
Gopher China 分享:Go 语言电子表格办公文档格式标准实践

Gopher China 致力于为中国广大的 Go 语言开发者提供最好的交流平台,国内最权威和最干货的 Go 语言大会,汇集广大 Go 语言的开发者以及大规模应用 Go 的示范企业给大家带来精彩分享。
第七届 Gopher China 大会于 2021 年 6 月 26 日至 27 日在北京举办。本次会上,续日带来了题为《Go 语言电子表格办公文档格式标准实践》的主题分享,以下是分享实录。

这是我的自我介绍,今天为什么要分享这个主题呢,我说一下准备这次分享背后的思考:近年来,随着在线办公的兴起,对办公文档云端处理有了更多需求; 企业信息化、数字化建设过程中,各类报表系统、企业应用对数据收集、录入和加工的场景越来越多,在这些场景中经常需要通过编程方式处理办公文档提供支持。XML 是一种应用十分广泛的数据标记语言,Excel 办公文档是应用复杂 XML 的典型代表之一,那么我的 Topic 就结合实践给大家分享使用 Go 语言在处理 XML 和 Excel 电子表格文档过程中的经验。

本次 Topic 有四个部分:第一部分:处理 XML 的基本模式和 Go 语言解析 XML 的原理;第二部分:Go 处理复杂 XML 时的一些技巧、遇到过的问题以及解决方式;第三部分:基于模式的 XML 解析,如何高效处理大规模 XML 文档;第四部分将介绍 Go 语言如何实现 Excel 电子表格文档标准、以及如何高效做流式处理。今天的 PPT 中会包含很多具体的代码实例。

首先是序列化与反序列化技术。先说反序列化技术,也就是对 XML 文档的解析,其典型处理方式分为两种:基于对象模型的处理和基于事件驱动的处理。

基于对象模型的处理方式,需要先对文档对象模型(DOM)进行定义,在 Go 语言中就是定义结构体。例如对于这个 XML 文档进行解析,与之对应的数据结构:Go 语言结构体 Person,结构体中有 Name、Email 等字段,与 XML 中的标签、属性一一对应,然后声明并初始化变量 p 为 Person 类型,调用 Go 语言标准库 encoding/xml 提供的 Unmarshal 函数,对 XML 文档进行解析,接着将解析结果输出。可以看到 XML 文档已经被正确地解析,标签和属性被映射到 Person 结构体中对应的字段中。至此一个简单的解析 XML 就完成了。
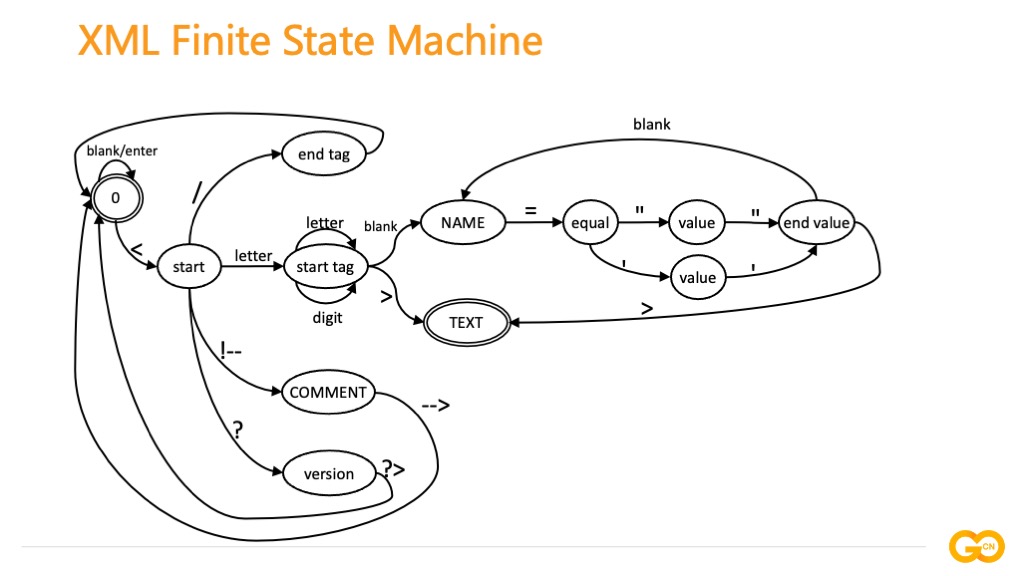
那么这样一个看似简单的过程,背后是如何实现的呢,先了解一下对 XML 文本进行词法分析,根据输入字符构成的词素状态建立 NFA 非确定型有限状态自动机,当输入一个字符或者条件得到一个状态机的集合,实现对 XML 的解析过程要比 JSON 相对复杂,这里我们主要关注 6 个状态:start tag、end tag、COMMENT、Version、Name 和 Text。
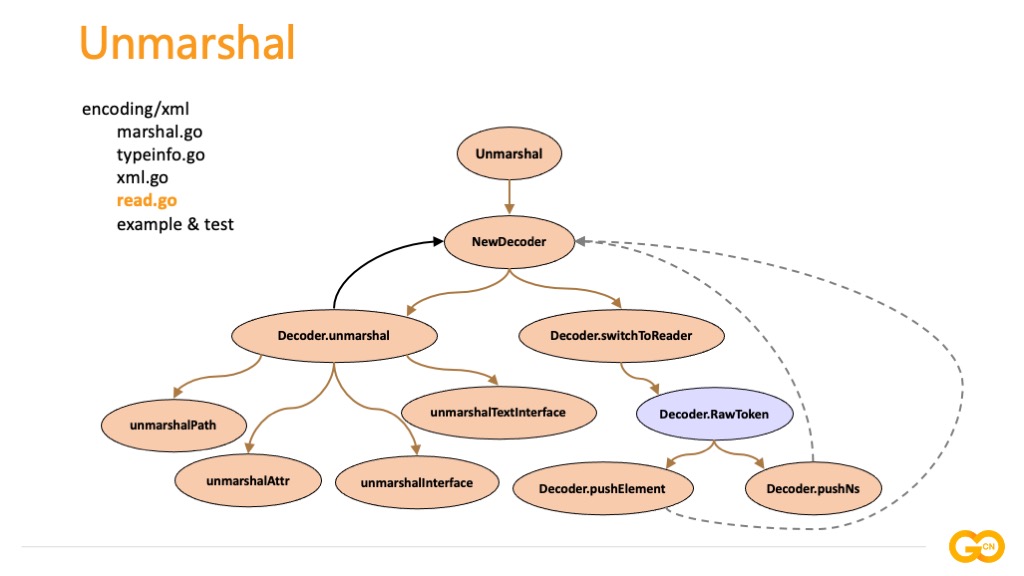
Go 语言标准库中对 XML 的处理共 4 个源码文件,当我们调用 Unmarshal 进行反序列化操作的时候,主要的内部处理过程是这样的,先通过 NewDecoder 初始化 Decoder 对象,程序判断当前为反序列化操作,switcherToReader 进入 XML 解析模式,对 XML 状态机的实现在 RawToken 内部函数中进行,在词法分析每个子状态中调用对应的处理指令(例如 pushElement、pushNs 等)构建 Token,接着调用 unmarshal 函数,通过反射对象模型内的字段信息,将不同类型的 Token 通过 unmarshalAttr、unmarshalInterface、unmarshalPath 等函数到对应的 Field 上面,完成解析过程。

观察 Decoder 解码器的数据结构定义,其中字段 Strict 定义了 XML 解析模式,AutoClose 用来处理自关闭标签,Entity 处理 XML 实体还包含其他 15 个未导出字段供内部处理使用。Go 语言中 XML _Token 主要分为六大类:StartElement 起始标签、EndElement 结束标签、CharData 字符数据、Comment 注释、ProcInst 和 Directive 是 XML 处理指令。在使用 Unmarshal 解析 XML 文档的时候,标准库内部先是通过 Decoder 读取 XML 文本字符流,这是一种流式解析方式,再此过程生成 Token 确定当前解析状态,所以通过 Token 的类型可以得知当前解析进程,基于 Token 对 XML 文档进行的解析就是事件驱动解析模式。

基于事件的驱动方式,可以直接调用 Go 语言 XML 标准库提供的 NewDecoder 方法,遍历 Token 终止条件为当其值为 nil,根据 Token 类型可以获得当前解析事件,常用的是 StartElemtent 和 EndElement 两个事件,该方式给开发者暴露了相对底层的接口,使用基于事件的方式处理同样一个 XML 文档,输出结果与 XML 文档中标签开闭的顺序相一致,显然这种方式无法进行回溯,如有需要开发者必须在程序内部自行维护与状态。对于一般普通的简单 XML 文档解析,使用基于文档模型的方式更灵活方便,Go 语言提供了多种解析与生成控制 flags。

关于反序列化和序列化控制,在标准库的 typeinfo.go 源码中定义了可用于在文档对象模型数据结构中使用的 Tag,主要有 7 种:带有 ”,attr” 标签的字段会成为 XML 元素的属性,其中属性的名字为字段的名字;带有 ”,cdata” 和 ”,chardata” 标签的字段将会被封装为字符数据而不是 XML 元素;带有 ”,innerxml” 标签的字段会以原样进行解析和编码;带有 ”,comment” 标签会被作为注释解析和编码;带有 ”,any” 标签的字作为以上几种规则失效的 failback 映射;带有 “omitempty” 选项的字段,其值为空时,这个字段将被忽略不参与解析与编码。在这个例子中,Tag 声明了结构体中的 Where 字段对应 XML 文档中的 where 属性,并且当该值为空的时候,不会进行反序列化和序列化。

利用控制 Tag 可以在业务中实现局部解析,在这个这个例子中,Person 包含 Name 和 Email 两个子标签,而 Email 还包含一个 Addr 的子标签,如果希望 Email 被延迟解析,可以将 Email 单独定义为 innerXML,当后续有解析需要时再对 Email.Content 进行一次反序列化操作即可,可以看到 Email 的 Content 没有参与解析,其原始值被保留。这种方式在处理嵌套层级深且复杂的 XML 文档时是一个可以参考的方法,避免了不必要的资源消耗有助于提高性能。

接下来进一步聊一聊对于复杂 XML 的处理,XML 标准是一套复杂的规范,Go 语言并没有完全对该标准进行实现,在实际生产应用过程中一些复杂情形需要做一些额外的处理,下面介绍 Go 在处理 XML 文档时在数据类型、实体和幂等性三个方面遇到的问题或需要注意的点。
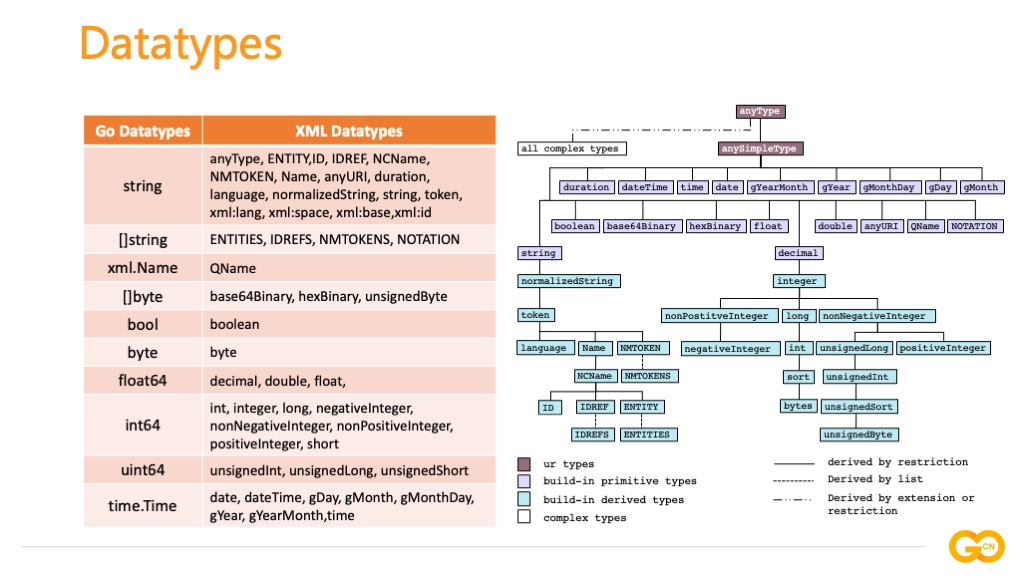
首先是数据类型,XML 标准规范中定的数据类型有 49 个,其中包含用户派生数据类型(紫色)、内置原始数据类型(淡紫色)、内置派生数据类型(蓝色)和复合数据类型(白色),它们的派生关系如右侧这张图片所示。左侧这张表梳理了 Go 语言的数据类型与 XML 数据类型之间的映射关系。当我们在处理复杂 XML 文档或在跨语言处理 XML 文档时需要关注数据类型的问题,数据类型的不一致可能导致潜在的数据校验失败、数据精度错误等问题,对于 XML 专有的数据类型根据需要单独实现。

XML 实体是用于定义引用普通文本或特殊字符的快捷方式的变量,在这个例子中包含两个实体声明 name 和 email,而 person 中的 &name; 和 &email; 是实体引用,Go 语言目前不完全支持对该 XML 的解析,需要开发者先对实体进行提取,在已经了解 Go 语言内部是如何处理 XML 文档的原理之后,可以知道实体信息存储于Directive 类型的 Token 中,通过正则表达式对实体声明进行模式匹配进行提取,将提取结果输出验证。
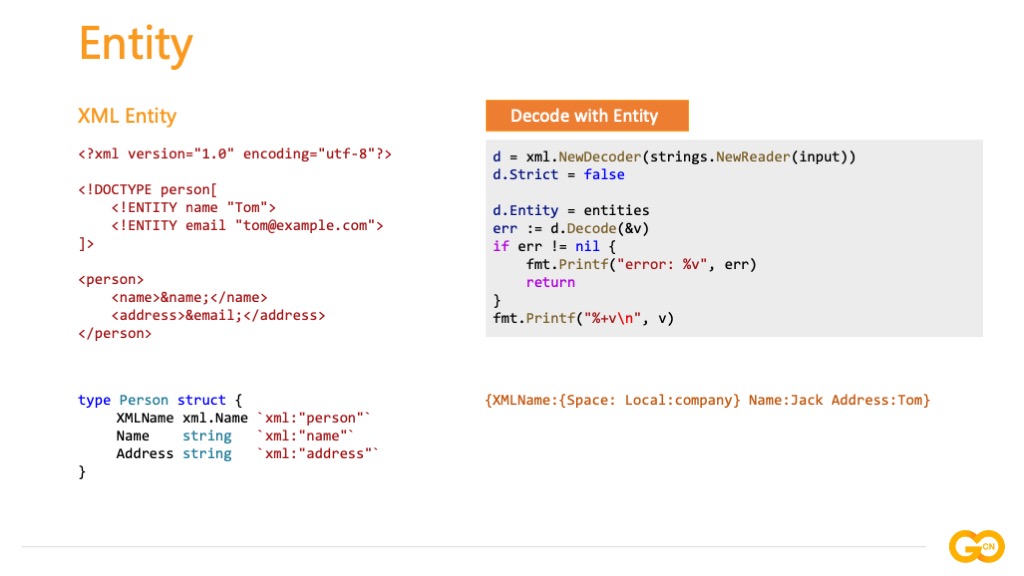
在提取实体声明之后再进行 XML 解析,关闭 XML 严格模式并设置 Decoder 的 Entity 为刚刚提取到的实体声明即可。将解析结果输出验证可以看到带有实体的 XML 文档被正确解析。

这是一个处理带有多命名空间 XML 的例子:标签 person 中声明了默认命名空间和其余三个命名空间 m、h 和 w,标签 m 拥有两个隶属于不同命名空间下的同名属性 addr,在解析该 XML 文档时需要将命名空间 URI 在控制 Tag 中的属性名称当中声明,需要注意的是标签 email 在 m 命名空间下,它的命名空间需要在 Email 结构体中通过 xml.Name 声明,而不是定义在结构体外,这样就可以正确解析带有多命名空间的 XML 文档到 Person 结构体中了,然而如果将反序列化后到对象通过 Marshal 序列化,person 中除默认命名空间之外的其余命名空间全部丢失,这就是反序列化 / 序列化幂等性问题,序列化输出与原始 XML 文档内容存在内容缺失。

为了解决该问题,需要先了解 Go 语言中对 XML 命名空间和文档对象模型是如何映射的:每个 StartElement 类型的 Token 中都有一个名为 Name 的字段用以映射命名空间,还有一个 Attr 数组用以存储该标签的属性。Name 数据结构中定义了命名空间名称和 Local name,Attr 结构体中也有名为 Name 字段用以存储该标签的命名空间,所以在解析 XML 后命名空间的原始结构没有丢失,开发者可以通过事件驱动解析的方式实现一个 getRootEleAttr 的函数来收集并存储 XML 文档根标签的全部属性。

当序列化带有多命名空间的 XML 时,如果根节点标签命名空间无变化,可以在基于事件解析的过程中通过根标签属性中的 Name.Space、Name.Local 和 attr.Value 构造命名空间声明字符,替换序列化结果中的 root element;如果在解析 XML 后根标签属性中的命名空间信息有改变,维护解析时通过 getRootEleAttr 得到的命名空间信息,序列化时同样可以拼接出带有完整 namespace 的 root element,这样即可保证反序列化 / 序列化幂等。

在 Topic 的第三部分,分享高效处理 XML 的经验。这里的高效从两方面理解:一方面是在处理大规模复杂 XML 文档时如何保证功能实现的高效;另一方面是如何在 DOM 解析和 SAX 解析方式上做选择实现高性能。

先来看如何保证功能实现的高效。来看这样一个例子:一个根标签为 note 的 XML 文档,其 XSD 模式描述如下,XSD 是对 XML 的模式描述,对于大规模 XML 文档可根据 XSD 对 XML 做验证。回到这个例子中,XSD 中通过 element 声明了名为 note 的对象是一个标签,complexType 声明该标签包含一个复杂类型对象,sequence 声明该复杂类型对象包含子标签序列,按顺序依次有 4 个子标签,其中 body 标签在名为 m 的命名空间下、且为必选标签,在 XSD 第 2 行声明了该命名空间的 URI,第 3 行声明该命名空间引自外部名为 shared.xsd 的模式中;在 shared.xsd 中定义了标签 body 的数据类型为 string。

基于 XSD 模式可以定义解析该 XML 的文档对象模型 Go 语言结构体最终如下。我们需要解析的 XML 文件中包含很多可选标签或属性,尤其在大规模 XML 处理过程中,可以利用 XSD 模式高效生成文档对象模型。
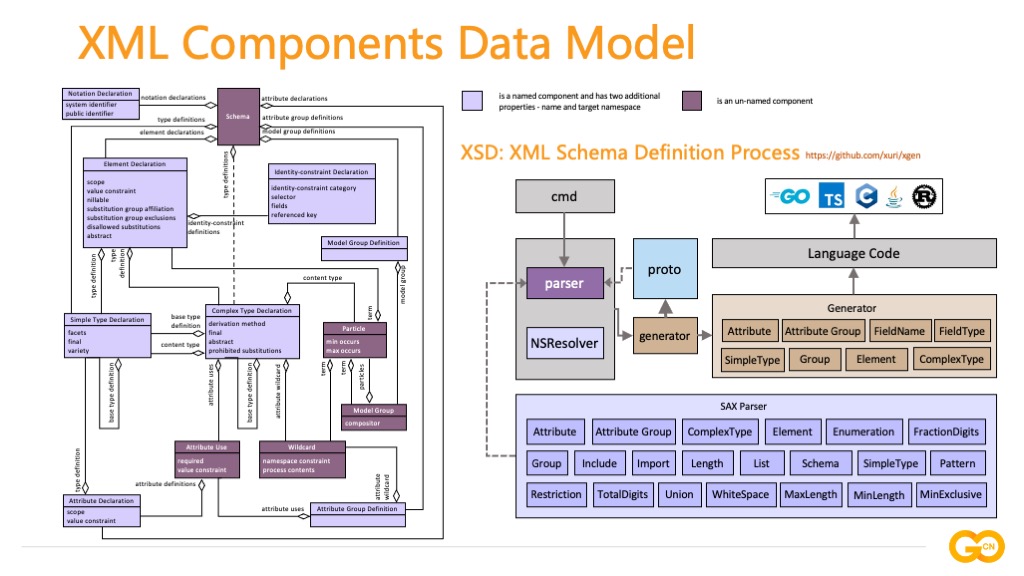
这是 XML 模式组件数据模型的 UML 类图,我们可以直观理解 XML 模式的基本组成,进而通过 XSD 可以生成解析 XML 文档的文档对象模型,这种方式在处理大规模复杂 XML 模式时能够有效提升开发速度。其翻译过程如右图所示:基于事件驱动解析 XML 文档,并根据模式状态机将 Token 映射到模式 proto 上完成内存模型的准备工作,文档模型的生成针对每个 XSD 组件分别实现代码生成器,最终可以为 Go、TypeScript、C、Java 和 Rust 等语言生成 XML 文档对象模型代码。这种方法应用于 Excel 电子表格文档基础库的实现过程中,效果十分显著,Office 办公文档中包含超过数以万计 XML 标签和属性,这些标签组合嵌套错综复杂,如果人工定义编写结构体工程量十分庞大且容易出错,文档对象模型代码的生成可将 XSD 转化为 Go 语言结构体代码,大幅提升开发效率。

再谈 XML 处理的性能:对于基于事件的 SAX 解析和基于文档对象模型的 DOM 解析如何抉择?表格中总结了两种方式的优缺点。总的来说 DOM 方式更适合处理复杂 XML 文档、内存占用相对较高、开发维护成本低;SAX 方式适合处理结构简单的 XML 大文件,更省内存占用,但无法回溯,维护成本相对较高。实际业务中两种解析方式根据场景来做选择。

进入分享的第四部分:下面将分享 Go 语言在处理 Excel 电子表格办公文档方面的实践。
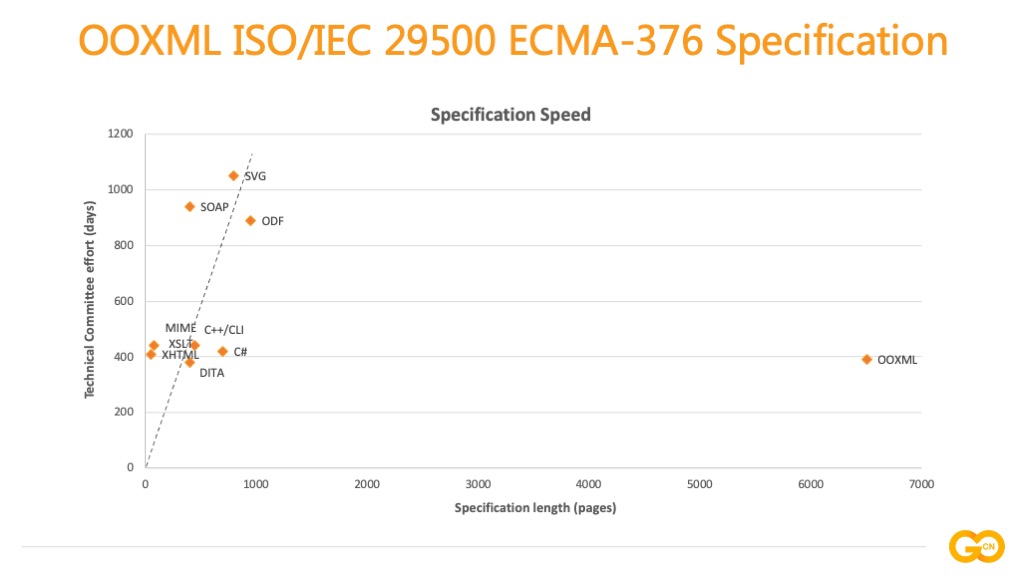
Office 办公文档的技术标准:两个名称 ISO/IEC 29500 或 ECMA-376,简称 OOXML,是基于 XML 技术的国际标准。大家所熟知的 Word、Excel、PowerPoint 办公文档都遵循该标准。这是一套十分庞大复杂的技术标准,这张图来自中国工程院倪光南院士在中欧研讨会上的分享,对比了 OOXML 与其他国际技术标准,横轴是标准规格书的页数,也就是描述该标准文档的页数;纵轴是技术委员会讨论天数,可以看到像 ODF、SVG 等技术标准的规格书都在 1000 页以内,形成标准周期在三年左右,而 OOXML 的标准规格书长达 6000 余页,大家可以在 ECMA 或 ISO 国际标准化网站下载该文档。Excelize 是 Go 语言操作电子表格文档的基础库,对该标准的部分内容进行了实现,下面我先向大家简要介绍该标准内容。
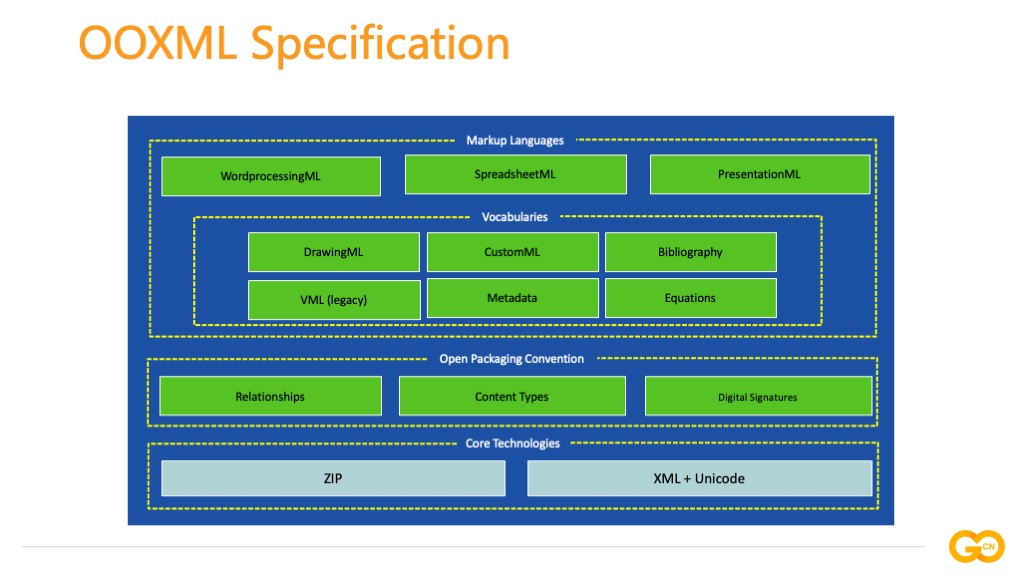
OOXML 的底层是基于 ZIP、XML 和 Unicode 的核心技术,将一个 Office 文档扩展名修改为 zip 进行解压即可得到一个文件夹,其中包含若干子文件夹和 XML 文档,这种设计相比于二进制类型文档格式也具备更好的兼容性。向上一层为开放包装公约(Open Packaging Convention),简称 OPC,定义了文档内部组件之间的关联依赖关系(Relationships)、文档内容类型(Content Types)和数字签名(Digital Signatures)。通用标记是跨应用的文本标记语言:囊括可视化图表、可扩展标记、源数据和目录引用等。上层是标记语言部分(Markup Language),它由四类标记语言组成:Word 文档对应的标记语言叫 WordprocessingML,电子表格则是 SpreadsheetML,演示文稿对应的是 PresentationML。除此之外 Office 文档支持进行跨应用的嵌套,例如:Word、PowerPoint 中可以嵌套 Excel。
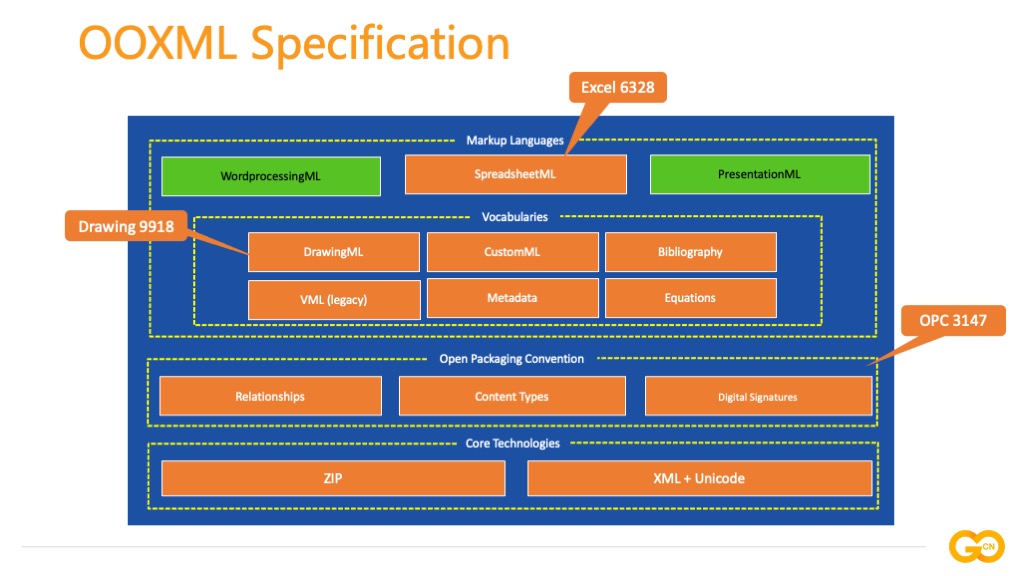
使用 Go 语言实现电子表格文档基础库,需要实现的图中橙色高亮的部分,通过 XSD 的定义可以得知其中涉及 XML 标签和属性的分布情况:Drawing 有 9918 个,OPC 有 3147 个,SpreadsheetML 有 6328 个。数据结构十分复杂,通过手工方式编写这些标签的结构体效率很低且易出错,通过 XML 模式来生成文档对象模型代码。
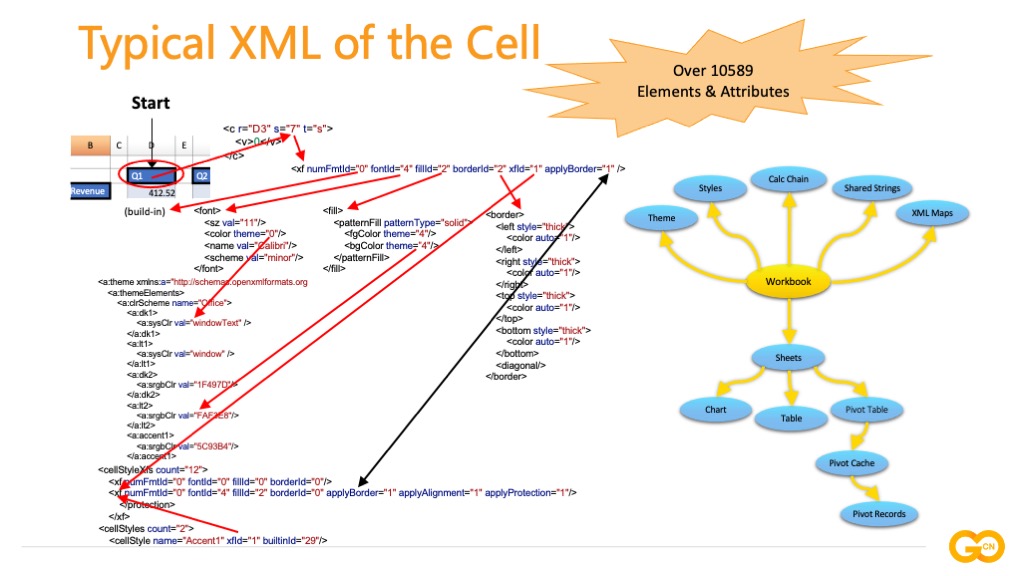
举一个典型的读取或创建单元格的例子:坐标为 D2 的单元格值是 Q1,带有蓝色背景色和黑色的实线边框样式。下面是处理过程:图中的这些 XML 的片段来源于目录中的不同文件,每个 c 标签代表一个单元格,s 属性值为 7 代表单元格应用了索引为 7 的样式,我们去 styles.xml 当中找到索引为 7 的样式,通过 xf 标签的 fontId 和 fillId 属性可以确定字体 ID 和 单元格填充样式 ID,borderId 和 applyBorder 属性对应边框样式的定义和边框是否开启,numFmtId 是数字格式相关的定义。根据每一个字段向下去找,可以看到字号是 11,字体是 Calibri,包括单元格填充的颜色,颜色如果用到主题色,再去主题索引查找所对应的主题,找到颜色的色值,根据具体的色值表示方法,需要对色值进行换算。后面是对于边框的处理,根据边框 ID 为 2 找到它的上下左右边框样式定义。最后样式处理完成,到这里我们还没有看到对单元格值 Q1 的定义,这个图里没有体现出 Q1 的实际存储结构。大家可以看到 v 标签的值是 0,而不是 Q1 这个字符,由于该单元格的值是字符串类型,不会随单元格存储,根据索引 0 到字典中查找就可以读到单元格的值了。这个过程涉及到跨多个 XML 文档的处理,需要对 Excel 文档内部结构比较了解,典型的结构包括:工作簿(Workbook)包含多个工作表(Sheets),工作表包含图表(Chart)、表格(Table)和数据透视表(Pivot table)等,数据透视表又包含数据透视缓存(Pivot Cache)和数据透视记录(Pivot Records)。另外,工作簿还与主题(Theme)、样式(Style)、公式计算链(Calc Chain)以及共享字符表(Shared Strings)等部分有关联关系。在了解这些之后就可以实现该技术标准了,其中涉及累计超过 1 万个不同的 XML 标签与属性。

一般来说 XML 文档的首行会声明文档编码,XML 支持累计 228 种编码类型,在使用 Go 语言处理非 UTF-8 编码的XML 文档时,可以在解析时设置 XML 标准库的 CharsetReader 为 charset 包的 NewReaderLabel 可以解决绝大多数常用的文档编码,此外也可以使用自定义的字符集转码函数进行处理。
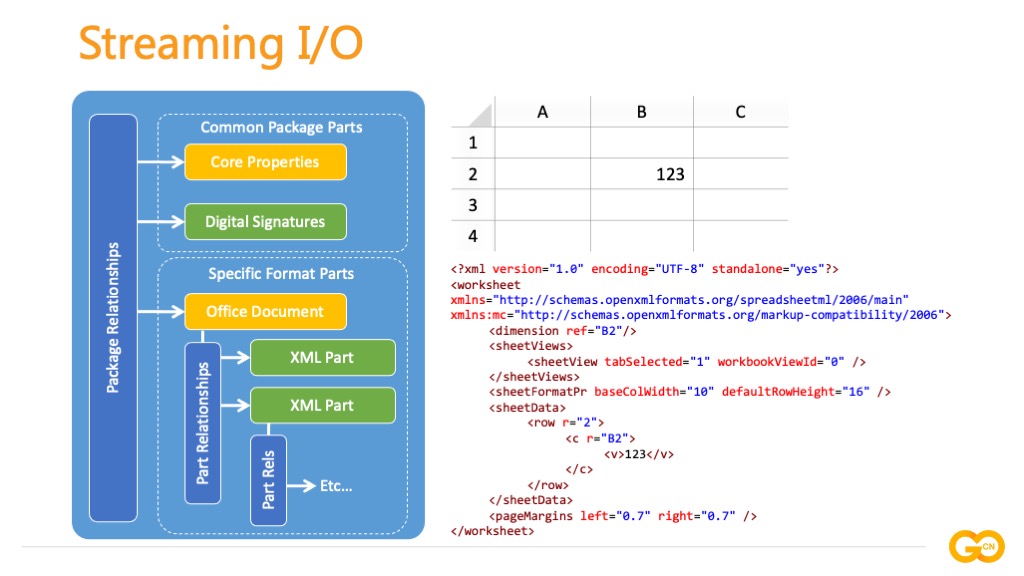
对于包含大规模数据的电子表格文档,使用流式处理可以获得更好的性能。利用基于事件驱动的方式进行流式读取,但对于生成文档, XML 本身没有“流式生成”的概念,下面就介绍一下如何用 Go 语言来“流式生成” Excel 文档。对于一个典型的 Excel 文档内部结构:其中包含了开放包装公约、显式关系、隐式关系等文档组件,往往数据量最大的部分是存储于工作表中的单元格。Excel 文档中单元格数据结构是什么样的呢:在每个工作表对应的 XML 中,sheetData 标签存储着全部单元格的数据,内部按行进行排布,例如 B2 单元格的值为 123,在行号为 2 的 row 标签的 c 子标签中,c 标签的 r 属性标记该单元格坐标,单元格的值存储于 v 子标签中,该结构构成了单元格数据结构的最小单元。除此之外在 sheetData 上下文中存储着其他工作表部件。

“流式写入”可以避免在创建包含大量单元格工作表过程中文档对象模型在内存中的大量分配,但是需要实现该功能需要维护整个工作表的数据状态,按照行号依次写入,对于每张工作表有对应的流式写入器 StreamWriter,其中还要维护支持流式写入的数据结构和上下文信息,例如当前工作表名称、ID、合并单元格和表格等,在准备对工作表进行流式写入之前,先初始化流式写入器,创建对应的缓冲区,当写入单元格时,根据单元格的数据结构来构造字符流写入缓冲区,为了控制内存占用,当缓冲区大小达到阈值时将会在系统临时目录进行磁盘缓存,根据每个单元格状态通过字符串拼接的方式进行流式生成,该过程需确保生成的 XML符合格式标准,一旦拼接出错将会导致最终保存生成文档无法被 Excel 程序所正确打开。

通过 Flush 终止流式写入进程,首先进行单元格状态的处理 sheetData 的标签是否需要提前关闭,然后将单元格之外的工作表部件数据分段序列化:例如合并单元格、表格等,序列化结果全部追加写入缓冲区完成流式写入,该设计模式不仅支持流式设置单元格,也可以扩展:支持设置列宽、单元格样式、流式合并单元格、流式设置表格等,此时工作表的完整数据加载至内存中,内存占用仅为使用文档对象模型的 10%。

保存工作簿,当保存或另存为工作簿时,依次将各文档部件序列化写入 ZIP 包中,同时读取缓冲区中的流式写入数据写入 ZIP 中,完成保存,至此一个完整的工作表生成过程就完成了。需要注意的是这里的流式写入是对于工作表单元格数据、共享字符表等典型的容易产生大规模数据的区域进行流式生成,而像文档属性、主题、数据透视表、批注评论、图表等部分采用文档对象模型处理则更好。
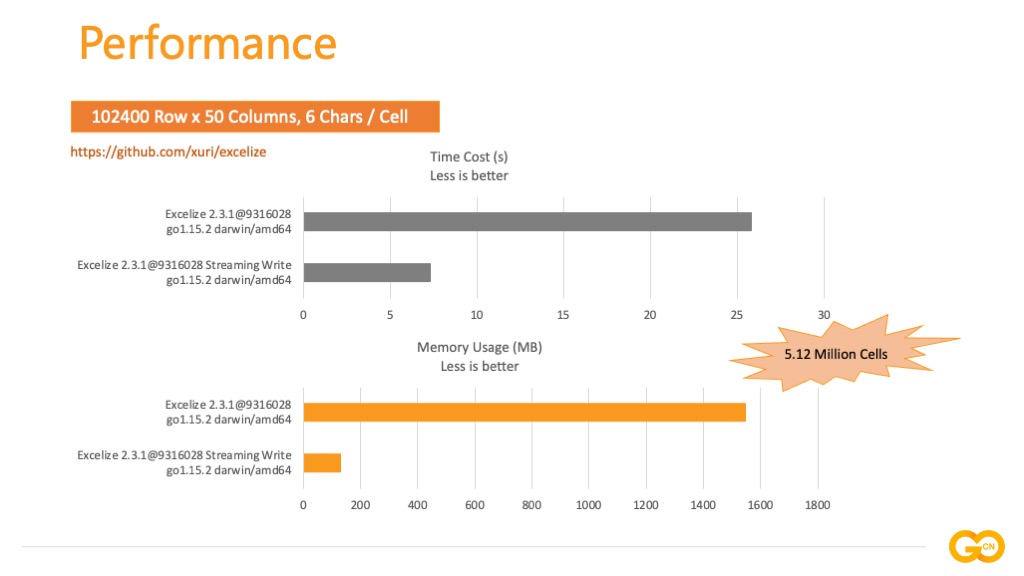
开源 Excel 文档基础库 Excelize 结合了以上两种处理方式,在保障兼容性和性能上做了平衡,生成 10.24 万行 50 列,每个单元格 6 个字符,累计 512 万单元格的工作表,对比普通和流式处理模式的性能,通过实测可以看出普通写入在耗时方面大约是流式生成的 5 倍,内存占用是流式写入的 7 倍。
电子表格作为大规模应用复杂 XML 的典型代表,在使用 Go 语言实现 Excel 文档基础库过程中,根据业务场景选择合适的处理方式,把其中的技术原理和应用实践经验给大家做了分享,其中一些设计和方法除了在办公文档领域、也可以在其他领域被泛化应用,希望能够对有需要的朋友有所帮助。