
Java 11 到 Java 17 的最佳 HotSpot JVM 选项和开关
一、前言
在本文中,你将了解 OpenJDK HotSpot Java 虚拟机 (HotSpot JVM) 中的一些系统知识,以及如何调整它们以获得最佳状态适应你的程序和运行环境。
HotSpot JVM 是一项了不起且灵活的技术。它作为二进制版本适用于每个主要操作系统和 CPU 架构,从微型 Raspberry Pi Zero 一直到包含数百个 CPU 内核和 TB 级 RAM 的“大型”服务器。由于 OpenJDK 是一个开源项目,HotSpot JVM 几乎可以针对任何其他系统进行编译,并且可以使用选项、开关和标志对其进行微调。
首先,这里有一些背景。HotSpot JVM 的语言是字节码。在撰写本文时,有超过 30 种编程语言可以编译成 HotSpot JVM 兼容的字节码,但迄今为止最受欢迎的、在全球拥有超过 800 万开发人员的当然是 Java。
Java 源代码被编译成字节码(如图 1 所示),以类文件的形式,使用 javac 编译器。在现代开发中,这可能会被 Maven、Gradle 或基于 IDE 的编译器等构建工具抽象掉。

程序的字节码表示由 HotSpot JVM 在一个虚拟堆栈机上执行,该虚拟堆栈机知道多达256条不同的指令,每条指令由一个8位数字操作码标识;因此,名称是“字节码”。
字节码程序由解释器执行,该解释器获取每条指令,将其操作数压入堆栈,然后执行该指令,移除操作数并将结果留在堆栈中,如图 2 所示。

将程序执行从底层环境中抽象出来,赋予了 Java “一次编写,随处运行”的可移植性优势。在一种架构上编译的类文件可以运行在完全不同架构的 HotSpot JVM 上执行。
如果你认为这种对底层硬件的抽象是以牺牲性能为代价的,那么你是对的。这通常就是 HotSpot JVM 开关、选项和标志的用武之地。
二、JIT 即时编译
用可移植、功能丰富的高级语言(如Java)编写的程序如何挑战那些从“低级”、“不太友好”的编程语言(如C)编译为特定于体系结构的本机代码的程序的性能呢?
答案是 HotSpot JVM 包含了性能提升的即时(JIT)编译技术,它可以分析程序的执行情况,并有选择地优化它认为最有好处的部分。这些被称为程序的热点(因此,将其命名为 HotSpot JVM),它通过使用底层系统架构的知识动态地将它们编译成本地代码来实现这一点。
HotSpot JVM包含两个 JIT 编译器,称为 C1(客户端编译器)和 C2(服务器编译器),它们提供了不同的优化权衡。
C1 提供了快速、简单的优化。 C2 提供了需要更多分析的高级优化,而且应用成本更高。
自 JDK 8 发布以来,默认行为一直是在称为分层编译的模式下同时使用这两个编译器,其中 C1 提供了快速的速度提升,而 C2 在进行高级优化之前收集了足够的评测信息。生成的本机代码存储在热点 JVM 的内存区域中,称为代码缓存,如图3所示。

三、GC 垃圾回收
除了 JIT 技术之外,HotSpot JVM 还包括提高生产力和性能的功能,例如:多线程和自动内存管理以及垃圾收集 (GC) 策略的选择。
对象被分配在 HotSpot JVM 的一个称为堆的内存区域中,一旦这些对象不再被引用,垃圾收集器就可以将它们清理干净,并将它们使用的内存回收。
四、符合人体工程学的 HotSpot JVM
HotSpot JVM 具有如此多的灵活性和动态行为,你可能会担心如何配置它以最好地满足你的程序要求。幸运的是,对于很多用例,你不需要进行任何手动调整。HotSpot JVM 包含一个称为 ergonomic(人体工程学)的过程,它在启动时检查执行环境,并根据 CPU 内核数量和可用 RAM 数量为 GC 策略、堆大小和 JIT 编译器选择一些合理的默认值。当前的默认值是:
垃圾收集器:G1 GC 初始堆:物理内存的 1/64 最大堆:物理内存的 1/4 JIT 编译器:同时使用 C1 和 C2 的分层编译
通过使用选项 -XX:+PrintFlagsFinal 并使用 grep 命令搜索 ergonomic,你可以看到 HotSpot JVM 将为你的环境选择的所有 ergonomic 默认值,如下所示:
java -XX:+PrintFlagsFinal | grep ergonomic
intx CICompilerCount = 4 {product} {ergonomic}
uint ConcGCThreads = 2 {product} {ergonomic}
uint G1ConcRefinementThreads = 8 {product} {ergonomic}
size_t G1HeapRegionSize = 2097152 {product} {ergonomic}
uintx GCDrainStackTargetSize = 64 {product} {ergonomic}
size_t InitialHeapSize = 526385152 {product} {ergonomic}
size_t MarkStackSize = 4194304 {product} {ergonomic}
size_t MaxHeapSize = 8403288064 {product} {ergonomic}
size_t MaxNewSize = 5041553408 {product} {ergonomic}
size_t MinHeapDeltaBytes = 2097152 {product} {ergonomic}
uintx NonNMethodCodeHeapSize = 5836300 {pd product} {ergonomic}
uintx NonProfiledCodeHeapSize = 122910970 {pd product} {ergonomic}
uintx ProfiledCodeHeapSize = 122910970 {pd product} {ergonomic}
uintx ReservedCodeCacheSize = 251658240 {pd product} {ergonomic}
bool SegmentedCodeCache = true {product} {ergonomic}
bool UseCompressedClassPointers = true {lp64_product} {ergonomic}
bool UseCompressedOops = true {lp64_product} {ergonomic}
bool UseG1GC = true {product} {ergonomic}
上面的输出来自具有 32 GB RAM 的机器上的 JDK 11,因此初始堆设置为 32 GB 的 1/64(约 512 MB),最大堆设置为 32 GB 的 1/4(8 GB)。
五、自定义
如果你认为默认的设置不适合你的应用程序,很高兴 HotSpot JVM 在每个领域都具有高度可配置性。
有三种主要类型的配置选项:
标准: 基本启动选项,例如 -classpath在 HotSpot JVM 实现中很常见。-X: 用于配置 HotSpot JVM 的通用属性的非标准选项,例如控制最大堆大小 ( -Xmx);不能保证所有 HotSpot JVM 实现都支持这些。-XX: 用于配置 HotSpot JVM 的高级属性的高级选项。根据文档,这些内容如有更改,恕不另行通知,但 Java 团队有一个管理良好的流程来删除它们。
六、-XX 选项
许多 -XX 选项可以进一步表征如下:
Product. 这些是最常用的 -XX 选项。
Experimental. 这些是与 HotSpot JVM 中的实验性功能相关的选项,这些功能可能尚未准备好投入生产。这些选项允许你尝试新的 HotSpot JVM 功能,并且需要通过指定以下内容来解锁它们:
-XX:+UnlockExperimentalVMOptions
例如,在 JDK 11 中使用 ZGC 垃圾收集器可以这样开启:
java -XX:+UnlockExperimentalVMOptions -XX:+UseZGC
一旦一个实验性功能准备好投入生产,控制它的选项就不再被归类为实验性的,不需要解锁。ZGC 收集器成为 JDK 15 中的 Product 选项。
Manageable. 这些选项也可以在运行时通过 MXBean API 或其他 JDK 工具设置。例如,要在 HotSpot JVM 线程转储中显示 java.util.concurrent 类持有的锁,请使用:
java -XX:+PrintConcurrentLocks
Diagnostic. 这些选项与访问有关 HotSpot JVM 的高级诊断信息有关。这些选项需要你使用以下内容才能使用:
-XX:+UnlockDiagnosticVMOptions
一个示例诊断选项是:
-XX:+LogCompilation
它指示 HotSpot JVM 输出一个日志文件,其中包含 JIT 编译器所做的所有优化的详细信息。你可以检查此输出以了解程序的哪些部分已优化,并确定程序中可能未按预期优化的部分。LogCompilation 输出很详细,但可以在 JITWatch 等工具中可视化,它可以告诉你有关方法内联、逃逸分析、锁省略和 HotSpot JVM 对你运行的代码所做的其他优化。
Developmental. 这些选项允许配置和调试最高级的 HotSpot JVM 设置,并且在你访问它们之前需要使用特殊的 HotSpot JVM 构建调试。
七、添加和删除的选项
选项开关的添加和删除是在 HotSpot JVM 中主要功能的到来或弃用之后进行的。这里有一些值得注意的地方。
在 JDK 9 中,许多 -XX:+Print...和-XX:+Trace...日志选项被删除并替换为-Xlog选项,用于控制由 JEP 158 引入的统一日志记录子系统。在添加了实验性 ZGC、Epsilon 和 Shenandoah 垃圾收集器的选项后,JDK11 中的选项数达到峰值,达到了惊人的 1504 个。 随着并发标记扫描(CMS)垃圾收集器的删除,JDK14 中的数据量大幅下降,如 JEP 363 中所述。
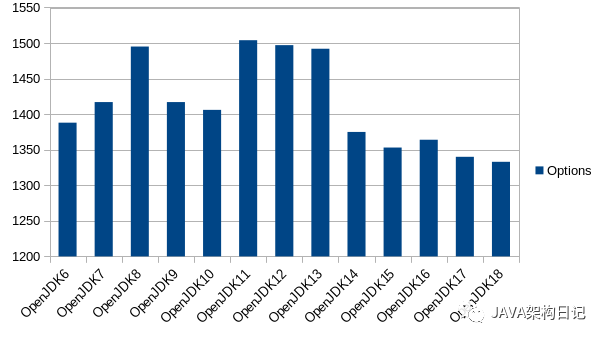
表 1. 从 OpenJDK 17 中删除的 OpenJDK 16 之前的 HotSpot JVM 选项

表 2. OpenJDK 17 新加入的 HotSpot JVM 选项

八、配置项的生命周期
那么 HotSpot JVM 开发团队如何管理选项的删除呢?自 JDK 9 以来,删除 -XX 选项的过程被扩展为三步过程:弃用、过时和过期,以向用户发出大量警告,提示他们的 Java命令行可能很快需要更新。
让我们看看 HotSpot JVM 如何对 -XX:+AggressiveOpts 选项作出的操作,该选项在 JDK 11 中被弃用,在 JDK 12 中被淘汰,最后在 JDK 13 中过期。
不推荐使用的选项。虽然可以支持这些选项,但会打印一条警告并让你知道将来可能会删除支持,例如:
./jdk11/bin/java -XX:+AggressiveOpts
OpenJDK 64-Bit Server VM warning: Option AggressiveOpts was deprecated in version 11.0 and will likely be removed in a future release.
过时的选项。这些选项虽然已被删除,但在命令行上仍被接受。(程序)会打印一条警告,让你知道这些选项将来可能不会被接受,例如:
./jdk12/bin/java -XX:+AggressiveOpts
OpenJDK 64-Bit Server VM warning: Ignoring option AggressiveOpts; support was removed in 12.0
过期的选项。 这些是不推荐使用或过时的选项,其 accept_until版本小于或等于当前JDK 版本。当这些选项在其过期的 JDK 版本中使用时,会打印一条警告,例如:
./jdk13/bin/java -XX:+AggressiveOpts
OpenJDK 64-Bit Server VM warning: Ignoring option AggressiveOpts; support was removed in 12.0
完全失败(不可用)。 当你一旦使用了某个老版本 JDK 中过时的配置时,HotSpot JVM 将在通过该选项并打印警告后启动失败,例如:
./jdk14/bin/java -XX:+AggressiveOpts
Unrecognized VM option 'AggressiveOpts'
Error: Could not create the Java Virtual Machine.
Error: A fatal exception has occurred. Program will exit.
令人遗憾的是,并不是所有的 option 都以这种有序的方式退场。例如,JDK 9 在引入统一日志记录和强大的 -Xlog 选项时放弃了对大量选项的支持,这在 Nicolai Palog 的博客中有详细介绍。Java 文档网站上还有一个页面,参考:Convert GC Logging Flags to Xlog。
九、迁移到高版本的 JDK
那么,你是否准备将 Java 启动脚本命令迁移到更高版本的 JDK?也许你使用了统一启动脚本,其中充满了你不熟悉的选项和配置,并且担心调整会影响应用程序的稳定性。
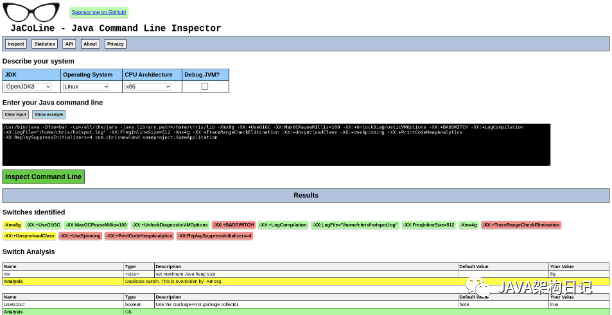
你可以使用 JaCoLine,Java 命令行检查器来帮助你。粘贴命令,选择目标平台,然后分析你的配置选项将如何工作。见图 5。
十、JVM 参数配置建议
虽然在 HotSpot JVM 调优方面没有一刀切的建议,但我相信肯定有一些选项可以帮助你更好地了解程序的执行并做出明智的配置选择。
以下选项在 JDK 11 及更高版本中可用。我选择这些开关是因为许多开发人员还没有转向更高版本的 Java。请记住,这些都是可选的;HotSpot JVM 的默认设置非常好。
首先,了解内存使用情况。 在 HotSpot JVM 中分配内存很便宜。垃圾收集成本是指当热点JVM清理堆中不再需要的对象时,稍后以执行暂停的形式到期的消耗。
在提高应用程序性能和稳定性方面,了解代码进行的堆分配以及由此产生的GC行为可能是最容易解决的问题,因为堆和GC配置以及应用程序的分配行为之间的不匹配会导致过度暂停,从而中断应用程序的进程。
使用 JaCoLine Statistics 网页确认配置堆和 GC 日志记录是 JaCoLine 检查的所有命令行中最受欢迎的选项。
要配置堆,请考虑以下问题的答案:
正常情况下预期最大堆的内存使用量是多少? -Xmx设置最大堆大小,例如:-Xmx8g。-XX:MaxRAMPercentage=n将最大堆设置为总 RAM 的百分比。你期望堆多快达到其最大值? -Xms设置初始堆大小,例如:-Xms256m.-XX:InitialRAMPercentage=n将最大堆设置为总 RAM 的百分比。如果希望堆快速增长,可以将初始堆设置为更接近最大堆。
要处理 OutOfMemory 错误,需要考虑在应用程序内存不足时 HotSpot JVM 应该如何工作。
-XX:+ExitOnOutOfMemoryError告诉 HotSpot JVM 在出现第一个OutOfMemory错误时退出。如果 HotSpot JVM 将自动重新启动,这会很有用。-XX:+HeapDumpOnOutOfMemoryError通过将堆的内容转储到java_pid.hprof文件来帮助诊断内存泄漏。-XX:HeapDumpPath定义 heap dump 路径。
其次,选择垃圾收集器。 大多数硬件上的 JDK 11 人体工程学过程将默认选择 G1GC 收集器,但它不是 JDK 11 及更高版本中的唯一选择。
其他可用的垃圾收集器是:
-XX:+UseSerialGC选择串行收集器,它在单个线程上执行所有 GC 工作。-XX:+UseParallelGC选择并行(吞吐量)收集器,它可以使用多个线程执行压缩。-XX:+UseConcMarkSweepGC选择 CMS 收集器。请注意,CMS 收集器在 JDK 9 中已被弃用,并在 JDK 14 中被删除。-XX:+UnlockExperimentalVMOptions -XX:+UseZGC选择 ZGC 收集器(在 JDK 11 中是实验性的,在 JDK 14 及更高版本中是标准功能;因此你不需要此开关)。
可以在 HotSpot Virtual Machine Garbage Collection Tuning Guide 中找到有关为你的应用程序选择收集器的建议。这是 JDK 11 的文档版本;如果你使用的是更高版本的 Java,请搜索更新的文档。
为避免过早提升,请考虑你的应用程序是否以高分配率创建短期对象。这可能导致短期对象过早提升到老年代堆空间,在那里它们将累积,直到需要完整的垃圾收集。
-XX:NewSize=n定义新生代的初始大小。-XX:MaxNewSize=n定义新生代的最大大小。-XX:MaxTenuringThreshold=n是一个对象在提升到老年代之前可以存活的最大新生代集合数。
要记录内存使用情况和 GC 活动,请执行以下操作:
使用 -XX:+UnlockDiagnosticVMOptions ‑XX:NativeMemoryTracking=summary ‑XX:+PrintNMTStatistics获取 HotSpot JVM 退出时内存使用情况的完整细节。使用以下命令启用 GC 日志记录: -Xlog:gc提供基本的 GC 日志记录。-Xlog:gc*提供详细的 GC 日志记录。
最后,了解 JIT 编译器如何优化你的代码。 一旦你对应用程序的 GC 停顿处于可接受的水平感到满意,你就可以检查 HotSpot JVM 的 JIT 编译器是否正在优化你认为对性能很重要的程序部分。
启用简单的编译日志,如下所示:
-XX:+PrintCompilation将有关每个 JIT 编译的基本信息打印到控制台。-XX:+UnlockDiagnosticVMOptions ‑XX:+PrintCompilation ‑XX:+PrintInlining添加有关方法内联的信息。
输出示例:
java -XX:+PrintCompilation
77 1 3 java.lang.StringLatin1::hashCode (42 bytes)
78 2 3 java.util.concurrent.ConcurrentHashMap::tabAt (22 bytes)
78 3 3 jdk.internal.misc.Unsafe::getObjectAcquire (7 bytes)
80 4 3 java.lang.Object:: (1 bytes)
80 5 3 java.lang.String::isLatin1 (19 bytes)
80 6 3 java.lang.String::hashCode (49 bytes)
输出中的项目(从左到右)如下:
PrintCompilation在《Java JIT 编译器解释 – 第 1 部分》文章中有说明。
将 JIT 信息记录到控制台对于检查方法是被 JIT 编译还是内联(或两者)非常有用,但如果你想更深入地了解 JIT 优化,则需要启用详细的日志记录。
使用 -XX:+UnlockDiagnosticVMOptions ‑XX:+LogCompilation ‑XX:LogFile=jit.log 启用详细的编译日志记录。它支持详细的 XML 格式编译日志记录,可以在 JITWatch 等工具中进行分析。你可以从 Ben Evans 的“使用 JITWatch 理解 Java JIT 编译,第 1 部分”以及第 2 部分和第 3 部分中了解有关 JITWatch 的更多信息。
译者说:
大家好,我是 如梦技术春哥(mica、mica-mqtt 开源作者)感谢一起参与翻译和校对的张亚东(JustAuth、Jap 开源作者)、xkcoding(spring-boot-demo 开源作者)同学,关注我们更多优秀开源助你早日走上人生巅峰!!!