
硬核干货 | 数据异常的本质和价值详解
数据异常在数据库领域中较为常见,但目前业界内并没有关于数据异常的通用定义。腾讯金融云TDSQL首席架构师李海翔老师携手团队对数据异常的本质和价值进行研究,该研究成果目前已经发表在《软件学报》上,论文题目为《数据库管理系统中数据异常体系化定义与分类》。
该文评审专家认为:本文系统地研究了数据库的数据异常及其对应的隔离级别,通过形式化的定义,总结和规范了数据异常的类型。基于形式化的解释,解释了不同数据异常之间的本质区别。同时,本文还通过偏序关系对数据异常进行分类,并阐述了数据异常与隔离级别之间的关系。另外,本文深入总结了前人在数据异常领域的研究工作,文献充实。文章具有极高的学术水平,作者分享了其在事务并发控制中数据异常和隔离级别上的深刻认知,另外作者也提供相应的开源工具用来检测数据异常,是一篇对事务并发控制方向非常有影响力的论文。
本次分享就是基于该篇论文的主要内容,以下是分享实录:
数据异常在数据库中很常见,但数据异常的基本问题,其实并没有得到很好的解决。比如在整个事务处理领域究竟有多少种数据异常?最开始SQL标准定义了4种数据异常,1995年Jim Gray等人在前者的基础上又提出了4种新的数据异常。在阅读了数百篇Paper后,我们也发现从1995年到2017年之间,不断有人在提出新的数据异常,加起来有将近20种。

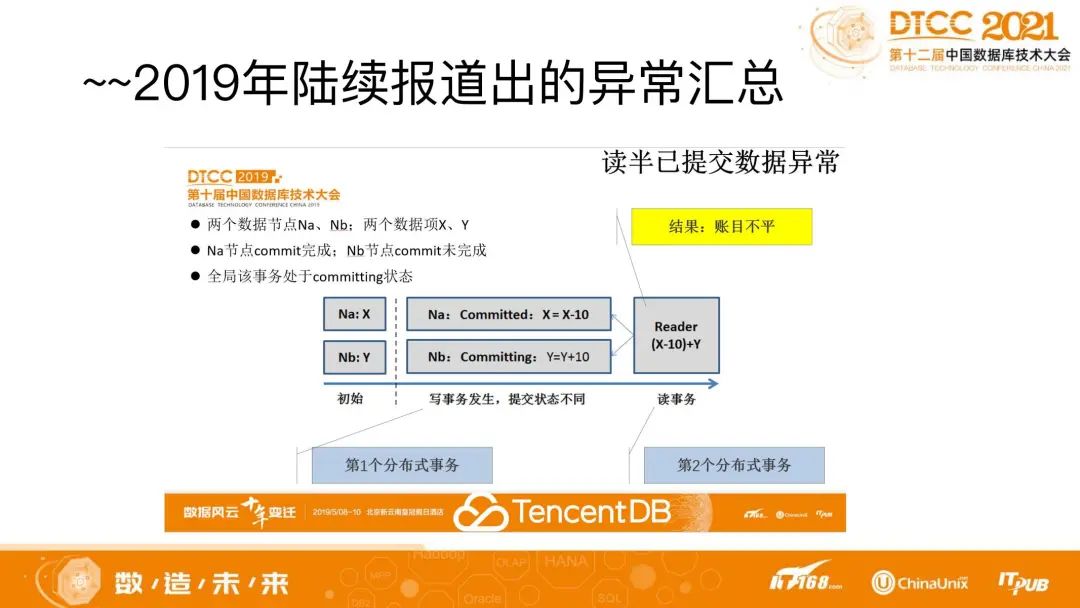
近几年也陆续有人提出新的数据异常,包括2019年TDSQL也在分布式系统下报告了新的异常。比如下图中提到的读半已提交数据异常。
在一个分布式系统中,有两个数据项,跨两个物理节点,一个在A节点上,一个在B节点上。有一个分布式事务,这个分布式事务是一个转账事务,即写X和Y,要给X减去10元,要给Y加10元。这时该事务是可以正常执行的。但对于另一个只读事务来说,当它要跨两个物理节点去读数据时,它读到的是数据旧的状态,在另一个节点又读到了新的状态,一个新状态和一个旧状态是在一个事务之前的状态和之后的状态,这两个状态跨越了一个事务的提交的一致性点,出现账户总额不匹配的情况,发生了数据不一致性现象(一致的情况是X+Y或者(X-10)+(Y+10),总和一定是X+Y),这就是我们所说的读半已提交数据异常。
除了上述例子外,还有一些其他的数据异常,例如读偏序、写偏序等。我们会发现,传统的教科书,在提到数据异常的时候,总是一个一个的说脏读、脏写、写偏序等数据异常分别是什么样子。这些都是针对每一个具体的数据异常,去加以形式化的描述,并没有一个关于数据异常的通用定义(即不能从数据异常整体上给出一个清晰定义)。那究竟什么是数据异常?这么多的数据异常之间究竟有什么关系?该如何用一个统一的方式或框架来理解所有的数据异常?这些都是没有解决的问题。在事务处理领域,连“数据异常究竟有多少个”这样的基本问题都不知道,不能回答,可见该领域还有很大空间。
为了理解数据异常,我们去探索了数据异常、变量和并发事务之间的关系。在这个问题的驱动下,我们把数据异常、变量、并发事务这些相关因素统一在一个模型下,再对数据异常加以形式化的定义,去找出每类数据异常的特征。这时我们发现数据异常其实有无穷多个。它不只是SQL标准所定义的4个数据异常,也不只是1995年Jim Gray等人定义的8种数据异常,其实,数据异常有无穷多个。

在数据异常有无穷多个的情况下,我们要如何去理解数据异常?这就要求必须对数据异常进行分类。我们用环形式化表达数据异常,对数据异常进行了特征研究。因为环的边的种类是固定的,可以根据边的种类可以对数据异常进行分类。分好类后,我们又进一步研究了非谓词类的数据异常,比如脏读、脏写、不可重复读和幻读这样的谓词类数据异常,看它们之间有什么样的关系。下图蓝色字体是TDSQL新报告的数据异常。

在理解了数据异常后,我们又去思考数据异常和一致性之间的关系。目前的事务处理领域的教科书,对一致性也没有一个统一且完整的定义。
目前有两种典型的说法:第一种,只提到“不违反完整性因素就叫符合一致性”。Jim Gray曾经提出,从一个一致性状态变迁到另一个合法的一致性状态,这就叫一致性。但这句话理解起来很抽象,存在认知上的困难。
第二种,源自Jim Gray的一篇Paper,作者们对一致性做过另一种形式的定义。该定义类似隔离级别,把一致性分成几个级别,称为degree0、degree1、degree2、degree3,并对每一种degree用具体规则来进行限定,具体的规则则是屏蔽了一定的数据异常。换句话说,Jim Gray其实给出了一个定义,即把一致性和数据异常联系在一起,但他并没有把所有的数据异常和一致性的定义联系在一起(因为事务处理技术的发展历史上,从没有完整地定义过所有的数据异常,TDSQL系统化定义所有数据异常,是该领域内首个对数据异常体系化定义的工作)。
我们又进一步去探索了数据一致性和数据异常之间的关系,再根据之前研究的结果对一致性下定义。这个定义描述起来很简单,即一致性等于无数据异常。只要没有数据异常那就符合数据一致性,反之,不一致就等于有数据异常。我们用数据异常去尝试定义了数据的一致性。

在定义完数据一致性后,我们又做了一个新的探索,即研究数据异常和隔离级别之间的关系。当我们在数据异常分类的基础上尝试去重新定义隔离级别时,我们发现隔离级别的定义非常灵活,它可以定义出不同级别或者不同粒度的一致性。
具体地说,我们基于数据异常这一体系,系统地提出了数据异常理论,再基于这样形象化的定义尝试去定义隔离级别。那怎么去定义隔离级别呢?因为掌握了全部数据异常,对数据异常的整体有了清晰认知,定义隔离级别就变为一项灵活的工作,可以是粗粒度的隔离级别的定义,也可以是细粒度的隔离级别的定义。如果很细粒度地去划分,我们可以分成多个层次,去定义成不同粒度的隔离级别,用以表达不同粒度的隔离级别和数据异常之间的本质差异或本质联系。之所以能这样做,是因为我们对于隔离级别,有了新的认知:隔离级别是数据异常的一种分类方法。
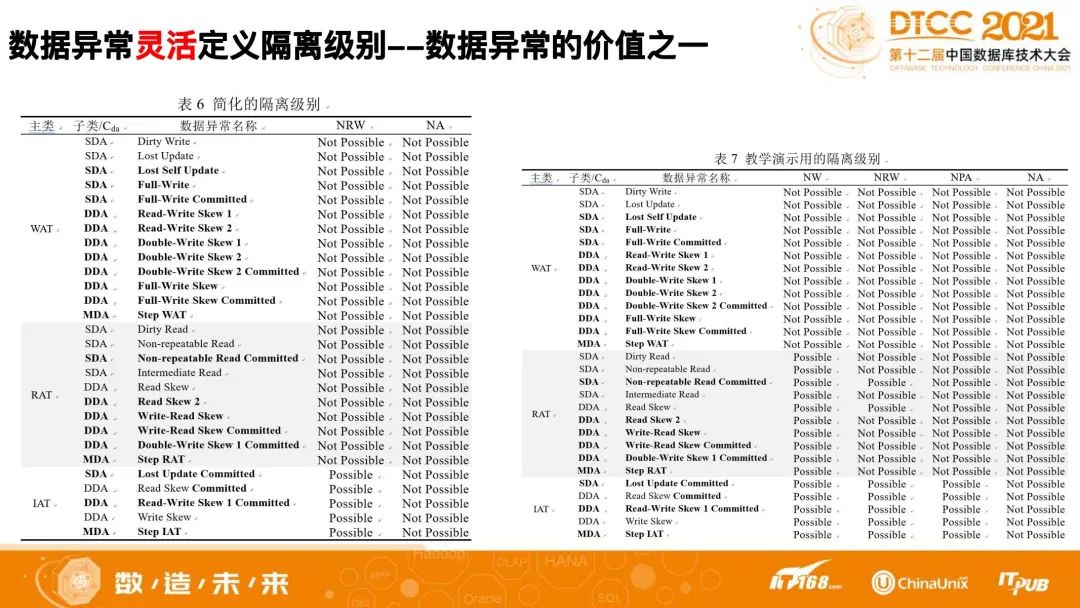
在灵活定义隔离级别后,对工程系统而言,就有了很大的帮助。如果用很复杂的隔离级别的定义去实现并发访问控制,其实是比较难、比较复杂、容易出错且低效率的。因此我们定义了一个简化的隔离级别。简化级别可以用于工程实际系统当中,用一些规则就可以屏蔽掉很多数据异常,进而实现较好的性能。另外的一种隔离级别定义方式,较为细致,可以用于教学演示,演示数据异常之间的细腻差异,以帮助我们充分认知数据异常。
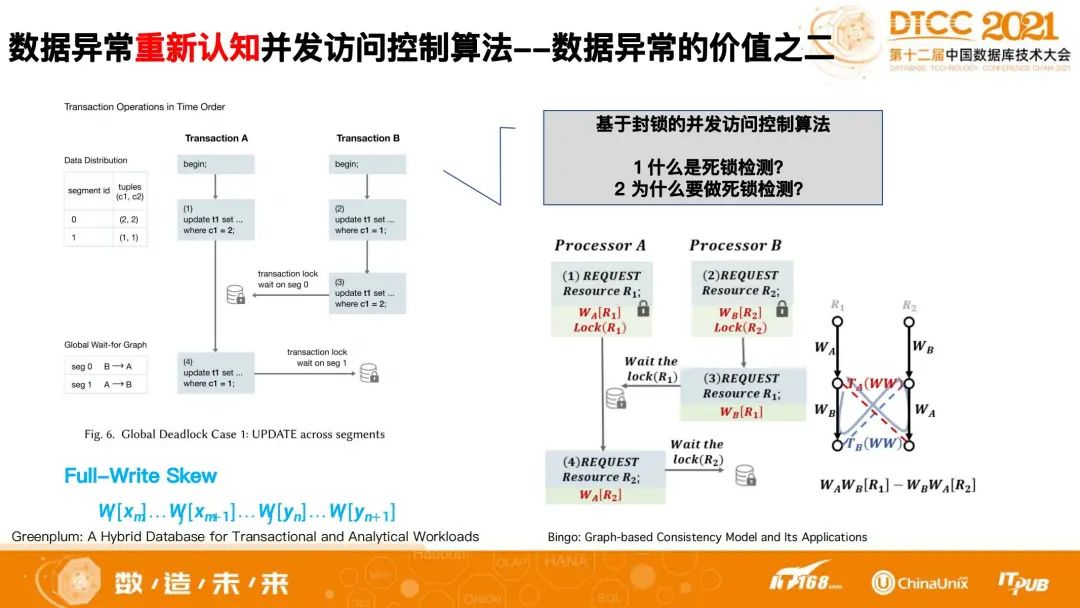
百尺竿头更进一步。TDSQL没有止步于系统地定义数据异常,除了把技术扩展到隔离级别外,我们更进一步地把数据异常体系化工作扩展到了并发访问控制算法。以死锁为例,死锁是并发编程中常出现的问题,但死锁的本质是什么?Greenplum在2021 Sigmod 上发表了一篇paper,该文提及了两个分布式死锁的例子。下图中的这种死锁,正是我们前述发现并定义的一种新的数据异常,称为“Full-write Skew”异常。换句话说,死锁就是一种数据异常。死锁检测算法就是数据异常的环检测算法。这是我们研究成果价值另一方面的体现。
﹀
﹀
﹀

金融级数据库新坐标:腾讯云TDSQL发布全自研新敏态引擎

多类型数据库统一管理,腾讯云数据库DBhouse工具重磅发布

TDSQL首次登上腾讯财报!金融机构核心系统落地实现规模化复制
↓↓点击阅读原文,了解更多优惠