
MCTF 即插即用 | 多准则Token融合让DeiT将FLOPs减少了44%,性能却得到了提升
点击下方卡片,关注「集智书童」公众号

视觉 Transformer (ViT)已经成为计算机视觉领域的一个重要 Pillar 。为了更高效的ViT,近期的研究通过剪枝或融合冗余的标记来减少自注意力层的二次成本。
然而,这些研究面临着因信息丢失而导致的速度与准确度之间的权衡。在这里,作者认为标记融合需要考虑标记之间的多样化关系,以最小化信息丢失。在本文中,作者提出了一个多准则标记融合方法(MCTF),它基于多准则(即相似性、信息量以及融合标记的大小)逐渐融合标记。
此外,作者利用一步提前的注意力机制,这是捕获标记信息量的改进方法。通过使用标记减少一致性训练配备MCTF的模型,作者在图像分类(ImageNet1K)中实现了最佳的速率-准确度权衡。
实验结果证明,MCTF在训练与否的情况下,一致地超过了之前的减少方法。特别是,配备MCTF的DeiT-T和DeiT-S将FLOPs减少了大约44%,同时相对于基础模型分别提升了性能(+0.5%和+0.3%)。作者还证明了MCTF适用于各种视觉 Transformer (例如,T2T-ViT,LV-ViT),在不降低性能的情况下实现了至少31%的速度提升。
代码:https://github.com/mlvlab/MCTF
1 Introduction
视觉Transformer [12](ViT)被提出用于借助自注意力机制解决视觉任务,这一机制最初是为自然语言处理任务而开发的。随着ViT的出现,Transformers已成为广泛视觉任务的主流架构,例如,分类,目标检测,分割等。仅由自注意力和多层感知机(MLP)构建的ViTs,与传统方法(如卷积神经网络(CNN))相比,提供了极大的灵活性和令人印象深刻的性能。然而,尽管有这些优势,自注意力关于 Token 数量的二次计算复杂性是Transformers的主要瓶颈。随着对大规模基础模型(如CLIP)的兴趣日益增长,这一局限变得更加重要。为此,一些研究提出了有效的自注意力机制,包括在预定义窗口内的局部自注意力。
近期,人们对在不改变ViT架构的情况下优化ViT的标记减少方法越来越感兴趣。早期的工作主要集中通过剪枝非信息性标记来减少标记数量。另一系列工作则尝试融合标记,而不是丢弃它们,以最小化信息丢失。然而,大多数标记融合方法仍然普遍观察到性能下降。作者注意到,标记融合方法通常只考虑一个标准,比如标记的相似性或信息性,导致次优的标记匹配。例如,基于相似性的标记融合容易将前景标记结合起来,而基于信息性的融合往往合并实质上不相似的标记,导致表示崩溃。此外,如果太多标记融合成一个标记,那么信息丢失是不可避免的。
为了解决这些问题,作者引入了多准则标记融合(MCTF),该方法通过基于多准则融合标记来优化视觉 Transformer 。与之前只考虑单一准则进行标记融合的工作不同,MCTF以下列多准则测量标记之间的关系:
-
相似性以融合冗余标记 -
信息性以减少非信息性标记 -
标记的大小以防止因大尺寸标记而损失信息。
同时,为了解决连续层间注意力图的不一致性,作者采用了“一步提前注意力”,它明确估计了下一层标记的信息性。
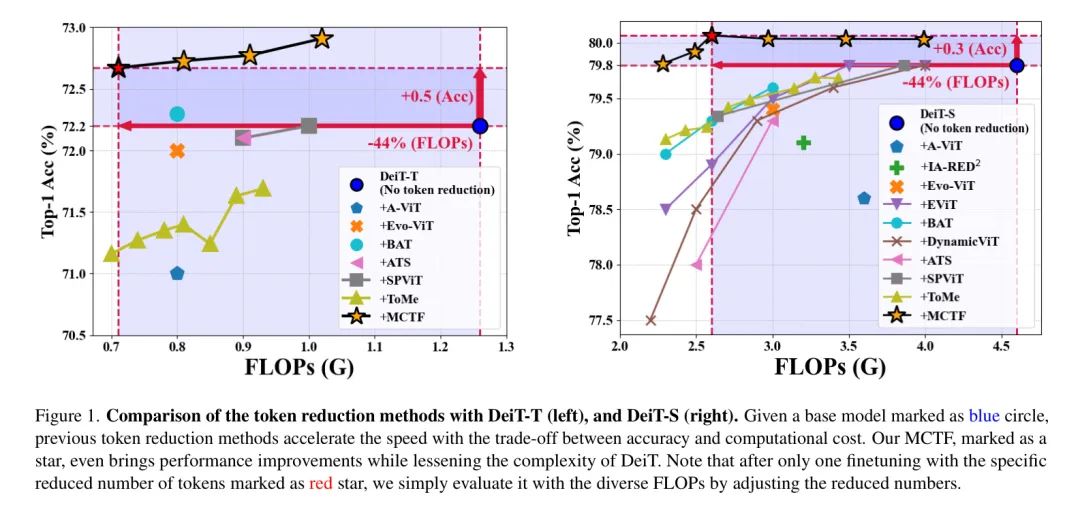
最后,通过引入一种“标记减少一致性”对模型进行微调,作者实现了如图1所示优于现有工作的性能。令人惊讶的是,MCTF甚至比“完整”的基础模型(红色虚线)在减少计算复杂性的情况下表现更好。
具体来说,在DeiT-T和DeiT-S中,它分别带来了0.5%和0.3%的增益,同时将FLOPs减少了大约44%。作者在T2T-ViT和LV-ViT中观察到了类似的加速(31%),且没有性能下降。
作者的贡献可以总结为四个方面:
-
作者提出了“多标准标记融合”(_Multi-criteria Token Fusion_)这一新型标记融合方法,该方法考虑了多个标准,例如相似性、信息量和大小,以捕捉标记之间的复杂关系并最小化信息损失。
-
为了衡量 Token 的信息量,作者利用“一步提前注意力”机制来保留在后续层中的关注 Token 。
-
作者提出了一种新的微调方案,该方案具有_token减少一致性_,用以提升装备了MCTF的 Transformer 模型的泛化性能。
-
广泛的实验表明,MCTF在多种ViTs中实现了最佳的速度-精度权衡,超过了所有先前的token减少方法。
2 Method
作者首先回顾自注意力与标记减少方法。然后,作者提出的多准则标记融合,该方法利用一步提前注意力。最后,作者在第3.4节介绍了一种带有标记减少一致性的训练策略。
Preliminaries
在Transformer模型中, tokens 通过自注意力进行处理,定义如下:
在公式 中,且 是可学习的权重矩阵。尽管自注意力具有出色的表现力,但由于其二次时间复杂度 ,它并不能很好地随标记数 的增加而扩展。
为了解决这个问题,一系列工作通过简单地 剪枝 不提供信息的标记来减少标记的数量。这些方法常常由于信息的丢失而导致性能显著下降。因此,另一系列工作融合不提供信息或冗余的标记 成为一个新标记 ,其中 是原始标记的集合,而 表示一个合并函数,例如,最大池化或平均化。在这项工作中,作者也采用 '标记融合' 而非 '标记剪枝',并通过多种标准来最小化通过减少标记而损失的信息。
Multi-criteria token fusion
给定一组输入标记集合 ,MCTF的目标是将这些标记融合成输出标记 ,其中 是融合标记的数量。为了最小化信息丢失,作者首先基于多标准评估标记之间的关系,然后通过双向二分软匹配来分组和合并标记。
多准则吸引力函数。 作者首先基于多个准则定义一个吸引力函数 。
在公式中, 是由第 个标准计算出的吸引力函数,而 是用来调整第 个标准影响力的温度参数。两个标记之间较高的吸引力分数表示有更高的融合机会。在这项工作中,作者考虑以下三个标准:相似性、信息量和大小。
相似性。 第一个标准是 Token 的相似性,以减少冗余信息。类似于之前的工作要求 Token 之间接近,作者利用一组 Token 之间的余弦相似性来衡量。
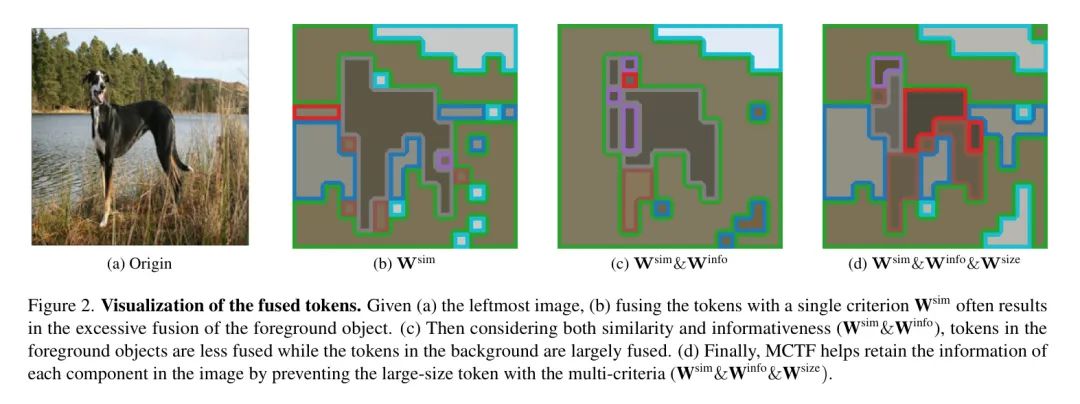
Token 融合与相似性有效消除了冗余 Token ,但如图1(b)所示,它通常过度结合了信息性 Token ,导致信息丢失。
信息性。 为了最小化信息丢失,作者引入了信息性以避免融合具有信息性的标记。为了量化信息性,作者测量自注意力层中的平均注意力分数 ,这表示每个标记对其他标记的影响: ,其中 。当 时,表示 对其他标记没有影响。利用这些信息性得分,作者定义了一个基于信息性的吸引函数。
其中 分别是 的信息得分。当两个标记都是非信息性的( ),
权重变得更高 ( ),使得两个标记倾向于被融合。在图2c中,结合了相似性和信息性的权重,前景物体中的标记融合得较少。
大小。 最后一个标准是标记的大小,它表示融合标记的数量。尽管标记不是通过丢弃而是通过合并函数进行合并,例如平均池化或最大池化,但随着构成标记数量的增加,保留所有信息是困难的。因此,更倾向于较小标记之间的融合。为此,作者最初将标记 的大小 设置为1,并跟踪每个标记的构成(融合)标记的数量,并定义一个基于大小的吸引力函数。
在图2d中,基于多标准:相似性、信息丰富性和大小,对标记(tokens)进行合并。作者观察到融合发生在相似的标记之间,同时适当地抑制了前景标记或大标记的融合。
双向二分软匹配。给定基于多准则的吸引力函数 ,MCTF执行一种称为二分软匹配的放松的双向二分匹配。二分匹配的一个优点是它减轻了 Token 之间相似度计算的二次成本,即, ,其中 。
此外,通过放松一对一对应关系的约束,解决方案可以通过一个高效的算法获得。在这个放松的匹配问题中, Token 集合 首先按照图3第1步的方式分裂为源和目标 。给定一组二元决策变量,即,在 和 之间的边矩阵 ,二分软匹配被表述为。
表示 中的 -th 标记之间的边存在,且 。
这个优化问题可以通过两个简单步骤解决:
-
为每个 寻找使 最大的最佳边 -
选择吸引力分数最大的前 个边。
然后,基于软匹配结果 ,作者将标记分组为:
其中 指的是与 匹配的标记集合。最后,融合的结果 被获得。
(11)
是考虑了注意力分数 和标记大小 的池化操作。然而,如图3的步骤2所示,目标标记的数量 不能减少。为了处理这个问题,MCTF执行双向二分软匹配,通过在与更新后的标记集 和 的情况下,如图3的步骤3、4中,反方向进行匹配。最终的输出标记 按以下方式定义。
请注意,用更新后的两套标记计算成对权重 会引入额外的计算成本,为 。
这个开销下,作者通过融合前的吸引力分数来近似吸引力函数。简而言之,作者只是重用预先计算的权重,因为 是 的子集。这使得MCTF能够有效地减少 Token ,同时考虑两个子集之间双向关系,与单向二分软匹配相比,额外开销可以忽略不计。
One-step-ahead attention for informativeness

在评估信息性时,先前的作品利用了上一自注意力层的注意力得分。如图5所示,先前的方法使用来自前一层注意力 来融合标记 。这种技术在连续层中注意力图相似的假设下允许有效的评估。
然而,作者观察到注意力图通常有显著差异,如图4所示,且前一层的注意力可能导致次优的标记融合。因此,作者提出了一步提前注意力,它根据下一层的注意力图 来衡量标记的信息性。然后,在方程(4)中的信息性得分 是使用 计算的。
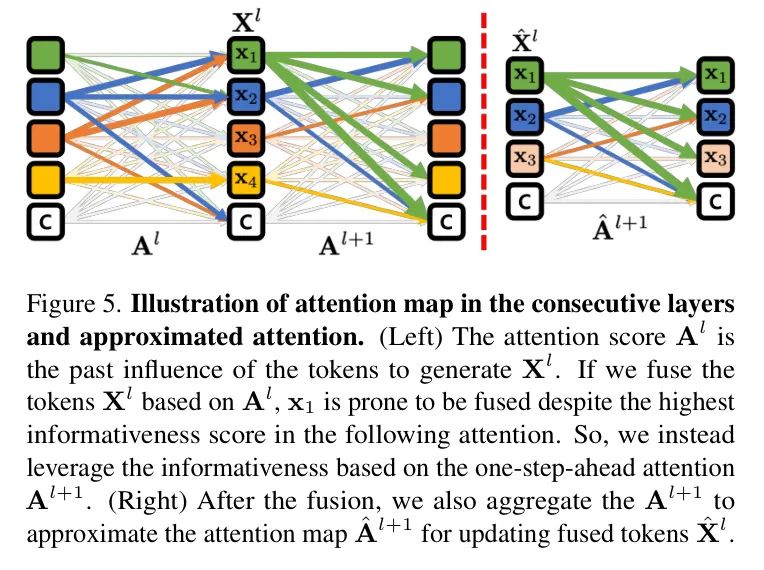
这个简单的改进提供了相当大的改进;参见4.2节的图7b。在标记融合后,作者通过简单聚合 ,而无需重新计算点积自注意力,高效地计算出融合标记 的注意力图 。具体来说,当在方程(10)到(14)中将标记融合为 时,它们对应的一步提前注意力得分也会在 Query 和键的方向上融合为 。
注意,在融合 Query 的注意力得分时,作者使用简单的求和作为 ,_即_, 。为了融合 Query 的注意力得分,作者使用简单的求和来保证 。
Token reduction consistency
作者在这里提出了一种新的微调方案,以进一步改进使用MCTF的视觉Transformer 的性能。作者观察到,每层减少的不同数量的标记,记作 ,可能导致样本的不同表示。通过训练具有不同 的Transformers,并鼓励它们之间的一致性,即标记减少一致性,作者获得了额外的性能提升。作者方法的优化目标函数给出为。
其中 是一个有监督的样本, 是固定的和动态减少的标记数量, 是一致性损失系数, 是模型 在最后一层的类别标记。在这个目标中,作者首先使用固定的 计算交叉熵损失 ,这是在评估中将使用的目标减少数量。同时,作者使用更小但随机抽取的 生成输入 的另一个表示,并计算损失 。
然后,作者对类别标记施加标记一致性损失 ,以保留在不同减少的标记数量 之间的连贯表示。所提出的方法可以被视为一种新型的标记级数据增强 [7, 20] 和一致性正则化。作者的标记减少一致性鼓励通过目标减少数量 获得的表示 模仿稍微增强的表示 ,因为 $r^{\prime}<r$,所以它更接近没有标记减少的情况。< p=""></r$,所以它更接近没有标记减少的情况。<>
4 Experiments
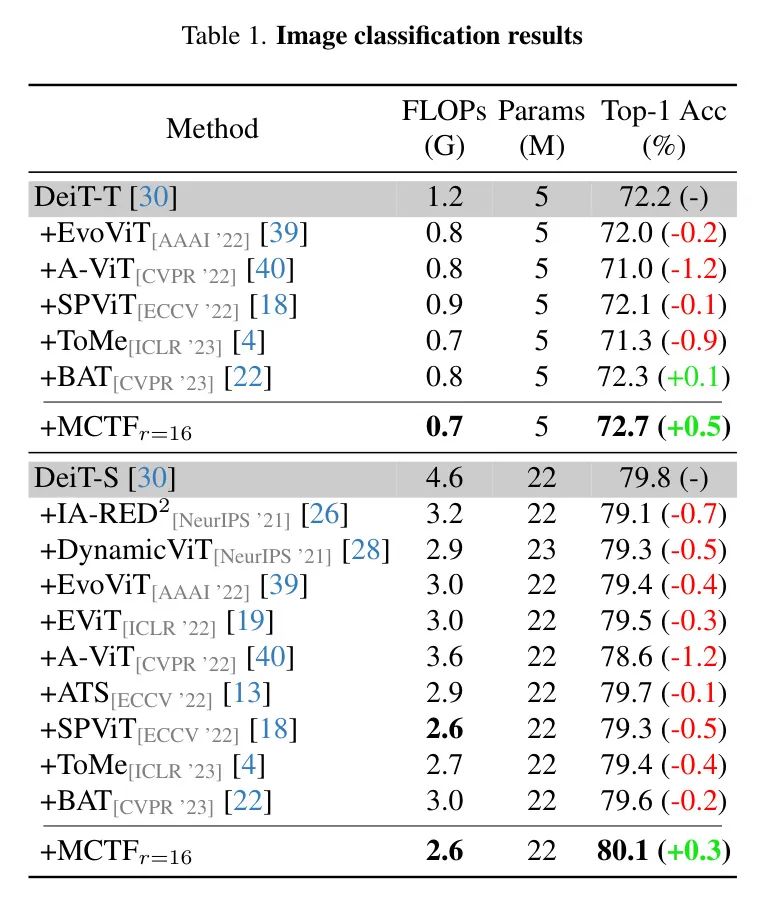
Baseline 方法。 为了验证所提出方法的有效性,作者将MCTF与之前的标记减少方法进行了比较。为了进行对比,作者选择了DeiT中的标记剪枝方法(A-ViT,IA-RED ,DynamicViT ,EvoViT,ATS)以及标记融合方法(SPViT,EViT,ToMe,BAT),并报告了每种方法的效率(FLOPs (G))和性能(Top-1准确率(%))。
此外,为了在其他的视觉 Transformer (T2T-ViT,LV-ViT)上验证MCTF,作者报告了MCTF的结果,并与现有工作的官方数据进行了比较。作者在表1和表2中用下标表示每层减少的标记数量 。表中的灰色表示 Baseline 模型,绿色和红色分别表示与基础模型相比的性能改进和退化。实施细节以及各种减少 的结果在补充材料中提供。
Experimental Results
标记减少方法的比较。 表1总结了与现有标记减少方法的比较。作者证明,在DeiT中,MCTF以最低的FLOPs实现了最佳性能,超过了所有以前的工作。此外,值得注意的是,MCTF是唯一一项在DeiT-T和DeiT-S中均以最低FLOPs避免性能下降的工作。通过针对DeiT-T微调30个周期,MCTF在几乎减少了一半FLOPs的情况下,相较于基础模型准确度显著提升了+0.5%。
同样地,作者在提升FLOPs减少2.0 (G)的同时,观察到DeiT-S的准确度提升了+0.3%。作者相信,结合一步提前关注的多标准有助于模型最小化信息损失;通过对类别标记通过标记减少的一致性损失,进一步提高了模型的泛化能力。
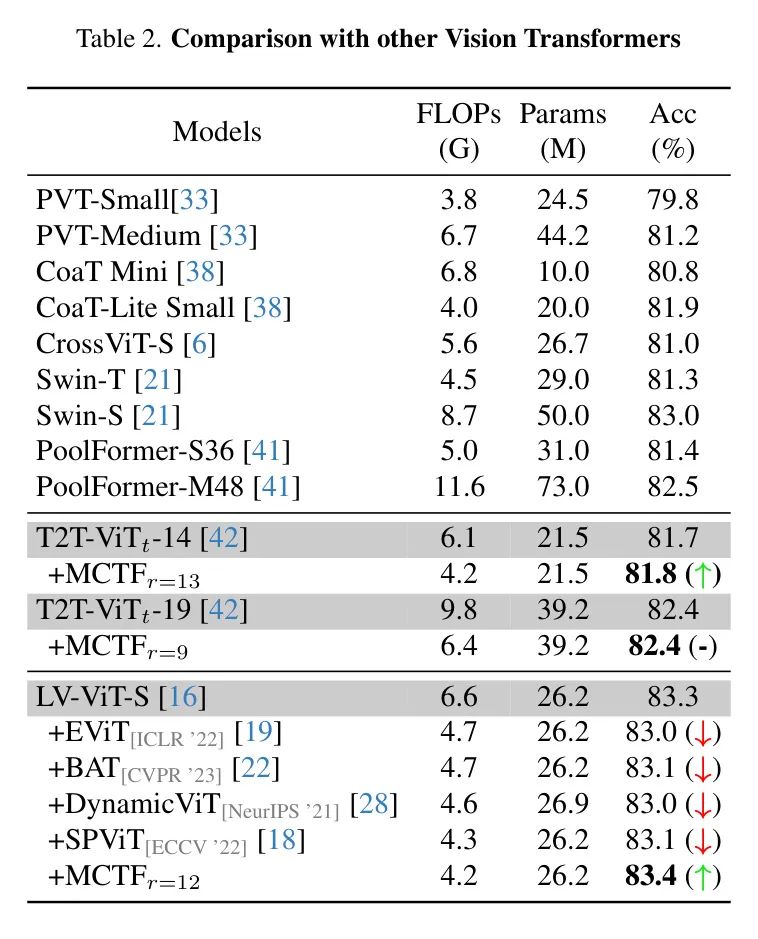
MCTF与其他视觉 Transformer 。 为了验证MCTF在各种ViTs中的适用性,作者在表2中展示了与其他 Transformer 架构结合的MCTF。遵循之前的工作,作者将在LV-ViT中应用MCTF。同时,作者也展示了T2T-ViT中MCTF的结果。
如表所示,作者的实验结果是鼓舞人心的。在这些架构中,MCTF至少实现了31%的速度提升且没有性能下降。此外,结合LV-ViT的MCTF在FLOPs和准确度方面都超过了所有其他 Transformer 和标记减少方法。特别是值得注意的是,除了MCTF之外的所有标记减少方法都会导致LV-ViT的性能下降。这些结果表明,MCTF是适用于各种视觉 Transformer 的高效标记减少方法。
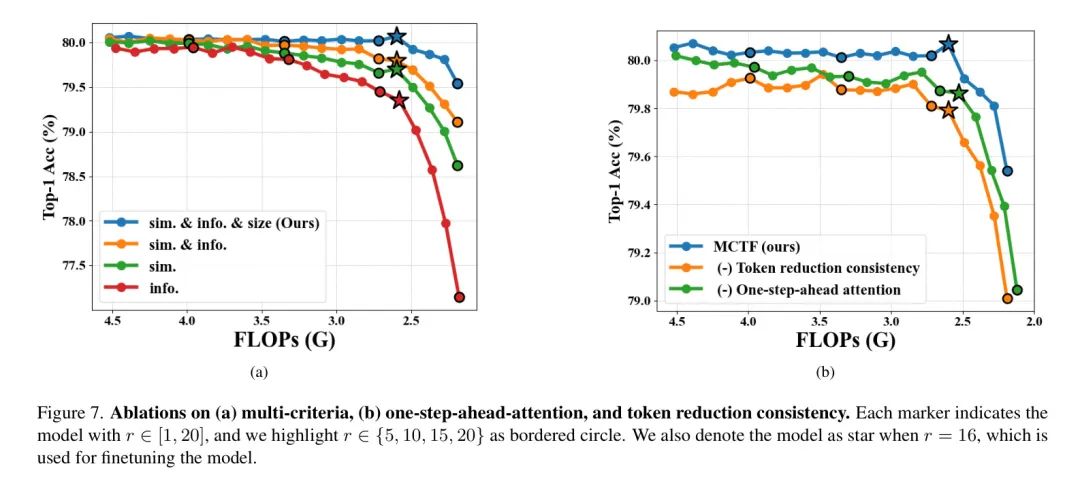
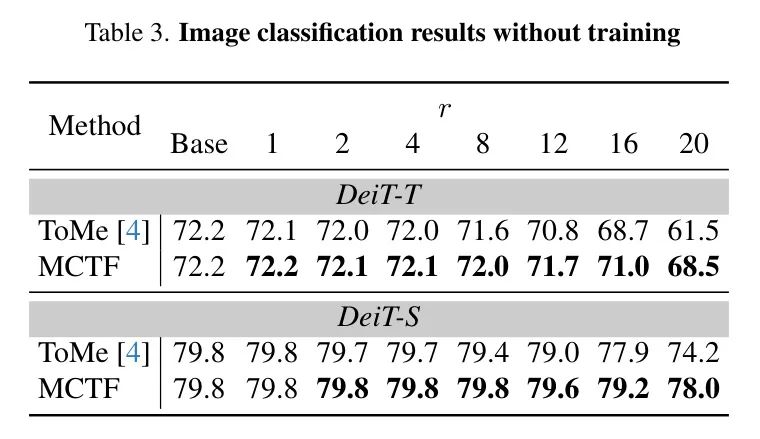
无需训练的标记减少。 与ToMe相似,MCTF可以适用于预训练的ViTs,无需任何额外的训练,因为MCTF不需要任何可学习的参数。在这里,作者将这两种减少方法应用于图7。对(a)多准则、(b)一步提前关注以及标记减少的一致性进行消融研究。每个标记代表r ∈ [1, 20]的模型,作者用边框圈出r ∈ {5, 10, 15, 20}。当r = 16时,作者也用星形表示模型,这是用于微调模型的。
Ablation studies on MCTF
作者提供了消融研究来验证MCTF的每个组件。除非另有说明,作者都是用经过MCTF微调的DeiT-S( )进行了所有实验。作者通过调整每层减少的标记数 ,提供了FLOPs-准确度图表。
多准则。作者在图6(a)中探讨了多准则的有效性。首先,关于多准则,作者为MCTF使用了三个准则,即相似性(sim.)、信息量(info.)和大小。每个单独的相似性和信息量准则与双准则(相似性&信息量)和多准则(相似性&信息量&大小)相比,表现相对较差。具体来说,当 时,单一准则的性能为79.7%,相似性和信息量分别为79.4%。

然后,采用双准则(相似性&信息量),MCTF达到79.8%。最后,通过尊重所有三个准则(相似性&信息量&大小),作者获得了80.1%的准确率,提高了0.3%。随着 的增加,这些性能差距变得更大,这证明了多准则对于标记融合的重要性。
一步提前关注和标记减少一致性。 为了展示一步提前关注和标记减少一致性的有效性,作者还在图6(b)中提供了带有和不含每个组件的MCTF的结果。当移除一步提前关注或标记减少一致性中的任何一个时,每个FLOP的准确度都会下降。这种一致性的性能下降表明,这两种提出的方法对MCTF都很重要。简而言之,通过采用一步提前关注和标记减少一致性,MCTF在广泛的FLOPs范围内有效地缓解了性能退化。
设计选择的比较。表4展示了在设计选择上的消融研究。首先,双向二分图匹配,它能够捕捉两个集合中的双向关系,与单向二分图匹配相比提高了准确性。接下来,对于池化操作 ,考虑大小 和注意力 的加权求和比其他如最大池化或平均池化是更好的选择。最后,作者比较了使用精确和近似注意力计算的 的结果。
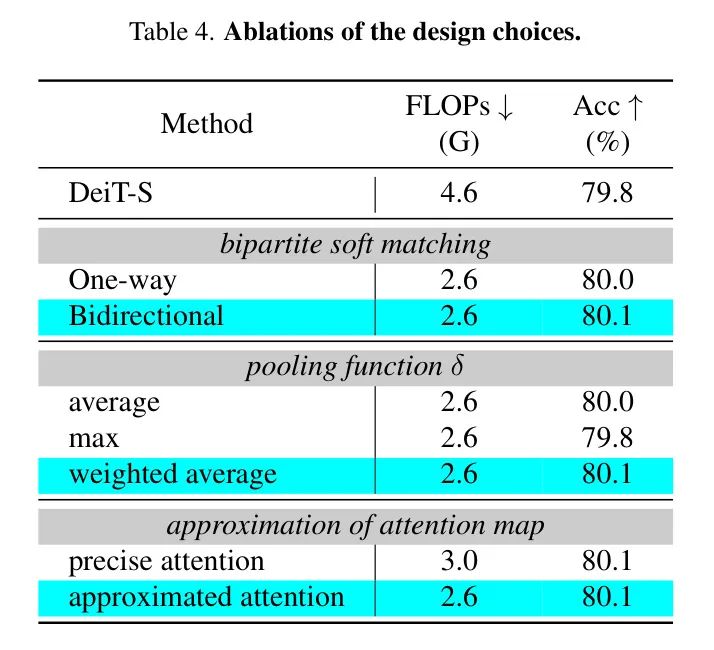
对于精确注意力,作者仅分别对一步提前的注意力和融合后自注意力层中的注意力进行相似度计算。否则,如第3.3节所述,作者用一步提前的注意力来近似计算后者。如表所示,作者的近似注意力在显著提高效率(-0.4 (G) FLOPs)的同时保持了性能。
Analyse of MCTF
定性结果。 为了更好地理解MCTF,作者在图8中提供了MCTF的定性结果。作者可视化了在ImageNet-1K数据集上DeiT-S最后一个模块中的融合标记,并用相同的边框颜色表示融合标记。如图所示,由于标记是根据多标准(例如,相似性、信息量、大小)进行合并的,作者在信息丰富的前景目标中保持了更多样化的标记。
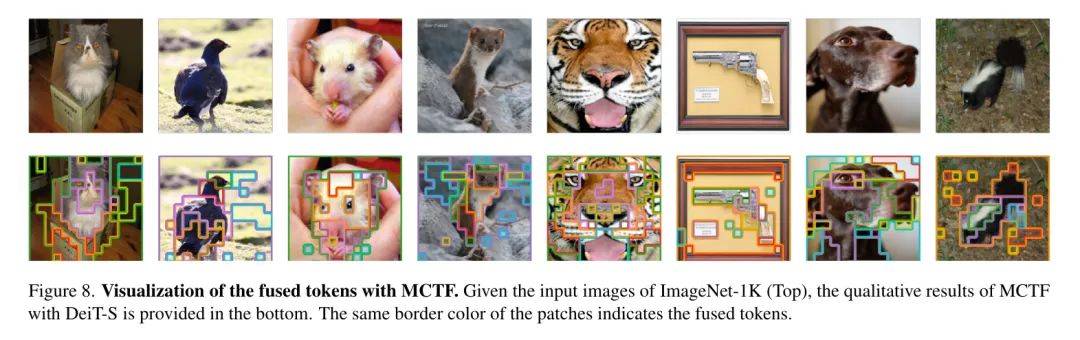
例如,在第三张仓鼠的图片中,虽然包括手在内的背景块被融合成一个标记,但前景标记融合得较少,同时保持了仓鼠的眼睛、耳朵和脸部等细节。简而言之,与背景相比,前景标记融合程度较低,中等大小,保留了主要内容的信息。
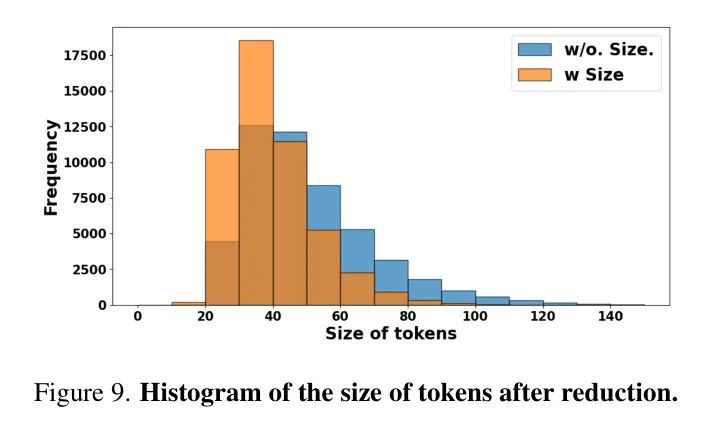
大小标准的健全性。 图9展示了在使用与不使用大小标准的情况下,标记缩减后标记大小的直方图。具体来说,作者测量了最后一个区块中最大标记的大小,并提供了直方图。采用作者的大小标准后,合并的标记倾向于有更小的尺寸s,分别在有无大小标准的情况下,平均大小为39.3/49.2。正如预期的那样,MCTF成功抑制了大尺寸标记,这些标记是信息丢失的来源,从而导致了性能的提升。
5 Conclusion
在这项工作中,作者引入了多准则标记融合(MCTF)这一新策略,旨在降低ViTs固有的复杂度,同时减轻性能下降。MCTF有效地根据多个准则,包括相似性、信息量和标记的大小,判别标记之间的关系。作者的全面消融研究以及详细分析展示了MCTF特别是作者创新的一次性提前关注和标记减少的一致性的有效性。
值得注意的是,采用MCTF的DeiT-T和DeiT-S模型在Top-1准确率上分别实现了高达+0.5%和+0.3%的提升,同时FLOPs减少了约44%。这是一个值得注意的改进,尤其是考虑到大多数 Baseline 模型的Top-1准确率都出现了下降。作者还观察到,在具有和没有训练的各种视觉Transformer中,MCTF优于所有先前的标记减少方法。这凸显了MCTF在视觉Transformer优化中的潜力。
Appendix B Analyses on MCTF
Sensitivity analysis on hyper-parameters of MCTF
为了分析MCTF中超参数的敏感性,作者在表A中根据温度参数 比较了准确度。在评估每个参数时,其他超参数被设置为在实现细节中提到的默认值。作者使用配备了MCTF( )的DeiT-S进行了实验。每个超参数的默认设置都已被突出显示。
Loss of information
在本小节中,作者测量了信息损失以验证MCTF的有效性。为此,作者将考虑在应用MCTF( )前后类标识符之间的余弦相似度作为一个度量标准来衡量信息损失,这反映了类标识符的变化。换句话说,如果类标识符之间的相似度较低,作者可以推理融合后的标识符显著地影响了类标识符的表示,同时丢失了原始内容的信息。每个区块类标识符之间的差异在表B中报告。如表所示,在Transformer的早期阶段(例如,[1-6]区块),不同标准之间没有太大的差距。
然而,随着连续区块中融合标识符数量的增加,类标识符发生了很大变化。特别是,当作者考虑单一标准时,相似度是减轻信息损失的最佳选择,相比于信息量和大小。然后,采用由相似度和信息量组成的双重标准,作者进一步减少了类标识符之间的变化,即使在后部区块(例如,[7-12]区块)也显示出高相似度。最后,拥有所有三个标准的MCTF比双标准显示出更高的相似度。作者相信,通过采用多标准来最小化信息损失,相比于其他单标准和双标准,这将在图像分类中带来一致的改进。
Qualitative comparison for one-step-ahead attention
在MCTF中,融合标记 的注意力图 是通过聚集一步提前的注意力 来近似的,这是融合标记之前的注意力。在4.2节中,作者展示了这种近似通过避免重新计算自注意力,带来了实质性的速度提升且没有任何性能下降。同时,作者在这里提供一个定性比较,以展示作者方法的合理性。在[3,6,9,12]层的注意力图的可视化在图A中提供。
Appendix C Detailed results
在本节中,作者提供了在ImageNet-1K 上使用视觉 Transformer 进行MCTF的更详细结果。
Full results with DeiT
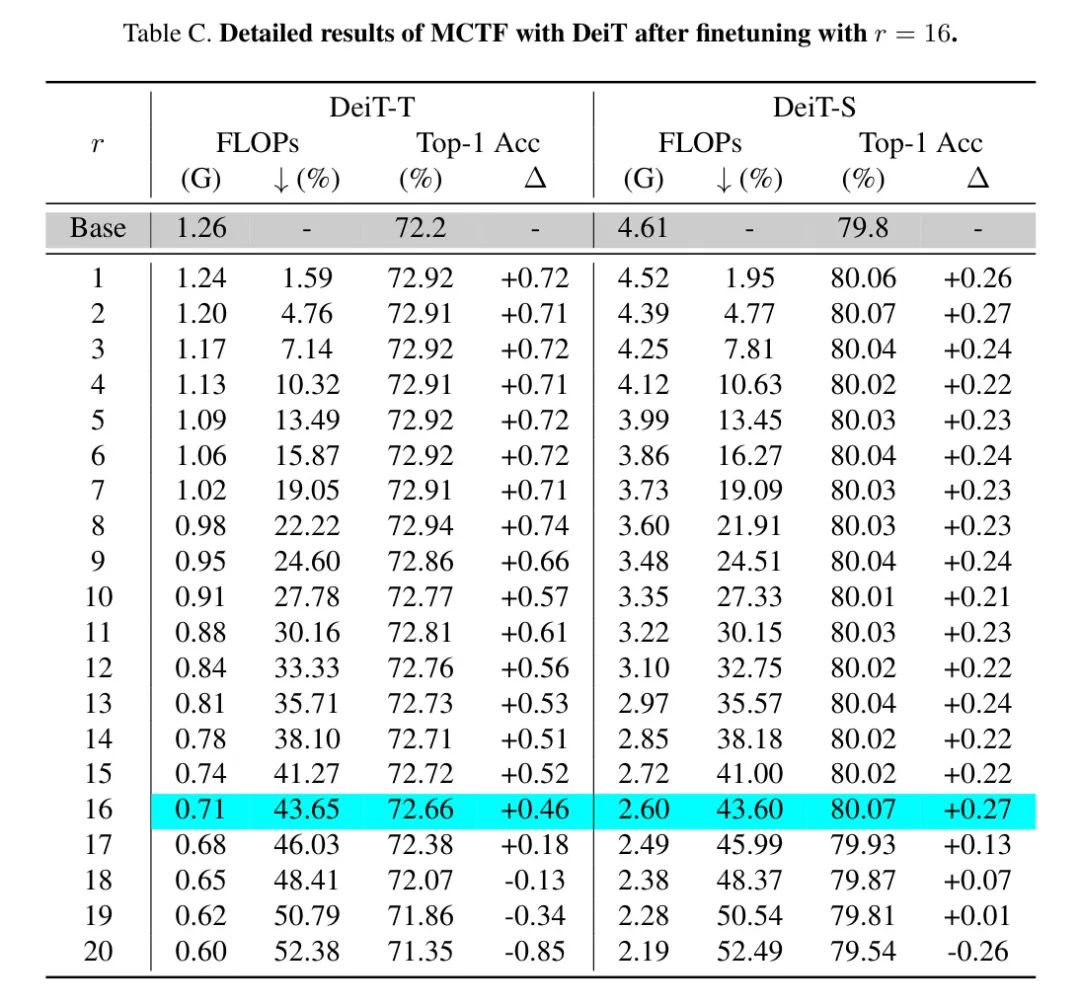
正如消融研究中的设置,作者首先使用每层减少的 Token 数 对模型进行微调,并报告了不同 下的浮点运算次数和准确度。作者突出了用于微调的那一行。同时,作者也展示了未经任何额外训练的MCTF的详细结果。无论是否进行微调的完整结果分别总结在表10和表5中。
Full results with T2T-ViT and LV-ViT
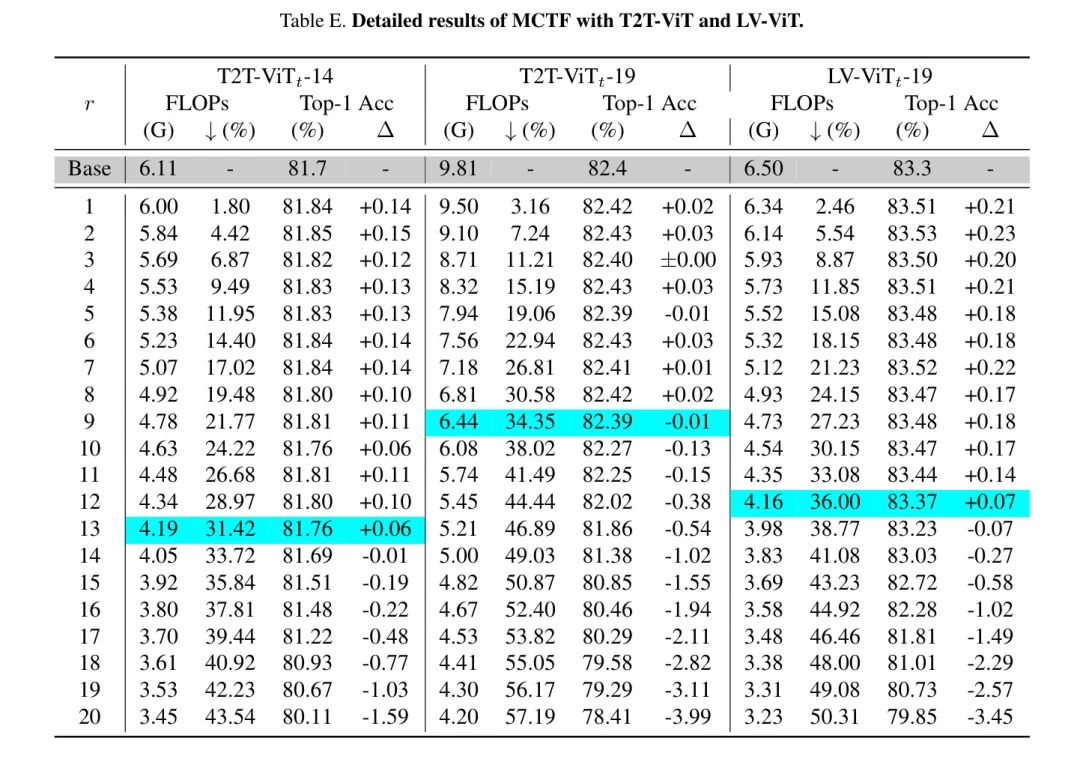
作者还展示了在表E中采用T2T-ViT和LV-ViT的完整结果。请注意,类似于DeiT-S,作者报告了在不同缩减比例下的FLOPs和准确度,这些是模型与特定缩减比例进行微调后得出的,并在表2中用于报告结果。作者还在这张表中突出了这个缩减比例。值得注意的是,尽管每个模型都针对特定的 进行了微调,但MCTF在从1到 的范围内展示了有希望的性能。
参考
[1].Multi-criteria Token Fusion with One-step-ahead Attention.

扫码加入👉「集智书童」交流群
(备注:方向+学校/公司+昵称)


前沿AI视觉感知全栈知识👉「分类、检测、分割、关键点、车道线检测、3D视觉(分割、检测)、多模态、目标跟踪、NerF」
欢迎扫描上方二维码,加入「集智书童-知识星球」,日常分享论文、学习笔记、问题解决方案、部署方案以及全栈式答疑,期待交流!