
3万字聊聊什么是Redis(七)
大家好,我是Leo
上一篇我们介绍了
缓存和数据不一致性引发的问题不同的缓存类型以及解决访问。 Redis常见的生产问题,缓存雪崩,击穿,穿透, 由穿透又聊到了布隆过滤器缓存污染以及应用措施, 顺带的聊了一下LFU和LRU的经典之处
继上篇Redis技术总结六,我们继续聊聊Redis的相关技术!
这篇主要是介绍一下Redis并发的解决方案
推荐阅读
分享语录:罗翔老师说过一个人真正的成功,不是在他辉煌的时候有多么的风光,绝大多数人让你登上辉煌的舞台也都会有辉煌的成就。但关键在于在你挫折的时候在你低迷的时候,你是不是依然有勇气继续的前行。
个人想法: 你是否能接受眼前摸不着看不见的东西你依然愿意选择相信,选择努力!
你想拥有别人没有的东西,那就要做别人做不了的事情。
Redis如何应对并发
我们使用Redis时,一定会遇到并发访问问题,比如我最近一直常遇到的电商项目。在进行修改库存时,控制不好就会出现库存不正确的情况。
为了保证数据的正确性,Redis提供了两种方法
加锁 原子操作
加锁
加锁是我们在解决并发访问时,最先接触,也是最简单的一种操作,客户端需要先获得锁,否则就无法进行操作,当一个客户端获得该锁后,其他客户端就无法进行更新数据操作。只有客户端释放锁后,另一个客户端才能拿到这把锁更新操作。
上述方案主要有两个问题:
每次操作只允许一个用户也就是只允许一个客户端进行操作。极大的降低了性能的并发访问性能。 Redis锁必须用分布式锁。而分布式锁实现复杂,需要用额外的存储系统来提供加解锁操作
原子操作
原子操作是另一种提供并发访问控制的方法。原子操作是指执行过程保持原子性的操作,而且原子操作执行时并不需要再加锁,实现了无锁操作。这样一来,既能保证并发控制,还能减少对系统并发性能的影响。
原子操作主要分两种
Redis单命令操作,可以说是原子操作 多个命令写入Lua脚本,比原子性的方式执行单个Lua脚本
Redis单命令操作,我们可以理解成电商项目的修改库存,从读取到修改到写入。一气呵成!采用一个命令实现,我们可以使用INCR/DECR 命令。
Redis的Lua脚本,是在我们无法使用单命令实现需求时,同时也要保证并发控制时的一种方案。比如使用的判断一些的写法就必须采用Lua脚本实现。
Redis的分布式锁
聊到分布式锁的实现,我们可以先来看看单机锁吧。
对于在单机上运行的多线程程序来说,锁本身可以用一个变量表示。
变量值为 0 时,表示没有线程获取锁; 变量值为 1 时,表示已经有线程获取到锁了。
我们保证数据不被其他访问修改时,底层的实现就是判断访问时拿到的这个变量与修改时的变量是否是一致的。如果是一致的就说明数据可以修改,如果不是一致的说明有线程先行一步把这个值改动了。那如果再动的话数据肯定就错了。
科普一下MySQL,MySQL里利用的是每条数据的版本号来判断的。
分布式锁也是同样的原理实现的。加锁和释放锁的逻辑和单机锁是一样的。加锁时同样需要判断锁变量的值,根据锁变量值来判断能否加锁成功;释放锁时需要把锁变量值设置为 0,表明客户端不再持有锁。
和单机锁不同的事,分布式的锁必须由一个共享的存储系统来维护。只有这样,多个客户端才可以通过访问共享存储系统来访问锁变量。相应的,加锁和释放锁的操作就变成了读取、判断和设置共享存储系统中的锁变量值。
实现分布式锁需要注意哪些要求
加锁与释放锁的过程涉及多个操作,一定要保证原子性 利用共享存储系统保存锁变量时,如果共享存储系统发生宕机如何处理?我们需要保证共享存储系统的可靠性。
单个节点
Redis可以采用键值对保存锁变量,再接收和处理不同客户端发送的加锁和释放锁的操作请求。
我们一点一点分析一下,键值对又是如何处理的呢?
我们要赋予锁变量一个变量名,把这个变量名作为键值对的键,而锁变量的值,则是键值对的值,这样一来,Redis 就能保存锁变量了,客户端也就可以通过 Redis 的命令操作来实现锁操作。为了便于理解,如下图所示(引用蒋德均老师)
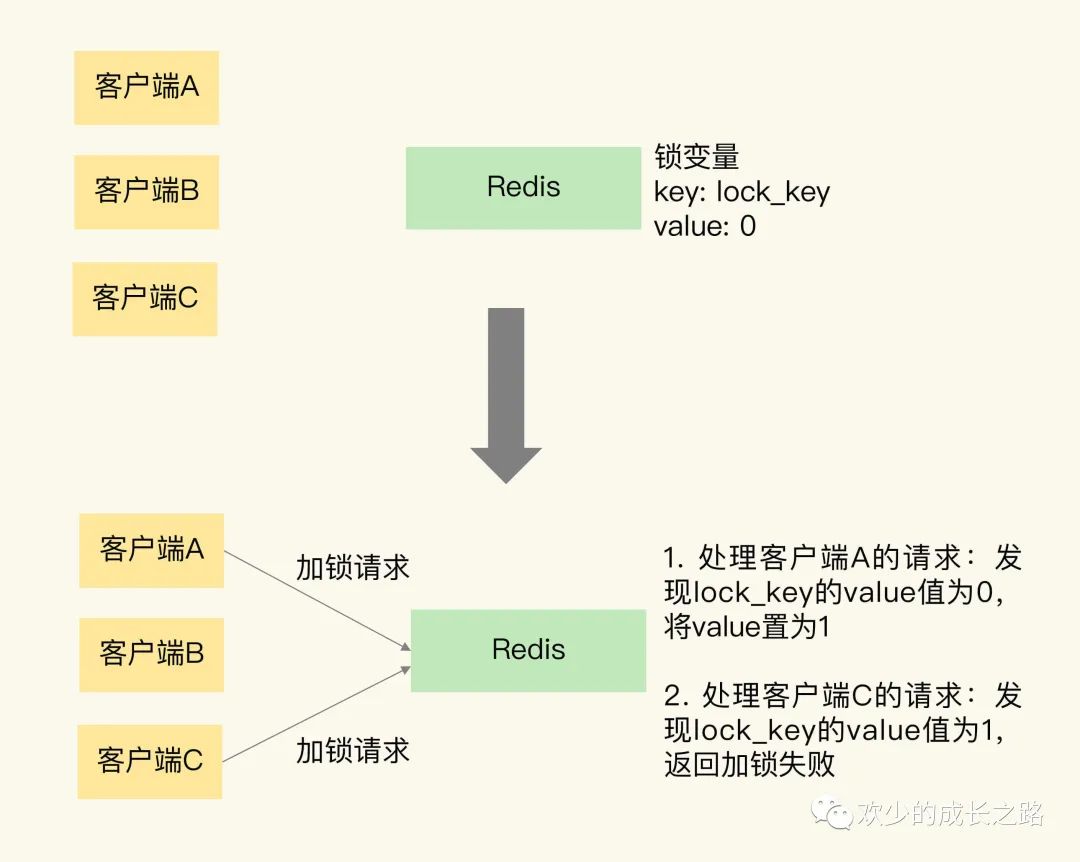
加锁之后如果要释放锁的话,就是把变量的value值变成0。
看似没有问题,其实还是有问题的。问题就出在 读取锁变量如何保证原子性?
我们之前聊过一个是单命令执行,另一种是Lua脚本执行。这个场景我们依然可以这样处理
通过使用Redis提供的 SETNX命令(这个命令在执行时会判断键值对是否存在,如果不存在,就设置键值对的值,如果存在,就不做任何设置)通过Lua脚本判断处理
用户在执行完加锁操作后,需要释放锁,释放锁就是把value标志为0。可以采用SETNX 和 DEL 命令组合来实现加锁和释放锁操作。下面贴一下伪代码方便大家理解下。
// 加锁
SETNX huanshao_lock_key 1
// 业务处理(库存,用户积分,订单号等)
DO THINGS
// 释放锁
DEL huanshao_lock_key
有何风险?
假如某个客户端在执行了 SETNX 命令、加锁之后,紧接着却在操作共享数据时发生了异常,结果一直没有执行最后的 DEL 命令释放锁。因此,锁就一直被这个客户端持有,其它客户端无法拿到锁,也无法访问共享数据和执行后续操作,这会给业务应用带来影响。 如果客户端 A 执行了 SETNX 命令加锁后,假设客户端 B 执行了 DEL 命令释放锁,此时,客户端 A 的锁就被误释放了。如果客户端 C 正好也在申请加锁,就可以成功获得锁,进而开始操作共享数据。这样一来,客户端 A 和 C 同时在对共享数据进行操作,数据就会被修改错误,这也是业务层不能接受的
如何解决?
可以通过给锁设置过期时间,就算是共享存储系统崩溃了,或者异常了这个锁再一段时间后就会自动释放了。 我们需要能区分来自不同客户端的锁操作,我们可以给不同客户端设置一个唯一值,在释放锁操作时,客户端需要判断,当前锁变量的值是否和自己的唯一标识相等,只有在相等的情况下,才能释放锁。这样一来,就不会出现误释放锁的问题了
可以通过如下指令进行设置
// 加锁, unique_value作为客户端唯一性的标识
// [EX seconds 分钟 | PX milliseconds 秒钟 ]
SET huanshao_lock_key unique_value NX PX 10000
我们刚刚在说 SETNX 命令的时候提到,对于不存在的键值对,它会先创建再设置值(也就是“不存在即设置”),为了能达到和 SETNX 命令一样的效果,Redis 给 SET 命令提供了类似的选项 NX,用来实现“不存在即设置”。如果使用了 NX 选项,SET 命令只有在键值对不存在时,才会进行设置,否则不做赋值操作。此外,SET 命令在执行时还可以带上 EX 或 PX 选项,用来设置键值对的过期时间。
释放锁时,不能再像之前那样简简单单的DEL就删了,需要判断当前是否是自己的锁,伪代码如下
//释放锁 比较unique_value是否相等,避免误释放
//KEYS[1]表示 huanshao_lock_key,ARGV[1]是当前客户端的唯一标识
//这两个也是调用Lua脚本时,必传的两个参数
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
如果采用这种方式的话,为了保证原子性肯定要上Lua脚本了。
多个节点
多节点的话和单节点差不多,但是有个很大的区别就是不能依赖单个命令操作了。我们需要按照一定的步骤和规则进行加解锁操作,否则,就可能会出现锁无法工作的情况。 分布式锁的算法
Redis采用的分布式锁算法是 Redlock。基本实现思路是让客户端和多个独立的 Redis 实例依次请求加锁,如果客户端能够和半数以上的实例成功地完成加锁操作,那么我们就认为,客户端成功地获得分布式锁了,否则加锁失败。这样一来,即使有单个 Redis 实例发生故障,因为锁变量在其它实例上也有保存,所以,客户端仍然可以正常地进行锁操作,锁变量并不会丢失
我们来具体看下 Redlock 算法的执行步骤。Redlock 算法的实现需要有 N 个独立的 Redis 实例。接下来,我们可以分成 3 步来完成加锁操作。
客户端获取当前时间。 客户端按顺序依次向 N 个 Redis 实例执行加锁操作。 一旦客户端完成了和所有 Redis 实例的加锁操作,客户端就要计算整个加锁过程的总耗时。
第二步 加锁操作和在单实例上执行的加锁操作一样,使用 SET 命令,带上 NX,EX/PX 选项,以及带上客户端的唯一标识。当然,如果某个 Redis 实例发生故障了,为了保证在这种情况下,Redlock 算法能够继续运行,我们需要给加锁操作设置一个超时时间。
如果客户端在和一个 Redis 实例请求加锁时,一直到超时都没有成功,那么此时,客户端会和下一个 Redis 实例继续请求加锁。加锁操作的超时时间需要远远地小于锁的有效时间,一般也就是设置为几十毫秒。
第三步 客户端只有在满足下面的这两个条件时,才能认为是加锁成功。
客户端从超过半数(大于等于 N/2+1)的 Redis 实例上成功获取到了锁 客户端获取锁的总耗时没有超过锁的有效时间。
在满足了这两个条件后,我们需要重新计算这把锁的有效时间,计算的结果是锁的最初有效时间减去客户端为获取锁的总耗时。如果锁的有效时间已经来不及完成共享数据的操作了,我们可以释放锁,以免出现还没完成数据操作,锁就过期了的情况。
当然,如果客户端在和所有实例执行完加锁操作后,没能同时满足这两个条件,那么,客户端向所有 Redis 节点发起释放锁的操作。
在 Redlock 算法中,释放锁的操作和在单实例上释放锁的操作一样,只要执行释放锁的 Lua 脚本就可以了。这样一来,只要 N 个 Redis 实例中的半数以上实例能正常工作,就能保证分布式锁的正常工作了。
所以,在实际的业务应用中,如果你想要提升分布式锁的可靠性,就可以通过 Redlock 算法来实现。
结尾
大概总结了Redis在处理并发访问时,如果不采取措施在进行读写,修改,写会时会有数据错误。我们要保证临界区(执行的代码)代码的互斥性。
根据暴露的问题提供了两种方案。加锁和原子操作。根据原子操作慢慢了转向了Lua脚本的必要性。
接下来又介绍了Redis分布式锁的实现。从单节点,多节点分别进行的介绍。
单节点中,通过把变量保存在键值对上,并且加上过期时间,防止共享存储系统发生宕机影响整个业务系统。
使用完后进行释放时,涉及到了DEL命令以及多个命令执行时,介绍了Lua脚本。
还有一点就是多个客户端释放锁时,有可能并发导致释放的不是自己的锁导致数据错误,采用了客户端唯一标识进行判断释放。(Lua脚本内操作的)
多节点中,通过借助共享存储系统进行锁的分配管理。基于单个 Redis 实例实现分布式锁时,会面临实例异常或崩溃的情况,这会导致实例无法提供锁操作于是展开介绍了Redlock算法。
非常欢迎大家加我个人微信有关后端方面的问题我们在群内一起讨论! 我们下期再见!
长按上方扫码二维码,加我微信,拉你进群
