
面试精选:手把手带你拆解 LRU 与 LFU
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


LFU
LFU 算法,全称 Least Frequently Used Algorithm,最不常用算法。
LFU 是基于 “如果一个页面在最近一段时间内使用次数很少,那么在将来一段时间内使用的可能性很小” 的思路。当发生缺页中断时,选择访问次数最少的那个页面,并淘汰之。
与 LRU (Least Recently Used) 算法相比较,LRU 是从时间维度进行考虑的,即 “如果一个页面在最近一段时间被访问过,那么它在将来被访问的可能性就很大”。当发生缺页中断时, LRU 优先考虑淘汰最久没有被访问过的页面。
记忆要点:LRU 考察的是多久未访问,时间越短越好;而 LFU 考虑的是访问次数或频度,访问次数越多越好。
实现方法:对每一个页设置一个访问计数器,每当一个页面被访问时,该页面的访问计数器加 1。在发生缺页中断时,淘汰计数值最小的那个页面。如果所有页具有相同的频率,则对该页采取 LRU 方法并删除该页。
问题描述
题目来源于 LeetCode 460 - LFU Cache[1] ,当然Ketan Shah 教授等人在 2010 年发表了题为 An O(1) algorithm for implementing the LFU cache eviction scheme[2] 的文章。
请你为 最不经常使用(LFU)缓存算法设计并实现数据结构。
实现 LFUCache 类:
LFUCache(int capacity)- 用 LFU 的容量 capacity 初始化对象int get(int key)- 如果键存在于缓存中,则获取键的值并返回,否则返回 -1。void put(int key, int value)- 如果键已存在,则更新其值;如果键不存在,请插入键值对。当缓存达到其容量时,则应该在插入新页之前,淘汰最不经常使用的页。在此问题中,当存在平局(即两个或更多个键具有相同使用频率)时,应该去除 最近最久未使用 的键。注意「项的使用次数」就是自插入该项以来对其调用 get 和 put 函数的次数之和。使用次数会在对应项被移除后置为 0 。为了确定最不常使用的键,可以为缓存中的每个键维护一个 使用计数器 。使用计数最小的键是最久未使用的键。
当一个键首次插入到缓存中时,它的使用计数器被设置为 1 (由于 put 操作)。对缓存中的键执行 get 或 put 操作,使用计数器的值将会递增。
这道题目频繁出现在字节跳动、网易、阿里等大厂的面试中。在力扣上,这道题目的难度是 Hard 级别,很多未曾接触和思考过这道题目的同学往往难以下手。
暂且放下题目本身的解法,反过来问一问,为什么面试官喜欢选择这样的题目考察面试者呢?
那一定是因为题目可以考察面试者对算法理解的深度和熟练程度。如果面试官提出实现一个 LRU 算法,此前你仅仅在操作系统的课程上接触过,你可能就会回答出我在最开始介绍的那些理论,但这是对一个毕业生最起码的要求,并不会加分,回答不好只能减分。
那么究竟怎样才能说服面试官呢?
从这篇文章中你将获得以下知识:
双向链表的添加和删除
哈希的特点
基础数据结构的组合:哈希 + 双向链表
LRU 算法的解析
LFU 算法的解析
双向链表
对于基础的数据结构,不论是线性表、链表、队列和栈等等,都应该了然于胸。双向链表的添加与删除操作当然也不例外。

拥有伪头部和伪尾部的双向链表
在拥有伪头部和伪尾部的双向链表中采用 头插法 添加一个元素的步骤大家应该也很清晰:
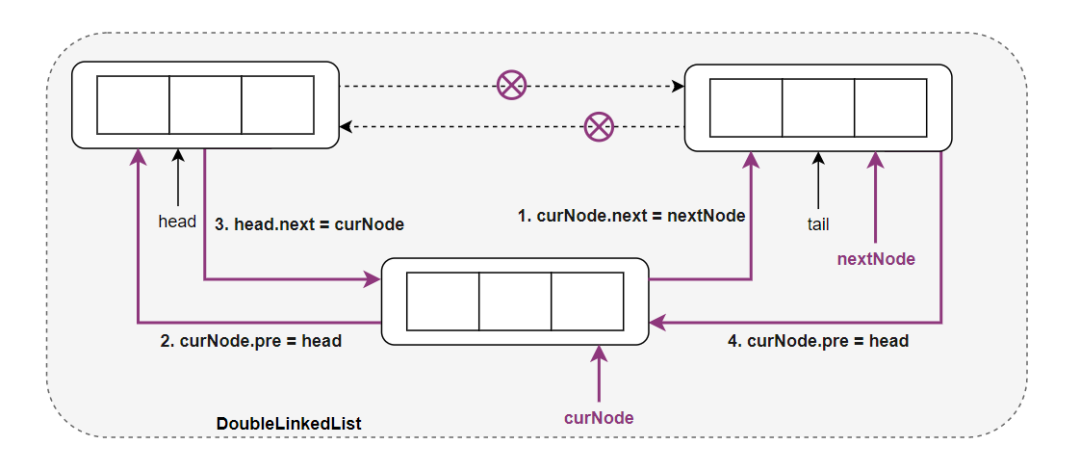
双向链表采用头插法插入一个结点
其中 head 指针表示头结点,tail 指针表示尾结点,curNode 表示当前要插入的结点,双向链表插入一个新结点指针的修改顺序一般就是图中的 4 个步骤。
对于删除双向链表尾部结点同样注意结点指针的修改顺序:
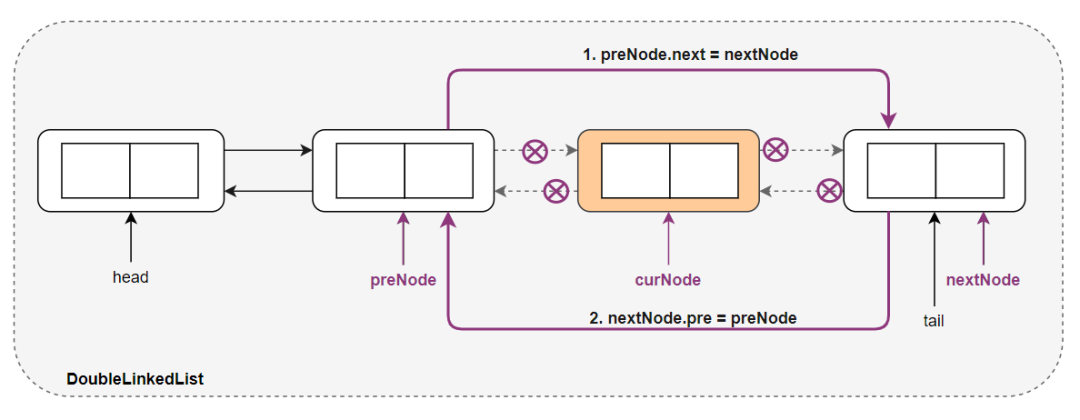
删除双向链表的一个结点
其中 curNode 表示当前要删除的结点,preNode 表示当前要删除结点的前驱结点,nextNode 表示当前结点的后继结点,删除双向链表中的一个结点只需将 preNode 的后继结点设置为 nextNode ,而将 nextNode 的前驱结点设置为 preNode 。
这是双向链表两个最基本的操作,我们也都知道双向链表的插入和删除操作的时间复杂度为 ,查找的时间复杂度为 ,但是面试官一般会要求你将查找的时间复杂度也降至 ,我们自然会想到哈希算法。
哈希
关于哈希的详细信息大家可以参考:图解:什么是哈希?
这里你只需掌握一个关键点:利用哈希可以保证我们利用指定的 key 在 的时间获取到指定的 value ,其中 key 和 value 可以是一个整数值,也可以是一个对象。
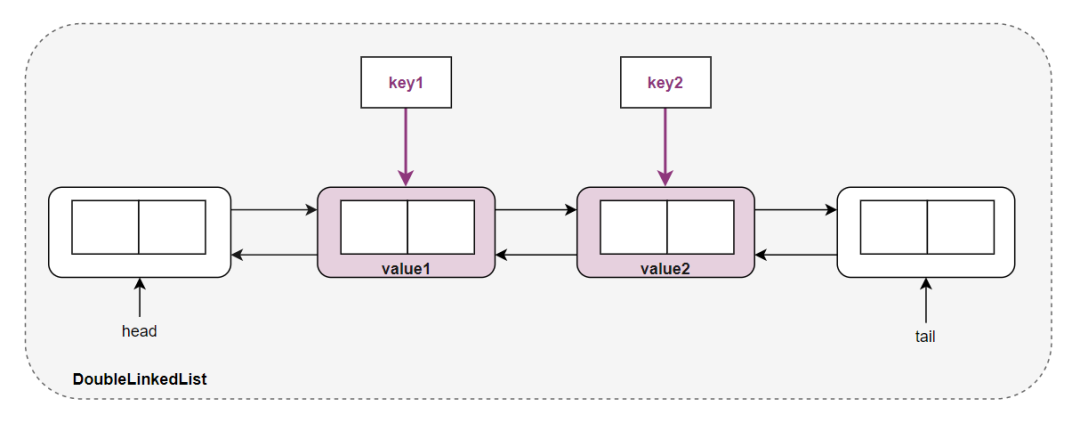
哈希算法
其中的 value 就表示双向链表的一个结点,而 key 则是页号。
双向链表 + 哈希
由于双向链表的查找时间复杂度为 ,而插入和删除的复杂度为 ,要设计一种查找、插入和删除均为 的数据结构,哈希算法 + 双向链表便是一个绝妙的组合。
我们可以将双向链表结点和结点的值之间建议一对一的映射关系,便可以在 的时间获取到结点本身,然后对结点进行插入和删除操作即可。
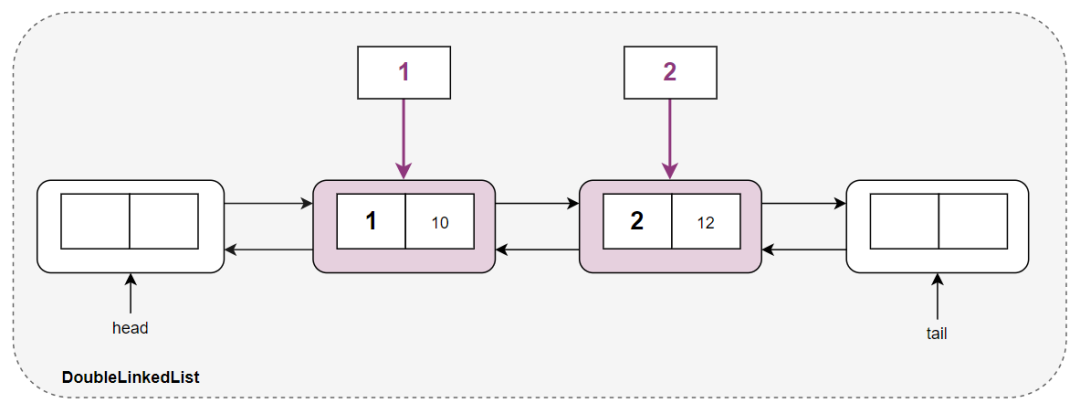
哈希算法 + 双向链表组合体
这便是 LRU 和 LFU 的基础框架。
我们也不难写出这样的框架代码:
class Cache {
private Map<Integer, Node> cache;
public int get(int key) {}
public void put(int key, int value) {}
class DoubleLinkedList {}
}
接下来就是完善这个框架。
LRU 缓存
关于 LRU 缓存在之前的文章中已有分享,详情请参阅 :深入剖析 LRU 算法和 LRU 缓存机制背后的数据结构 。
这里就不详细展开了,因为 LRU 缓存仅是 LFU 的一个子过程,会了 LFU ,LRU 自然也不在话下,不过还是建议大家做一下 LeetCode 146 - LRU 缓存机制[3] 。
LFU 算法
对于 LFU 算法,涉及到 3 个关键的变量,这三个变量的信息在题目中就可采集:
key,用来标识一个双向链表的结点;value,表示key所对应的值,也就是结点本身所保存的值;frequency,表示结点被访问的次数或频度。
有了这三个信息点,我们可以定义出一个双向链表的结点,用来模拟 LFU 的缓存块。
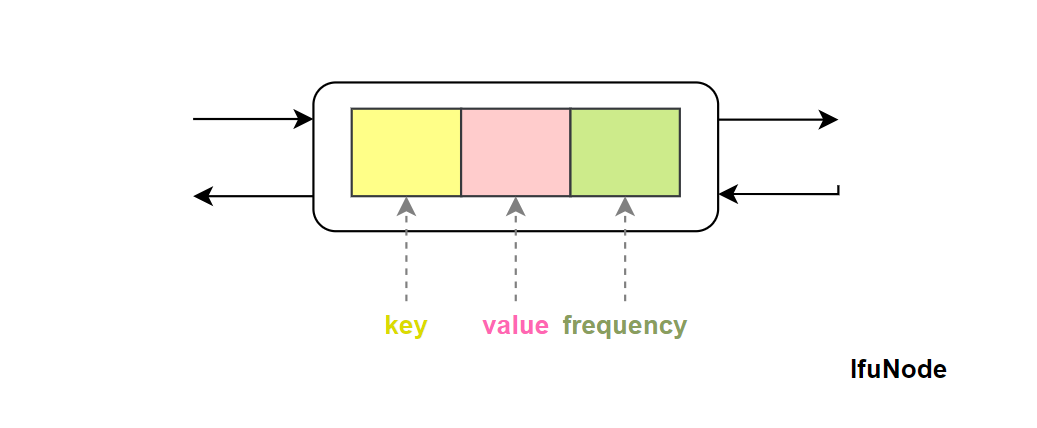
lfrNode 双向链表结点
定义一个 LFUNode :
class LFUNode {
int key;
int val;
int frequency;
LFUNode prev;
LFUNode next;
public LFUNode(int key, int val) {
this.key = key;
this.val = val;
this.frequency = 1;
}
}
然后我们可以完善 DoubleLinkedList 类,添加删除和插入的方法:
/**
* listSize 表示双向链表的大小
* head 表示双向链表的头结点
* tail 表示双向链表的尾结点
*/
class DoubleLinkedList {
int listSize;
LFUNode head;
LFUNode tail;
public DoubleLinkedList() {
this.listSize = 0;
this.head = new LFUNode(0, 0);
this.tail = new LFUNode(0, 0);
head.next = tail;
tail.prev = head;
}
/** 在链表的头部添加一个结点,链表长度加 1 **/
public void addNode(LFUNode curNode) {
LFUNode nextNode = head.next;
curNode.next = nextNode;
curNode.prev = head;
head.next = curNode;
nextNode.prev = curNode;
listSize++;
}
/** 删除链表中的结点,链表长度减 1 **/
public void removeNode(LFUNode curNode) {
LFUNode prevNode = curNode.prev;
LFUNode nextNode = curNode.next;
prevNode.next = nextNode;
nextNode.prev = prevNode;
listSize--;
}
/** 删除尾部结点 **/
public LFUNode removeTail() {
// 别忘了判断链表的长度
if (listSize > 0) {
LFUNode tailNode = tail.prev;
removeNode(tailNode);
return tailNode;
}
return null;
}
}
注意 addNode(LFUNode curNode) 方法采用的头插法,将当前结点插入到双向链表的头部;removeTail() 方法删除的双向链表尾部的结点 tail.prev ,一定要注意边界条件的判断,防止操作一块未知的内存空间。
做好准备工作之后,接下来要做的就是设计实现 int get(int key) 和 void put(int key, int value) 两个方法了。
再次回到题目描述:
int get(int key)- 如果键存在于缓存中,则获取键的值并返回,否则返回 -1。void put(int key, int value)- 如果键已存在,则更新其值;如果键不存在,请插入键值对。当缓存达到其容量时,则应该在插入新页之前,淘汰最不经常使用的页。在此问题中,当存在平局(即两个或更多个键具有相同使用频率)时,应该去除 最近最久未使用 的键。
其实根据题目描述,我们就可以写出 get 和 put 方法的框架:
public int get(int key) {
LFUNode curNode = cache.get(key);
if (curNode == null) {
return -1;
}
updateNode(curNode);
return curNode.val;
}
public void put(int key, int value) {
if (cache.containsKey(key)) {
// 更新 key 所对应的值 value
}
else {
// 插入键值对
}
}
其中的 updateNode 表示更新结点的值,具体如何更新我们稍后补充,接下来,我们需要解决的是题目中描述的 “当缓存达到其容量时,则应该在插入新页之前,淘汰最不经常使用的页。在此问题中,当存在平局(即两个或更多个键具有相同使用频率)时,应该去除 最近最久未使用 的键。” 的问题。
当缓存达到其容量时,则应该插入新页之前,淘汰最不经常使用的页。所以我们需要一个全局变量来标识 LRU Cache 的容量,还需要一个标识当前 LFU Cache 当前容量的变量,“淘汰最不经常使用的页” 意味着我们要标识当前 LFU Cache 中访问频率(次数)最少的页面,同时由于不论是访问次数最少的页面,还是其他页面均存在平局的可能,所以我们需要将这些访问频次相同的页面通过双向链表组织在一起,也就是位于同一双向链表中的页面具有相同的频度 freq 。如何快速的访问到某一频度 freq 所对应的双向链表呢?我们就可以考虑将页面的访问次数 freq 与双向链表之间建议映射关系,即利用哈希,在 的时间访问到具有相同 freq 的页。
而在具有相同 freq 的双向链表内部,我们通过 LRU 的方法进行处理即可。LFU cache 的数据结构逻辑图就是如下这样:
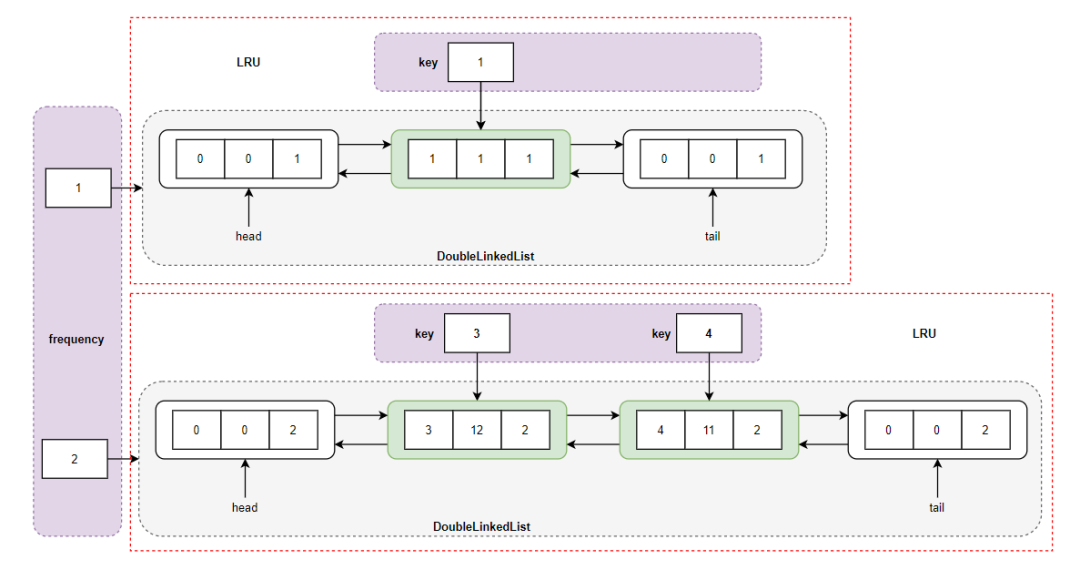
LFU Cache 数据结构图
对于这个图的理解,可以让你彻底搞清楚 LRU 和 LFU 的关系,LFU 包含多个 LRU ,其中的红色虚线方框内的结构就是 LRU 数据结构图。
class LFUCache {
private final int capacity; // LFU Cache 的容量
private int curSize; // LFU Cache 当前的容量
Map<Integer LFUNode> cache;
Map<Integer DoubleLinkedList> frequencyMap; // freq 到 DoubleLinkedList 之间的映射关系
public LFUCache(int capacity) {
this.capacity = capacity;
this.curSize = 0;
this.minFrequency = 0;
this.cache = new HashMap<>();
this.frequencyMap = new HashMap<>();
}
}
我们继续完善 put(int key, int value) 方法,要插入键值对,又可以分为两个子条件判断:
LFU Cache 的空间已满,在 freq最小的双向链表内删除最近最少访问的页面(也就是双向链表尾部结点),然后再添加新结点;如果空间足够,则直接添加新结点即可。
public void put(int key, int value) {
if (cache.containsKey(key)) {
LFUNode curNode = cache.get(key);
curNode.val = value;
updateNode(curNode); //更新当前结点的频度
}
else {
curSize++;
if (curSize > capacity) { // LFU Cache 已满
// 获取到访问次数最少的双链表
DoubleLinkedList minFreqList = frequencyMap.get(minFrequency);
LFUNode deleteNode = minFreqList.removeTail(); // 删除 LRU 页面
cache.remove(deleteNode.key); // 在 cache 中删除结点
curSize--;
}
// 因为插入新的结点,所以将最小的访问次数重置为 1
minFrequency = 1; // 插入新的键值对<key, value>
LFUNode newNode = new LFUNode(key, value);
// 获取 freq = 1 所对应的双向链表,如果不存在就新建一个双链表
DoubleLinkedList curList = frequencyMap.getOrDefault(1, new DoubleLinkedList());
curList.addNode(newNode); // 插入新结点
frequencyMap.put(1, curList); // frequency 中添加 1 -> DoubleLinkedList
cache.put(key, newNode); // cache 中添加 key -> newNode
}
}
但是一定要注意在 put() 方法内部最开始对 LFU 的 capacity 进行校验,防止初始化时 LFU 的缓存大小是 0 的情况,直接退出。
public void put(int key, int value) {
if (capacity == 0){
return;
}
}
接下来就是完善最关键的一个方法 updateNode() 方法,该方法出现在两处。
一处是 get(int key) 方法中,用于更新 LFU 缓存当中已存在 key 所对应的 freq ,因为每调用一次 get() 方法,就相当于访问 key 一次,那么该 key 所对应的频率(访问次数)也需要相应的进行更新。
一处出现在 put(int key, int value) 当中,当 key 已经在内存中存在时,则更新 key 所对应的结点 value 以及频率 freq ,同时对 LFU Cache 的存储结构做出调整。
public void updateNode(LFUNode curNode) {
int curFreq = curNode.frequency;
DoubleLinkedList curList = frequencyMap.get(curFreq);
curList.remove(curNode);
// 当前结点的频率 + 1
curNode.frequency++;
// 将频率加 1 之后的结点添加 freq 为 cur.frequency 的新的双向链表中
// 如果该链表不存在,则创建一个新的双向链表并添加 curNode
DoubleLinkedList newList = frequencyMap.getOrDefault(curNode.frequency, new DoubleLinkedList());
newList.addNode(curNode);
frequencyMap.put(curNode.frequency, newList);
}
但上面的这段代码并不完整,因为我们缺少一个关键的边界判断,那就是当前被更新的结点 curNode 刚好在 minFrequency 所指向的双向链表当中,且该双链表中仅包含 curNode 一个结点,从 curList 中删除结点 curNode 将导致整个 LFU 缓存中最少访问次数的提升,即最少访问次数 minFrequency 需要进行加 1 操作 。这一边界情况的判断一定要添加到更新操作之前:
public void updateNode(LFUNode curNode) {
int curFreq = curNode.frequency;
DoubleLinkedList curList = frequencyMap.get(curFreq);
curList.remove(curNode);
// curNode所在双链表的频率为minFrequency 且仅包含 curNode 一个结点
if (curFreq == minFrequency && curList.listSize == 0) {
minFrequency++;
}
// 当前结点的频率 + 1
curNode.frequency++;
// 将频率加 1 之后的结点添加 freq 为 cur.frequency 的新的双向链表中
// 如果该链表不存在,则创建一个新的双向链表并添加 curNode
DoubleLinkedList newList = frequencyMap.getOrDefault(curNode.frequency, new DoubleLinkedList());
newList.addNode(curNode);
frequencyMap.put(curNode.frequency, newList);
}
至此,我们完成了整个 LFU Cache 块的设计和开发。
但是还是不排除有的小伙伴不理解,记住:看完之后不理解,那只能说明我讲的不够清楚,而不是你的问题!
为了消除你对上面所讲的 LFU 算法的所有疑惑,我们一起以一个简单的例子再作为解释。
图解 LFU
输入:
["LFUCache", "put", "put", "get", "put", "get", "get", "put", "get", "get", "get"]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [3], [4, 4], [1], [3], [4]]
输出:
[null, null, null, 1, null, -1, 3, null, -1, 3, 4]
我们对此输入依次进行图解。
LFUCache lfuCache = new LFUCache(2) 表示申请一个容量为 2 的 LFU 缓存。
紧接着执行 put(1,1) 操作,创建一个新的双向链表,并采用头插法插入新的结点 <1,1,1> ,cache 增加到结点的映射,frequencyMap 增加 freq 到双向链表的映射:
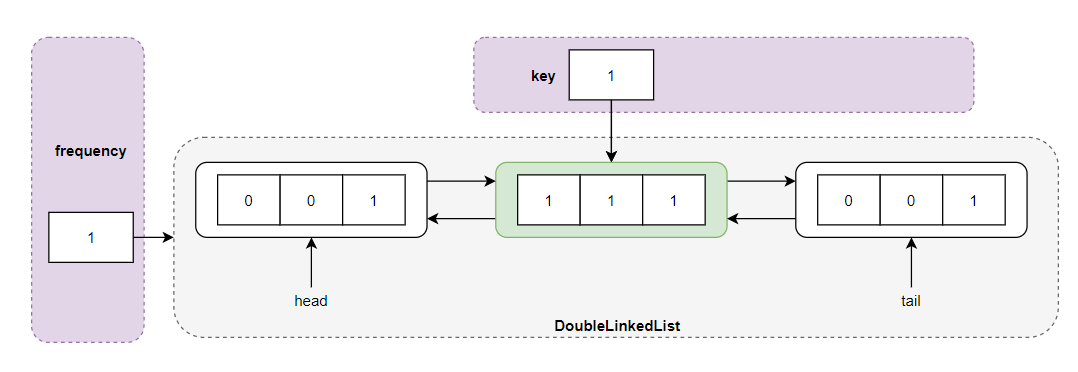
执行 put(1,1) 操作之后的存储结构
执行 put(2,2) 操作,发现 LFU 缓存未满且不包含 key = 2 的结点,而且频率 freq = 1 的双向链表已经存在了,则直接采用头插法将结点 <2,2,1> 插入到频度 freq = 1 所对应的双向链表中:
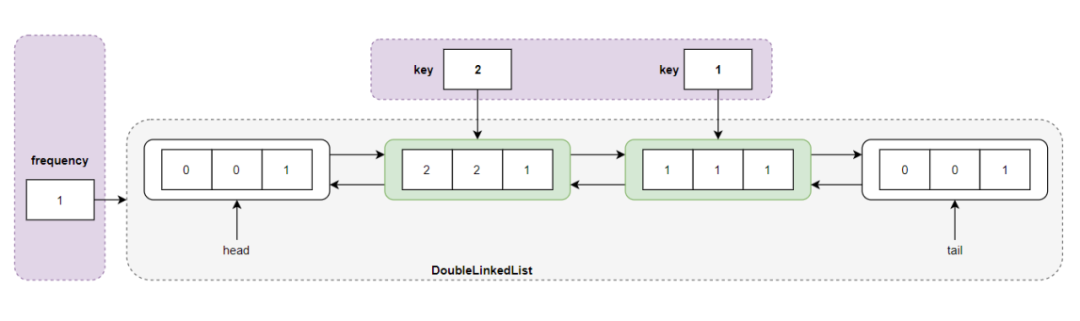
执行 put(2,2) 操作之后的存储结构
执行 get(1) 操作,发现 key = 1 的结点在 LFU 缓存中,通过 cache 查找到结点,然后调用 updateNode() 函数对结点进行更新,将其频度进行加 1 操作,即结点变成了 <1,1,2> ,但是频度为 2 的链表并不存在,所以创建新链表并插入结点 <1, 1, 2> :
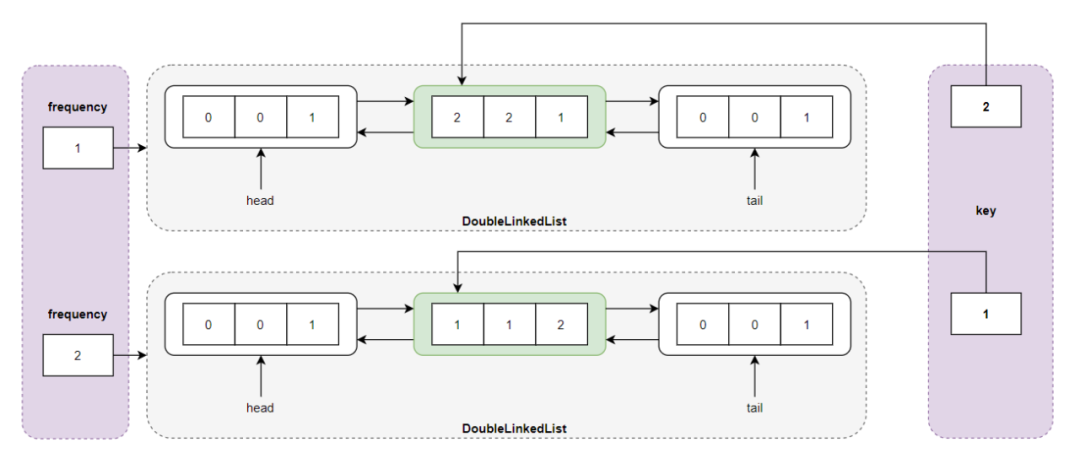
执行 get(1) 操作之后的存储结构
执行 put(3,3) 操作,此时 LFU Cache 的缓存已满 capacity = 2 ,首先删除访问频度最小的双链表中的尾结点 <2,2,1> ,然后插入频度为 1 的新结点 <3,3,1> :
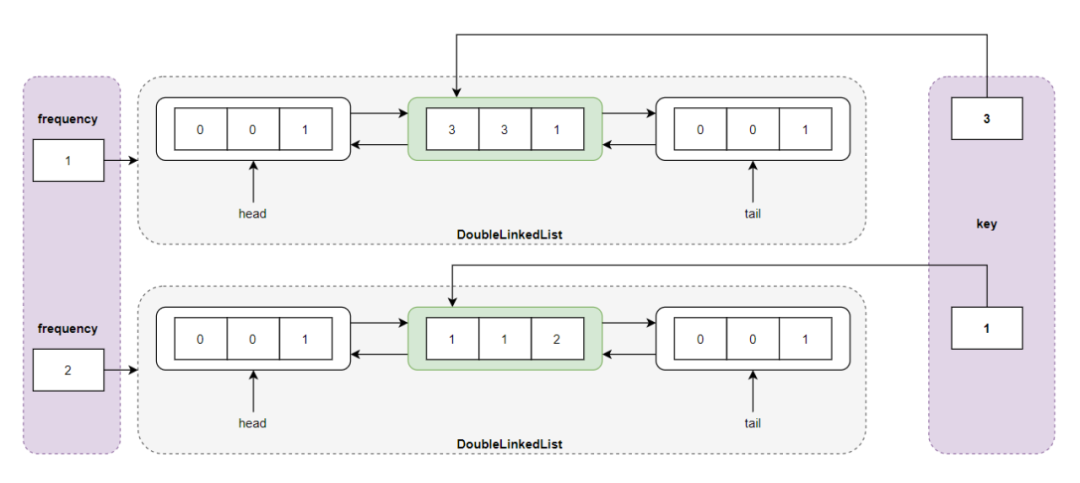
执行 put(3,3) 操作之后的存储结构
之后执行 get(2) ,key = 2 的结点已经不在 LFU 缓存中了,直接返回 -1 。
执行 get(3) ,返回结点 <3,3,1> 的值 value = 3 ,同时更新结点的频度,这个比较特殊,一定要注意奥,从频度 frequency = 1 所对应的双向链表中删除结点 <3,3,1> ,然后将结点的频度更新为 2,即 <3,3,2> ;但是一定要注意此时频度 frequency = 1 所对应的双向链表中没有结点,也就是说此时最小频度 minFrequency 变成了 2 ,然后将结点 <3,3,2> 插入到频度 freqeuncy = 2 所指向的双向链表的头结点中:
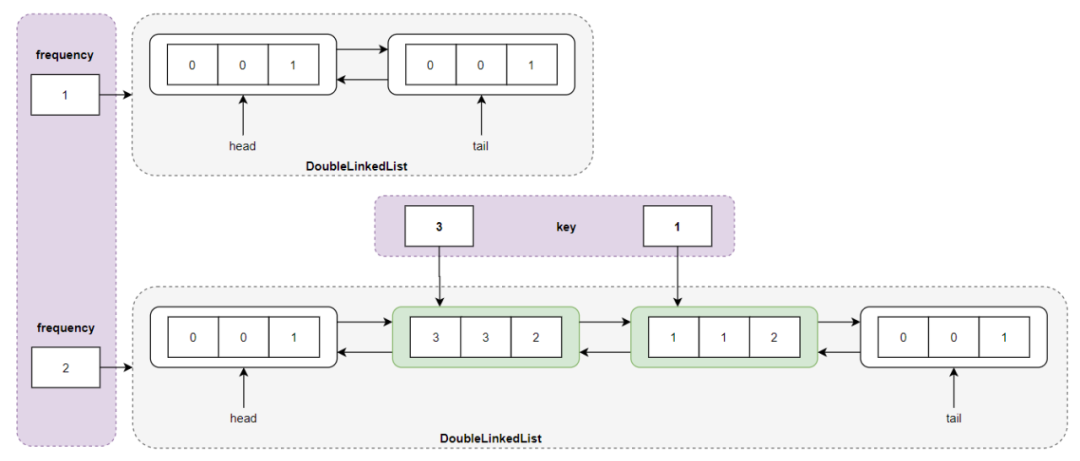
执行 get(3) 操作之后的存储结构
执行 put(4,4) ,发现 LFU Cache 已满,删除频率最小(minFrequency=2)所指向的双向链表的尾结点 <1,1,2> ,然后插入新结点 <4,4,1> ,最小频度变成了 1,即 minFrequency = 1 :
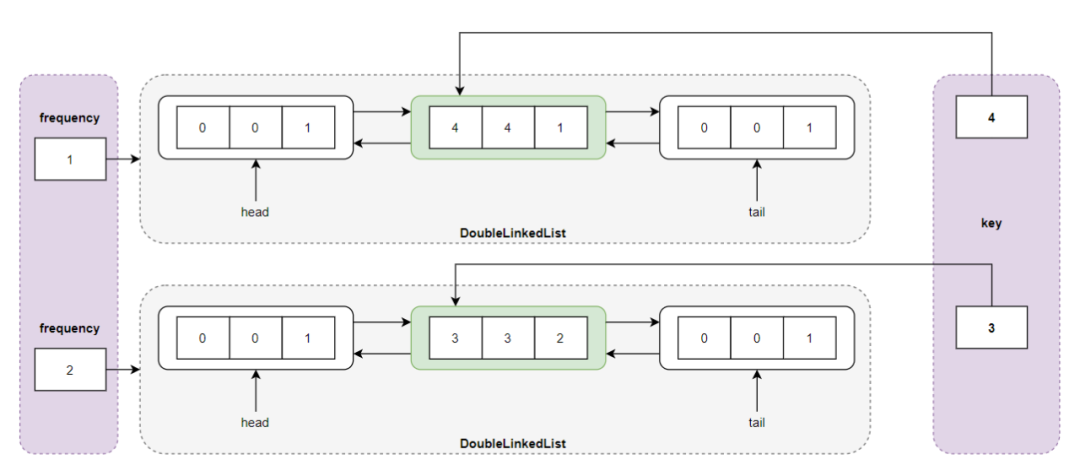
执行 put(4,4) 操作之后的存储结构
执行 get(1) ,返回 -1,因为前一步我们删除了结点 <1,1,2> 。
然后执行 get(3) 操作,返回 3,但是此时需要更新 key = 3 所对应的结点的频度,首先将结点 <3,3,2> 从频度 frequency = 2 所对应的双向链表中删除,并更新结点的频度,将其插入频度 frequency = 3 所对应的双向链表中,注意 frequency = 2 所对应的单链表中没有结点,但这并不影响 LFU Cache 的机制和存储结构,接下来不论是 put() 还是 get() 操作,都会保证我们设计的算法的正确性:
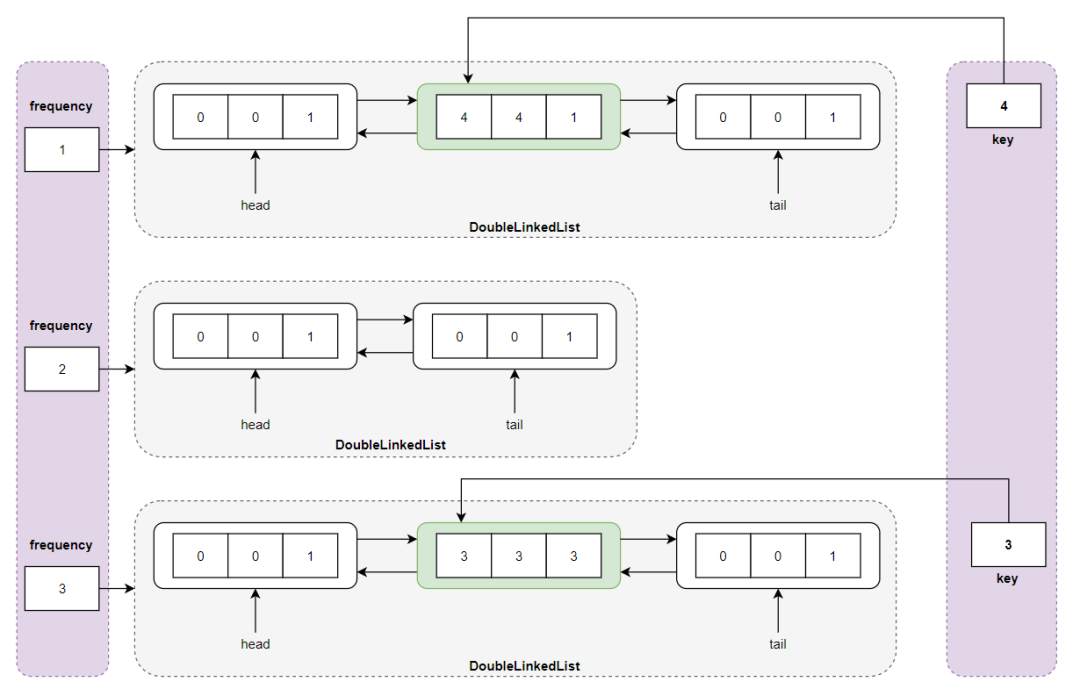
执行 get(3) 操作之后的存储结构
执行 get(4) 操作之后,返回 4 ,更新结点 <4,4,1> ,将 key = 4 所指向的结点 <4,4,1> 从 frequency = 1 所指向的双向链表中删除,然后更新其频度 <4,4,2> ,并将其插入 frequency = 2 所指向的双向链表的头部:
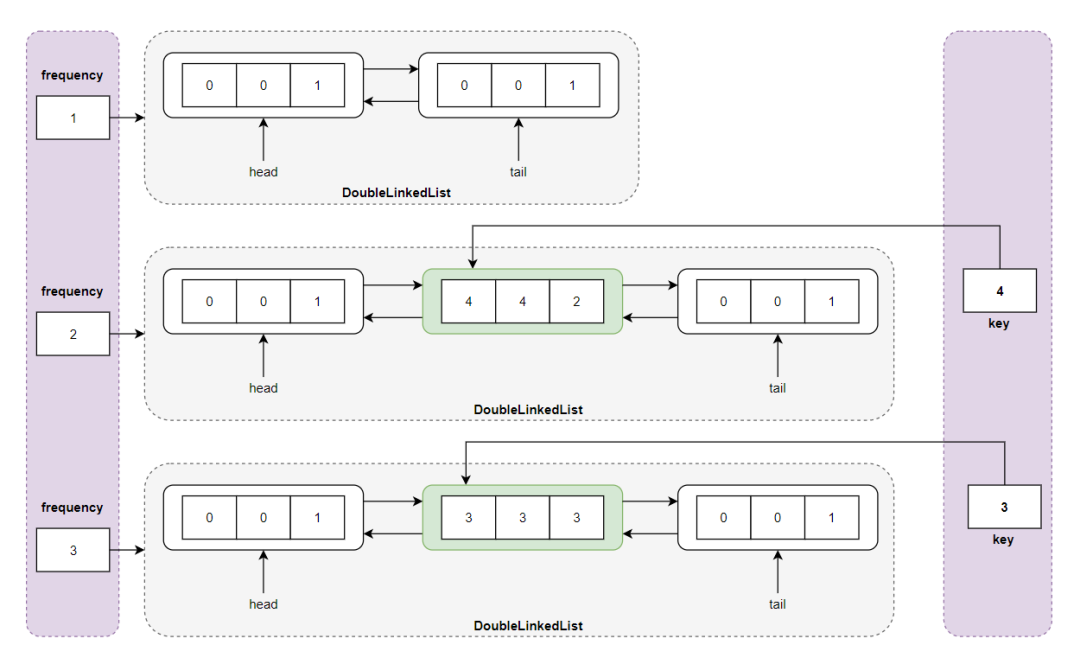
执行 get(4) 操作之后的存储结构
以上就是力扣所提供的示例的执行过程,相信看到这里,你已有所悟!完整的实现代码仅供参考[4]:
import java.util.HashMap;
import java.util.Map;
class LFUCache {
private final int capacity;
private int curSize;
private int minFrequency;
private Map<Integer, LFUNode> cache;
private Map<Integer, DoubleLinkedList> frequencyMap;
/*
* @param capacity: LFU Cache 总容量
* @param curSize: LFU cache 当前容量
* @param minFrequency: 全局最小的频度
* @param cache: 保证 O(1) 的时间访问到结点,key-->LFUNode 的映射
* @param frequencyMap: 保证 O(1) 的时间访问到频率为 freq 的结点所对应的双链表
* */
public LFUCache(int capacity) {
this.capacity = capacity;
this.curSize = 0;
this.minFrequency = 0;
this.cache = new HashMap<>();
this.frequencyMap = new HashMap<>();
}
public int get(int key) {
LFUNode curNode = cache.get(key);
if (curNode == null) {
return -1;
}
updateNode(curNode);
return curNode.val;
}
public void put(int key, int value) {
// 边界条件,检查 LFU capacity
if (capacity == 0) {
return;
}
if (cache.containsKey(key)) {
LFUNode curNode = cache.get(key);
curNode.val = value;
updateNode(curNode);
}
else {
curSize++;
if (curSize > capacity) {
// 获取最小频率所对应的双向链表
DoubleLinkedList minFreqList = frequencyMap.get(minFrequency);
LFUNode deleteNode = minFreqList.removeTail();
cache.remove(deleteNode.key);
curSize--;
}
// 重置最小频率,插入新结点
minFrequency = 1;
LFUNode newNode = new LFUNode(key, value);
// 获取到频率为 1 的双向链表并插入新结点
DoubleLinkedList curList = frequencyMap.getOrDefault(1, new DoubleLinkedList());
curList.addNode(newNode);
frequencyMap.put(1, curList);
cache.put(key, newNode);
}
}
public void updateNode(LFUNode curNode) {
int curFreq = curNode.frequency;
DoubleLinkedList curList = frequencyMap.get(curFreq);
curList.removeNode(curNode);
// 防止删除结点所在的频度最小的双向链表仅包含删除结点一个结点
if (curFreq == minFrequency && curList.listSize == 0) {
minFrequency++;
}
curNode.frequency++;
DoubleLinkedList newList = frequencyMap.getOrDefault(curNode.frequency, new DoubleLinkedList());
newList.addNode(curNode);
frequencyMap.put(curNode.frequency, newList);
}
class LFUNode {
int key;
int val;
int frequency;
LFUNode prev;
LFUNode next;
public LFUNode(int key, int val) {
this.key = key;
this.val = val;
this.frequency = 1;
}
}
class DoubleLinkedList {
int listSize;
LFUNode head;
LFUNode tail;
public DoubleLinkedList() {
this.listSize = 0;
this.head = new LFUNode(0, 0);
this.tail = new LFUNode(0, 0);
head.next = tail;
tail.prev = head;
}
// 表头插入一个新结点
public void addNode(LFUNode curNode) {
LFUNode nextNode = head.next;
curNode.next = nextNode;
curNode.prev = head;
head.next = curNode;
nextNode.prev = curNode;
listSize++;
}
// 删除一个结点
public void removeNode(LFUNode curNode) {
LFUNode prevNode = curNode.prev;
LFUNode nextNode = curNode.next;
prevNode.next = nextNode;
nextNode.prev = prevNode;
listSize--;
}
// 删除尾部结点
public LFUNode removeTail() {
// DO NOT FORGET to check list size
if (listSize > 0) {
LFUNode tailNode = tail.prev;
removeNode(tailNode);
return tailNode;
}
return null;
}
}
}
以上的实现方式仅是为了让大家彻底理解 LFU Cache 机制,所以里面的双向链表,以及 key-->LFUNode 的映射,以及 frequency --> DoubleLinkedList 的映射都是我们自己实现的,事实上 LFUCache 已经在 Apache 基金会的开源项目中存在了,我们一起看一下 Apache[5] 项目中基于 LinkedHashSet 的开源实现。
import java.util.Collection;
import java.util.HashMap;
import java.util.Iterator;
import java.util.LinkedHashSet;
import java.util.Map;
import java.util.Set;
/**
* @author Sergio Bossa
*/
public class LFUCache<Key, Value> implements Map<Key, Value> {
private final Map<Key, CacheNode<Key, Value>> cache; // LFU Node
private final LinkedHashSet[] frequencyList; // freq->DoubleLinkedList的映射一样
private int lowestFrequency; // 全局最小的频度,相当于 minFrequency
private int maxFrequency; // 全局最大的频度
//
private final int maxCacheSize; // 缓存的最大容量 capacity
private final float evictionFactor; // 淘汰因子,用于确定被淘汰元素的数目(百分比)
public LFUCache(int maxCacheSize, float evictionFactor) {
if (evictionFactor <= 0 || evictionFactor >= 1) {
throw new IllegalArgumentException("Eviction factor must be greater than 0 and lesser than or equal to 1");
}
this.cache = new HashMap<Key, CacheNode<Key, Value>>(maxCacheSize);
this.frequencyList = new LinkedHashSet[maxCacheSize];
this.lowestFrequency = 0;
this.maxFrequency = maxCacheSize - 1;
this.maxCacheSize = maxCacheSize;
this.evictionFactor = evictionFactor;
initFrequencyList();
}
public Value put(Key k, Value v) {
Value oldValue = null;
CacheNode<Key, Value> currentNode = cache.get(k);
if (currentNode == null) { // key 不在LFU Cache 中
if (cache.size() == maxCacheSize) {
doEviction(); // 淘汰页面
}
LinkedHashSet<CacheNode<Key, Value>> nodes = frequencyList[0]; // 获取到频度最小的双链表,添加新结点
currentNode = new CacheNode(k, v, 0);
nodes.add(currentNode);
cache.put(k, currentNode);
lowestFrequency = 0;
} else { // key 在 LFU Cache 中,更新结点的值
oldValue = currentNode.v;
currentNode.v = v;
}
return oldValue; // 返回结点的值
}
// 插入多个键值对
public void putAll(Map<? extends Key, ? extends Value> map) {
for (Map.Entry<? extends Key, ? extends Value> me : map.entrySet()) {
put(me.getKey(), me.getValue());
}
}
public Value get(Object k) {
CacheNode<Key, Value> currentNode = cache.get(k); // 获取到当前结点
if (currentNode != null) { // 当前键为 k 的结点存在,更新其频度 frequency
int currentFrequency = currentNode.frequency;
if (currentFrequency < maxFrequency) { // 保证双向链表的数目小于 frequencyList 所能容纳的最大频度
int nextFrequency = currentFrequency + 1;
LinkedHashSet<CacheNode<Key, Value>> currentNodes = frequencyList[currentFrequency];
LinkedHashSet<CacheNode<Key, Value>> newNodes = frequencyList[nextFrequency];
moveToNextFrequency(currentNode, nextFrequency, currentNodes, newNodes);
cache.put((Key) k, currentNode);
if (lowestFrequency == currentFrequency && currentNodes.isEmpty()) {
lowestFrequency = nextFrequency;
}
} else { // 当前结点的访问频度 >= maxFrequency, 则将其添加到最大频度 maxFrequency 所指向双向链表的头部
LinkedHashSet<CacheNode<Key, Value>> nodes = frequencyList[currentFrequency];
nodes.remove(currentNode);
nodes.add(currentNode);
}
return currentNode.v;
} else {
return null;
}
}
// 删除结点
public Value remove(Object k) {
CacheNode<Key, Value> currentNode = cache.remove(k);
if (currentNode != null) {
LinkedHashSet<CacheNode<Key, Value>> nodes = frequencyList[currentNode.frequency];
nodes.remove(currentNode);
if (lowestFrequency == currentNode.frequency) {
findNextLowestFrequency();
}
return currentNode.v;
} else {
return null;
}
}
// 返回当前键为 k 的结点的访问次数
public int frequencyOf(Key k) {
CacheNode<Key, Value> node = cache.get(k);
if (node != null) {
return node.frequency + 1;
} else {
return 0;
}
}
// 清空 LFU 缓存
public void clear() {
for (int i = 0; i <= maxFrequency; i++) {
frequencyList[i].clear();
}
cache.clear();
lowestFrequency = 0;
}
public Set<Key> keySet() {
return this.cache.keySet();
}
public Collection<Value> values() {
return null; //To change body of implemented methods use File | Settings | File Templates.
}
public Set<Entry<Key, Value>> entrySet() {
return null; //To change body of implemented methods use File | Settings | File Templates.
}
public int size() {
return cache.size();
}
public boolean isEmpty() {
return this.cache.isEmpty();
}
public boolean containsKey(Object o) {
return this.cache.containsKey(o);
}
public boolean containsValue(Object o) {
return false; //To change body of implemented methods use File | Settings | File Templates.
}
// 初始化 maxFrequency + 1 个双向链表一样
private void initFrequencyList() {
for (int i = 0; i <= maxFrequency; i++) {
frequencyList[i] = new LinkedHashSet<CacheNode<Key, Value>>();
}
}
// 淘汰页面
private void doEviction() {
int currentlyDeleted = 0;
float target = maxCacheSize * evictionFactor; // 缓存的最大容量乘以淘汰因子
while (currentlyDeleted < target) {
LinkedHashSet<CacheNode<Key, Value>> nodes = frequencyList[lowestFrequency];
if (nodes.isEmpty()) {
throw new IllegalStateException("Lowest frequency constraint violated!");
} else {
Iterator<CacheNode<Key, Value>> it = nodes.iterator();
while (it.hasNext() && currentlyDeleted++ < target) {
CacheNode<Key, Value> node = it.next();
it.remove();
cache.remove(node.k);
}
if (!it.hasNext()) {
findNextLowestFrequency();
}
}
}
}
private void moveToNextFrequency(CacheNode<Key, Value> currentNode, int nextFrequency, LinkedHashSet<CacheNode<Key, Value>> currentNodes, LinkedHashSet<CacheNode<Key, Value>> newNodes) {
currentNodes.remove(currentNode);
newNodes.add(currentNode);
currentNode.frequency = nextFrequency;
}
private void findNextLowestFrequency() {
while (lowestFrequency <= maxFrequency && frequencyList[lowestFrequency].isEmpty()) {
lowestFrequency++;
}
if (lowestFrequency > maxFrequency) {
lowestFrequency = 0;
}
}
/*
* @desc LFU Cache Node
* @param k key
* @param v value
* @param frequency 频率
*/
private static class CacheNode<Key, Value> {
public final Key k;
public Value v;
public int frequency;
public CacheNode(Key k, Value v, int frequency) {
this.k = k;
this.v = v;
this.frequency = frequency;
}
}
}
总结
看似最耳熟能详的概念,往往背后蕴含的丰富的数据结构知识,LRU 与 LFU ,不论哪一个我们都在操作系统的课程中学习过,但当我们第一次碰到这样的题目,一定要从容处理。
一道好的面试题,一定既可以考察面试者的基础知识是否稳固,同时也会考察你运用已掌握的知识解决新问题的能力。链表、哈希单独拎出来,可能每一个人都很清楚,而两者结合起来却能有这么神奇的反应,妙哉妙哉~~
我坚信,这样的题目会越来越多的出现在大厂的面试中,点再看,进大厂
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!