
虚拟试衣:GAN的落地应用挑战之一
点击上方“机器学习与生成对抗网络”,关注星标
获取有趣、好玩的前沿干货!
背景
近年来,在线购物需求不断增长。尽管网购能提供一些便利,但消费者也关心网购所买的服装真正在他们身上穿上去时效果如何。因此,能让消费者虚拟地试穿衣服,无疑极大地改善购物体验,也能为零售商节省成本。因此,一些公司开发了各种虚拟试衣间/镜子。但是,其背后的关键在于使用了3D人体形状等相关测量值,这些测量值可以由深度相机捕获;尽管这些3D建模技术可实现逼真的服装模拟,但安装硬件和收集3D带注释的数据有着高昂成本,这也限制了它们的大规模部署应用。
而基于普通的RGB图像来完成虚拟试穿的方法,目的如前所述,将产品衣服图像无缝地覆盖在人的相应身体区域上,以此达到逼真的试穿效果。不难看出,合成图像需要满足以下需求:(1)人的身体部位、姿势与原始图像相同;(2)待试穿衣物需要根据人的姿势和形状做出一定自然的变形;(3)虚拟试穿后,新衣服的纹理图案包括颜色等低级特征、绣花或徽标等复杂图形不应受到影响。其中涉及的变形和遮挡在没有3D信息的情况下,无疑是巨大挑战。
今天介绍一篇较早使用GAN进行虚拟试衣的论文,后续很多改进论文均是基于它之上所展开的。

1 VITON: An Image-based Virtual Try-on Network
VITON一种基于图像的虚拟试穿网络,无需借助任何3D信息。基于由粗到细的策略,将试穿服装无缝地迁移到人的相应身体区域上。
VITON的输入是与服装无关的描述性人物表征。方法首先会生成粗略的合成图像,再通过细化网络进一步扩大和精修服装的模糊区域。该工作还收集了Zalando数据集。
1.1 VITON方法的输入
虚拟试穿的主要挑战是使试穿服装有恰当的变形去匹配人的姿势,从而达到一种从视觉上看像是人真正地穿上该服装所拍出来的照片一般的效果。
VITON引入了“试穿衣服无感知”(可以穿上任意而不是非特定款式的衣服)的人体表征,包括的特征有:姿势、身体部位、脸部和头发,以此作为输入条件来约束试穿图像的生成过程。

姿势热图(Pose heatmap)。人体姿势的变化会带来身上服装的变形,使用姿势估计算法显式地建模姿势信息,它是通过18个关键点的坐标来表示的。为了利用其空间布局信息,每个关键点都将进一步转换为热图,关键点周围的11×11邻域在其他位置填充为1和0,所有关键点热图被拼接成一个18通道的姿势热图。
人体表征(Human body representation)。虚拟试衣也需要知道身体不同部位(例如手臂或躯干)的形状和位置。首先使用人体解析或者分割算法来得到人体的分割图,其中不同的区域代表人体的不同部位,例如手臂、腿等。将分割图进一步转换为1通道二进制掩码,其中1表示人体(不包括脸和头发),其他表示0。
面部和头发部分(Face and hair segment)。为了保持人的身份信息不变(小明还是小明),需要结合诸如脸部、肤色、发型等属性。同样地,也提取人脸和头发区域的RGB通道,以便在生成新图像时注入这种脸部表示的身份信息。
最后,将上述三个特征图的大小调整为相同分辨率,并将它们拼接起来以形成“试穿衣服无感知”的表示形式,用p表示(p∈R^m×n×k),其中m = 256和n = 192表示特征图的高度和宽度,而k = 18 +1 + 3 = 22表示通道数。以这种表示作为输入,好处是包含了试穿人的大量信息,便于通过卷积来对其中的复杂关系进行建模学习。
1.1 VITON的生成器
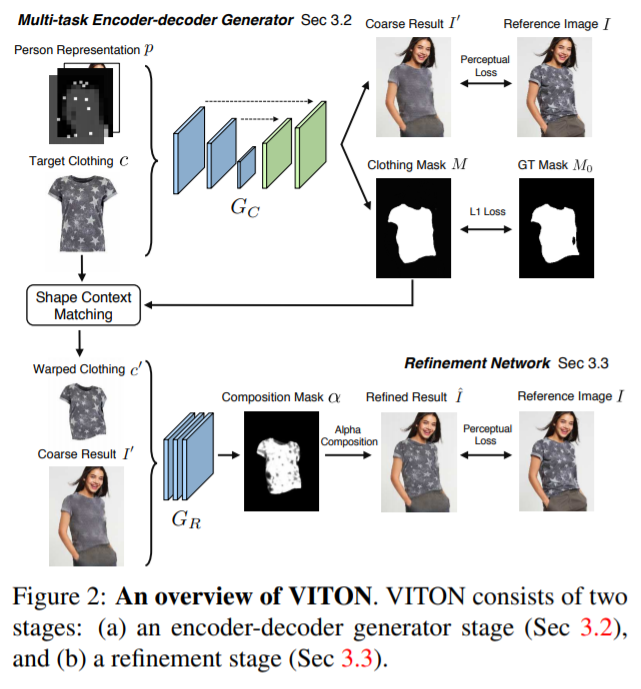
基于编码器/解码器的多任务生成器。给定与服装无关的人体信息表示p和服装图像c,通过重构来合成参考图像I,从而学习到从c到p对应区域的自然迁移。这是利用一个多任务编码器-解码器网络完成,它可以生成穿衣的人像以及该人的衣服掩膜。除了引导网络专注于服装区域之外,还将进一步使用预测的服装掩膜来细化所生成的结果。编码器-解码器基于U-net网络结构,具有跳跃连接共享层之间的信息。
具体地,使用Gc表示由这个编码器-解码器构成的生成器,它以c和p作为输入,生成4通道的输出:(I',M)= Gc(c,p),其中前3个通道代表合成图像I',最后一个通道M代表分割掩膜。目的在于该生成器通过学习使输出的I'接近参考图像I,M接近M0(M0是人为通过其它分割算法获取的的服装掩膜)。
一种简单的方法是使用L1损失训练网络,当目标是二进制掩码(M0)时,这会产生不错的结果。但对于彩色图像,L1损失会产生模糊的现象,所以采用感知损失。感知损失计算的是合成图像和真实图像特征图之间的距离。
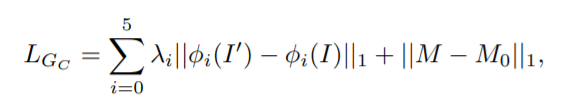
- 其中第一项中的φi(y)是对图像y进行感知计算时,所用的特征提取网络φ中第i层的特征图(一般用在ImageNet上预训练的VGG19网络)。对于第i> 1层,使用VGG模型的“conv1_2”,“conv2_2”,“conv3_2”,“conv4_2”,“conv5_2”,而对于第0层,直接使用RGB像素值。超参数λi控制第i层对总损失的贡献。
1.2 VITON的细化网络
VITON中的细化网络G_R进一步细化渲染生成图像的细节,以增加真实的视觉感。通过直接从目标服装图像c中借用信息,对上一阶段所生成的粗糙区域进行细节填充。
考虑到,衣服会根据人的姿势和身体部位的形状有变形,因此,如下图所示,通过薄板样条(thin plate spline,TPS)变换来扭曲服装。
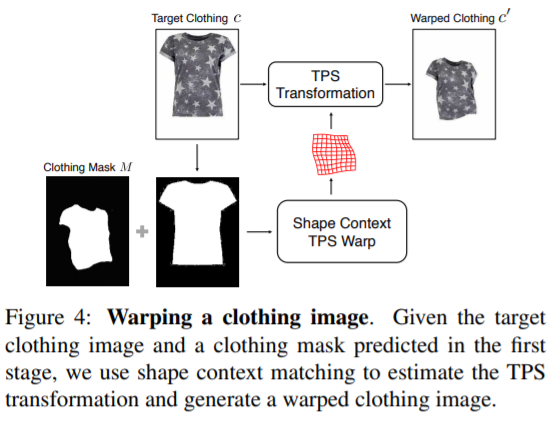
- 合成学习阶段,需要完成的是:将已做合适扭曲的衣服c'在粗略的合成图像I'的对应区域上进行无缝结合,还要在手臂或头发位于身体前方的情况下有良好的处理。细化网络正是完成这一“组合”过程:首先将c'和粗略输出I'连接起来,作为网络输入;然后生成单通道的掩模α∈(0,1)^m×n。所生成的掩膜的意义是指出衣服c'和粗糙图像I'分别各应该利用多少信息,即最终虚拟试穿的效果输出是c'和I的组成:
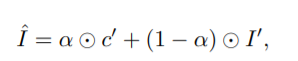
- 其中⊙表示逐元素矩阵乘法。为了学习最佳的构图掩膜,也采用感知损失最小化生成结果和参考图像I之间的差异:
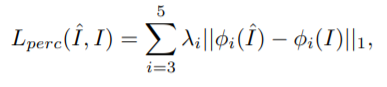
类似地,φ表示用视觉感知距离计算的特征提取网络VGG19。在这里,仅使用“conv3_2”,“conv4_2”,“conv5_2”来计算此损失。由于视觉感知计算的特征网络在低层(“conv1”和“ conv2”)更多关注图像的像素级细节信息,因此I和ˆI之间的较小位移将导致特征之间的较大差距,但是这种差距在虚拟试穿应用中可以接受。因此,仅使用较高的层。
进一步使用L1和total-variation(TV)损失来正则化所生成的掩膜:
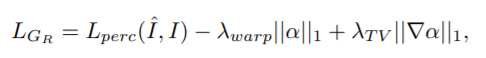
其中λwarp和λTV分别表示L1和TV的权重。最小化负L1项会促使模型去利用更多关于服装图像的信息,来得到更多的细节。||∇α|| 1则惩罚生成的合成蒙版α的梯度,以使其在图像空间上的过渡更加自然平滑。
下图展示了不同步骤中生成的结果。给定目标衣服和人体表征,编码器-解码器会产生粗糙的结果,它保留着人体原来的姿势、形状和面部,但衣物上的图形和纹理等细节则丢失了。基于所生成的服装掩膜,细化阶段使目标服装图像变形,并得到构图的掩膜,以确定应该在粗糙的合成图像中替换哪些区域。

1.3 VITON的实验数据
- 从网站www.zalando.de上收集数据集Zalando。首先抓取了大约19,000个正面视图的女性图像和上衣图像对,通过数据清洗得到16,253对。进一步分为分别为14,221和2,032对的训练集和测试集。
2 LA-VITON: A Network for Looking-Attractive Virtual Try-On
LA-VITON也是一种基于图像的虚拟试穿网络,主要由两个模块组成:几何匹配模块(Geometric Matching Module)和试穿模块(Try-On Module,TOM)。--- (未完待续。
猜您喜欢:
附下载 |《TensorFlow 2.0 深度学习算法实战》