
香港城市大学研发发型合成新框架!手绘草图妙变逼真秀发
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达

来源:arXiv,新智元
编辑:贝壳
【导读】你见过手绘草图秒变逼真秀发吗?香港城市大学提出的新网络SketchHairSalon就可以,不但头发结构外观真假难辨,而且细节也清晰无比,只是通过简单寥寥几笔素描,想拥有什么样的发型都不在话下。
现有的解决方案通常需要用户提供的二进制掩码来指定目标发型。这不仅会增加用户的劳动成本,而且也无法捕捉复杂的头发边界。这些解决方案通常通过方向图编码头发结构,然而,这对编码复杂结构并不是很有效。
其实,彩色头发草图已经含蓄地定义了目标头发形状和头发外观,比方向图更灵活地描述头发结构。基于这些观察,香港城市大学提出了SketchHairSalon,一个两阶段框架,直接从手绘草图生成真实的头发图像,描绘所需的头发结构和外观。
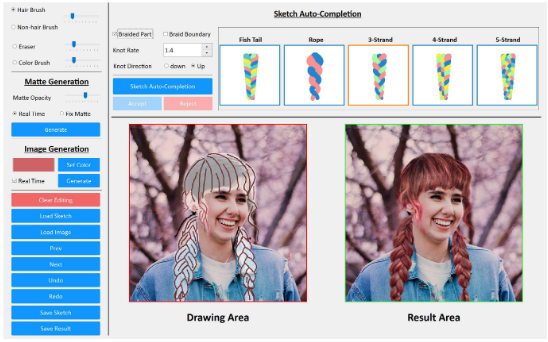
并且还提供了设计界面,如下图所示,包括Hair Structure Specification(头发结构定制)、Hair Shape Refinement(头发形状优化)、Hair Appearance Specification(头发的外观定制)、Sketch Auto-completion(自动完成草图)等功能。
设计思想
为了解决现有算法存在的问题,作者观察到头发草图本身包含了足够的信息来描述局部和整体层面上所需发型的结构、外观和形状。例如,对于一个波浪发型,一笔可以代表一个局部和连贯的头发束,而两笔可以用来形成一个t型结。彩色的笔画能够表明头发图像的局部外观。
此外,描绘发型结构的草图已经含蓄地定义了头发区域的整体形状,最好是沿着毛发区域的边界自动推断局部和柔软的细节,因为这些细节很难由用户指定,而且耗时。在这种情况下,由于支持软边界,毛发哑光比二进制掩模更适合描述毛发区域。
基于以上关键观察,作者提出了SketchHairSalon,一个新颖的深度生成框架,直接从一组彩色笔画合成真实的头发图像。它包括两个关键阶段:素描到亚光生成和素描到图像生成。
第一阶段侧重于从输入的头发草图生成头发哑光,以减少草图到头发生成的模糊性。用户可以选择输入非毛发笔画,这些笔画被用作额外的条件来指导哑光的生成。
第二阶段根据给定输入草图和生成的头发哑光,设法合成一个逼真的头发图像。同时将自我注意模块应用到这两个阶段的网络中,以学习更多的对应关系。
为了训练这两个阶段的网络,作者还提出了一个新的头发草图-图像数据集,其中包含了数以千计的头发图像和相应的手工注释的头发草图,以描述底层的头发结构。每个头发图像也与自动生成的头发哑光相关联。
网络架构
该网络框架由两个主要网络组成:
素描到亚光网络(简称S2M-Net)
素描到图像网络(简称S2I-Net)
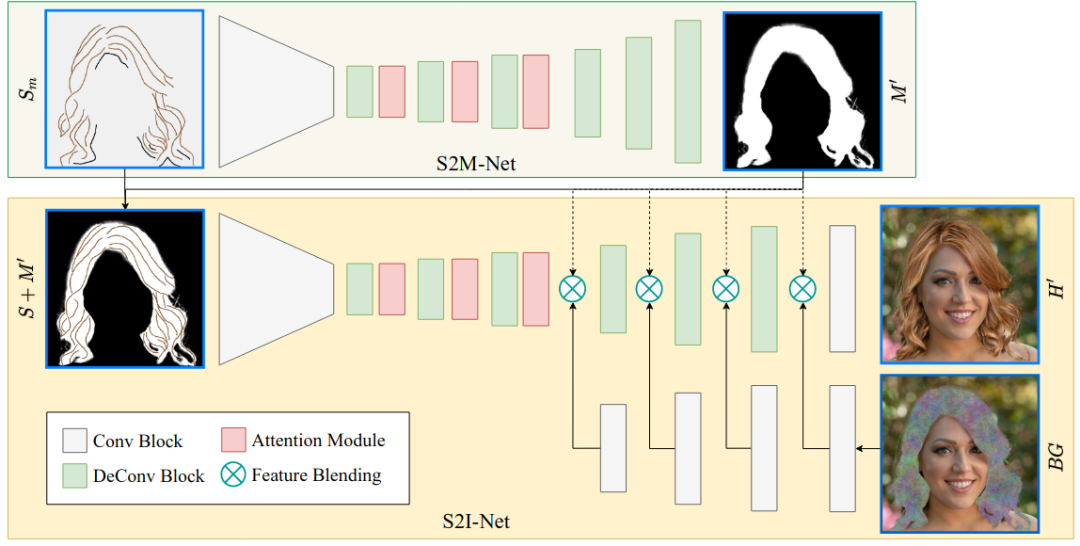
素描到亚光网络(S2M-Net)

S2M-Net以素描图𝑆𝑚𝑆𝑚𝑆𝑚𝑆𝑚𝑆𝑚𝑆𝑚Sm∈R512×512×1作为输入,其中包含头发和非头发的笔画,其中有色笔画设置为一种颜色(例如,蓝色),非笔画设置为黑色(如图4 (d)所示),即可输出头发哑光M𝑀'∈512×512×1(图4(a))。
为了准备用于训练S2M-Net的数据集,首先通过距离图从GroundTruth真实的头发遮光物中提取头发轮廓(图4 (b))。头发的轮廓从头发区域被稍微推开(从3到8像素随机设置)。
然后,通过随机擦除大部分头发轮廓推导出非头发笔画,以平衡训练中非头发笔画和头发笔画的密度。描边宽度随机设置为3到15像素,以定义非毛发区域的大小,避免过拟合。
最后,将非毛发笔画和毛发笔画在草图中融合在一起,表示为𝑆𝑚(如图4 (d)所示),然后送入S2M-Net。
另外,该部分网路采用了带有自注意模块的编码器-解码器生成器,在解码器的前三层中,在每个反卷积层之后重复应用三个自注意模块,以关注全局和高层翻译。
考虑到自注意力计算随着特征图空间尺寸的增大呈指数级增长,所以就没有在后一层插入任何自注意模块。
素描到图像网络(简称S2I-Net)
在S2M-Net之后,我们得到了一个合成的头发掩模M𝑀’,明确了目标头发的形状。如图5(下)所示,S2I-Net与S2M-Net类似,关键的区别在于它包含了背景混合模块,同上面这个网络不同,这里采用彩色草图来代表头发结构和外观。
背景区域𝐵𝐺在头发哑光𝑀'的引导下,在特征层上与合成头发区域混合,表示为:
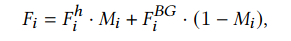
背景输入是通过用高斯噪声替换原始图像的毛发区域得到的。在S2I-Net的主分支,只在最后四层混合背景区域。
草图自动补全
由于大多数发型都有简单但较大的区域,具有相似的局部结构,需要用重复的头发笔画填充,以减少S2I-Net的模糊性。在设计发型时,要求用户画一套完整的头发线条是很乏味的。为了减少用户的工作量,作者提出了两种给定稀疏笔画的编发和非编发草图自动补全方法。
编织发型
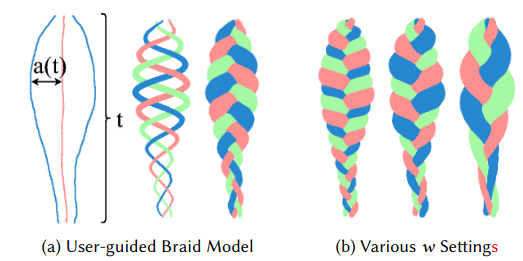
解开发型

给定输入的草图(a),medial-axis提取算法从(a)-(b)中提取额外的笔画(c)。(d)是完成的草图,其中蓝色笔画和绿色笔画分别是用户指定的和自动生成的笔画。
性能评估
头发哑光质量
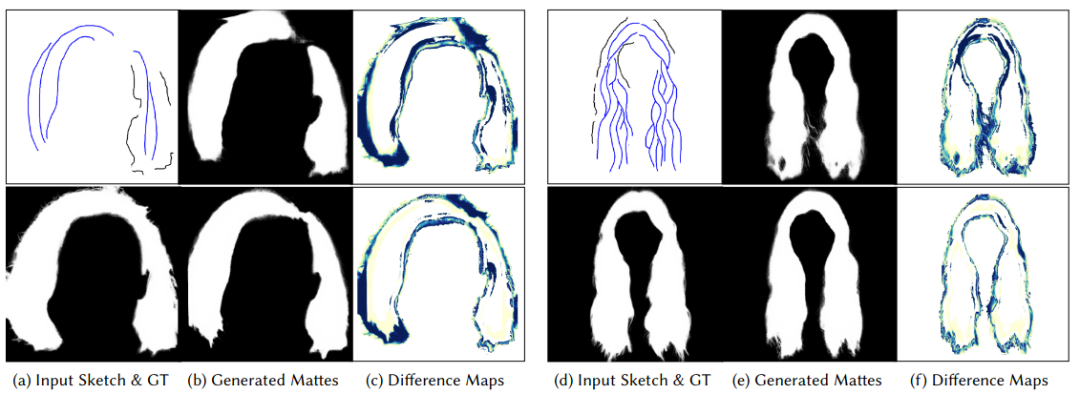
除(a)和(d)外,顶部一行为未设置自注意模块的模型,底部一行为设置自注意模块的模型。在每一组左右,(b)和(e)是给定草图((a)和(d)顶部)生成的Mask,而(c)和(f)是Mask和GT((a)和(d)底部)之间的差异图。在差值图中,蓝色区域越大,与GT值的差值越高。
基于草图的头发图像合成与其他算法的比较

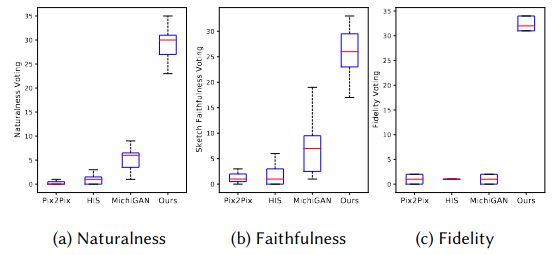
感知和可用性研究

消融实验

对比模型包含和不包含方向图的结果:(b)单独使用方向图;(c)使用草图和方向图;(d)单独使用草图。对于每一对(a),上面的是草图和背景输入,下面的是草图预测的稠密方向图。

比较模型变量在给定相同输入的不同设置下产生的结果(a)。(b)在合成数据集上训练。(c)没有注意模块,(d)完整模型。

两个不太成功的例子。顶部行显示不自然的结果缺乏足够的分层效果,而底部行显示自闭塞卷一起的失败案例。
参考资料:
https://arxiv.org/abs/2109.07874
交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
