
如何更好地结构化表示一个 URL?
“
阅读本文大概需要 3 分钟。
相信各位 Python 开发者都用过 Requests 库,有些朋友还用过 WebSockets 库。这里回顾一下它们的基本用法,例如使用 Requests 库向目标网站发出 GET 请求:
import requestsurl ="https://www.baidu.com"resp = requests.get(url)print(resp.status_code)# output -> 200
使用起来非常简单,我们很轻松地向目标网站发出了请求并打印输出响应状态码。当然,你还可以把它缩短:
import requestsprint(requests.get("https://www.baidu.com").status_code)# output -> 200
怎么写出更短的代码并不是这次要讨论的话题。今天我们来研究一下:运行代码的计算机是如何找到目标服务器的?
显然,你的第一映象是 IP 地址和端口号。
没错,就是 IP 地址和端口号。
但你明明输入的是 URL 地址,怎么就 IP + 端口号呢?
URL 解析的原因一下子你也回答不上来吧?
我们可以将上方代码的逻辑,即计算机向目标服务器发出请求并拿到响应信息的过程抽象成下图:
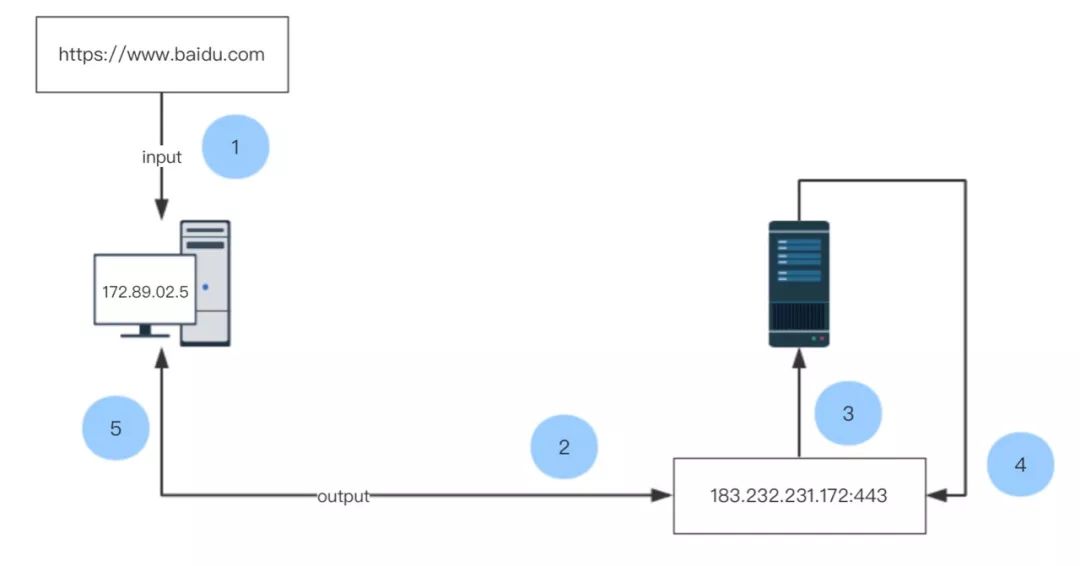
程序输入的是 https://www.baidu.com,但最终要解析出具体的 IP 地址和端口号才能访问,例如 183.232.231.172:443。
网络交互实际上属于 Socket 编程的范畴,无论是 Requests 还是 WebSockets 库,最终都会通过 Socket 与目标网站的服务器进行交互。
而 Socket 编程中并不能直接使用域名,而是采用 IP + 端口号这种形式进行寻址的。
假设你现在需要编写一个网络请求库,有可能是 HTTP 协议的,也有可能是 WebSocket 协议的。
你要解决的第一个问题就是解析 URL,将网址转换成 IP + 端口号,甚至还需要分割出协议类型、资源路径以及是否采用更安全的传输方式等。
URL 解析格式以 WebSocket 协议方面的客户端库为例,在双端确认连接之前有一个「握手」的过程,这个过程之前已经需要双端的 IP 和端口号等信息了。下面的代码描述了 WebSocket 发出「握手」请求之前,双端建立连接时需要用到的基本信息:
# aiowebsocketreader, writer = await asyncio.open_connection(host=host, port=port, ssl=ssl)
也就是 host、port 和 ssl。
大部分的 WebSocket 服务给出的都是域名,例如 wss://echo.websocket.org。「握手」时还会用到资源路径。
接下来,我们来尝试一下,如何将域名转换为 IP + 端口号和 is ssl 这样的格式。
代码实现 URL 解析开始之前,我们先规划一下基本步骤:
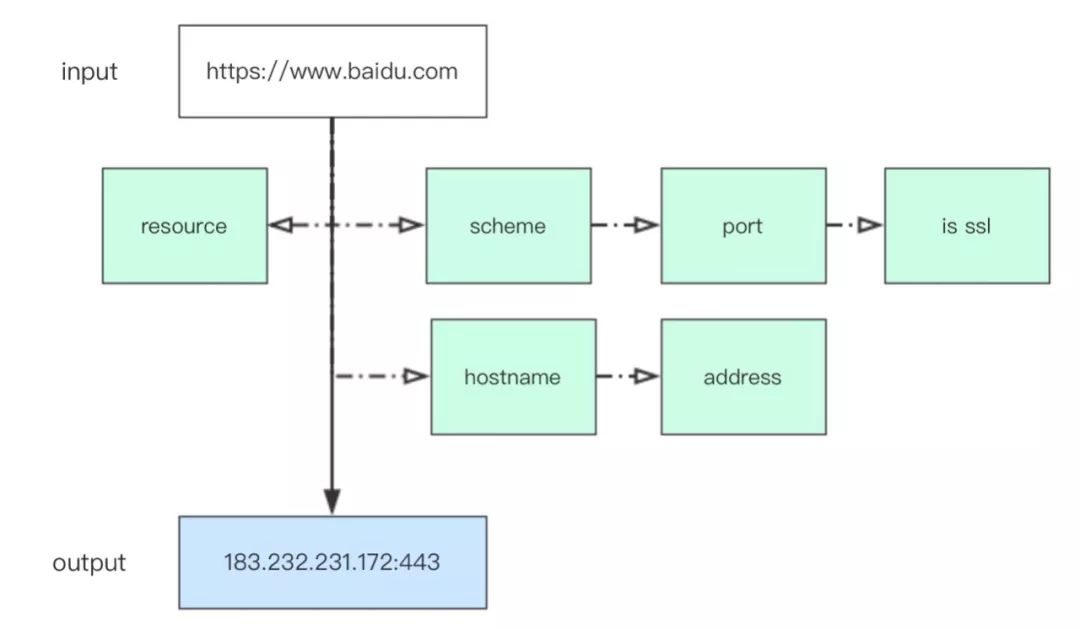
然后确定要使用的标准库:解析 URL 当然要用到 urllib 库中的 url parse;解析 address 则需要用到 socket 库;为了方面取数据,可以尝试使用 collections 库中的 namedtuple。
首先引入这几个库:
import socketfrom collections import namedtuplefrom urllib.parse import urlparse
然后定义输出结构,对应代码如下:
REMOTE = namedtuple('REMOTE',['scheme','hostname','address','port','resource','ssl'])然后定义一个方法,我们传入 URL,获得解析好的 REMOTE 对象。方法定义如下:
def parses(url: str)-> REMOTE:pass
待会我们在 pass 处编写属于该方法的代码。
最开始要解析 URL,获得 scheme 和 hostname,对应代码如下:
url = urlparse(url)urlparse 方法会返回一个 ParseResult 对象,对象大体格式如下:
ParseResult(scheme='wss', netloc='echo.websocket.org', path='',params='', query='', fragment='')有了 scheme 和 hostname 后,就可以得到 port、is ssl 和 address。对应代码如下:
scheme = url.schemeaddress = url.hostnameport = url.port or(443if scheme =='wss'else80)ssl =Trueif scheme =='wss'elseFalse
WebSocket 协议中只有两种协议头:ws 和 wss。它们对应的端口分别是 80、443,这里借助 scheme 的值进行判断即可得到答案。同理,也直接得到了 is ssl 答案。
拿到 hostname 后,调用 socket 库的 getbyhostname 方法就能够得到目标服务器的 IP 地址了。对应代码如下:
address = socket.gethostbyname(hostname)至于资源路径,它早已存在于 ParseResult 对象中,直接取出即可:
resource = url.path要注意的是,有些 URL 中还会携带请求正文(即参数和值)。所以这里需要取 query,并将其拼接到 resource 中:
if url.query:resource +='?'+ url.query
至此,我们已经拿到了所需的所有数据。
现在将它们装在到 REMOTE 结构中,返回给调用方:
return REMOTE(scheme, hostname, address, port, resource, ssl)此时,调用 parses 方法后就会拿到 REMOTE 结构,它的取值方式很舒服,用 . 符号取值即可。例如:
res = parses("ws://echo.websocket.org?sign=i9878")print(res.address, res.port, res.resource)
代码运行结果如下:
174.129.224.7380?sign=i9878
这样,我们就完成了 URL 解析的代码编写。
小结代码虽然不多,逻辑也并不复杂。但我们完整实现了网络请求库中的 URL 解析模块,这代表着完成了编写库的基石之一。
在这个过程当中,我们了解到双端通信的基本过程和要用到的信息。在编码中学会了如何将 urlparse、socket 和 namedtuple 结合到一起。
而且,你今天学到了 namedtuple 这个新姿势!
「你好骚啊.gif」
完整代码可在我的 Github 仓库查看:https://github.com/asyncins/CFA/tree/master/FightingCoder
推荐阅读
1
2
跟繁琐的模型说拜拜!深度学习脚手架 ModelZoo 来袭!
3
4
妈妈再也不用担心爬虫被封号了!手把手教你搭建Cookies池
崔庆才
静觅博客博主,《Python3网络爬虫开发实战》作者
隐形字
个人公众号:进击的Coder


长按识别二维码关注