
千万级内容类产品的中台是怎样的?
说到内容,可以把它想象为一块牛肉。它首先是一头牛,然后这头牛被送进了加工厂,在一系列加工之后,通过物流送到超市,最后,你通过消费获得这块牛肉。内容也是一样,需要经过生产、加工、审核、分发等工序最后展示在用户面前。本文说的内容中台便是如此。
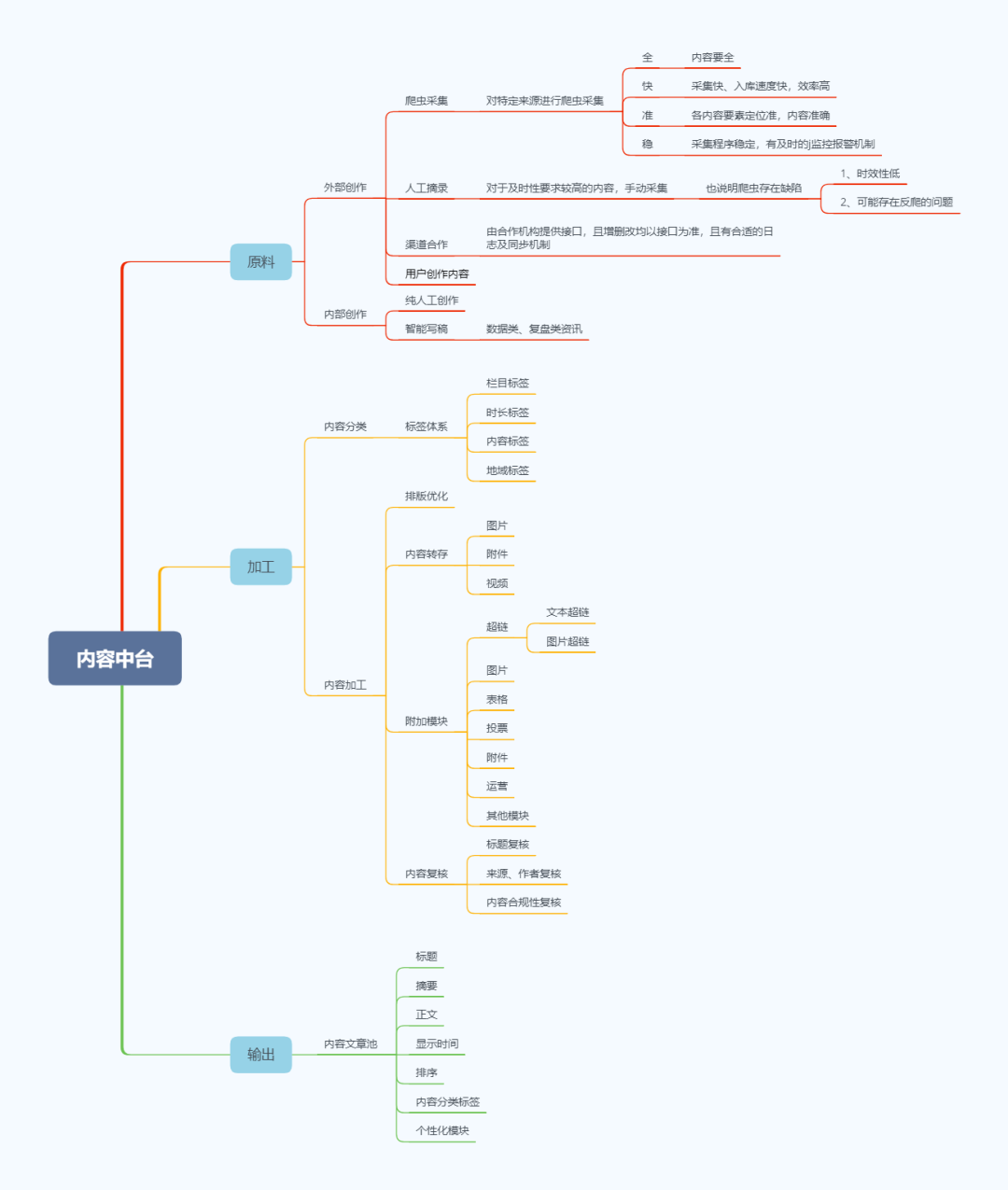
一头牛(内容原料/内容生产)
和通常说的UGC/PGC的分类不一样,此处的说的中台将内容来源分为外部创作和内部创作。
外部创作指的是爬虫采集、人工摘录、渠道合作以及用户创作内容(UGC)。
爬虫采集:是指对特定信息源进行机器爬虫采集、内容入库。此处说的特定的信息来源通常是公开信息网站,比如gov类的。
爬虫采集要求全、快、准、稳。
全,爬取的内容要全,不能把信息源的文章少爬了几篇。
快,采集要快、入库要快,最好是能在几秒钟内就出现在内部文章池,然而现在一般是在五分钟左右。
准,内容要素要准、内容定位准确,比如说不能把作者当成媒体来源。
稳,采集程序稳定,而且要有及时的监控报警机制。
人工摘录:主要是针对那些及时性要求比较高的内容,比如突发性重大新闻。这也侧面反映出爬虫采集存在一定缺陷,比如时效性低,很难做到秒级反应。此外部分来源也设有反爬虫机制,会使得内容有所缺失。这时候就需要人工摘录进行补充。
渠道合作:是指由合作商提供接口,除了常规的内容要素,还应该包含增删改信息,最好是有合适的日志以及信息同步机制。
内部创作说的是企业原创,这类又分为两种:一种是纯人工创作,另一种是智能写稿。
纯人工创作:也就是原创内容,由强大的编辑团队一手创作
智能写稿:这个有点像文字填充。产品经理在经过一系列的分析以后筛选出能够满足用户需求并且能被技术支持的文章类型,再对每一类文章编写模板并规定由机器填写的字段。此后机器就能自动产出符合要求的内容了。
加工厂(内容加工)
加工厂主要有两种“机器”,一类是标签体系(内容分类),一类是内容加工。
标签体系主要服务于构建文章池并以此作为个性化推荐的基础。比如说某篇文章的标签是{A,B},某用户的标签也是{A,B},那么这篇文章便可能有很大的概率被推送到这个用户面前。而此处的标签体系便是通过对内容的分析给它们打上各种标签以便于后续的分发和推送。值得注意的是,标签并不是越多越好,而是要遵循一定的规则,这样才能尽可能地提高匹配程度,从而提高文章的消费率。
内容加工主要有以下几步:
首先是格式的优化,对于采集过来的文章我们需要把不合适的内容去掉,比如说超链、广告等。
然后是内容转存,将文章的图片和视频转到自己的服务器上(这需要取得对方许可)。
其次还有一些附加模块,这块主要作用于各前台的特色功能或者个性化需求,比如在文章中添加图片、表格、投票、附件、运营模块(主要是banner)等。
最后是盖戳环节,就像加工厂给牛肉盖戳一样,我们需要对内容的合规性、与原文的一致性等进行复核,主要是违规词屏蔽(也就是你们在王者农药里显示不出来的芬芳)、关键词替换、原文比对等。
物流分发(内容分发)
物流分发输出的就是成品牛肉——文章池,它最重要的元素有:标题、摘要、正文、时间、排序、内容标签、个性化模块。分发的逻辑比较复杂,而且也需要配合前台具体需求,这里就不展开论述了。
最后附上逻辑图
本次分享到此结束,更多内容和免费资料请到公众号内查看哦~