
数仓(六)从0到1简单搭建数仓ODS层(埋点日志 + 业务数据)
数仓(三)简析阿里、美团、网易、恒丰银行、马蜂窝5家数仓分层架构
最近工作一直忙着,报名参加了上海地区观安杯CTF的比赛。第一次参加比预期好,拿了银行行业分行二等奖(主要是团队给力!)。
此外还在搞DAMA中国CDGA考证的事情。9月5日考试发挥正常,感觉应该是PASS可以拿到证书,数据治理证书我感觉最近几年会很火爆!就像十年前的项目管理证书PMP。数据管理,数据治理方向必定火爆!这次9月成绩北京、广州、深圳早一天出成绩,一些大佬特别是彭友会的已经发喜报了!
可惜上海今天中午才能出结果!中午吃饭的时候邮件推送消息显示81分!成功get证书,也是预料之中吧!
一、ODS层数据搭建前提工作
二、DataGrip利器使用
我们在操作数仓表、数据等需要使用一些工具,这里推荐使用JetBrains的DataGrip工具。
1、配置Data Source界面
添加数据源,选择Apache Hive
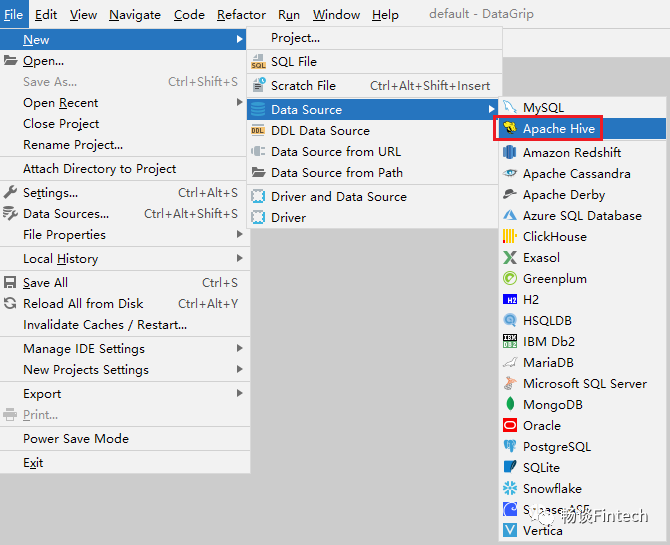
配置相关信息
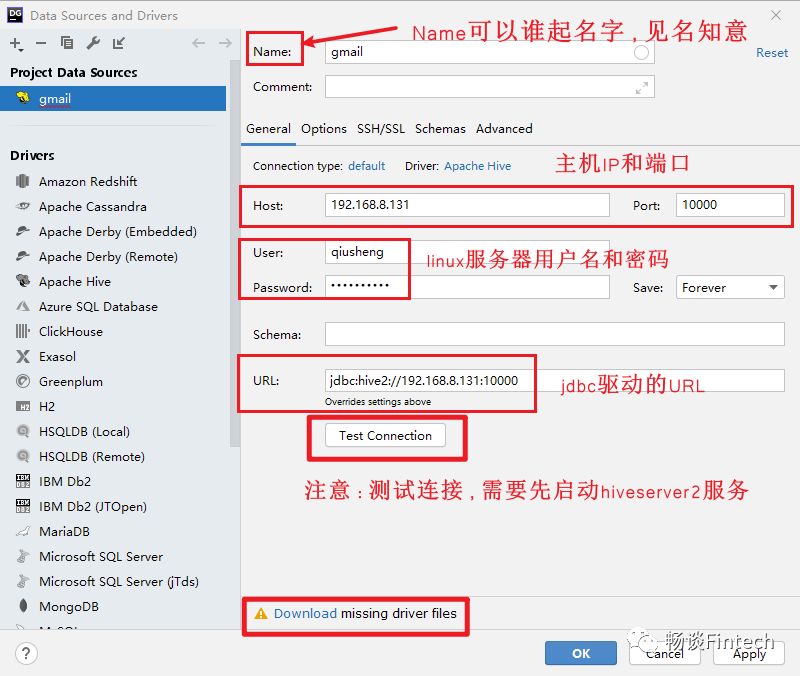
先启动hiveServer2服务
在做测试连接TestConnection前,先启动hiveServer2服务。
注意:并且有4个hive session id 出现才点击“TestConnection”按钮。否则出现connectied failure

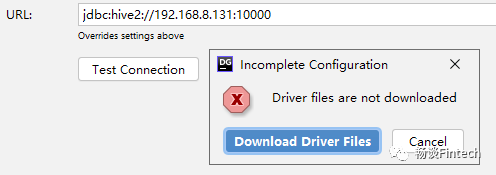
下载相应的驱动(自动下载)
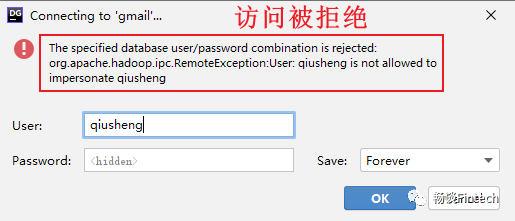
2、解决用户访问拒绝问题
这个报错界面,困扰了我一些时间,远程访问被拒绝,原因在于hive 和hdfs以及linux之间的权限问题。
解决办法如下:
配置hdfs的core-site.xml文件,配置用户;
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>测试后发现还是不行,报错依然是访问拒绝!qiusheng和root用户都不行
思考配置hive的hive-site.xml文件
<property>
<name>hive.server2.enable.doAs</name>
<value>FALSE</value>
<description>
Setting this property to true will have HiveServer2 execute
Hive operations as the user making the calls to it.
</description>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>true</value>
<description>
If "true", enable permission checking in HDFS.
If "false", permission checking is turned off,
but all other behavior is unchanged.
Switching from one parameter value to the other does not change the mode,owner or group of files or directories.
</description>
</property>
重启Hadoop集群
修改配置后需要重启hadoop。
测试连接
显示测试成功!说明主要问题在于linux用户访问HDFS权限问题。
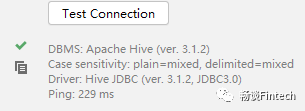
3、查看hive仓库里面的数据库和表以及内容
发现student里面已经有id和name字段了
当然,也可以通过beeline来通过SQL查询。

三、ODS层(埋点日志处理)
首先我们回顾一下ODS层的主要作用和特点:
又叫“贴源层”,这层保持数据原貌不做任何修改,保留历史数据,储存起到备份数据的作用。 数据一般采用lzo、Snappy、parquet等压缩格式,减少磁盘存储空间(例如:原始数据 10G,根据算法可以压缩到 1G 左 右)。 创建分区表,防止后续的全表扫描,减少集群资源访问数仓的压力,一般按天存储在数仓中。
1、创建前端埋点日志ods_log表
前端埋点日志信息都是JSON格式形式主要包括两方面:
(1)启动日志;(2)事件日志:

我们把前端整个1条记录埋点日志,当一个字符串来处理,传入到hive数据库。
创建HQL语句如下:
在DataGrip里面执行
drop table if exists ods_log;create external table ods_log(line string)partitioned by (dt string)Stored asinputformat 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'outputformat 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'Location '/warehouse/gmail/ods/ods_log';
添加lzo索引
还需要在hive文件上,添加lzo索引,要不然无法支持切片操作。
具体做法是通过hadoop自带的jar包在hadoop集群命令行里面执行:
hadoop jar /opt/module/hadoop-3.1.4/share/hadoop/common/hadoop-lzo-0.4.20.jarcom.hadoop.compression.lzo.DistributedLzoIndexer-Dmapreduce.job.queuename=hive/warehouse/gmail/ods/ods_log/dt=2021-05-01
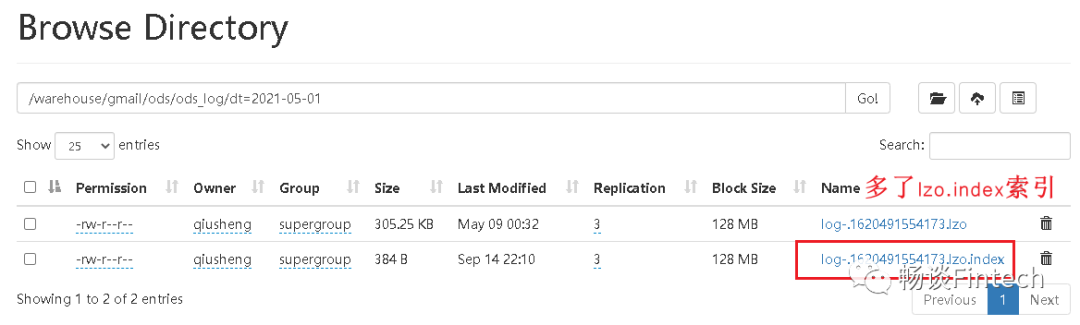
2、执行完,观察Browser Director
发现已经多了lzo.index索引
3、加载读取HDFS数据到hive
load data inpath '/origin_data/gmall/log/topic_log/2021-05-01'into table ods_log partition (dt='2021-05-01');
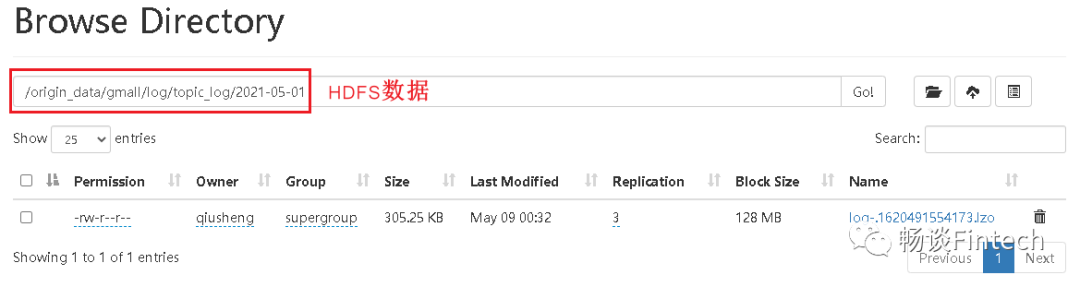
加载到hive,路径是
/warehouse/gmail/ods/ods_log/dt=2021-05-01
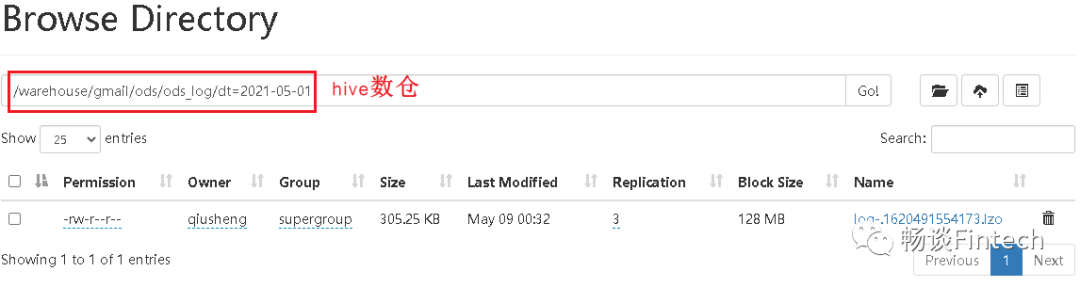
load做的是剪切的操作!
4、查看hive库数据是否已经加载成功?
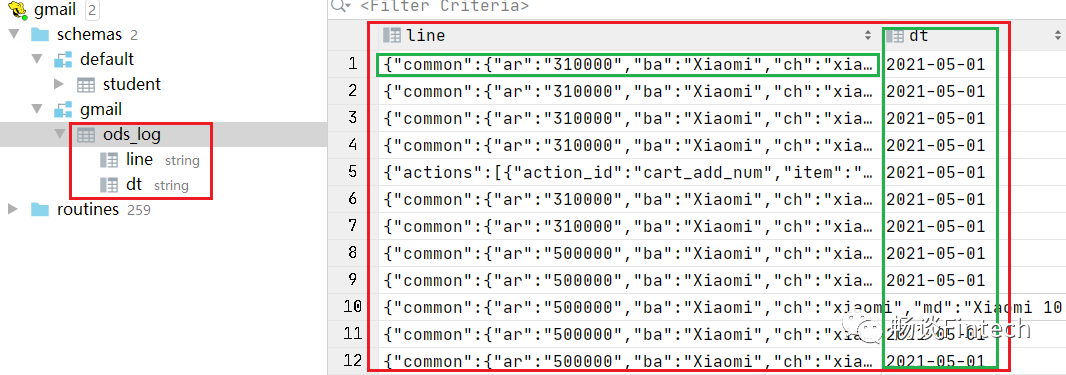
这样我们就完成了ODS层前端埋点日志的处理。
四、ODS层(业务数据处理)
现在我们来处理ODS层业务数据,先需要回顾一下ODS层当时建表的表结构关系。
1、业务表逻辑结构关系
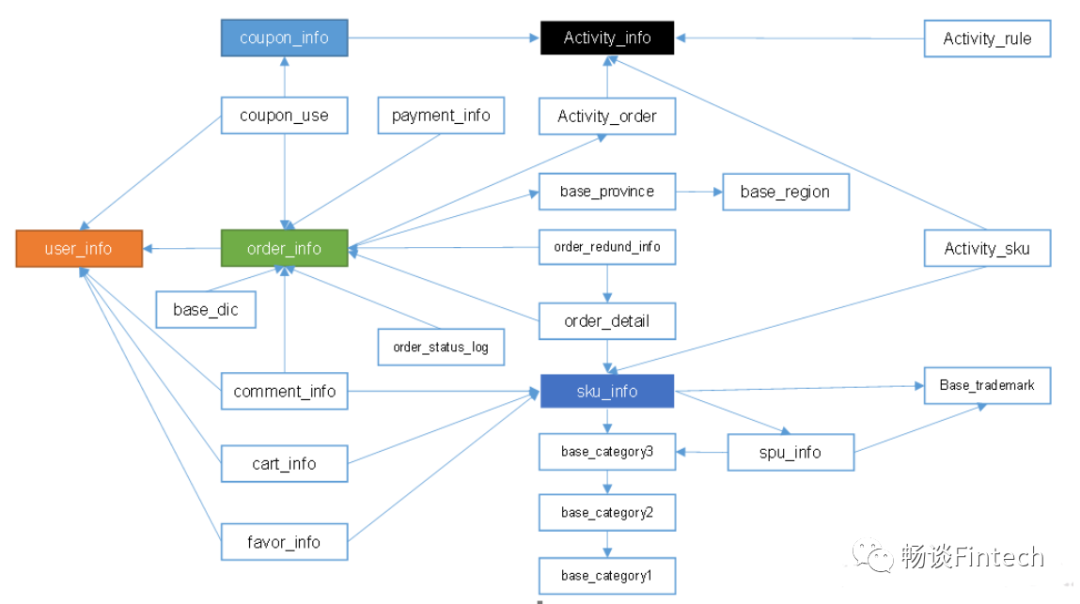
其中有颜色填充的代表:事实表;
其他:代表维度表;
2、HDFS文件对应hive表结构关系

源业务系统javaweb项目中的数据存储在mysql里面,通过sqoop采集到HDFS对应的文件,需要在hive数仓里面设计外部表与其一一对应;
(1)考虑到分区partitioned by 时间
(2)考虑到lzo压缩,并且需要lzo压缩支持切片的话,必须要添加lzo索引
(3)mysql数据库的表通过sqoop采集到HDFS,用的是\t作为分割,那数仓里面ODS层也需要\t作为分割;
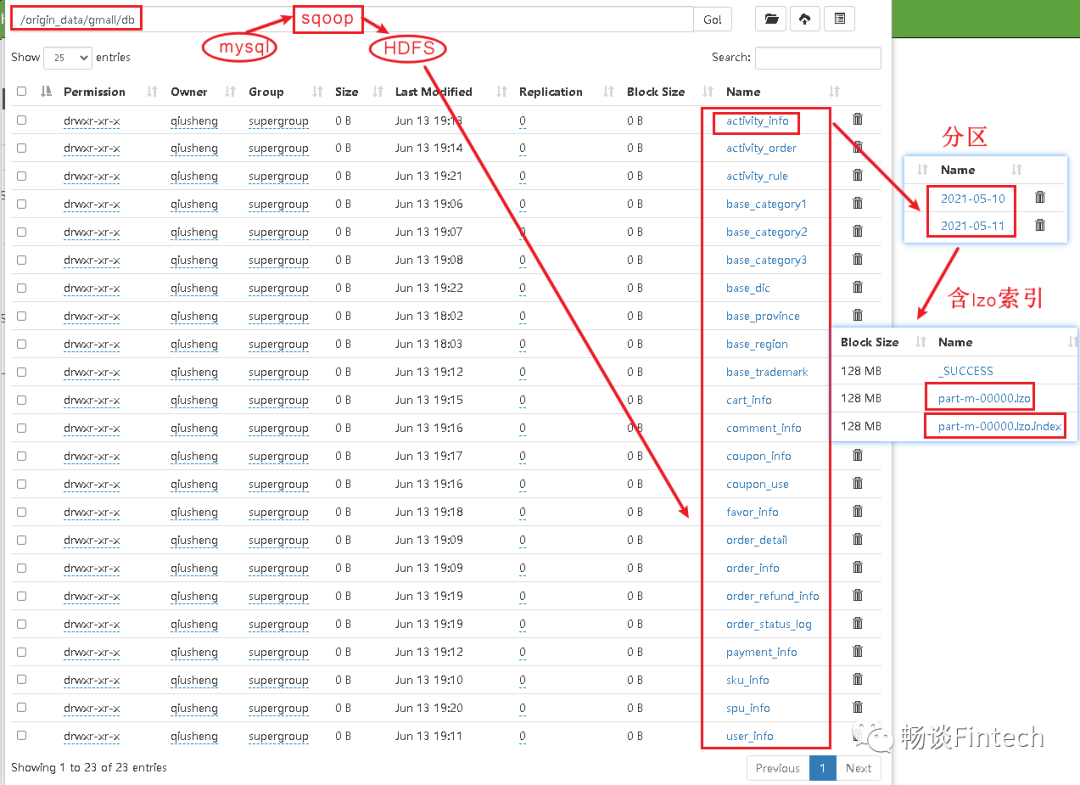
3、创建ODS层业务表
这里我们业务系统javaweb项目一共有23张表,数仓hive我们这里只演示创建三张代表性的表。因为23张创建表的结构大都一样,这里只有3种数据同步策略的方式。
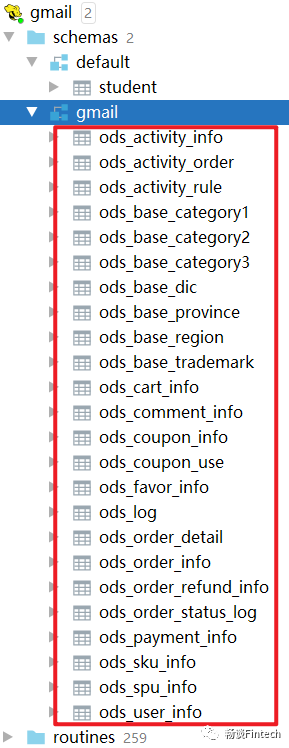
订单表ods_order_info
表数据同步更新策略:增量
drop table if exists ods_order_info;create external table ods_order_info (`id` string COMMENT '订单号',`final_total_amount` decimal(16,2) COMMENT '订单金额',`order_status` string COMMENT '订单状态',`user_id` string COMMENT '用户id',`out_trade_no` string COMMENT '支付流水号',`create_time` string COMMENT '创建时间',`operate_time` string COMMENT '操作时间',`province_id` string COMMENT '省份ID',`benefit_reduce_amount` decimal(16,2) COMMENT '优惠金额',`original_total_amount` decimal(16,2) COMMENT '原价金额',`feight_fee` decimal(16,2) COMMENT '运费') COMMENT '订单表'PARTITIONED BY (`dt` string) -- 按照时间创建分区row format delimited fields terminated by '\t' -- 指定分割符为\tSTORED AS -- 指定存储方式,读数据采用LzoTextInputFormat;输出数据采用TextOutputFormatINPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'location '/warehouse/gmail/ods/ods_order_info/'; -- 指定数据在hdfs上的存储位置
SKU商品表ods_sku_info表
数据同步更新策略:全量
drop table if exists ods_sku_info;create external table ods_sku_info(`id` string COMMENT 'skuId',`spu_id` string COMMENT 'spuid',`price` decimal(16,2) COMMENT '价格',`sku_name` string COMMENT '商品名称',`sku_desc` string COMMENT '商品描述',`weight` string COMMENT '重量',`tm_id` string COMMENT '品牌id',`category3_id` string COMMENT '品类id',`create_time` string COMMENT '创建时间') COMMENT 'SKU商品表'PARTITIONED BY (`dt` string)row format delimited fields terminated by '\t'STORED ASINPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'location '/warehouse/gmail/ods/ods_sku_info/';
省份表ods_base_province
数据同步更新策略:特殊一次性全部加载
不做分区partitioned BY
drop table if exists ods_base_province;create external table ods_base_province (`id` bigint COMMENT '编号',`name` string COMMENT '省份名称',`region_id` string COMMENT '地区ID',`area_code` string COMMENT '地区编码',`iso_code` string COMMENT 'iso编码,superset可视化使用') COMMENT '省份表'row format delimited fields terminated by '\t'STORED ASINPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'location '/warehouse/gmail/ods/ods_base_province/';
4、加载数据
load datainpath '/origin_data/gmall/db/order_info/XXXX-XX-XX'OVERWRITE into table gmail.ods_order_info partition(dt='XXXX-XX-XX');
显示如下:
然后把其他20张表也类似这样操作,我们就完成了整个ODS层的数据处理。