
Hudi 实践 | ByteLake:字节跳动基于 Apache Hudi 的实时数据湖平台


一篇关于字节跳动基于 Apache Hudi 的实时数据湖平台 ByteLake 的分享。

本篇内容包含四个部分,首先介绍一下 Hudi,其次介绍字节的实时数据湖平台 ByteLake 的应用场景;然后针对应用场景,字节做的优化和新特性;最后介绍未来规划。

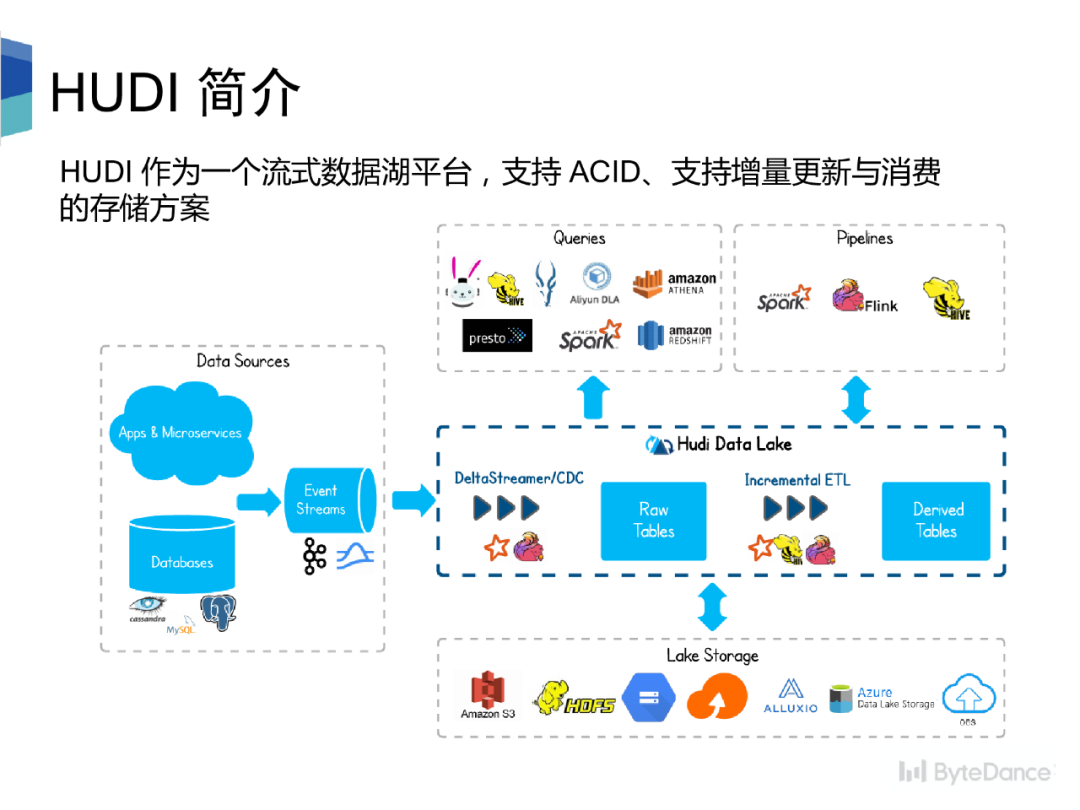
Hudi 是一个流式数据湖平台,提供 ACID 功能,支持实时消费增量数据、离线批量更新数据,并且可以通过 Spark、Flink、Presto 等计算引擎进行查询。
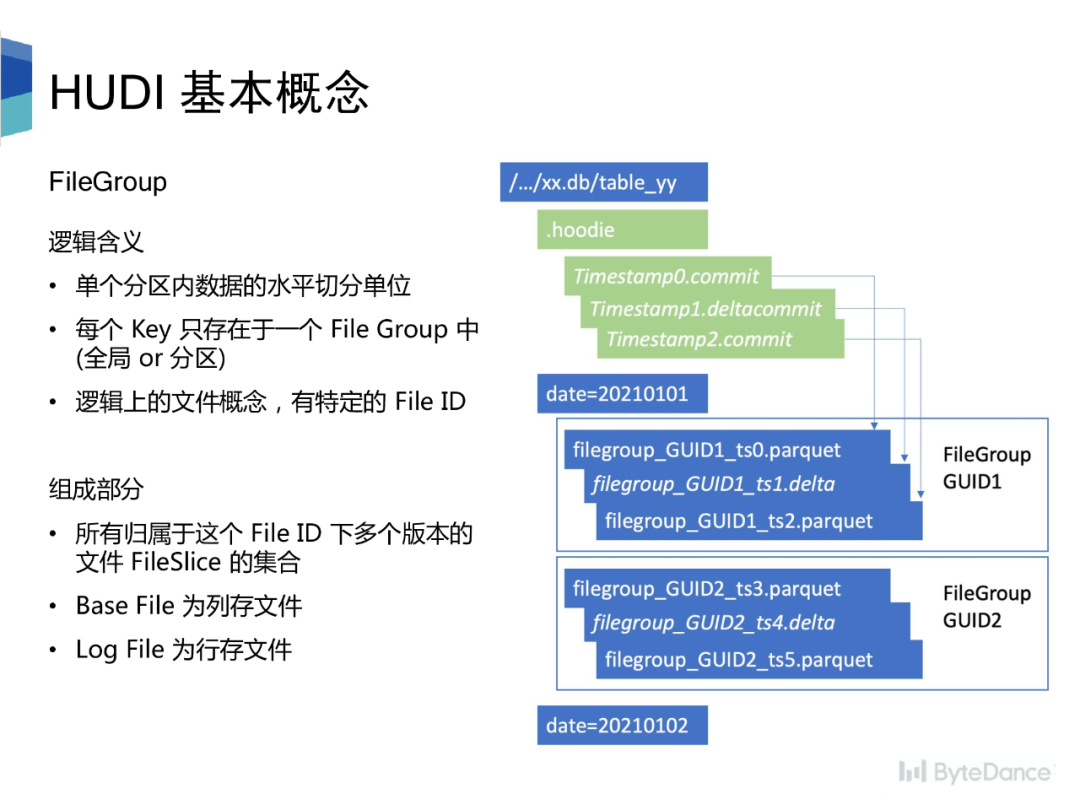
Hudi 表由 timeline 和 file group两大项构成。Timeline 由一个个 commit 构成,一次写入过程对应时间线中的一个 commit,记录本次写入修改的文件。
相较于传统数仓,Hudi 要求每条记录必须有唯一的主键,并且同分区内,相同主键只存在在一个 file group中。底层存储由多个 file group 构成,有其特定的 file ID。File group 内的文件分为 base file 和 log file, log file 记录对 base file 的修改,通过 compaction 合并成新的 base file,多个版本的 base file 会同时存在。

Hudi 表分为 COW 和 MOR两种类型,
•COW 表适用于离线批量更新场景,对于更新数据,会先读取旧的 base file,然后合并更新数据,生成新的 base file。•MOR 表适用于实时高频更新场景,更新数据会直接写入 log file 中,读时再进行合并。为了减少读放大的问题,会定期合并 log file 到 base file 中。

对于更新数据,Hudi 通过索引快速定位数据所属的 file group。目前 Hudi 已支持 Bloom Filter Index、Hbase index 以及 Bucket Index。其中 Bucket Index 尚未合并到主分支。

ByteLake 是字节跳动基于 Hudi 的实时数据湖平台,通过秒级数据可见支持实时数仓。ByteLake除了提供 Hudi 社区的所有功能外,还支持下述第三部分介绍的特性。

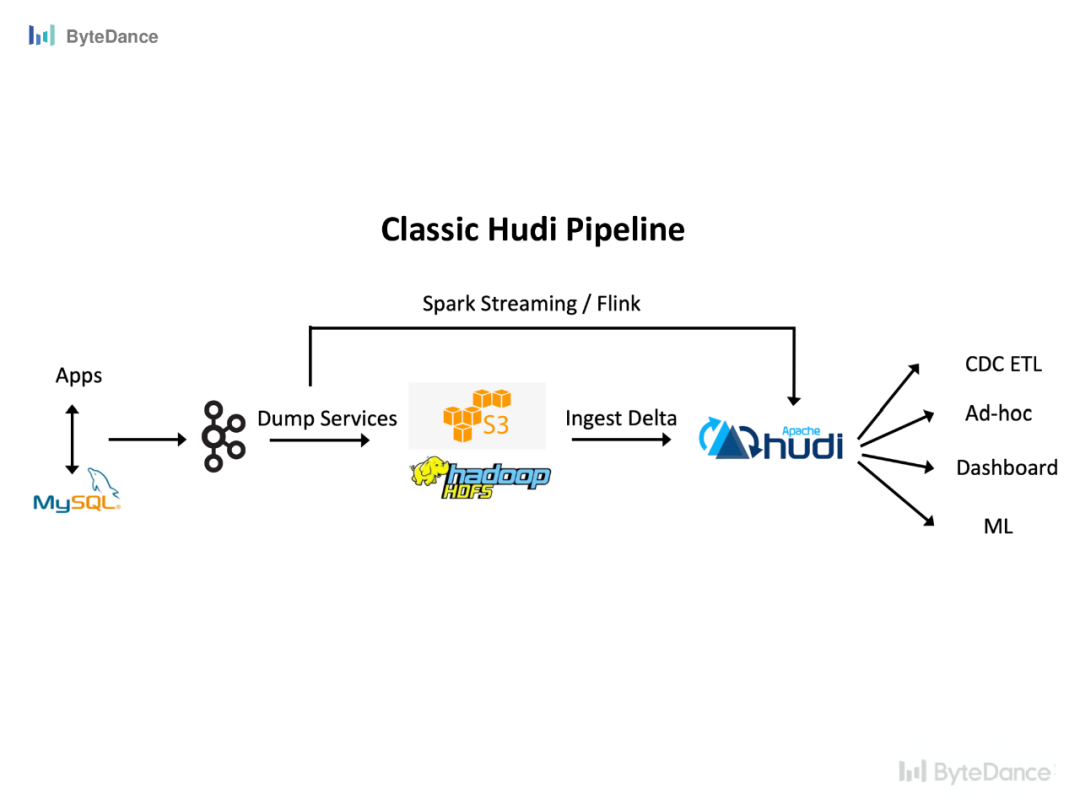
一个典型的 pipeline 是MySQL 侧的 binlog 生产到 Kafka。
•实时场景直接通过 Spark Streaming 或 Flink 消费这部分更新数据,写入数据湖,供下游业务使用。•批量场景会先将 binlog 通过 dump service 存储到 HDFS上,再按照小时/天级粒度更新到数据湖中。
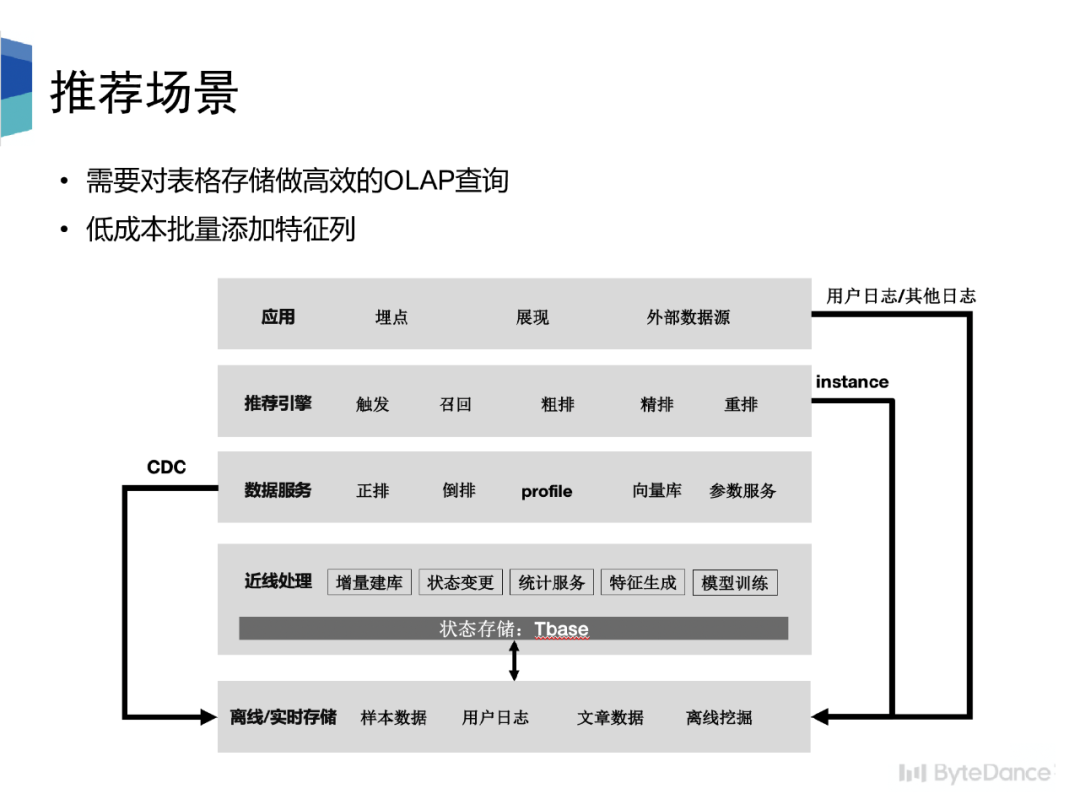

在字节的推荐场景中,为服务离线对数据分析挖掘需求,需要将数据从类 Hbase的存储导出到离线存储中,并且可以提供高效的 OLAP 访问。因此我们基于数据湖构建BigTable 的 CDC。
此外,在特征工程和模型训练场景中,需要将推荐系统 Serving 时获得的数据和端上埋点数据这两类实时数据流通过主键合并到一起,作为机器学习样本。因此我们希望可以借助数据湖的能力,低成本的批量添加特征列。
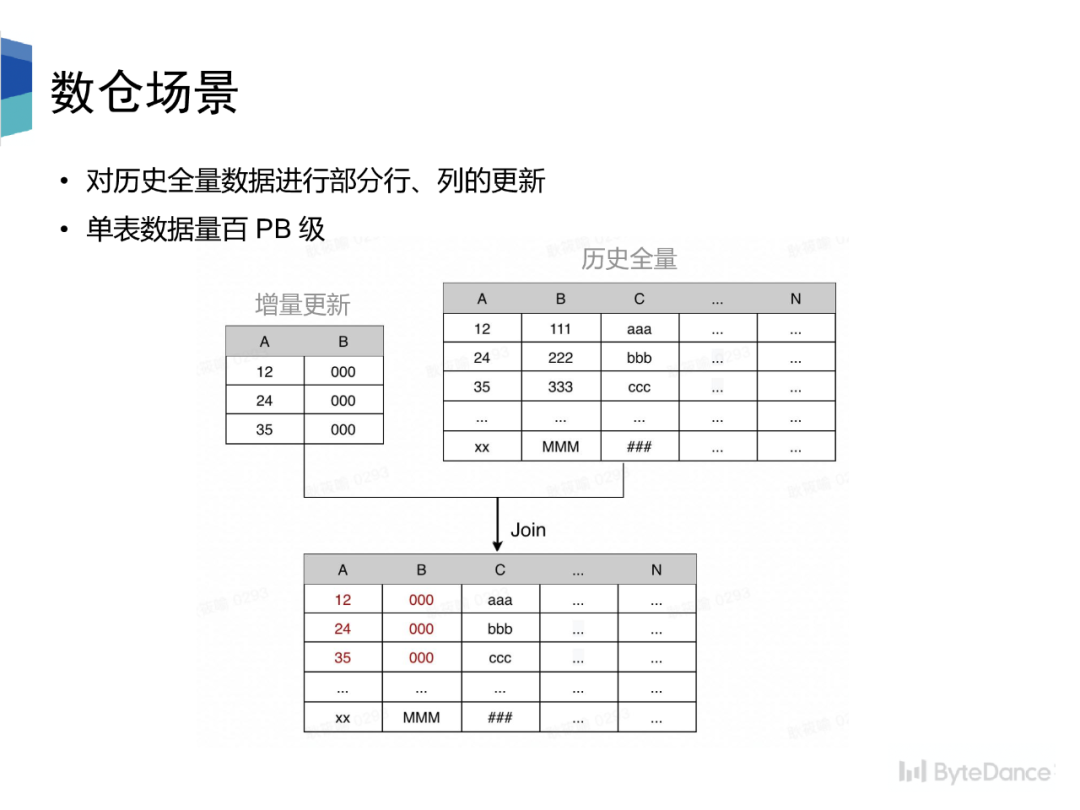
数仓 backfill 场景中,需要对历史全量数据进行部分行、列的更新,在 Hive 模式下,需要将增量数据和历史全量进行 join,重新生成全量数据。其中,部分表的存量数据到达百 PB 级别。我们通过数据湖极大的减少了计算资源消耗,提升了端到端的性能。
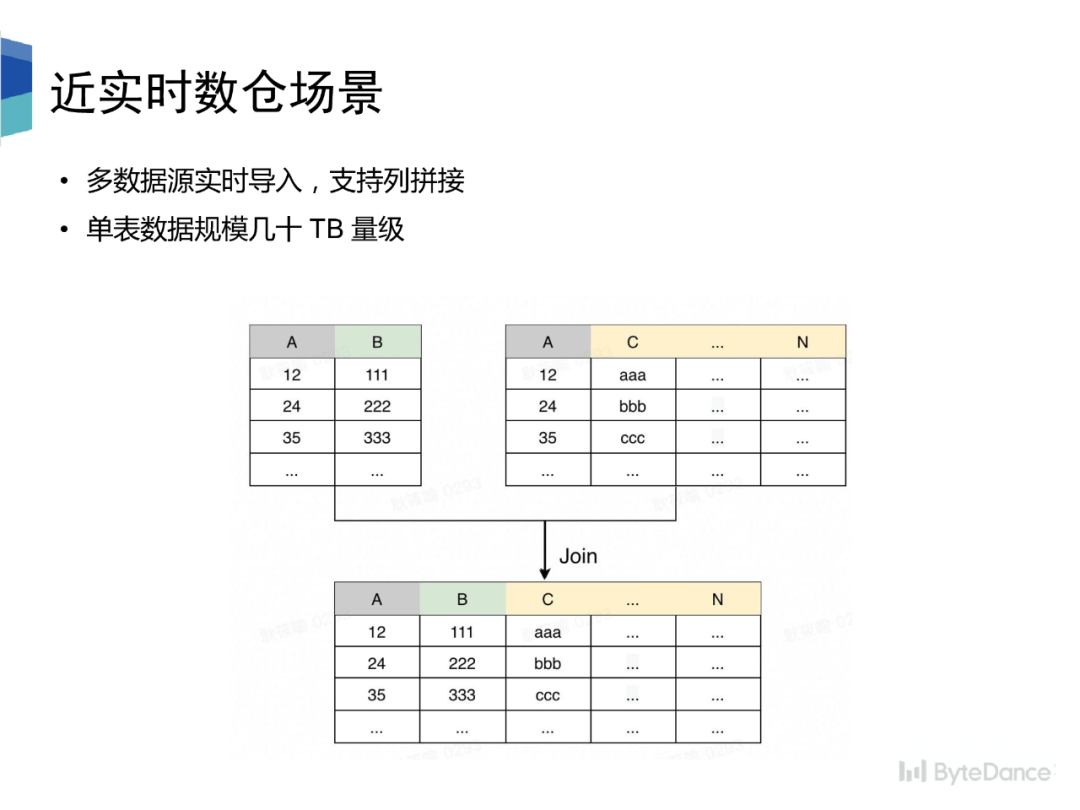
数仓场景中,对于一张底层分析表,往往是通过多个数据源的数据组合拼接而成,每个数据源都包含相同的主键列,和其他不同的属性列。在传统数仓场景中,需要先将每个数据源数据 dump 成 Hive 表,然后再将多张 Hive 表按主键 join 后生成最终的完整 schema 的大表,延迟可到达天级别。我们通过数据湖使实时成为可能,并且提供列拼接能力,使下游数据分析性能大幅提升。

接下来介绍第三部分,针对上述场景,字节做的优化与新特性。
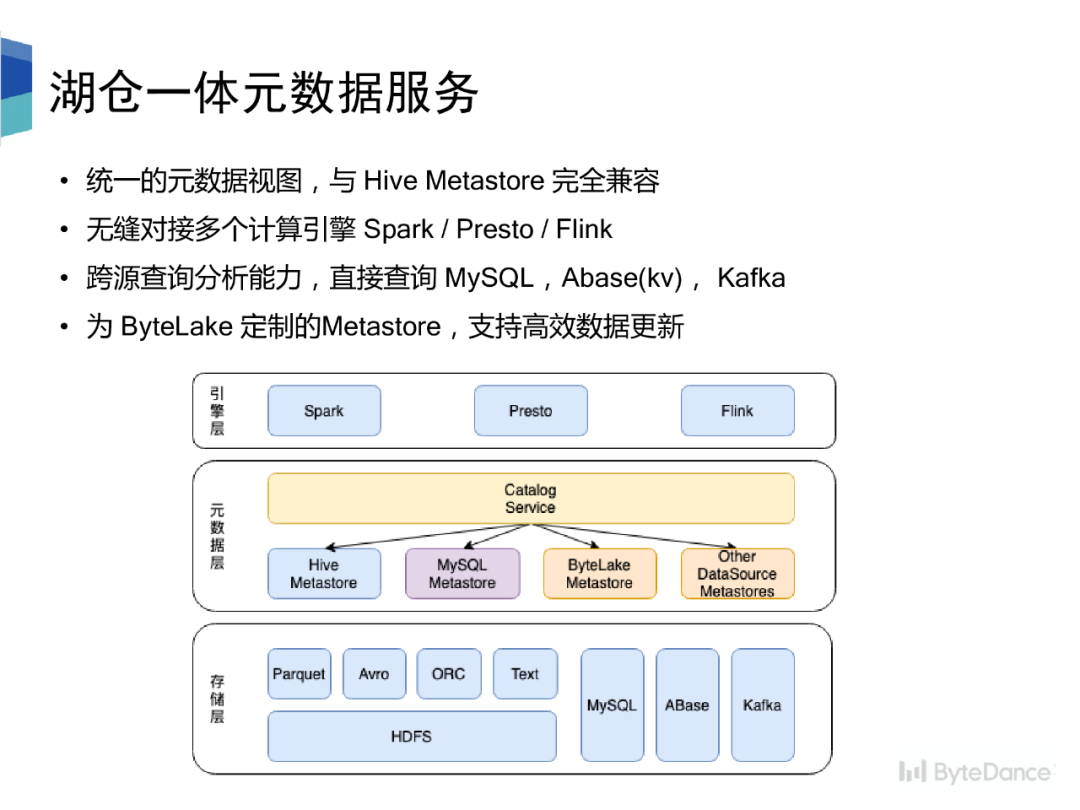
Hive Metastore 是元数据的事实标准,但是基于目录的元数据管理方式太粗,没有办法满足数据湖以 commit 的形式管理元数据的需求。我们提出了适用于数据湖场景下的元数据管理系统 ByteLake Metastore,并基于此设计了湖仓统一的元数据管理系统。
整个架构分为三部分引擎层、元数据层、存储层。元数据层对外提供统一的元数据视图,与 HMS 完全兼容,可无缝对接多个计算引擎。元数据层的 Catalog Service 接收来自引擎层的访问请求,按规则路由到不同的 Metastore 上。元数据层通过 Catalog Service 屏蔽底层多 Metastore 的异构性。
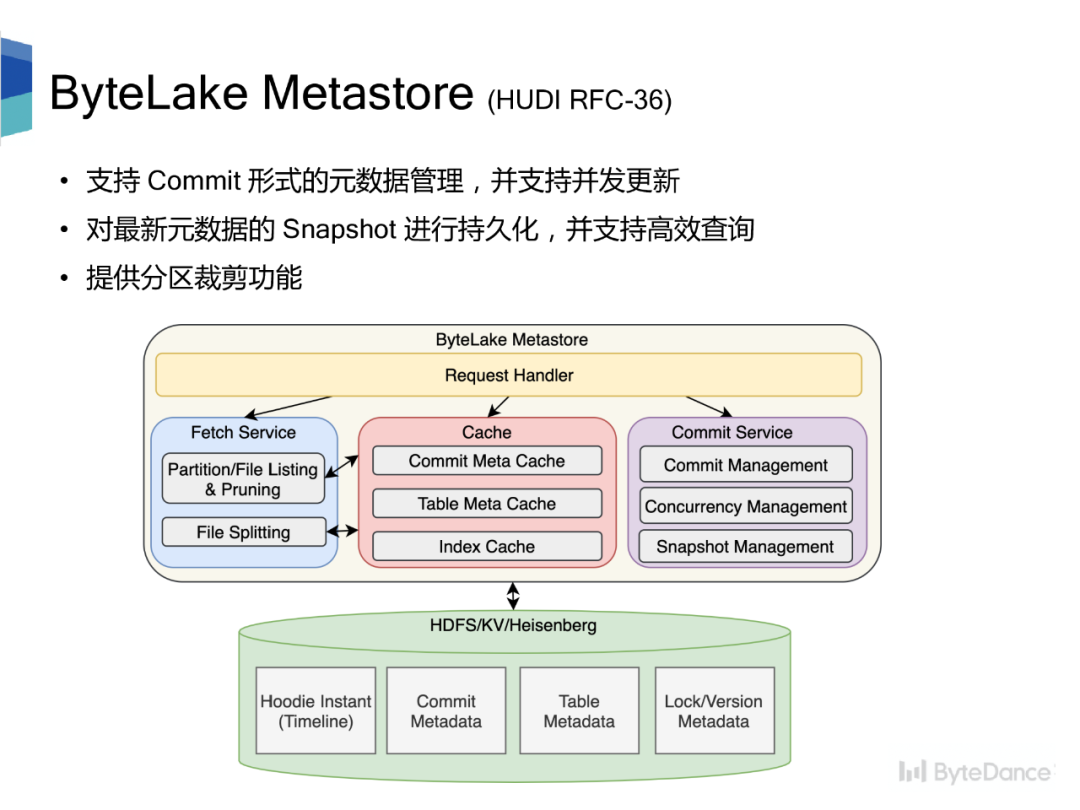
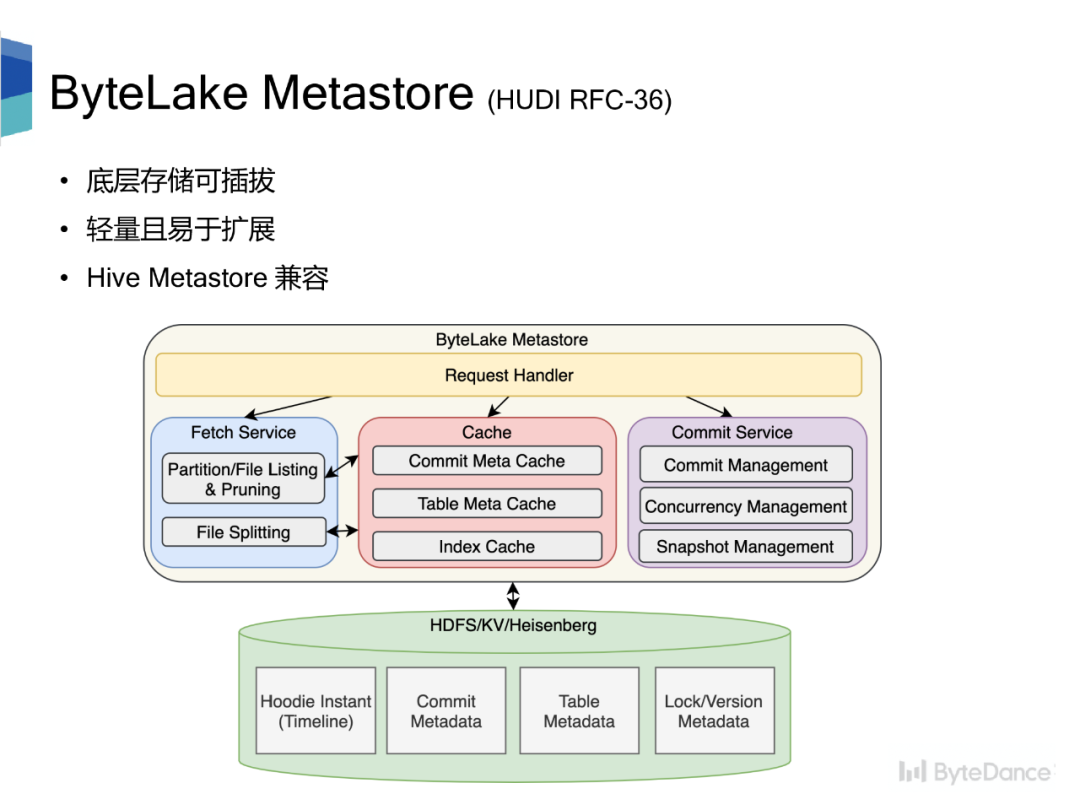
ByteLake Metastore 作为数据湖元数据管理系统,支持 commit 形式的元数据管理,基于乐观锁和 CAS 支持并发更新;持久化元数据的 Snapshot,通过缓存常被访问的元数据、索引信息,提供高效查询;提供分区裁剪功能。整体设计
•底层存储可插拔,不依赖某个特定的存储系统,可以是 HDFS、KV、MySQL•轻量且易于扩展,服务无状态,支持水平扩展;存储可通过拆库/表的方式纵向扩展•与 Hive Metastore 兼容
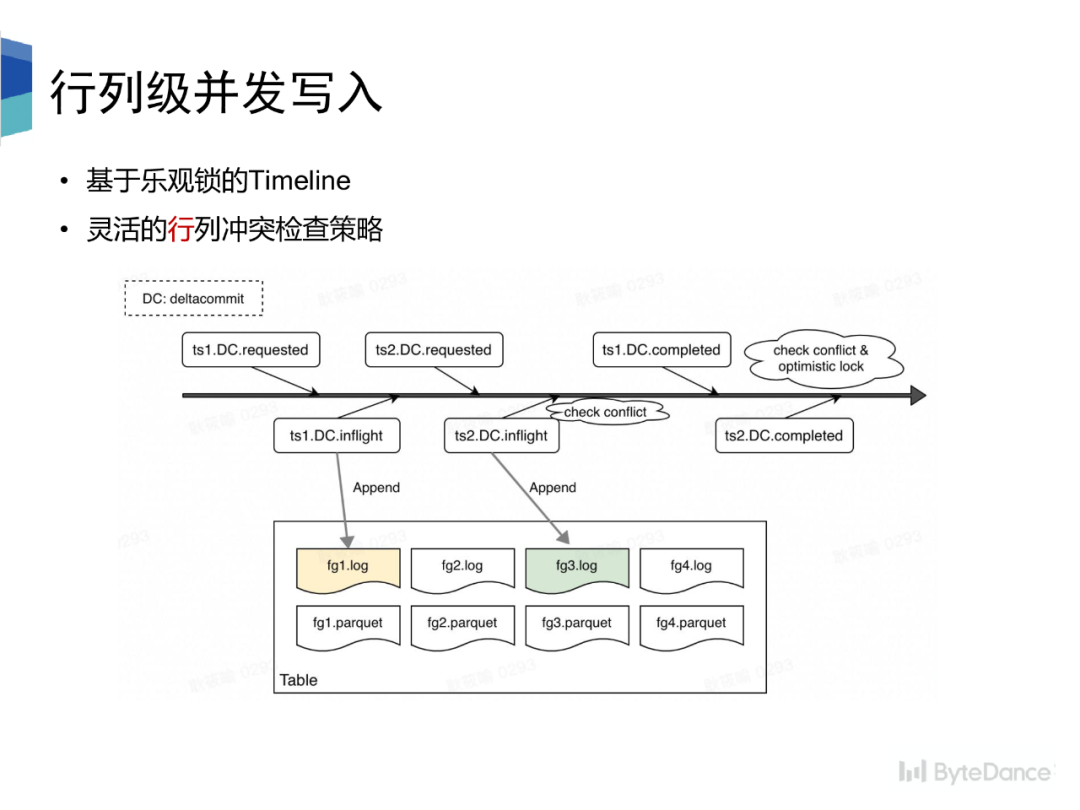
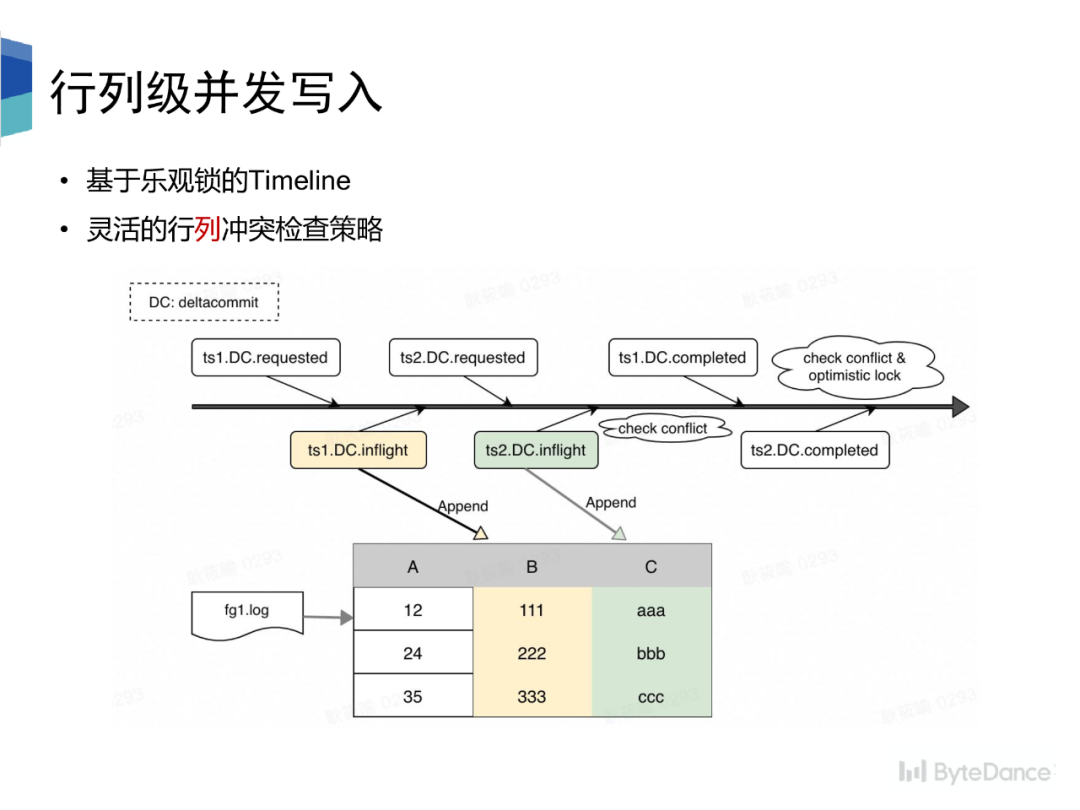
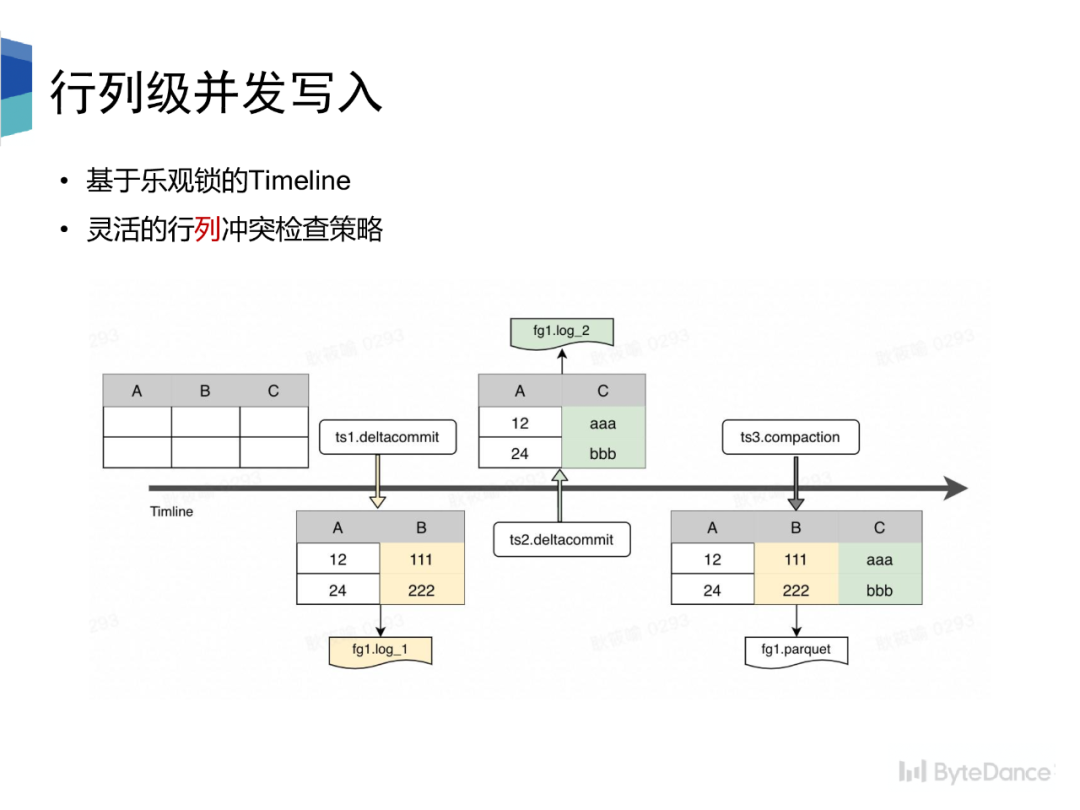
我们基于ByteLake Metastore和乐观锁的假设,实现了并发写入,并且支持灵活的行列冲突检查策略。冲突检查会在 instant 状态变换的两个节点进行,一个是 requested 转 inflight 状态,一个是 inflight 转 completed 状态。其中,后者状态变换时,会进行加锁操作,以实现版本隔离。
冲突检查即是对 instant 创建到状态变化的过程中其他已经完成/正在执行的 instant 之间的进行冲突检查,检查策略分为行列两种,
•行级别的冲突检查即是不能同时有两个 instant 往同一个 file group 写。•列级别的冲突检查即是可以有两个 instant 往同一个 file group 写,但是两个 instant 写入的schema 不可以存在交集。•每个 instant 只写入 schema 中的部分列,log 文件中的数据只包含 schema 中的部分•Compaction 按主键拼接不同列下的数据,Parquet 文件中存储的数据拥有完整的 schema
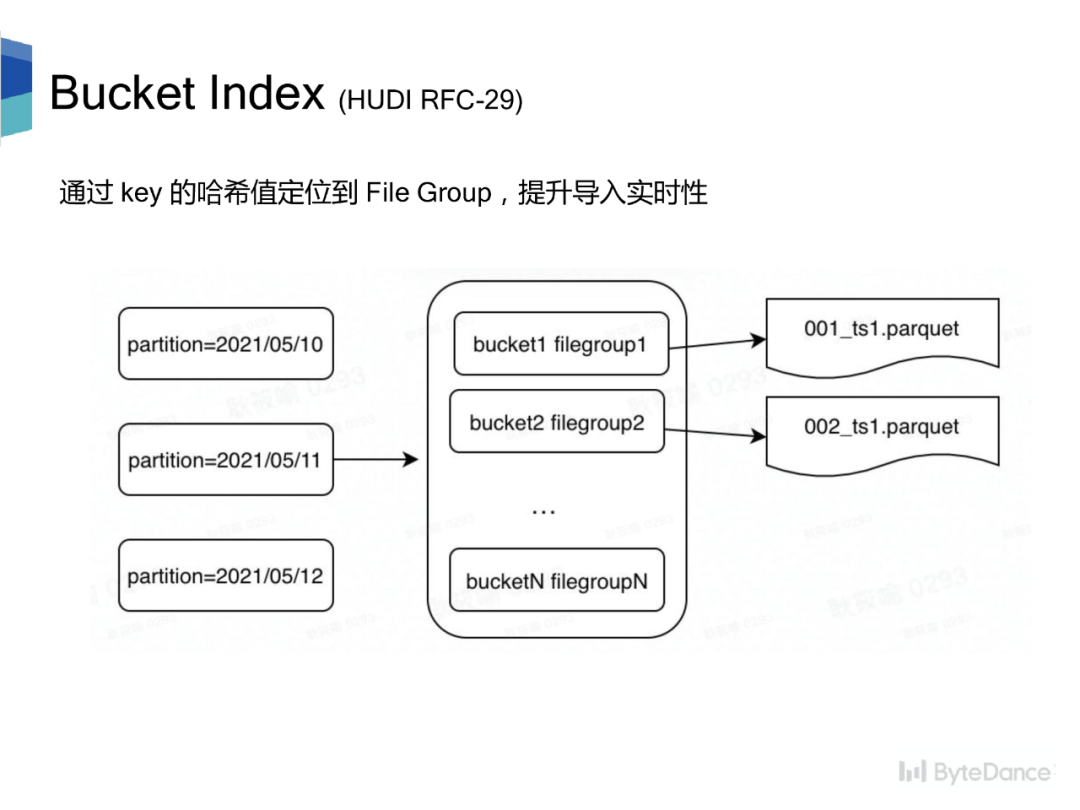
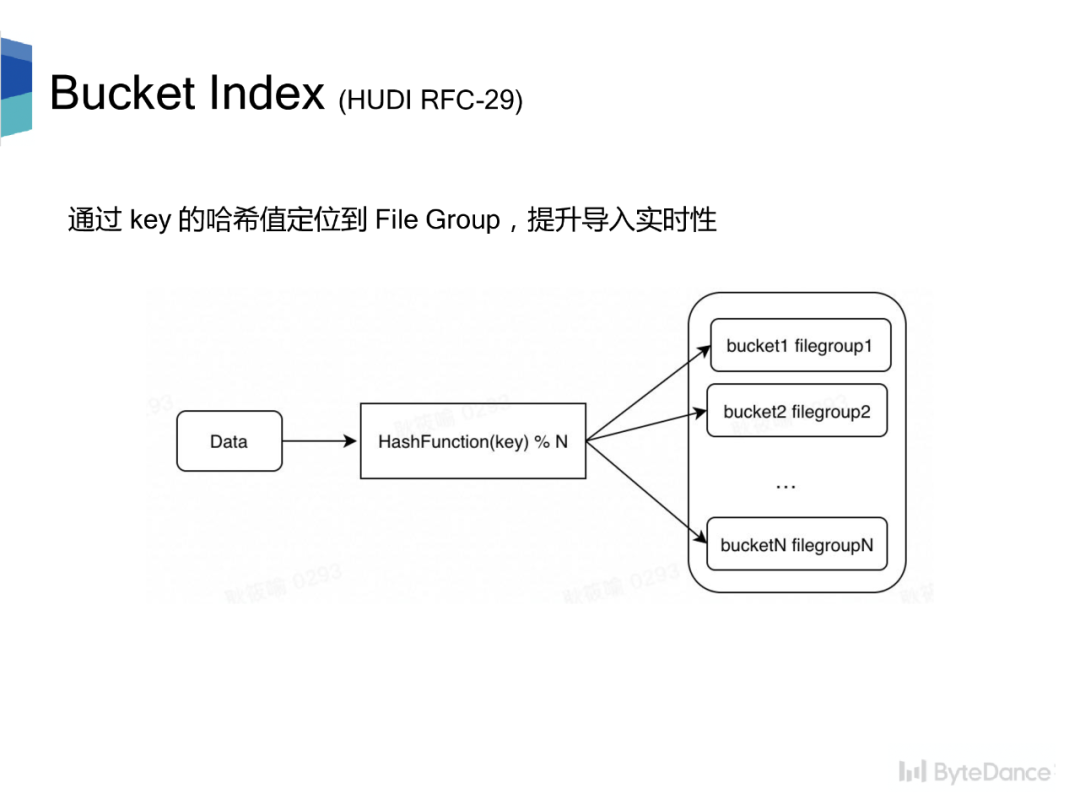
Hudi 目前的两种索引方式,Bloom Filter Index 在大数据场景下,假阳性的问题会导致查询效率变差,而 Hbase Index 会引入额外的外部系统,从而提升运维代价。因此,我们希望能有一个轻量且高效的索引方式。
Bucket Index 是一种基于哈希的索引。每个分区被分成 N 个桶,每个桶对应一个 file group。对于更新数据,对更新数据的主键计算哈希,再对分桶数取模快速定位到 file group,提升导入实时性。
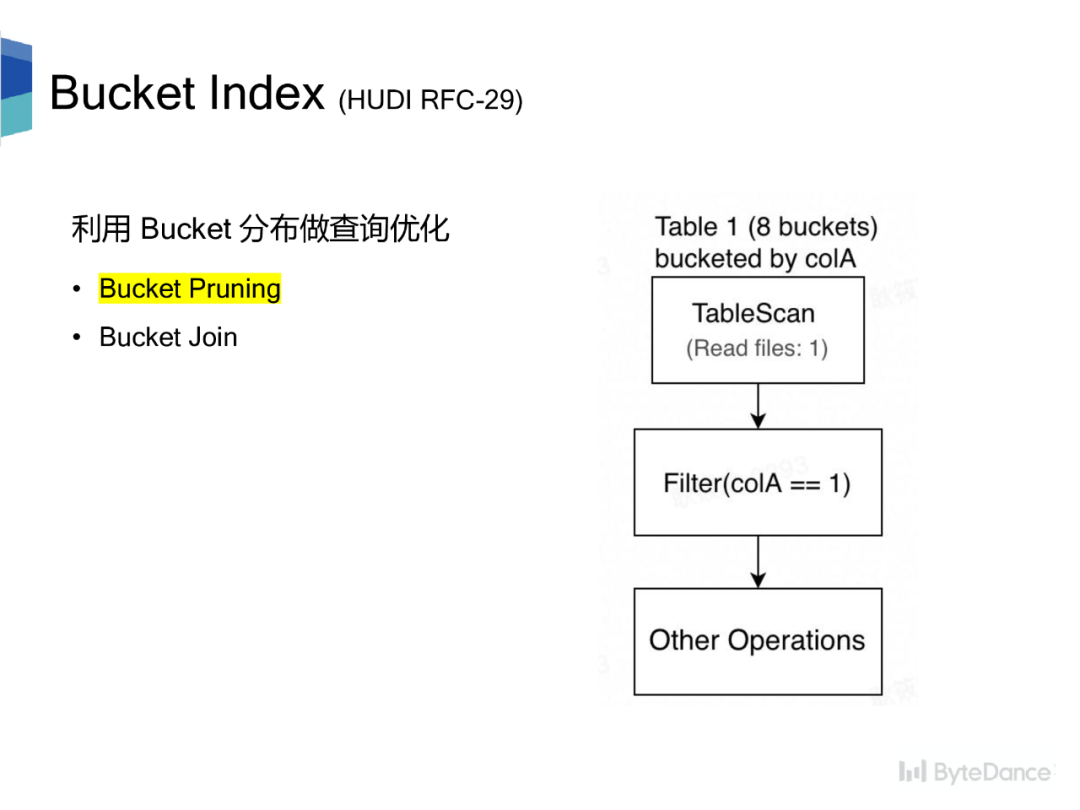
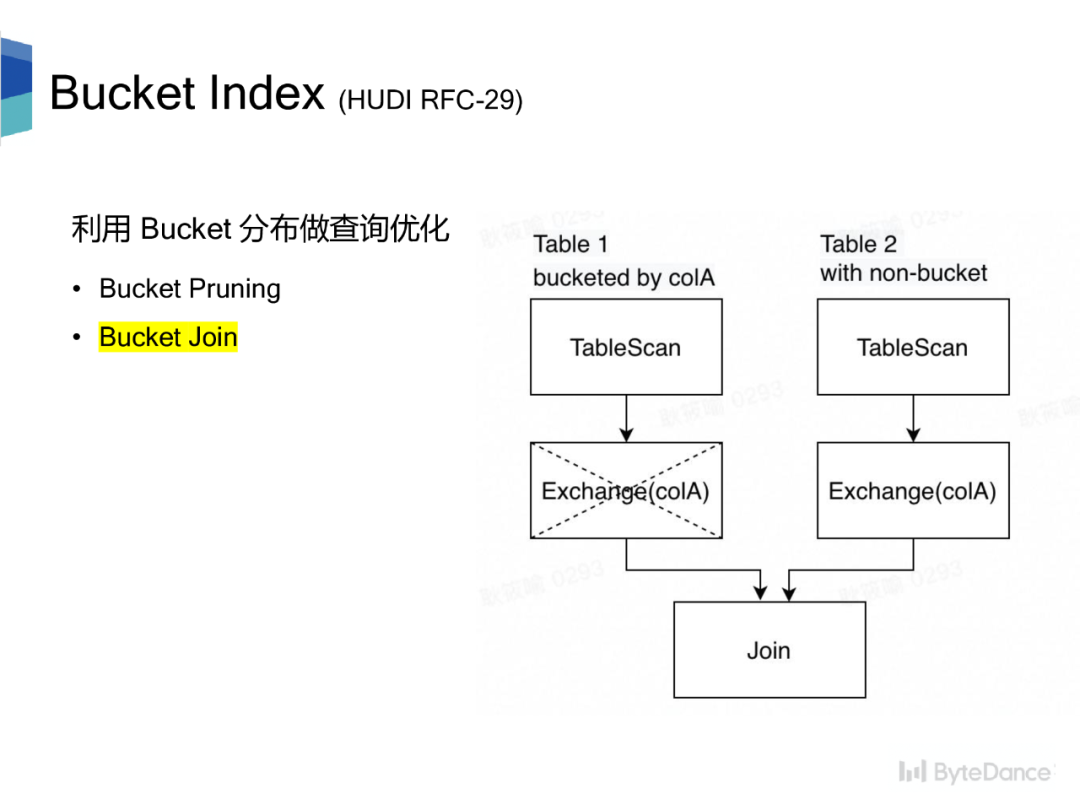
现有的计算引擎大都会利用表的 Bucket 分布做查询优化,提升查询性能。优化规则包含两种:
•Bucket Pruning,利用表的 Bucket 分布对读取数据进行剪枝。•Bucket Join,利用表的 Bucket 分布减少 Join/Aggregate 带来的 shuffle 操作。
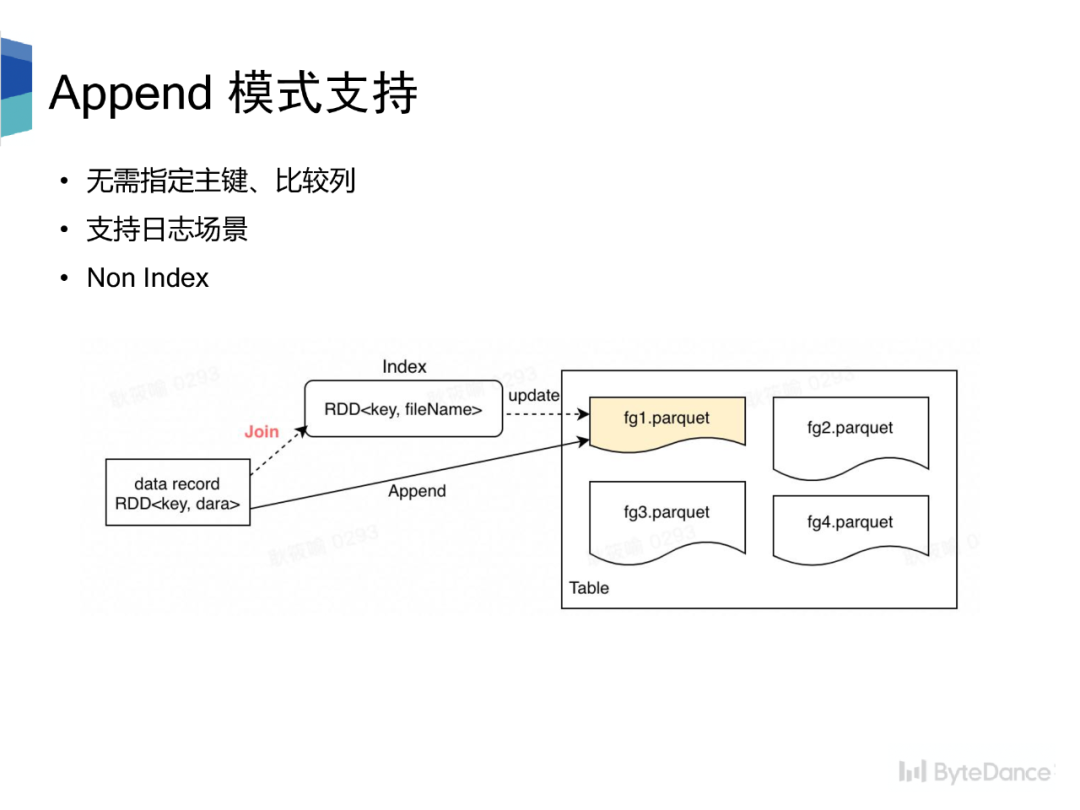
Hudi 要求每条数据都有唯一主键和比较列,用于数据更新时定位 file group 和新旧数据比较。数据定位 file group 过程需要先根据索引构建主键到 file group 的映射关系,然后与更新数据按照主键进行 join,从而找到每条更新数据对应的 file group。
对于日志场景,无确定的主键,并且用户查询也仅仅是对某些列进行 count 操作,因此更新数据只需要直接追加到任一文件末尾即可,也就是 Append 模式。为此,我们提出了 NonIndex方案,无需指定主键和比较列,更新过程也无需构建主键到 file group 的映射关系,避免了 join,提升了导入的实时性。


后续我们会将新特性逐步贡献到社区。
最后,字节跳动数据引擎团队持续招人中,团队支撑字节所有业务线的数仓,打造业界领先的 PB 级 OLAP引擎。工作地包括:北京/上海/杭州,有兴趣的小伙伴欢迎添加微信 minihippo666,或发送简历至邮件 gengxiaoyu@bytedance.com,或直接通过下述二维码进行投递,具体职位信息可通过下述二维码查询。
推荐阅读
顺丰科技 Hudi on Flink 实时数仓实践一文彻底弄懂Apache Hudi不同表类型
37 手游基于 Flink CDC + Hudi 湖仓一体方案实践
硬核!Apache Hudi中自定义序列化和数据写入逻辑
Apache Hudi 在 B 站构建实时数据湖的实践