好家伙,这是从零写了一个“lerna”
点击上方 前端Q,关注公众号
回复加群,加入前端Q技术交流群
背景
相信大家多多少少都接触过或听过 monorepo 这个东西,为了方便多个项目进行调试、复用和管理,采取一种单git仓库管理多个项目方式,市面上流行的库vue、react、bable等都采用 monorepo 方式进行管理。带来便利的同时,也带来了很多挑战。
我们应该以何种方式统一管理这些包呢?包版本升级的时候、发布的时候、依赖冗余这些问题都摆在我们面前。市面上也有很多成熟的解决方案,我司则是选择了 yarn + lerna 做 monorepo 管理。
pnpm、yarn、npm
node_modules 一直是前端人的头痛,一个依赖黑洞魔物。为了解决依赖黑洞问题,yarn 和 npm采取平铺方式,去复用部分依赖,但其中还是存在着不少问题:依赖非法访问、依赖分身等问题,面对多包管理的场景,这种问题尤为突出。
这时候,pnpm 英雄登场,pnpm 下载的文件会统一放到存储中心,项目里面node_modules 会硬链接到存储中心,以一种特殊快捷方式存在,而不是直接在磁盘上生成全新的副本,节省空间。还会通过软链链接依赖的依赖,有效解决依赖分身这个问题。而且硬链接还有一个特性,当存储中心建立起硬链接的文件链接数为0时,还会自动清除该文件,及时回收磁盘空间,跟WeakSet这些弱引用效果一样。
定位
上面说到了包管理器,大家也看到了 pnpm 的优势,所以我这边决定给它来个大革新,yarn 换成 pnpm,而 lerna 已经不维护了,而且我个人更喜欢包管理器就做包管理器的事,monorepo 就做 monorepo 该做的事,大部分功能重合,这并不是什么好事,容易带来混乱,同一件事,有的人用a去做,有的人用b去做,也许可以制定规则去规范大家,但是从一开始就不存在这些事情的话,不是更好吗
开展
上面给出的定位是只做本分,所以现在要实现的功能有两个:version和publish。但是在实现这部分功能之前,我们要分析这个项目的包结构,为后续功能做一个支撑
分析图谱
假定一个项目的结构如下👇🏻,接下来要为项目生成一个分析图谱对象
// 假设下面的包是有依赖关系,并且b依赖a,c依赖b跟a
- packages
- a
- package.json
- b
- package.json
- c
- package.json
- package.json
复制代码
通过globby把里面所有的packages路径拿到手,然后调用fs-extra读取packages.json,将这些信息转换成下面的 contextAnalysisDiagram
// 每个包的具体格式
interface AnalysisBlockObject {
packageJson: IPackageJson // package.json
filePath: string // pacakge.json文件路径
dir: string // 包的路径
relyMyDir: string[] // 依赖该包的包路径
myRelyDir: string[] // 该包依赖的包路径
}
// 项目整体格式
type ContextAnalysisDiagram = Record<string, AnalysisBlockObject>
// 例子:b包的AnalysisBlockObject
{
packageJson: {
"name": "@test/b"
"version": "0.0.0",
"dependencies": {
"@test/a": "workspace:~0.0.0"
}
},
filePath: "packages/b/package.json",
dir: "packages/b",
relyMyDir: [ “packages/c” ] // c依赖了b
myRelyDir: [ “packages/a” ] // b依赖了a
}
// 然后ContextAnalysisDiagram是以dir作为key,去对应每个包的AnalysisBlockObject
contextAnalysisDiagram = {
"": 根目录的AnalysisBlockObject,
"packages/a": a包的AnalysisBlockObject,
"packages/b": b包的AnalysisBlockObject,
"packages/c": c包的AnalysisBlockObject,
}
复制代码
其中转换比较特别点的是 relyMyDir 和 myRelyDir
// 读取项目每个包的package.json以下属性,把包依赖关系都提取出来
const RELY_KEYS = [
'bundleDependencies',
'bundledDependencies',
'optionalDependencies',
'peerDependencies',
'devDependencies',
'dependencies',
]
复制代码
正如上面所说, relyMyDir 是用来保存所有依赖该包的包路径数组,麻烦的是,它不像 myRelyDir 可以在当前package.json里面全部找出来。
常规的方法是对包循环的时候,再在里面加一个循环来找当前包的依赖,但是这种做法会使时间复杂度达到O(n ^ 2)。所以我这边做了一个优化,通过一个对象数组,以每个包的name作为key,对应的值为数组,在每次循环的时候都对当前包的依赖搜索一遍,发现匹配到包name,就将当前dir push进去,这样就实现了一次循环,把所有依赖都保存起来
// 对象数组
const relyMyMap = {
"root": [],
"@test/a": [],
"@test/b": [],
"@test/c": [],
}
// dirs:包的路径数组。
dirs.forEach((dir, index) => {
**伪代码**
// 用来获取当前dir的packageJson依赖,把命中的依赖放到relyMyMap对应的数组
setRelyMyDirhMap(dir, packageJson, relyMyMap)
**伪代码**
this.contextAnalysisDiagram[dir] = {
packageJson,
dir,
filePath: filesPath[index],
// 赋值到relyMyDir,因为是引用类型,后续命中的依赖都会出现在对应的relyMyDir
relyMyDir: relyMyMap[packageJson.name],
myRelyDir,
}
})
复制代码
模式
lerna 有固定模式和独立模式,而我这边对应的是sync 模式和diff模式,大同小异。
命令
// lerna的使用方法
lerna version
lerna publish
// 我为当前工具起了个pkgs命令名
pkgs version
pkgs publish
复制代码
如何定义一个命令行工具呢
创建一个bin目录,在里面创建一个index.js。第一句的意思是告诉系统用node去执行这个文件
#!/usr/bin/env node
console.log('abmao')
复制代码
在package.json定义bin
// package.json
{
"bin": {
"pkgs": "bin/index.js" // 指向bin目录
},
}
复制代码
属于你的命令实现了

我先摊牌,下面是已经实现了的命令函数,使用commander处理复杂命令和友好提示
#!/usr/bin/env node
const { program } = require('commander')
const {
executeCommand,
executeCommandTag,
executeCommandInit,
executeCommandRun,
} = require('../dist/pkgs.cjs.min') // 打包好的构建物
const pkg = require('../package.json')
function handleExecuteCommand (type, cmd) {
executeCommand(type, {
[type]: cmd,
})
}
program
.version(pkg.version)
.description('Simple monorepo combined with pnpm')
program
.command('version')
.description('version package')
.option('--mode <type>', 'sync | diff')
.option('-m, --message <message>', 'commit message')
.action(cmd => {
// pkgs version
handleExecuteCommand('version', cmd)
})
program
.command('publish')
.description('publish package')
.option('--mode <type>', 'sync | diff')
.option('--tag <type>', 'npm publish --tag <type>')
.option('-m, --message <message>', 'commit message')
.action(cmd => {
// pkgs publish
handleExecuteCommand('publish', cmd)
})
program
.command('tag')
.description('pkgs tag, diff mode: Compare according to tag')
.option('-p', 'publish tag')
.option('-v', 'version tag')
.action(cmd => {
// pkgs tag
executeCommandTag(cmd)
})
program
.command('init')
.description('create pkgs file')
.action(() => {
// pkgs init
executeCommandInit()
})
program
.command('run <cmd> [mode]')
.description('run diff scripts.\n mode: work | stage | repository, default: work')
.option('-r <boolean>', 'Include rootPackage', 'true')
.action((cmd, mode, option) => {
// pkgs run <cmd>
executeCommandRun(cmd, mode, option.r !== 'false')
})
program.parse(process.argv)
复制代码
version 命令
version 命令是用来升级各个包的版本。一开始我是用了antfu大佬的bumpp来做命令行交互,但是这个库每次选择完版本都会写进package.json文件,我更想要的是在内存里面获取到newVersion,然后等所有包都选择完版本后,再一次过写进去。因此我提交pr的同时也publish了一个新库,今天看了下,pr还没人理,估计没怎么关注这个库了
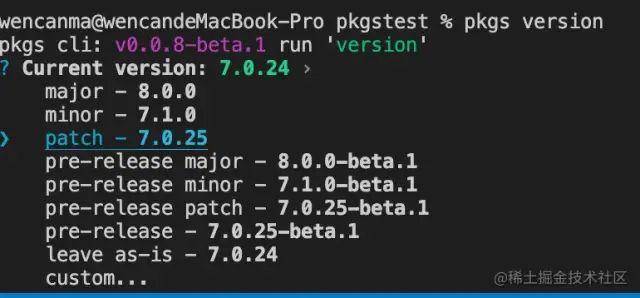
sync 模式
sync模式是提供给组织性质比较强的项目使用,同时迭代,同时发布。调用命令的时候,只会选择一次版本,然后同步所有包的package.json,最后git commit并打上git tab
pkgs version
// 默认是sync,可以省略后面这段
pkgs version --mode sync
复制代码
diff 模式
diff模式只会对修改过和被修改影响到的包触发,对每个需要版本升级的包都单独选择一次版本,然后分别写到对应的package.json
pkgs version --mode diff
复制代码
问:那么它是如何找到上述包进行版本升级呢?
答:首先它会根据git提交的最新记录和最近的一个gitTab,拿到之间修改过的文件,再通过bump当前包获取到newVersion,再与contextAnalysisDiagram分析relyMyDir里面的依赖关系,根据版本语义化*、^、~等进行判断是否要升级该依赖,是的话,会调用bump,如此类推。当然,还要把已经升级过的包储存到一个Set里面,防止多次调用bump。最后git commit并打上git tab
publish 命令
对于需要发布到npm上的包,提供了publish命令,用于包发布
pkgs publish
// 添加npm标签
pkgs publish --tag beta
复制代码
对@开头的组织包,还会在末尾自动添加上 --access public如果是 0.0.8-beta.1这种带标签的版本号,会自动为其添加标签。当然你可以通过--tag手动添加
同时publish命令也是有sync模式和diff模式,sync模式对于publish来说比较鸡肋,所以一般都是diff,或者是配合sync的version一起使用。而publish的diff没有version那么复杂,只需要拿到最新commit和第一个gittag就可以,并不需要计算影响这一步。
插曲
了解过lerna的小伙伴可能意识到,这不就是lerna的实现原理吗?雀实,我有个坏习惯,对于不熟悉的领域我都喜欢撸了再说,我比较喜欢那种两倍痛苦带来的两倍快乐,我事先是闭门造车的思考了这套方案,等我实现了的时候,发现跟 lerna 一模一样,是坏消息的同时也是好消息。其实一不一样我都是可以接受,不一样,可以得到两套思想的碰撞💥,你可以非常非常地深入到两种思想中,探讨其中的优劣,如果能得出更好的方案,更是一种思考上的升华。一样的话,是不是可以证明,已经达到了一定的水平了呢?(自吹自擂ing
tag 命令
问:为什么会有 tag 这个命令呢?
答:上述的 version 和 publish 命令的 diff 模式都是基于git tag打上跟 pkgs 定义好的tag实现的,为了让 lerna 之类的项目无痛迁移到 pkgs,保证正确的 diff,放出了 tag 命令,先对项目使用 tag 命令,就可以保证后面正确的 diff
git tag // 打上publish标签和version标签
git tag -p // 打上pbulish标签
git tag -v // 打上version标签
复制代码
init 命令
创建pkgs相关模板,如下。当然,创建的时候先检察当前文件目录是否已经存在,存在会跳过当前文件目录的创建
pkgs init
复制代码
- packages
- package.json
- pkgs.json
复制代码
自定义命令
一个经常有的场景,修改了包后,其他很多包依赖着这个包,运行测试的时候有两种
全部运行npm run test 指定某些包npm run test
这两种方法都不好,浪费、繁杂、并且人工指定容易出错。
如果有一个功能,继承了上面说的 diff 功能,并且可以对工作区、暂存区和版本区进行分析,只对修改过和被影响的包运行npm命令,这听起来是不是很棒(๑•̀ㅂ•́)و✧
有没有一种可能,pkgs 已经实现了。是的,已经提供了该功能啦~👇
// 可以看成是monorepo版本的`npm run`
pkgs run <cmd>
// 测试
pkgs run test
// 默认是工作区,可以忽略wokr
pkgs run test work
// 暂存区
pkgs run test stage
// 版本区
pkgs run test repository
复制代码
优先排序
还有一种场景,a包依赖b包,那么build的时候,正确的顺序是等b包完成构建才到a包构建,为了实现这个功能,要对contextAnalysisDiagram的myRelyDir进行分析:
找到当前包依赖的包,然后将当前包塞进去stack,同时还要创建一个result数组,用来保存包的顺序 对依赖包循环,找到该依赖包是否也有依赖,如此类推,有依赖,则继续递归 那么如何才停止递归呢?只需要判断该依赖是否在stack或者result里面,如果是在stack里面,则弹出一个,放到result里面,如果result已经保存有,则忽略。同时会跳过对该依赖的搜索。
这样就拿到所有包的运行顺序,解决了上述场景的问题
配置
为了减少命令行输入的参数,一般都会有一个对应的配置文件,把参数都预先都写上去
pkgs.json
放到根目录即可
{
rootPackage: true, // 自定义命令是否包括根目录
mode: 'sync', // sync | diff 模式
version: {
mode: undefined, // sync | diff 模式,更高的优先级
message: 'chore: version', // version命令后的commit message
},
publish: {
mode: undefined, // sync | diff 模式,更高的优先级
tag: '', // npm包标签
},
}
复制代码
pnpm-workspace.yaml
pkgs会读取pnpm-workspace.yaml文件的工作区,默认是packages/**
构建
使用rollup进行打包,因为用的是ts,所以一开始是使用了esno进行运行
依赖循环
在构建过程中发现很多cjs的老牌包存在依赖循环的包,因为涉及的场景太多了,提pr改的话是不会采纳的,我是直接fork出来,调整重新发包
esbuild
用了esbuild是真的快,而且还可以运行ts。上手成本非常低,但是效果杠杠的
测试
其实一开始测试这种类型我是懵逼的,如何测试git?如何测试命令行?在我观摩了多个相关开源项目的测试后总结的一种方式:
测试git:为了保证不污染环境,使用node的临时目录,在其创建项目模板,使用 process.chdir切换工作目录到临时目录上,就ok了测试命令行:总不能测试的时候,要命令行交互选择版本号吧,给npm那边publish吧。查看了 bumpp测试代码,发现可以直接输入版本号,绕过命令行交互形式。publish的话,我则是直接修改源码,判断当前环境是否测试,是的话,就不走命令,而是返回命令的字符串,我再进行对比。
测试工具
一开始用的是老牌测试框架jest,但是对ts的支持还是试验性,用起来非常的麻烦。正好最近关注vitest,就直接拿来用,因为语法一样,切换成本也是非常的低,而且开箱就支持了ts,妙啊
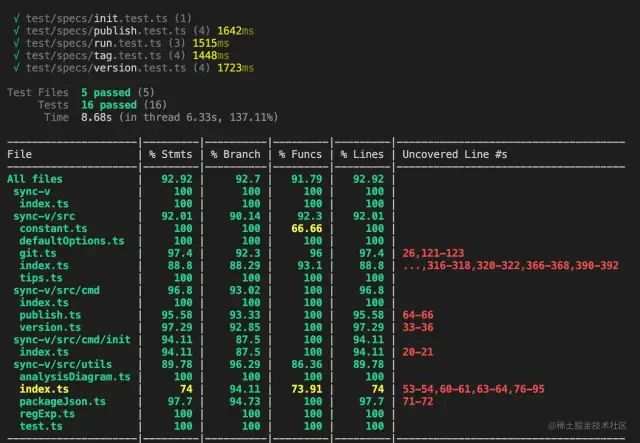 除了那些不必要的分支,基本都覆盖到所有功能了。
除了那些不必要的分支,基本都覆盖到所有功能了。
发布
pkgs的版本管理和发布,都是用了本身的version和publish逻辑去管理,而pkgs并不是一个多包项目,所以这个库是无论你是多包还是单包,都可以使用。
// release.ts
import { execSync } from 'child_process'
import colors from 'colors'
import { executeCommand } from '../index'
console.log(`${colors.cyan.bold('release: start')} 🏗`);
(async function () {
// 运行测试
execSync('npm run test', { stdio: 'inherit' })
// 打包
execSync('npm run build', { stdio: 'inherit' })
// 版本选择,相当于pkgs version
await executeCommand('version')
// 发布,相当于pkgs publish
await executeCommand('publish')
})()
console.log(`${colors.cyan.bold('release: success')} 🎉🎉🎉🎉🎊`)
复制代码
// 这样就可以开始发布啦
npm run release
// 安装
npm i -g @abmao/pkgs
复制代码
TODO
接下来记录下想解决的事,或者说大伙有啥想法的不?
构建物过大
真的非常大,而且还存在着依赖循环问题,愁啊,有空看下解决,依赖大估计是fs-extra的问题
状态分析
后面想要实现一个state的功能,查看包之间的状态
pkgs state
复制代码
谢幕
也许你可以来个赞或者评论或者星,没有的话,下次再问
pkgs-github:https://github.com/hengshanMWC/pkgs
关于本文
来自:科目三后吃饭
https://juejin.cn/post/7084596115177209886

往期推荐


最后
欢迎加我微信,拉你进技术群,长期交流学习...
欢迎关注「前端Q」,认真学前端,做个专业的技术人...