitMap,到底牛逼在哪? 5、全网最全 Java 日志框架适配方案!还有谁不会? 6、30个IDEA插件总有一款适合你 7、Spring中毒太深,离开Spring我居然连最基本的接口都不会写了

点分享

点收藏

点点赞

点在看