
一次爬美团网美食团购的经历

作者:刘早起早起
来源:早起python


在一开始还是选择去一些技术网站看看有没有思路可以借鉴,根据搜索结果我将相关帖子分为两类,一类是已失效的代码,另一类是吐槽为什么美团的反爬机制这么变态。所以自己想办法解决。还是先打开目标页面看一下
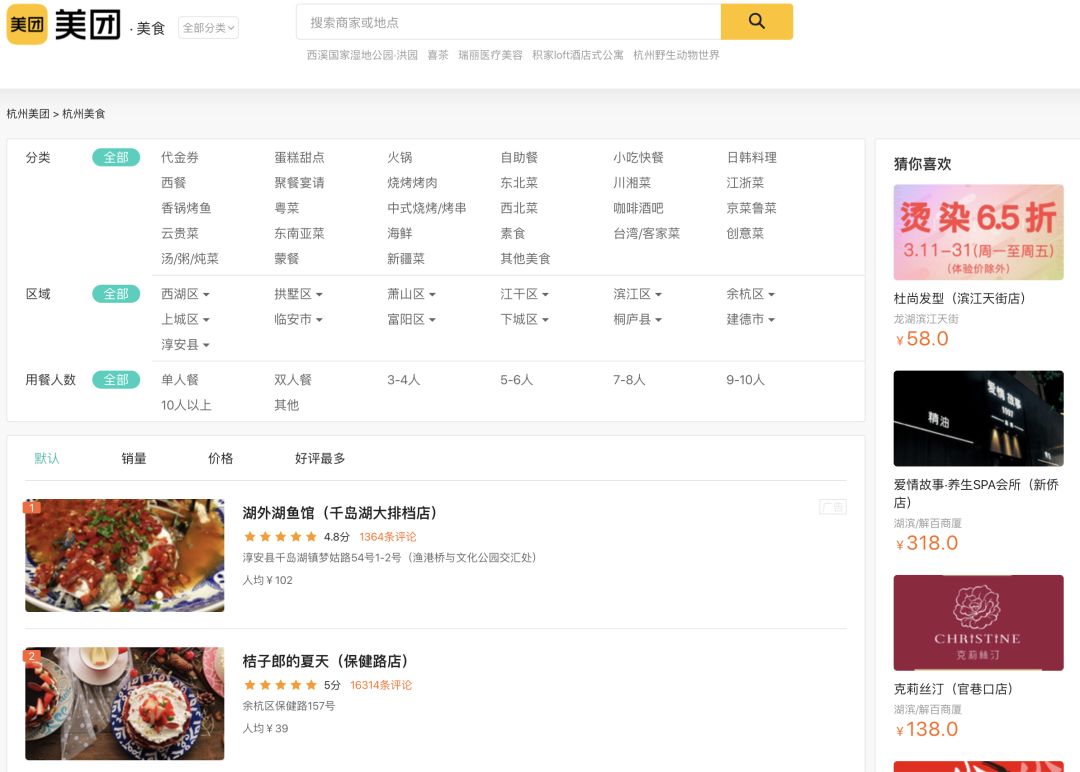
通过切换区域可以发现页面的内容是通过Ajax异步请求技术得到的,简单来说就是能够实现在后台与服务器交换数据,在不重新加载页面的情况下更新网页。所以打开浏览器F12,进入开发者工具,选择Network,刷新页面,选择XHR(XmlHttpRequest)就可以选出Ajax的请求包
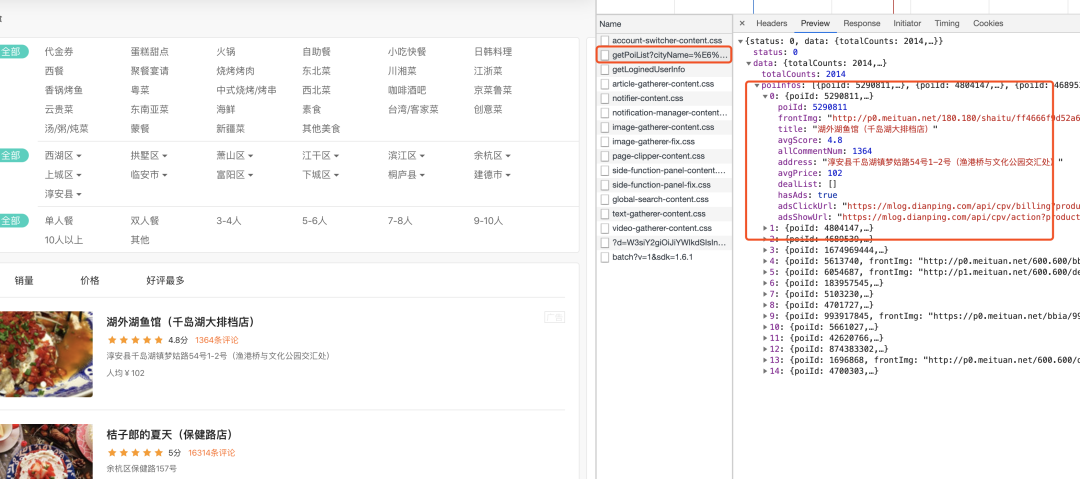
通过check preview的内容很轻松的就能从几个数据包中找到我们需要的那一个,再看下headers信息找到Requests URL
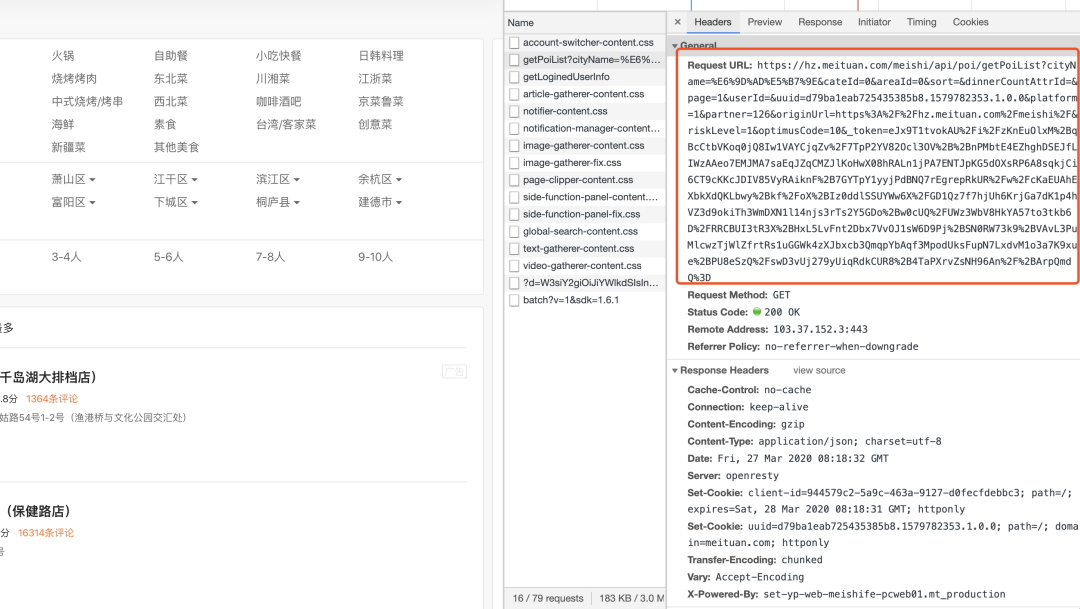
我们先打开一下这个URL试试?

OK返回的是一个json数据,心中暗喜,这不是搞定了吗,再定睛一看

这除了给了一个店铺名和地址还有评分就完了,就这点信息拿什么去分析,回想了一下刚刚查阅的一些其他大神曾经写的代码明明还有优惠券等信息,于是翻回之前的相关文档,通过对比发现只要在URL中添加userID就能返回更多的店铺信息

心中再次暗喜,虽然这只是一页的数据,我再写个循环多取几页不就能取一些数量的数据用于分析了吗,所以抓紧操作起来
url_list = []
for _ in range(1,31):
url = 'https://hz.meituan.com/meishi/api/poi/getPoiList?cityName=%E6%9D%AD%E5%B7%9E&cateId=0&areaId=0&sort=&dinnerCountAttrId=&page=' + str(_) + '替换为你F12之后URL中page参数后对应的字符'
url_list.append(url)OK,这样一操作之后30页的URL就有了,再用requests去请求数据不就完事了,先测试一下
headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
"Host": "hz.meituan.com",
"Referer": "https://hz.meituan.com/meishi/",
"Sec-Fetch-Dest": "empty",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-origin"}
data = requests.get(url,headers = headers).json()和我们预想的结果一样,那么接下来写个循环去取30页数据并保存不就收工了

但是自己还是太年轻,程序没有跑几秒就直接异常了,也设置了请求频率怎么还是挂了,没事我们先看下怎么回事,浏览器打开刚刚的API试试
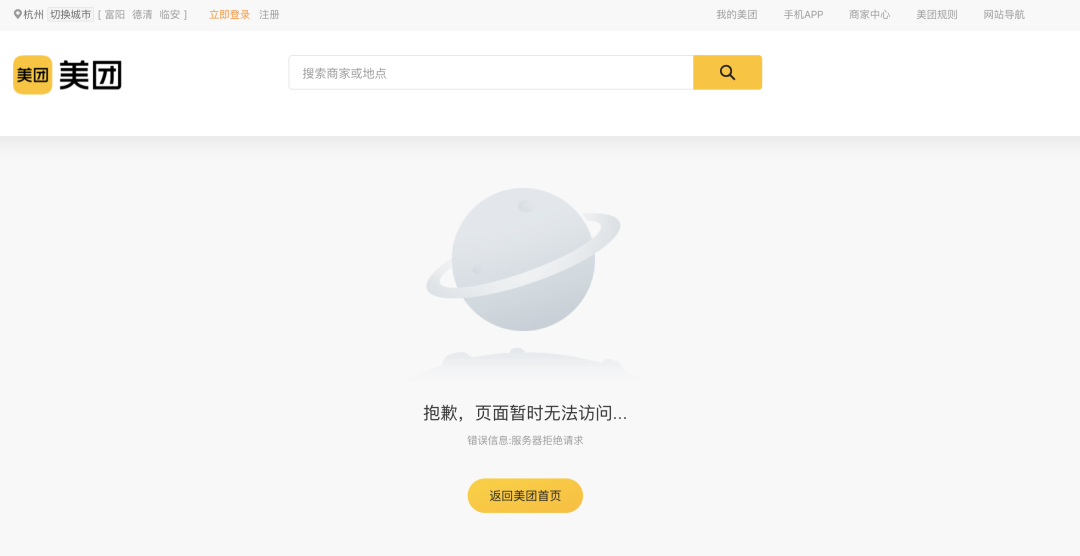
哦吼,这是API直接整挂了吗?难道是更换地址了?再从首页进美食栏目试一下
再定睛一看,这还是美团还单独做了一个页面。不管怎么访问美团都是返回error403

不要慌,我们设置一下代理IP,再换个UA,伪装一下再去请求,可是在换了数个代理IP之后,并且不管是用代码还是用浏览器正常请求返回的永远是
没事requests 请求不行,我用selenium试试,还是不行,再换手机试试,结果还是一样无法访问,现在开始慌了,难道一行代码就把美团服务器干趴了

再经过几个设备测试,可以确定只是我的电脑被美团ban掉了,可是怎么连我的手机也不行,难道是因为同一个Wi-Fi还是登陆了同一个账号

那最后是怎么解决的,三个字:慢慢来
◆ ◆ ◆ ◆ ◆
长按二维码关注我们
数据森麟公众号的交流群已经建立,许多小伙伴已经加入其中,感谢大家的支持。大家可以在群里交流关于数据分析&数据挖掘的相关内容,还没有加入的小伙伴可以扫描下方管理员二维码,进群前一定要关注公众号奥,关注后让管理员帮忙拉进群,期待大家的加入。
管理员二维码: