
在 Go 中对依赖图进行排序
最近,我在思考在软件工程中遇到的许多重要问题可以归结为几个简单的问题。只要看看任何关于算法的书,其中的大部分都会是排序或搜索集合的一些变体。谷歌的存在是因为“哪些文档包含这些短语?”是一个真正难以解决的问题(好吧,这极大地简化了 Google 产品的庞大范围,但基本思想仍然成立)。
01 什么是拓扑排序?
在我的职业生涯中,我一次又一次遇到的常见问题之一就是对依赖图的节点进行拓扑排序。换句话说,给定一些有向无环图 — 想想可以依赖于其他软件包或大型公司项目中的任务的软件包 — 对它们进行排序,以便列表中的任何项目都不会依赖于列表中后面出现的任何内容。假设我们正在制作蛋糕,在开始之前,我们需要一些原料。让我们来简化一下,说我们只需要鸡蛋和面粉。嗯,要吃鸡蛋,我们需要鸡(相信我,我在这里不是开玩笑),要吃面粉,我们需要谷物。鸡也需要谷物作为饲料,谷物需要土壤和水才能生长。我们考虑表达所有这些依赖关系的图表:
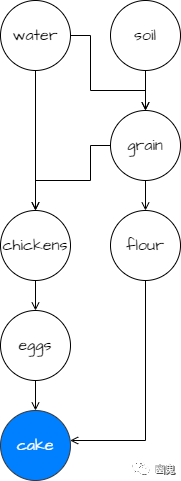
该图的一种可能的拓扑顺序是:
[]string{"soil", "water", "grain", "chickens", "flour", "eggs", "cake"}
但是,还有其他可能的拓扑顺序:
[]string{"water", "soil", "grain", "flour", "chickens", "eggs", "cake"}
我们也可以把面粉放在鸡蛋后面,因为唯一依赖鸡蛋的就是蛋糕。由于我们可以重新排列项目,我们还可以并行完成其中一些项目,同时保持任何项目都不会出现在依赖于它的任何东西之前。例如,通过添加一层嵌套,我们可以表明内部切片中的所有内容都独立于该切片中的其他任何内容:
[][]string{
{"soil", "water"},
{"grain"},
{"chickens", "flour"},
{"eggs"},
{"cake"},
}
从这个图中,我们得到了一个很好的“执行计划”,用于为蛋糕准备依赖项。首先,我们需要找到一些土壤和水。接下来,我们种植谷物。然后,我们同时养一些鸡和做面粉,收集鸡蛋。最后,我们可以做蛋糕了!对于小于四岁的人来说,这似乎是一项艰巨的工作,但好的事情需要时间。
02 构建依赖图
现在我们了解了要做什么,让我们考虑如何编写一些能够构建这种依赖项列表的代码。我们当然需要跟踪元素本身,我们需要跟踪什么取决于什么。为了使“取决于什么X?” 和“X取决于什么?” 两者都高效,我们将跟踪两个方向的依赖关系。
我们已经足够了解开始编写代码所需的内容:
// A node in this graph is just a string, so a nodeset is a map whose
// keys are the nodes that are present.
type nodeset map[string]struct{}
// depmap tracks the nodes that have some dependency relationship to
// some other node, represented by the key of the map.
type depmap map[string]nodeset
type Graph struct {
nodes nodeset
// Maintain dependency relationships in both directions. These
// data structures are the edges of the graph.
// `dependencies` tracks child -> parents.
dependencies depmap
// `dependents` tracks parent -> children.
dependents depmap
// Keep track of the nodes of the graph themselves.
}
func New() *Graph {
return &Graph{
dependencies: make(depmap),
dependents: make(depmap),
nodes: make(nodeset),
}
}
这种数据结构应该适合我们的目的,因为它包含我们需要的所有信息:节点、“依赖”边和“依赖于”边。现在让我们考虑创建用于向图形添加新依赖关系的 API。所有我们需要的是一个声明的方法,一些节点依赖于另一个,就像这样:graph.DependOn("flour", "grain")。有几种情况我们要明确禁止。首先,一个节点不能依赖于自己,其次,如果flour依赖于grain,那么grain一定不能依赖于flour,否则我们会创建一个无限的依赖循环。有了这个,让我们编写Graph.DependOn()方法。
func (g *Graph) DependOn(child, parent string) error {
if child == parent {
return errors.New("self-referential dependencies not allowed")
}
// The Graph.DependsOn() method doesn't exist yet.
// We'll write it next.
if g.DependsOn(parent, child) {
return errors.New("circular dependencies not allowed")
}
// Add nodes.
g.nodes[parent] = struct{}{}
g.nodes[child] = struct{}{}
// Add edges.
addNodeToNodeset(g.dependents, parent, child)
addNodeToNodeset(g.dependencies, child, parent)
return nil
}
func addNodeToNodeset(dm depmap, key, node string) {
nodes, ok := dm[key]
if !ok {
nodes = make(nodeset)
dm[key] = nodes
}
nodes[node] = struct{}{}
}
一旦我们实现,这将有效地为我们的图表添加依赖关系Graph.DependsOn()。我们可以很容易地判断一个节点是否直接依赖于其他某个节点,但我们也想知道是否存在传递依赖。例如,由于flour依赖于grain并且grain依赖于soil,因此也flour依赖于soil。这将要求我们获取节点的直接依赖项,然后对于这些依赖项中的每一个,获取其依赖项等等,直到我们停止发现新的依赖项。用计算机科学术语来说,我们正在计算一个固定点,以在我们的图上找到“DependsOn”关系的传递闭包。
func (g *Graph) DependsOn(child, parent string) bool {
deps := g.Dependencies(child)
_, ok := deps[parent]
return ok
}
func (g *Graph) Dependencies(child string) nodeset {
if _, ok := g.nodes[root]; !ok {
return nil
}
out := make(nodeset)
searchNext := []string{root}
for len(searchNext) > 0 {
// List of new nodes from this layer of the dependency graph. This is
// assigned to `searchNext` at the end of the outer "discovery" loop.
discovered := []string{}
for _, node := range searchNext {
// For each node to discover, find the next nodes.
for nextNode := range nextFn(node) {
// If we have not seen the node before, add it to the output as well
// as the list of nodes to traverse in the next iteration.
if _, ok := out[nextNode]; !ok {
out[nextNode] = struct{}{}
discovered = append(discovered, nextNode)
}
}
}
searchNext = discovered
}
return out
}
03 对图表进行排序
现在我们有了一个图数据结构,可以考虑如何按照拓扑顺序将节点取出。如果我们可以发现叶节点—即,节点本身对其他节点没有依赖关系—那么我们可以重复获取叶子并将它们从图中移除,直到图为空。在第一次迭代中,我们将找到独立的元素,然后在随后的每次迭代中,我们将找到仅依赖于已删除元素的节点。最终结果将是一个按拓扑排序的独立“层”节点的切片。
获取图的叶子很简单。我们只需要找到在 dependencies 中没有条目的节点。这意味着它们不依赖于任何其他节点。
func (g *Graph) Leaves() []string {
leaves := make([]string, 0)
for node := range g.nodes {
if _, ok := g.dependencies[node]; !ok {
leaves = append(leaves, node)
}
}
return leaves
}
最后一块拼图实际上是计算图的拓扑排序层。这也是最复杂的一块。我们将遵循的一般策略是迭代地收集叶子并将它们从图中删除,直到图为空。由于我们将对图进行变异,因此我们希望对其进行克隆,以便在执行排序后原始图仍然完好无损,因此我们将继续实施该克隆:
func copyNodeset(s nodeset) nodeset {
out := make(nodeset, len(s))
for k, v := range s {
out[k] = v
}
return out
}
func copyDepmap(m depmap) depmap {
out := make(depmap, len(m))
for k, v := range m {
out[k] = copyNodeset(v)
}
return out
}
func (g *Graph) clone() *Graph {
return &Graph{
dependencies: copyDepmap(g.dependencies),
dependents: copyDepmap(g.dependents),
nodes: copyNodeset(g.nodes),
}
}
我们还需要能够从图中删除一个节点和所有边。删除节点很简单,就像从每个节点删除出站边一样。然而,我们跟踪两个方向的每条边的事实意味着我们必须做一些额外的工作来删除入站记录。我们将用于删除所有边的策略如下:
在 dependents中查找节点A的条目。这为我们提供了依赖于A的节点集 。对于这些节点中的每一个,在 dependencies中找到条目。从nodeset中删除A。在 dependents中删除节点A的条目。执行逆操作,在 dependencies中查找节点A等。
借助一个允许我们从 depmap 条目中删除节点的小实用程序,我们可以编写从图中完全删除节点的方法。
func removeFromDepmap(dm depmap, key, node string) {
nodes := dm[key]
if len(nodes) == 1 {
// The only element in the nodeset must be `node`, so we
// can delete the entry entirely.
delete(dm, key)
} else {
// Otherwise, remove the single node from the nodeset.
delete(nodes, node)
}
}
func (g *Graph) remove(node string) {
// Remove edges from things that depend on `node`.
for dependent := range g.dependents[node] {
removeFromDepmap(g.dependencies, dependent, node)
}
delete(g.dependents, node)
// Remove all edges from node to the things it depends on.
for dependency := range g.dependencies[node] {
removeFromDepmap(g.dependents, dependency, node)
}
delete(g.dependencies, node)
// Finally, remove the node itself.
delete(g.nodes, node)
}
最后,我们可以实现 Graph.TopoSortedLayers():
func (g *Graph) TopoSortedLayers() [][]string {
layers := [][]string{}
// Copy the graph
shrinkingGraph := g.clone()
for {
leaves := shrinkingGraph.Leaves()
if len(leaves) == 0 {
break
}
layers = append(layers, leaves)
for _, leafNode := range leaves {
shrinkingGraph.remove(leafNode)
}
}
return layers
}
这种方法清楚地概述了我们对图进行拓扑排序的策略:
克隆图,以便我们可以对其进行转变。 反复将图的叶子收集到输出的“层”中。 收集后删除每一层。 当图为空时,返回收集的图层。
现在我们可以回到最初的蛋糕制作问题,以确保我们的图为我们解决了这个问题:
package main
import (
"fmt"
"strings"
"github.com/kendru/darwin/go/depgraph"
)
func main() {
g := depgraph.New()
g.DependOn("cake", "eggs")
g.DependOn("cake", "flour")
g.DependOn("eggs", "chickens")
g.DependOn("flour", "grain")
g.DependOn("chickens", "grain")
g.DependOn("grain", "soil")
g.DependOn("grain", "water")
g.DependOn("chickens", "water")
for i, layer := range g.TopoSortedLayers() {
fmt.Printf("%d: %s\n", i, strings.Join(layer, ", "))
}
// Output:
// 0: soil, water
// 1: grain
// 2: flour, chickens
// 3: eggs
// 4: cake
}
所有这些工作都不是小菜一碟,但现在我们有了一个依赖图,可以用来对几乎任何东西进行拓扑排序。您可以在 GitHub 上找到[1]这篇文章的完整代码。这个实现有一些明显的限制,我想挑战你改进它,以便它可以:
存储不是简单字符串的节点 允许单独添加节点和边/依赖信息 产生用于调试的字符串输出
原文链接:https://kendru.github.io/go/2021/10/26/sorting-a-dependency-graph-in-go/
参考资料
在 GitHub 上找到: https://github.com/kendru/darwin/tree/main/go/depgraph
推荐阅读