编辑:David 好困
【新智元导读】近日,NeurIPS 2021被接收论文的详细得分公布。最高分为MIT的8.75分,现华中科大助理教授和清华校友8.5分并列第2!澳华人团队遭遇Consistency Experiment低分。
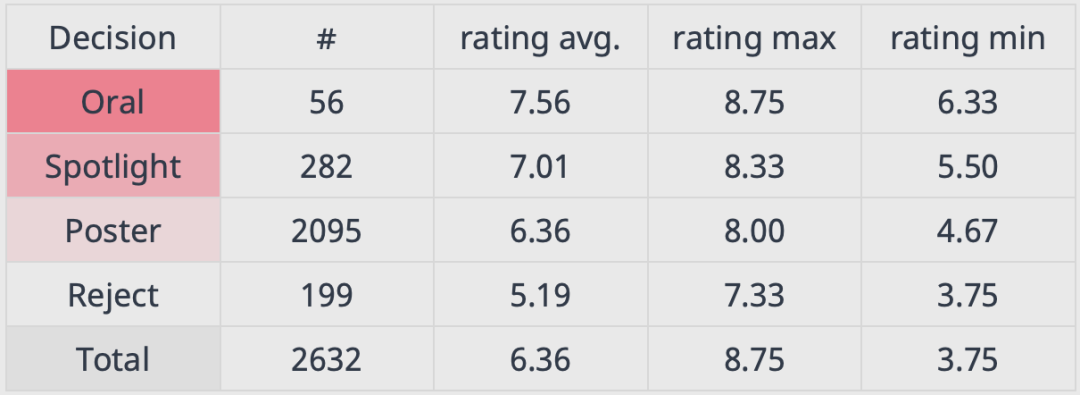
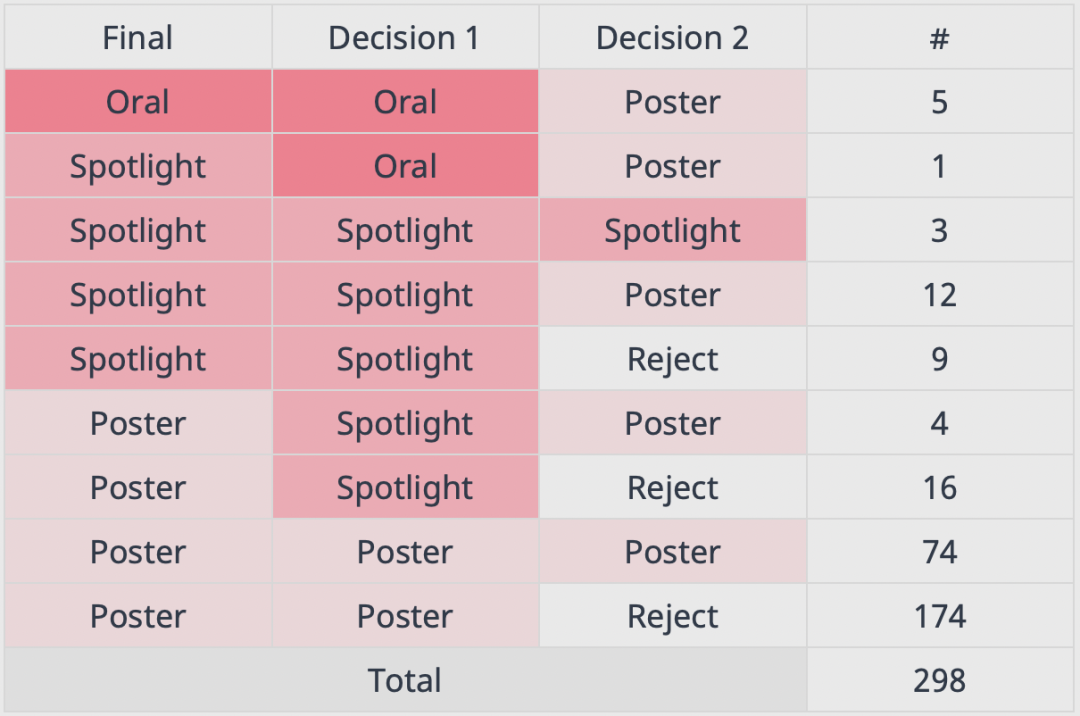
本届共有9122篇论文提交,其中2334篇被接收,占比26% ,接受率较前几年的20%左右水平明显上升。近日,这些论文的得分数据统计,以及「一致性实验」的评审结果也被放出了!从被接受论文的总体评分分布上看,大部分文章的得分分布在6.12分-7.17分之间,最高分为8.75分,最低分为3.75分。从文章评分和审稿意见来看,在总计2334篇被接受的文章中,共产生了2632组审稿意见。其中有298篇文章参与了「一致性实验」,经过两次审稿。同样是获得Accept,但按照文章评分不同,审稿人给出的最终意见分为三等。最高的是Oral,以长报告的形式介绍论文,其次为Spotlight,以短报告的形式介绍论文成果,再次为Poster,通过海报展示论文成果。要获得最高的Oral意见,平均得分达到了7.56分,最终审稿人给出的决定中,只有56个Oral,仅占全部审稿意见总数的2.1%。比Oral次一级的Spotlight要求也很高,平均分达7.01分,审稿给出的Spotlight意见也只有282个,占总意见数的10.7%。大部分被接受的文章最终获得资格是Poster,即海报展示。达到这一标准的平均分为6.36,占总意见数的比例为79.5%。另外,审稿人在二次评审中还给出了199个拒稿意见。不过这部分论文的最终的Decision都是接受,甚至还有9篇文章获得了Spotlight评价。强化学习、深度学习、表示学习、自监督学习、元学习、泛化、在线学习、图神经网络、鲁棒性、生成模型等。有趣的是,在这个统计中,graph neural networks(51)和graph neural network(33)被分开计算了。除此以外,还有transformer(57)+transformers(37)=Transformer(94)。所以,实际上涉及Transformer的论文数量为94篇,仅次于强化学习的199篇和深度学习的129篇,位列第三。自2014年开始,NeurIPS就在进行一致性实验,由两个独立的委员会审查10%的提交材料,从而量化审查过程中的随机性,以及审查过程的质量如何随时间的推移而变化。参与实验的论文会被分配给两个委员会(由审稿人、一个地区主席和一个高级地区主席组成)。如果两个委员会都提出相同的建议,则遵循这一建议。如果只有一个委员会建议接受,该论文就被接受。这其中,有221篇投稿收到的两个决定是不同的,占比为74%。从中可以看出,两组评委在Oral/Spotlight方面的共识极低。其中有6篇论文,一组评委认为是Oral,而第二组评委则认为是Poster。在34篇Spotlight论文中,也只有3篇评委达成了一致。还有25篇论文,第二组评委直接投了Reject。
平均得分最高的论文是来自麻省理工的「Near-Optimal No-Regret Learning in General Games」。https://arxiv.org/pdf/2108.06924.pdf本文解决了一个自Syrgkanis等人2015年的工作以来一直都没有被解决的问题。尽管Chen & Peng, 2020的最新进展显示了T^{1/6}的遗憾,但为了实现polylog(T)的遗憾,本文提出了一个显著的新观点,我们认为这对社区非常有益。所有审稿人都对这一结果感到兴奋。
并列第二的是加利福尼亚大学伯克利分校的「Hessian Eigenspectra of More Realistic Nonlinear Models」和以色列魏茨曼科学研究所和Facebook AI合著的「Volume Rendering of Neural Implicit Surfaces」。https://arxiv.org/pdf/2103.01519.pdf本文在随机矩阵理论中提出了新的数学结果,描述了高维系统中广义线性模型(G-GLMs)对应的Hessian矩阵的极限谱分布。其结果是对极限谱的渐进式精确表征,表现出实践中经常出现的结构类型,包括孤立的离群特征值、多模态密度等。因此,本文为NeurIPS社区提供了一个理解高维模型频谱的新的和强大的视角,并有可能为二阶优化和其他领域的新发展铺平道路。本文标题中的「更现实」描述了结果的范围和通用性:这里的重点实际上并没有触及现实模型、NN等,但G-GLM设置和一般分布假设使指针明显朝向「现实」方向。虽然本文确实观察到了一些确实倾向于出现在实际配置中的现象(比如大的离群值),但仍然不清楚这里提供的解释实际上是否是更普遍的现象所依据的那些解释。本文的扩展版本肯定会受益于对这个问题的一些详细(经验)分析。不过,如果没有这些补充,本文中的技术和见解还是会引起社区的兴趣,而且本文将成为NeurIPS的一个重要补充。
https://arxiv.org/pdf/2106.12052.pdf这篇论文介绍了一个及时而重要的贡献,将SDF表征与神经体积渲染相结合。四个审稿人中的三个强烈建议接受。作者应该努力解决审稿人所关注的问题。这包括加入反驳期的消融研究,纳入L3KT建议的讨论等。
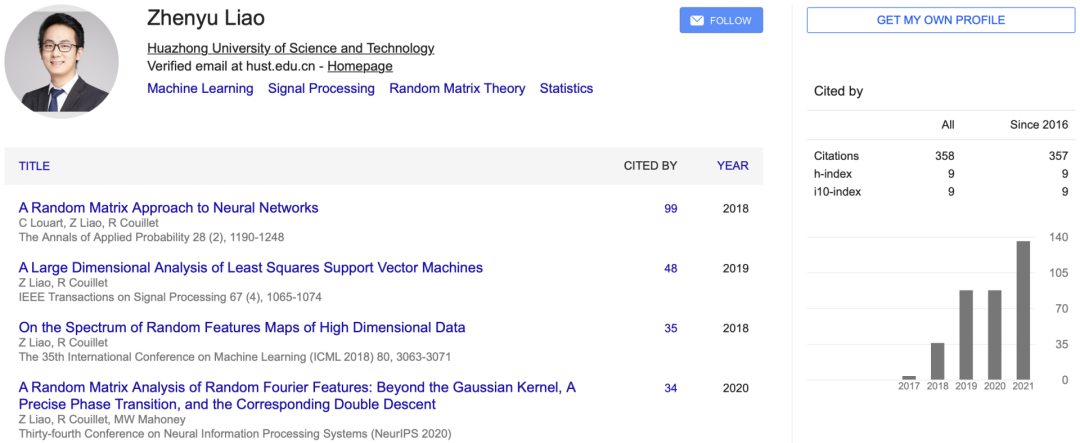
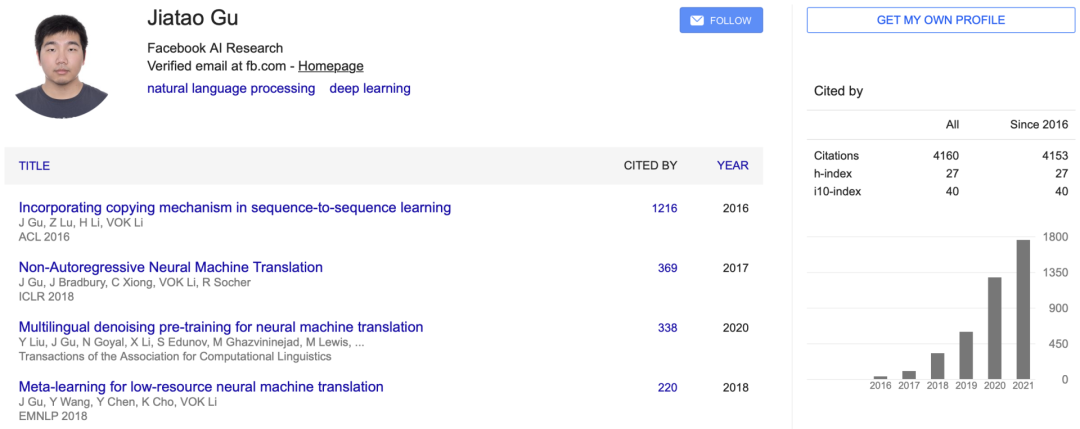
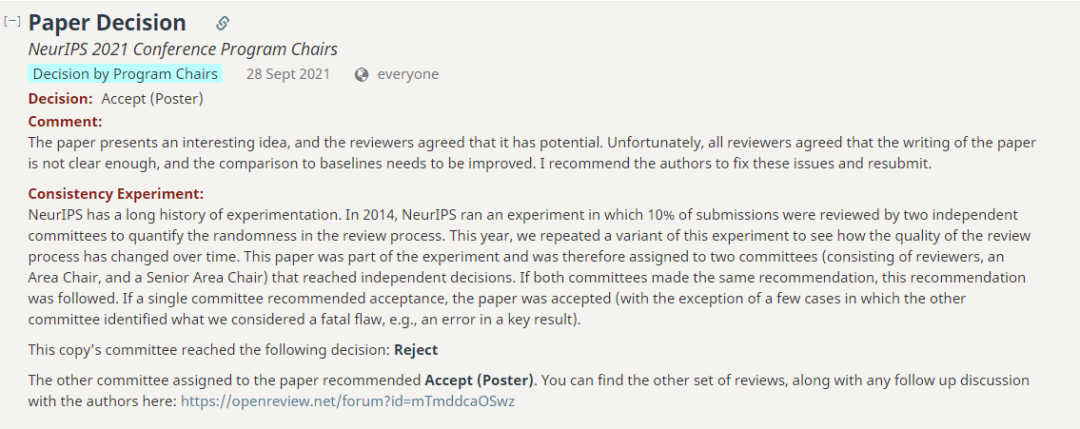
「Hessian Eigenspectra of More Realistic Nonlinear Models」的一作Zhenyu Liao现在是华中科技大学电子信息与通信学院的助理教授。在此之前,Zhenyu Liao于2020年在加利福尼亚大学伯克利分校统计系做博士后研究。2019年在巴黎萨克雷大学CentraleSupélec获得博士学位,2016年在巴黎萨克雷大学获得信号与图像处理硕士学位,2014年在华中科技大学获得光学与电子信息学士学位。此外,他还是是IEEE、CCF和CAAI的成员。研究兴趣主要集中在(统计)机器学习、信号处理、随机矩阵理论和高维统计。「Volume Rendering of Neural Implicit Surfaces」的二作是来自Facebook人工智能研究中心的Jiatao Gu。他于2018年在香港大学电气与电子工程系获得博士学位。在此之前,于2014年在清华大学电子工程系获得学士学位。研究兴趣是将深度学习方法用于自然语言处理(NLP)问题,以及为人类语言建立一个高效、有效和可靠的神经机器翻译(NMT)系统。此外,在最终被接收的论文中,有两篇论文收到了评审组给出的最低平均分,3.75分。 其中,「CO-PILOT: COllaborative Planning and reInforcement Learning On sub-Task curriculum」的第二组得分为6.00,低于另一篇的7.00分。https://papers.nips.cc/paper/2021/file/56577889b3c1cd083b6d7b32d32f99d5-Paper.pdf作者在文章中提出了一个新的框架CO-PILOT,其中规划器(Planner)和强化学习代理从头开始训练,并可以通过自动生成的易到难的子任务课程,相互促进和指导彼此的训练。这篇论文提出了一个有趣的想法,审稿人一致认为它有潜力。不幸的是,所有审稿人都认为论文的写作不够清晰,与基线的比较也需要改进。我建议作者解决这些问题并重新提交。
第一组审稿人的意见其实是非常统一的:拒稿(4,4,3,4)。第一位审稿人认为,这篇文章的观点很新颖,方法也是「闭环」的,但是在细节上有欠缺,实验没有描述预测模型是如何训练的。在论文写作上描述不够清晰,使得论文有些难以理解,给出了4分,拒稿的意见。第二位审稿人认为,作为一篇以实验为基础的论文,文章的实验设置不够扎实,致使实验结果比较的可信度打了折扣。另外,在论文写作上也存在不少语法错误。给出4分,拒稿的意见。第三位审稿人认为,论文的表述、正确性和可读性均存在问题。文中数学和算法公式以及文本的清晰度需要大修。对实验部分的每个域中的状态、动作空间缺乏必要的明确定义和解释。给出3分,明确拒稿的意见。第四位审稿人认为,实验评估的一个主要问题是该方法没有与基线进行公平的比较,所提出的方法还存在许多技术问题,论文存在许多写作问题和语法错误。据此给出4分,拒稿的意见。作者团队的Rebuttal均未能改变审稿人的意见。 第二组审稿人的评价要明显好一些,四位审稿人的评分也非常统一,都是6分。第一位审稿人认为,这篇论文很好地激发了洞察力,论文中的方法原则性强,提出的训练策略也比较有趣。但新颖性略显不足 ,对算法差异结果的讨论有些不够。第二位审稿人认为论文写作比较清晰,但是实际上有其他方法和 CO-PILOT的表现不相上下。没有真正讨论该研究的局限和社会影响。第三位审稿人认为:这篇论文提出了一个有趣的想法。实验还可以进一步改进,该论文需要更强有力地阐明他们的方法有何不同,以及实现了哪些具体好处。第四位审稿人认为:文中算法的大多数关键方面都进行了巧妙的讨论。问题主要是HRL和CO-PILOT之间的区别应该进一步解释,还需要强调成果的局限性,尤其是对新环境下的泛化问题,以及如何解决。
参考资料:
https://guoqiangwei.xyz/htmls/neurips2021/neurips2021_submissions.html