
什么神器,竟然能自动检索、修复 Python 代码 bug?
↑ 关注 + 星标 ,每天学Python新技能
后台回复【大礼包】送你Python自学大礼包
还在为不断的 debug 代码烦恼吗?

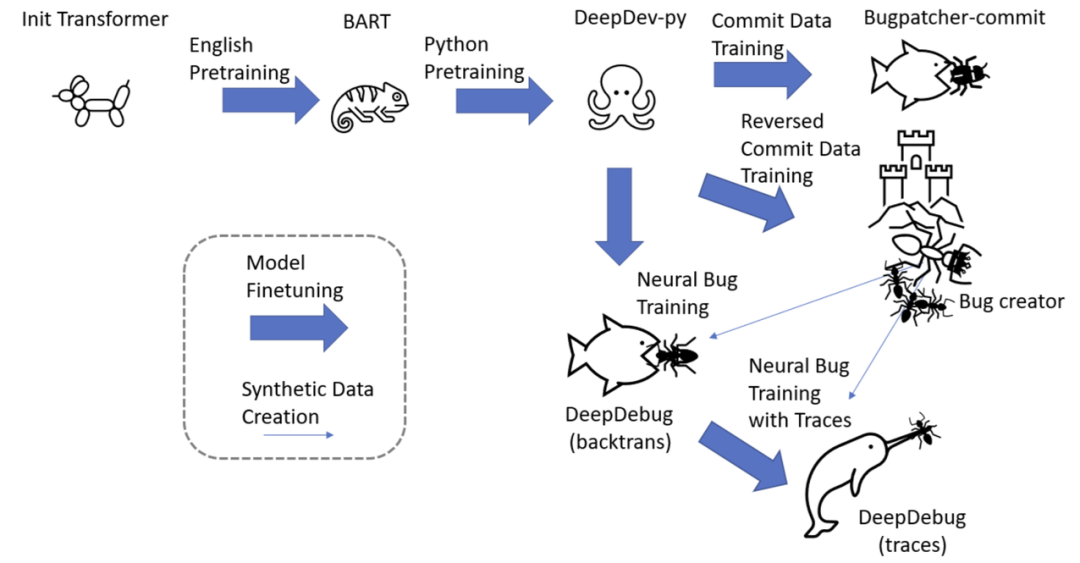
用于预训练的原始 python 代码;
用于训练神经 bug 创建和 bug 修补程序的 commit 数据;
从原始代码中提取的方法,其中插入了神经 bug 以训练更强大的 bug 修补程序;
通过可执行测试的方法。
将点访问器替换为方括号访问器;
将截断链接的函数调用;
删除返回行;
将返回值封装在元组和字典等对象中然后忘记封装对象;
将 IndexError 等精确错误替换为 ValueError 等不同的错误;
误命名变量诸如 self.result 而不是 self._result;
错误地按引用复制而不是按值复制。研究者几乎应用了以前文献中已报道的所有启发式 bug。


追踪法:除了使用测试对不正确的编辑进行分类之外,还以三种不同的方式将来自测试的信息整合到训练中:将错误消息附加到 buggy 方法中,另外附加了栈追踪,并进一步使用测试框架 Pytest 提供了故障处的所有局部变量值;
收集通过测试法:为了以训练规模收集可执行的测试,从用于预训练的 20 万个库开始,过滤到包含测试和 setup.py 或 requirements.txt 文件的 3.5 万个库。对于这些库中的每一个,都在唯一的容器中执行 Pytest,最终从 1 万个库中收集通过的测试;
合成 bug 测试法:在过滤通过可执行测试的函数并插入神经 bug 之后,重新运行测试以收集 Pytest 追踪,并滤除仍通过测试并因此实际上不是 buggy 的已编辑函数。




推荐阅读
评论