
因为一个低级错误,生产数据库崩溃了将近半个小时
昨天午休的时候,我正在工位上小憩,睡梦中仿佛看到了自己拿着李白在荣耀峡谷里大杀四方的情景,就在我刚拿完五杀准备带领队友推对面水晶的时候,一句慌乱急促的“糟了”把我从睡梦中惊醒。
我眯开朦胧的双眼,才发现刚才的发声来源于我的组长二哥,看到他在紧张的点开日志系统查看日志。
我预感到有什么不妙的事情发生,仔细一问才知道,原来就在我眯眼的期间,线上数据库服务器的 CPU 被打满,同时触发了生产数据库只读延迟的限定时间并且发出告警,而且告警的过程持续了半个小时。
这让我倒吸了一口凉气,因为我们组做的系统很多都用的是同一个数据库服务器,日用户活跃量有好几十万,如果服务器崩溃了将会使所有的系统服务都不可用。
于是我们赶紧通过 sql 日志进行问题查找,最后排查出来是因为一张 sql 的高量查询没有走索引导致,日志列表显示,这条 sql 语句的扫描行数达到了上百万,基本就是全表扫描的情况,而且半个小时的时间查询了达上万次,每条 sql 查询的耗时都在 3000ms 以上。
我的天啊,难怪服务器会 CPU 打满,这么一条耗时的 sql 语句查询量这么大,数据库的资源当然是直接就崩溃了,这是当时那条 sql 的查询情况:

看了这条语句,我又倒吸一口凉气,这不就是我写的系统调用的 sql 语句吗?完了,这回逃不掉了,真是人在睡梦里,锅从天上来。

当然,因为是我自己写的 sql,所以我一看就知道这条语句是有问题的。
根据我的代码处理,这条 sql 的调用还少了个重要的参数 user_fruit_id,这个参数没有传的话是不应该走这条 sql 查询的,在我的设计里,该参数是数据表里一个联合索引的最左侧字段,如果该字段没有传值的话,那么索引就不会生效了。
KEY `idx_userfruitid_type` (`user_fruit_id`,`task_type`,`receive_start_time`,`receive_end_time`) USING BTREE
虽然定位到了 sql 语句,但是线上的问题刻不容缓,总不可能找出 bug 改完再上线吧,所以,我们只能做了一个临时处理,就是在原来的表上多加了一个联合索引,其实就是去掉了 user_fruit_id 字段,让这些高量的查询都能走新的索引,就像下面这样。
KEY `idx_task_type_receive_start_time` (`task_type`,`receive_start_time`,`receive_end_time`,`created_time`) USING BTREE
加上索引后,sql 的扫描行数就大幅度的降低了,重启实例后就又能正常运行了。
那么为什么最左侧的字段没传索引就不生效了,这是因为 MySQL 的联合索引是基于“最左匹配原则”匹配的。
我们都知道,索引的底层是 B+ 树结构,联合索引的结构也是 B+ 树,只不过键值数量不是一个,而是多个,构建一颗 B+ 树只能根据一个值来构建,因此数据库依据联合索引最左的字段来构建 B+ 树。
例如我们用两个字段(name,age)这个联合索引来分析
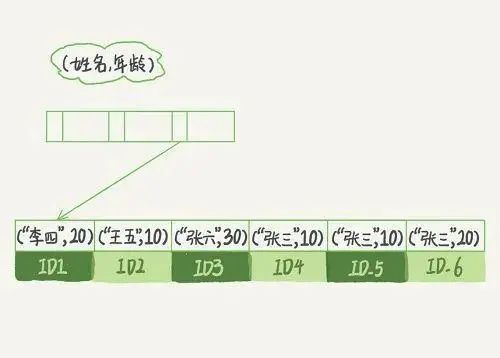
当我们在 where 条件中查找 name 为“张三”的所有记录的时候,可以快速定位到 ID4,并且查出所有包含“张三”的记录
而如果要查找“张三,10”这一条特定的数据,就可以用 name = "张三" and age = 10 获取,因为联合索引的键值对是两个,所以只要前面的 name 确定的情况下就可以进一步定位到具体的 age 记录。
但是如果你的查询条件只有 age 的话,那么索引就不会生效,因为没有匹配最左边的字段,后面所有的索引字段都不会生效,所以我之前写的 sql 语句才会因为少了最左边的 user_fruit_id 字段而走了全表扫描的查询方式。
正常来说,假设一个联合索引设计成(a,b)这样的结构的话,那么用 a and b 作为条件,或者 a 单独作为查询条件都会走索引,这种情况下我们就不要再为 a 字段单独设计索引了。
但如果查询条件里面只有 b 的语句,是无法使用(a,b)这个联合索引的,这时候你不得不维护另外一个索引,也就是说你需要同时维护(a,b)、(b) 这两个索引。
虽然临时做了处理,但问题并不算解决,很明显是系统出现了 bug 才会有走这样的查询条件。因为是我自己写的代码,所以知道是哪条 sql 后我就马上定位到了代码里的具体方法,后来才发现是因为我对 user_fruit_id 字段的判空处理不生效所致。
因为该字段是从调用方传过来的,所以我在方法参数里对该字段做了非空限制的注解,也就是 javax 包下的 @NotNull。
public class GardenUserTaskListReq implements Serializable {
虽然加上该注解来做非空校验,但我却没有在参数加上另一个注解 @Validated,该注解如果没加上的话,那么调用 javax 包下的校验规则就都不生效,正确的写法是在 controller 层方法的参数前面加上注解

除此之外,因为 user_fruit_id 这个字段是另一张表的主键,我在代码里也没有对这张表是否存在这个 id 做查询判断,这样一来,无论调用方传什么值过来都会直接触发 sql 查询,并且在不跑索引的情况下直接走全表扫描。
不得不说,这真是个低级错误,说真的,我对这个原因真是感到嘀笑皆非,再怎么说也工作几年了,怎么还犯一些新手级别的错误呢,这脸打得真是让我相当惭愧。

虽然是低级错误,但造成的后果也算挺严重了,这次事件也让我更加的警醒,在以后的开发工作中必须要遵守该有的原则,大概有这么几点:
1、不能相信调用端。重要的参数都要先做验证,即使是非空值也需要做验证,不符合条件的就要直接返回或抛异常,不能参与业务 sql 的查询,否则频繁的访问也会对服务造成负担。
2、sql 语句要先做性能查询。对于数据量大的表,建好索引后,所有的 sql 查询语句要用 explain 检测性能,并且根据结果来进一步优化索引。
3、代码必须要 review。之前我没有放太大的精力在代码的 review 上,虽说跟迭代排期的紧凑也有关系,但不管怎么说,bug 确实是我的疏忽造成的,尤其是像空值这种细小的错误在 Java 里可以说家常便饭。
千里之堤毁于蚁穴,有时一个小 bug 很容易就引发整个系统的崩盘,这一次的问题也让我更加深刻的认识到了 review 代码的重要性,不管业务开发的工作量有多麻烦,这一步操作绝对不能忽视。
知道了 bug 的原因,改完代码当天就重新发布了,后来,二哥告诉我说,为了以后让组里的其他人对此次问题有所警戒,让我写一篇问题记录总结一下,我想了一下,这不是我的强项啊,但怎么说也确实是自己的问题,还是老老实实的写一下记录好了。
我本以为这样就可以松一口气了,可二哥却突然用诡异的眼神看着我,语重心长的说,上次小北也因为线上出现问题写了报告,你这一次估计也不能例外了,可能要一万字以上。我瞬间就感觉一个雷劈到了我头上,苍天啊。。。。。。
PS:这篇文章是一个读者鄙人薛某写的,我感觉很不错,就推荐给大家读一读。
PPS:天气变凉了,洛阳的气温来到了零度左右,我已经把秋裤穿上了,毕竟这是对冬天最起码的尊重。如果是在北方的小伙伴,记得保暖,如果是在南方嘛,可以来北方体验一下冷的快乐,哈哈。