
无状态节点服务的缓存数据同步实现
在目前需求背景下要设计一套底层服务系统,提供一系列基本数据请求接口,这里把该系统服务称为P,为保证高可用高可靠性,P系统最少依赖外部中间件,例如数据库消息队列等组件,服务所涉及的数据全部缓存到本地缓存中,然后由其他服务来请求接口或数据库收集数据,将收集的数据存入Redis中,再去通知P系统更新本地缓存的数据,收集数据的服务称为D。以下为P,D,Redis关系图。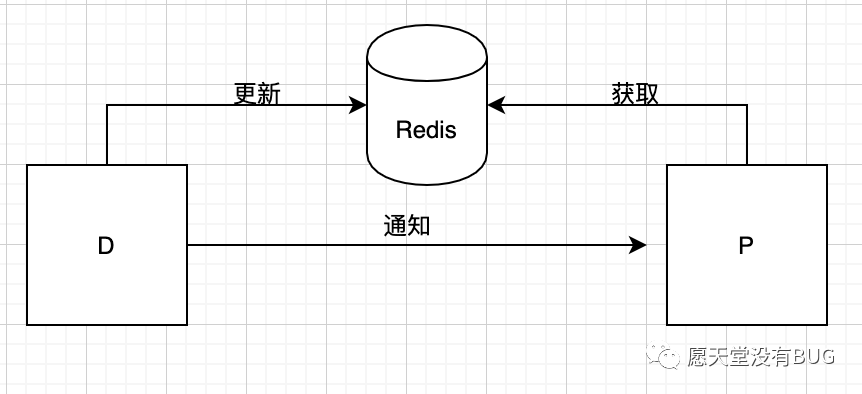
需要注意的是,P并不会强依赖与Redis与D系统,因其本地缓存有一份全量的数据,只是对数据的实时性不能保证,要靠D系统来定时发送更新通知,本文是对P,D系统在Redis中数据的同步进行讨论,不关注其他细节实现。
数据同步一般分为全量和增量
在系统初始化阶段最好是全量加载,待本地有了完整数据后,之后的更新最好是增量进行,一是可以提高网络传输性能,加快更新进度,二是可以避免在数据量过大时全量覆盖速度太慢影响正常业务请求,还可能导致本次更新未完成便收到下次更新通知,使得系统陷入更新困境,造成恶循环拖垮性能。下面描述对两种同步方式的实现思路
全量覆盖的实现:
D系统拉取到全部数据后,直接删除redis上旧的数据结构,例如一个Hash,再将新的数据全部传到新的Hash结构里,P系统收到更新后,全量拉取该Hash的数据覆盖本地缓存。
增量覆盖的实现:
增量存在三种数据不一致情况,新增数据,删除数据,修改数据,比较容易想到的方式是,每次D系统拉取到新的全部数据后,用该数据集和Redis中的数据集对比,假设新数据集为n,旧数据集为m,用n与m数据做差集,其实就是n中的数据查找m中是否存在,存在的话进行对比,不一致则更新,如果不存在就插入该数据,时间复杂度在n*m,这样只能统计出新增和修改的数据,如果要统计删除的数据还需要再进行双向遍历来查找。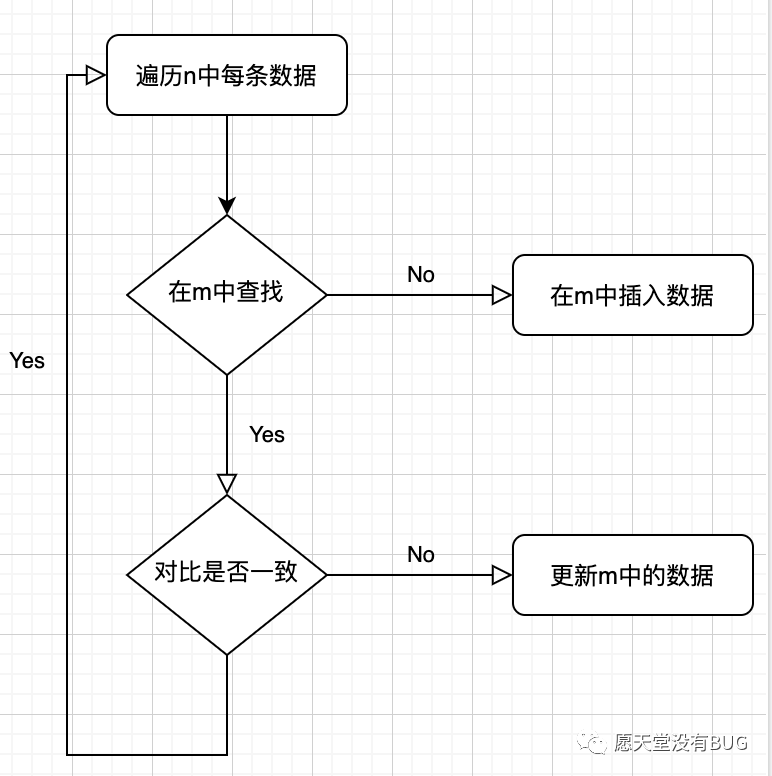
优化增量同步:
基于此方案的缺陷,提出来另一种优化思路,增加版本号来控制数据的更新,使用Zset或者Hash来存储数据,Score作为版本号,即在D系统拿到全量数据后,不需要把Redis的旧数据挂下来,直接用新的数据集去查找对比,根据三种数据状态来描述,查找数据时如果能找到说明数据没有更新,将该记录的score值递增,找不到可能是已经更新的数据,则直接新插入该数据,并将score设置为相同的值,当整个过程执行完成后,Redis上的数据就被更新了一遍,以score来区分,没有更新score值的可能是已经更新了或者删除了,更新了score值的可能是新插入或者能查找到的。P系统在接收到更新通知后,根据本次的版本号score值,拉取对应score值的数据集来覆盖本地的缓存。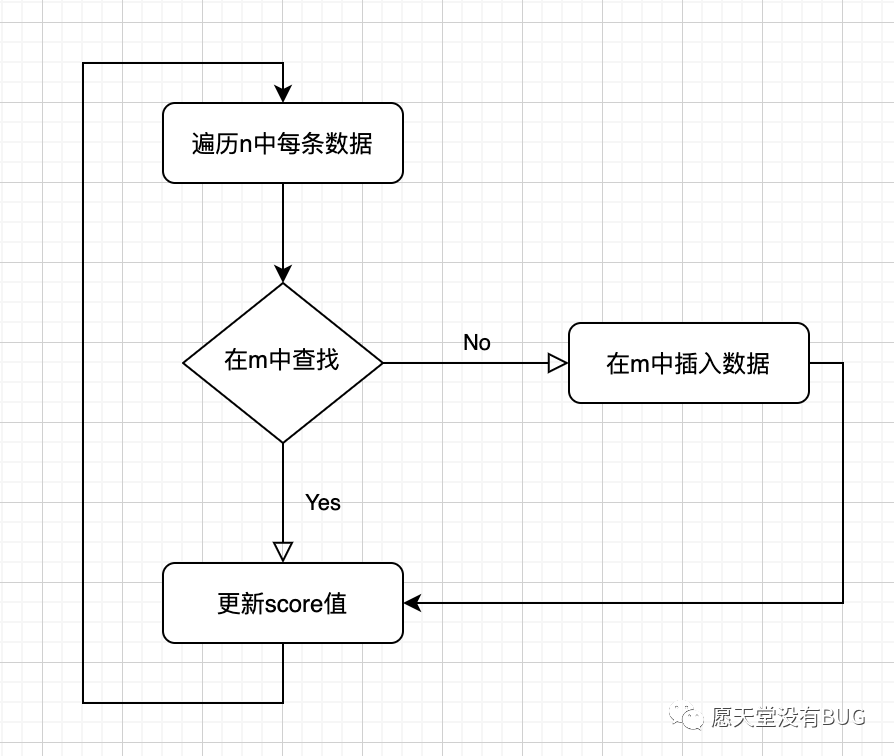
作者:AlgoRain
链接:https://juejin.cn/post/6972131556269752334
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。