
如何写出更具有Python风格的代码
我们都喜欢 Python,因为它让编程和理解变的更为简单。但是一不小心,我们就会忽略规则,以非 Pythonic 方式编写一堆垃圾代码,从而浪费 Python 这个出色的语言赋予我们的优雅。Python 的代码风格是非常优雅、明确和简单,在 Python 解释器中执行 import this 你可以看到 Tim Peters 编写的 Python 之禅:
>>> import this
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
这里我找了目前最好的中文版本:
美 优于 丑
明确 优于 隐晦
简单 优于 复杂
复杂 也好过 繁复
扁平 优于 嵌套
稀疏 优于 拥挤
可读性很重要
固然代码实用与否 比洁癖更重要,
我们以为的特例也往往没有特殊到必须打破上述规则的程度
除非刻意地静默,否则不要无故忽视异常
如果遇到模棱两可的逻辑,请不要自作聪明地瞎猜。
应该提供一种,且最好只提供一种,一目了然的解决方案
当然这是没法一蹴而就的,除非你是荷兰人[1]
固然,立刻着手 好过 永远不做。
然而,永远不做 也好过 不审慎思考一撸袖子就莽着干
如果你的实现很难解释,它就一定不是个好主意
即使你的实现简单到爆,它也有可能是个好办法
命名空间大法好,不搞不是地球人!
[1]:本文作者 Tim peters 解释说这里的荷兰人指的是 Python 的作者 Guido van Rossum.
以下是用 Python 编写更好的代码的 8 种方法:
一、忘掉类 C 语言风格
如果需要打印列表中的所有元素及其索引,你想到的第一件事是:
for i in range(len(arr)):
print(i, arr[i])
那么你仍然在编写 C 代码。摆脱这一点,请牢记 Python 关键字 enumerate 。它索引列表/字符串中的所有元素,并且支持设置索引的起始编号:
>>> for index, item in enumerate(['a','b','c']):
... print(index, item)
...
0 a
1 b
2 c
>>> for index, item in enumerate(['a','b','c'],1): #这里第二个参数可以设置起始编号
... print(index,item)
...
1 a
2 b
3 c
现在看起来更好了,而且更加 Pythonic。将列表转换成字符串呢?如果你这样写:
# The C way
string = ''
for i in arr:
string += i
就是 C 风格,如果使用 Python 的关键字 join,不仅效率更高,而且更优雅:
# The Python way
string = ''.join(arr)
就像 join 一样 ,Python 有很多神奇的关键字,因此请不要为语言工作,而是使用该语言为你工作。

二、牢记 PEP8
我不是要求你完全遵循 PEP8,而是要求遵循其中的大多数规则,何况现在有很多自动格式化的工具,足以让你的代码更加美观,我们的 Python 之父也说过:阅读代码的频率远远高于写代码的频率,他是如此的正确!因此代码的可读性非常重要。
你是否对自己曾经写过的代码感到好奇?为什么这么写,这句话为什么在这?好吧,PEP8 是大多数这类问题的答案。尽管代码注释是个好方法,但是代码的风格也需要加以调整,比如变量 i , j , count 等即使第一次出现时写了注释,也不能保证后面你仍然记得住,这样来看就浪费了宝贵的时间。
任何普通的程序员都可以编写计算机可以理解的代码。只有好的程序员可以编写人类可以理解的代码。

首选 CamelCase 作为类, UPPER_WITH_UNDERSCORES 作为常量,而 lower_with_underscores 作为变量,方法和模块名称。即使使用,也要避免使用单一名称功能 lambda 。
三、善用推导式
常用的推导式有:列表推导式,集合推导式,字典推导式。先说下列表推导式。
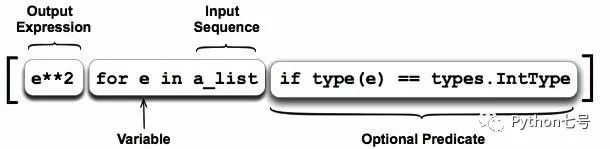
列表推导式就是当我们需要基于一个已有的列表创建新的列表时,所使用的语法格式,列表推导式包含以下四个部分:
1、一个输入序列(Input Sequence)
2、一个变量,代表着输入序列的一个成员(Variable)
3、一个可选的判定表达式,表达这个变量满足的条件(Optional Predicate )
4、一个输出序列,根据 2 和 3 生成一个输出序列(Output Expression)
比如有个列表既有数字,又有字符,现在需要计算数字的平方,并将结果放在新的列表中,如果不用列表推导式,写出的代码就是这样的:
# bad code
a_list = [1, ‘4’, 9, ‘a’, 0, 4]
squared_ints = []
for item in a_list:
if type(item) == types.IntType:
squared_ints.append(item**2)
如果使用列表推导式,只需要两行代码,非常的优雅:
a_list = [1, ‘4’, 9, ‘a’, 0, 4]
squared_ints = [ e**2 for e in a_list if type(e) == types.IntType ]
当然,如果你喜欢 map 和 filter,你还可以这样做,当时这是不推荐的,因为可读性不好:
map(lambda e: e**2, filter(lambda e: type(e) == types.IntType, a_list))
比如集合推导式的使用:
给定输入
names = [ 'Bob', 'JOHN', 'alice', 'bob', 'ALICE', 'J', 'Bob' ]
希望得到:
{ 'Bob', 'John', 'Alice' }
那么集合推导式就是:
{ name[0].upper() + name[1:].lower() for name in names if len(name) > 1 }
再比如字典推导式:
mcase = {'a':10, 'b': 34, 'A': 7, 'Z':3}
mcase_frequency = { k.lower() : mcase.get(k.lower(), 0) + mcase.get(k.upper(), 0) for k in mcase.keys() }
# mcase_frequency == {'a': 17, 'z': 3, 'b': 34}
从上面可以看出。推导式风格的代码是优雅的,人类易读的。
四、你还在显式的关闭文件吗?
如果你在写代码时仍然在显式的关闭文件,就像上图中的 programmer,你在为编程语言工作,如果你学会了使用 with 上下文管理器,那么你就是一个 Python programmer,让编程语言为你工作:
with open('filename.txt', 'w') as filename:
filename.write('Hello')
当程序退出 with 块时,文件会自动关闭。with 语句的语法格式:
with VAR as EXPR:
BLOCK
相当于:
mgr = (EXPR)
exit = type(mgr).__exit__ # Not calling it yet
value = type(mgr).__enter__(mgr)
exc = True
try:
try:
VAR = value # Only if "as VAR" is present
BLOCK
except:
# The exceptional case is handled here
exc = False
if not exit(mgr, *sys.exc_info()):
raise
# The exception is swallowed if exit() returns true
finally:
# The normal and non-local-goto cases are handled here
if exc:
exit(mgr, None, None, None)
有很多网络连接、数据库连接库都会提供 with 功能。甚至熟悉了 with 的实现机制后,可以自行实现 with 功能:
class File(object):
def __init__(self, file_name, method):
self.file_obj = open(file_name, method)
def __enter__(self):
return self.file_obj
def __exit__(self, type, value, traceback):
self.file_obj.close()
只要定义了 __enter__,__exit__方法,就可以使用 with 语句:
with File('demo.txt', 'w') as opened_file:
opened_file.write('Hola!')
五、使用迭代器和生成器
迭代器:iterator
生成器:generator
迭代器和生成器都是 Python 中功能强大的工具,值得精通。迭代器是一个更笼统的概念:任何一个对象只要它所属的类具有__next__方法(Python 2是next)和具有返回 self 的__iter__方法都是迭代器。
每个生成器都是一个迭代器,但反之不然。生成器是通过调用具有一个或多个 yield 表达式的函数而构建的,并且该函数是满足上一段对iterator 的定义的对象。
使用区别:
网络上很多技术博主都说生成器是懒人版的迭代器,比迭代器更节省内存,其实是错误的,他们都很节省内存(我会举例子)。
他们真正的区别是:当你需要一个具有某些复杂的状态维护行为的类,或者想要公开除__next__(和__iter__和__init__)之外的其他方法时,你就需要自定义迭代器,而不是生成器。
通常,一个生成器(有时,对于足够简单的需求,一个生成器表达式)就足够了,并且它更容易编写代码。
比如说计算正整数 a 到 b (b 远远大于 a)直接的平方,生成器的话就是:
def squares(start, stop):
for i in range(start, stop):
yield i * i
generator = squares(a, b)
或者:
generator = (i*i for i in range(a, b))
如果是迭代器,则是这样:
class Squares(object):
def __init__(self, start, stop):
self.start = start
self.stop = stop
def __iter__(self): return self
def __next__(self): # next in Python 2
if self.start >= self.stop:
raise StopIteration
current = self.start * self.start
self.start += 1
return current
iterator = Squares(a, b)
可以看出,迭代器写起来稍麻烦,当也更为灵活,比如你想提供一个 current 方法时,可以直接添加到 Squares 类中:
def current(self):
return self.start
从上述可以看出,迭代器并没有保存 a 到 b 之间的所有值,所有并不消耗过多的内存,这一点也可以自行测试,代码如下:
>>> from collections.abc import Iterator
>>> from sys import getsizeof
>>> a = [i for i in range(1001)]
>>> print(type(a))
<class 'list'>
>>> print(getsizeof(a))
9016
>>>
>>> b = iter(a)
>>> print(type(b))
<class 'list_iterator'>
>>> print(isinstance(b,Iterator))
True
>>> print(getsizeof(b))
48
>>> c = (i for i in range(1001))
>>> print(getsizeof(b))
48
>>> type(c)
<class 'generator'>
>>> type(b)
<class 'list_iterator'>
可以看出 b 是 iterator,c 是 generator,它们占用的内存大小是一样的。
六、善用 itertools
itertools 模块标准化了一个快速、高效利用内存的核心工具集,这些工具本身或组合都很有用。它们一起形成了“迭代器代数”,这使得在纯 Python 中有可以创建简洁又高效的专用工具。比如,如果你想要字符串中所有字符的组合或列表中数字的所有组合,则只需编写
from itertools import combinations
names = 'ABC'
for combination in combinations(names, 2):
print(combination)
''' Output -
('A', 'B')
('A', 'C')
('B', 'C')
'''
这是一个值得经常使用的标准库,更多详细功能请参考官方文档:https://docs.python.org/zh-cn/3/library/itertools.html[1]
七、善用 collections
这又是一个值得使用的标准库 collections,它提供替代内置的数据类型的多个容器,如 defaultdict、OrderedDict、namedtuple、Counter、deque 等,非常使用,而且比自己实现要安全稳定的多。比如:
# frequency of all characters in a string in sorted order
from collections import (OrderedDict, Counter)
string = 'abcbcaaba'
freq = Counter(string)
freq_sorted = OrderedDict(freq.most_common())
for key, val in freq_sorted.items():
print(key, val)
''' Output -
('a', 4)
('b', 3)
('c', 2)
'''
不多说了,看官方文档:https://docs.python.org/3/library/collections.html[2]
八、不要过度使用类
不要过度使用类。坚持用 Java 和 C ++ 的程序员会经常使用类,但是在使用 Python 时,可以在函数和模块的帮助下复用代码。除非绝对需要,否则不必创建类。
本文讲述类 8 个让你写出更好 Python 代码的方法,希望对你有所帮助。
推荐阅读:
参考资料
https://docs.python.org/zh-cn/3/library/itertools.html: https://docs.python.org/zh-cn/3/library/itertools.html
[2]https://docs.python.org/3/library/collections.html: https://docs.python.org/3/library/collections.html