
Go 程序员必须懂的分布式架构 — 世界读书日福利
大家好,我是 polarisxu。
21世纪以来,大规模分布式系统、云计算和云原生飞速发展,在短短20年间就成为各大企业信息技术基础架构的核心基石。
企业迈向分布式的根本原因包括:
移动互联网时代,各大企业每天都在和巨大的流量和爆炸性增长的数据打交道;
摩尔定律的失效,使得提升单机性能会产生很高的成本,同时网络速度越来越快,意味着并行化程度只增不减;
此外,许多应用都要求7×24小时可用,因停电或维护导致的服务不可用,变得越来越让人难以接受;
最后,经济全球化也导致了企业必须构建分布在多台计算机甚至多个地理区域的系统。
相较于单体应用或单机系统,分布式应用或分布式系统具有高性能、高可用性、容错性和可扩展性等优点。可见,未来所有的基础架构都会是分布式的。
然而分布式系统是一个相当复杂的领域,需要处理各种各样的异常,这些异常不仅难以排查和诊断,而且难以复现,这不是增加测试或采用DevOps就能解决的,有些异常是不可避免的,需要在软件架构中做取舍。
因此,想要构建一个健壮的分布式系统,必须先学习相关的基础知识,消化大量信息。
尽管学习分布式系统最好的方式是阅读大量的经典论文,但大部分关于分布式系统的资料,要么艰深太晦涩,要么散落在不计其数的学术论文中,对于初学分布式系统的从业者来说,门槛太高,学习曲线太陡峭;再加上相关知识点比较零散、不成体系,让人觉得云山雾罩、望而却步。《深入理解分布式系统》一书便可以很好地解决该问题!

而分布式系统中一个很重要的知识点就是——分区。下面就根据《深入理解分布式系统》书中所述,详细介绍分区的概念及水平分区算法。

分布式系统带来的主要好处之一是实现了可扩展性,使我们能够存储和处理比单台机器所能容纳的大得多的数据集。
实现可扩展性的主要方式之一是对数据进行分区(Partition)。
分区是指将一个数据集拆分为多个较小的数据集,同时将存储和处理这些较小数据集的责任分配给分布式系统中的不同节点。数据分区后,我们就可以通过向系统中增加更多节点来增加系统可以存储和处理的数据规模。分区增加了数据的可管理性、可用性和可扩展性。
分区分为垂直分区(Vertical Partitioning)和水平分区(Horizontal Partitioning),这两种分区方式普遍认为起源于关系型数据库,在设计数据库架构时十分常见。
图1展示了垂直分区和水平分区的区别。
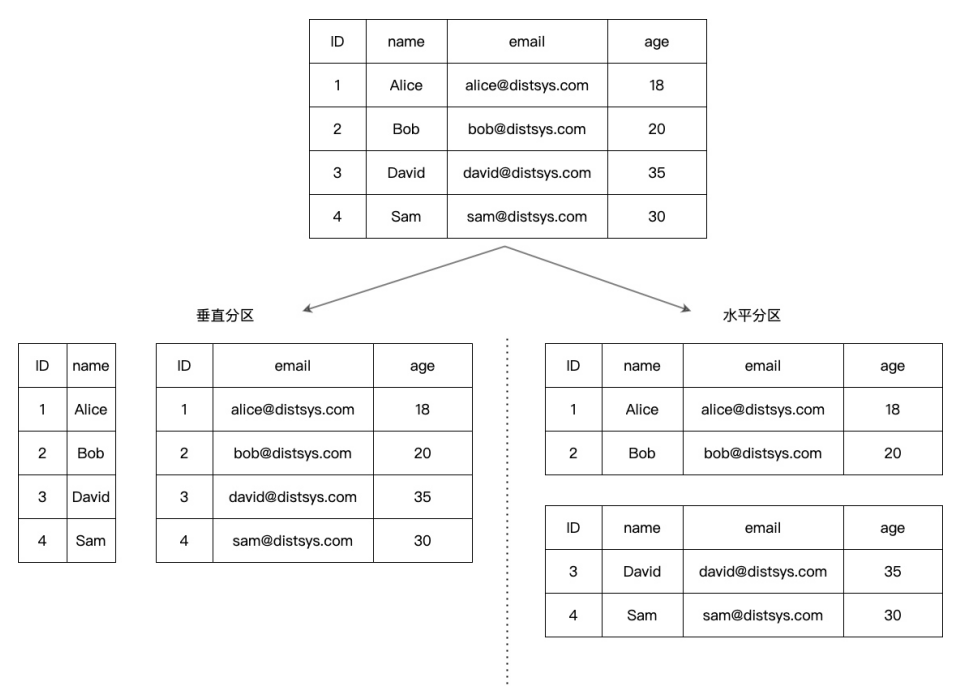
图1
垂直分区是对表的列进行拆分,将某些列的整列数据拆分到特定的分区,并放入不同的表中。垂直分区减小了表的宽度,每个分区都包含了其中的列对应的所有行。垂直分区也被称为“行拆分(Row Splitting)”,因为表的每一行都按照其列进行拆分。例如,可以将不经常使用的列或者一个包含了大text类型或BLOB类型的列垂直分区,确保数据完整性的同时提高了访问性能。值得一提的是,列式数据库可以看作已经垂直分区的数据库。
水平分区是对表的行进行拆分,将不同的行放入不同的表中,所有在表中定义的列在每个分区中都能找到,所以表的特性依然得以保留。举个简单的例子:一个包含十年订单记录的表可以水平拆分为十个不同的分区,每个分区包含其中一年的记录(具体的分区方法我们会在后面详细讨论)。
列式数据库(Column-Oriented DBMS或Columnar DBMS)也叫列存数据库,是指以列为单位进行数据存储架构的数据库,主要适用于批量数据处理和即时查询。与之相对应的是行式数据库。一般来说,行式数据库更适用于联机事务处理(OLTP)这类频繁处理事务的场景,列式数据库更适用于联机分析处理(OLAP)这类在海量数据中进行复杂查询的场景。
另外,表中数据以行为单位不断增长,而列的变动很少,因此,水平分区更常见。
在分布式系统领域,水平分区常称为分片(Sharding)。
需要说明的是,很多图书和文章会纠结分片和分区的具体区别,一种观点认为,分片意味着数据分布在多个节点上,而分区只是将单个存储文件拆分成多个小的文件,并没有跨物理节点存储。由于本书重点讨论的是分布式系统,因此无论是分区还是分片,本书都认为其数据分布在不同物理机器上。
分片在不同系统中有着各种各样的称呼,MongoDB和Elasticsearch中称为shard,HBase中称为region,Bigtable中称为tablet,Cassandra和Riak中称为vnode。
水平分区算法用来计算某个数据应该划分到哪个分区上,不同的分区算法有着不同的特性。本节我们将研究一些经典的分区算法,讨论每种算法的优缺点。
为了方便讨论,我们假设数据都是键值对(Key-Value)的组织形式,通常表示为
1. 范围分区
范围分区(Range Partitioning)是指根据指定的关键字将数据集拆分为若干连续的范围,每个范围存储到一个单独的节点上。用来分区的关键字也叫分区键。前面介绍的按年拆分表数据就是一个范围分区的例子,对于2011年到2020年这十年的订单记录,以年为范围,可以划分为10个分区,然后将2011年的订单记录存储到节点N1上,将2012年的订单记录存储到节点N2上,以此类推。
图A中的数据可以按年龄进行范围分区,将数据划分成如图2所示的分区。
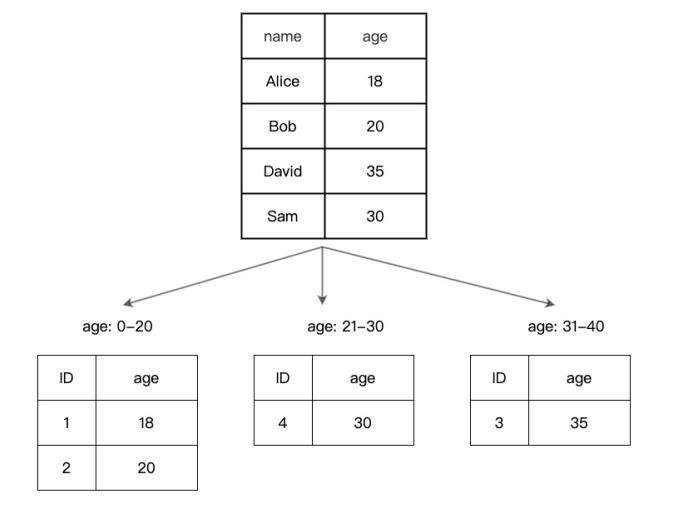
图2
如何划分范围可以由管理员设定,或者由存储系统自行划分。通常会选择额外的负载均衡节点或者系统中的一个节点来接收客户端请求,然后根据范围分区算法,确定请求应该重定向(路由)到哪个节点或哪几个节点。
范围分区的主要优点有:
实现起来相对简单。
能够对用来进行范围分区的关键字执行范围查询。
当使用分区键进行范围查询的范围较小且位于同一个节点时,性能良好。
很容易通过修改范围边界增加或减少范围数据,能够简单有效地调整范围(重新分区),以平衡负载。
范围分区的主要缺点有:
无法使用分区键之外的其他关键字进行范围查询。
当查询的范围较大且位于多个节点时,性能较差。
可能产生数据分布不均或请求流量不均的问题,导致某些数据的热点现象,从而某些节点的负载会很高。例如,当我们将姓氏作为分区键时,某些姓氏的人非常多(比如姓李或者姓王),这会造成数据分布不均。又例如前面的按年拆分订单的例子,虽然数据分布较为均衡,但根据日常生活习惯,最近一年的订单查询流量可能比前几年的查询流量加起来还要多,这就会造成请求流量不均。总的来说,一些节点可能需要存储和处理更多的数据和请求,一般通过继续拆分范围分区来避免热点问题。
使用范围分区的分布式存储系统有Google Bigtable、Apache HBase和PingCAP TiKV。范围分区适合那些需要实现范围查询的系统。
2. 哈希分区
哈希分区(Hash Partitioning)的策略是将指定的关键字经过一个哈希函数的计算,根据计算得到的值来决定该数据集的分区,如图3所示。

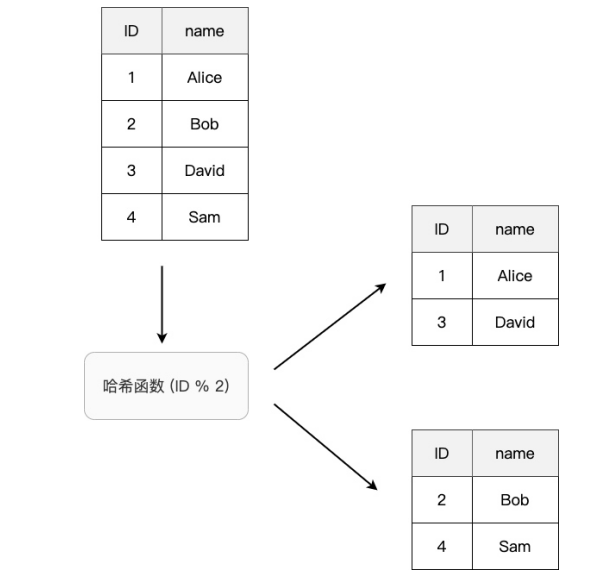
图3
哈希分区的优点是,数据的分布几乎是随机的,所以分布相对均匀,能够在一定程度上避免热点问题。
哈希分区的缺点是:
在不额外存储数据的情况下,无法执行范围查询。
在添加或删除节点时,由于每个节点都需要一个相应的哈希值,所以增加节点需要修改哈希函数,这会导致许多现有的数据都要重新映射,引起数据大规模移动。并且在此期间,系统可能无法继续工作。
3. 一致性哈希
一致性哈希(Consistent Hashing)是一种特殊的哈希分区算法,在分布式存储系统中用来缓解哈希分区增加或删除节点时引起的大规模数据移动问题。
一致性哈希算法将整个哈希值组织成一个抽象的圆环,称为哈希环(Hashing Ring)。哈希函数的输出值一般在0到INT_MAX(通常为232-1)之间,这些输出值可以均匀地映射到哈希环边上。举个例子,假设哈希函数hash()的输出值大于/等于0小于/等于11,那么整个哈希环看起来如图4所示。
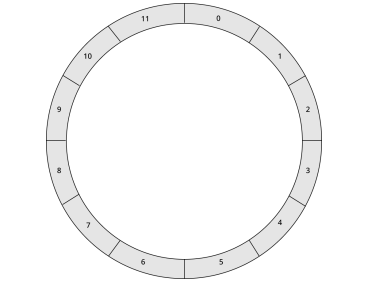
图4
接下来将分布式系统的节点映射到圆环上。假设系统中有三个节点N1、N2和N3,系统管理员可以通过机器名称或IP地址将节点映射到环上,假设节点分布到哈希环上,如图5所示。
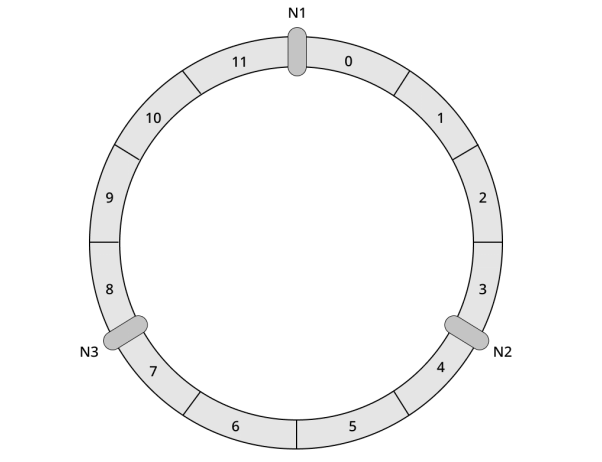
图5
接着,将需要存储的数据的关键字输入哈希函数,计算出哈希值,根据哈希值将数据映射到哈希环上。假设此时要存储三个键值对数据,它们的关键字分别为a、b和c,假设经过哈希函数计算后的哈希值分别为1、5和9,则数据映射到环上后如图6所示。
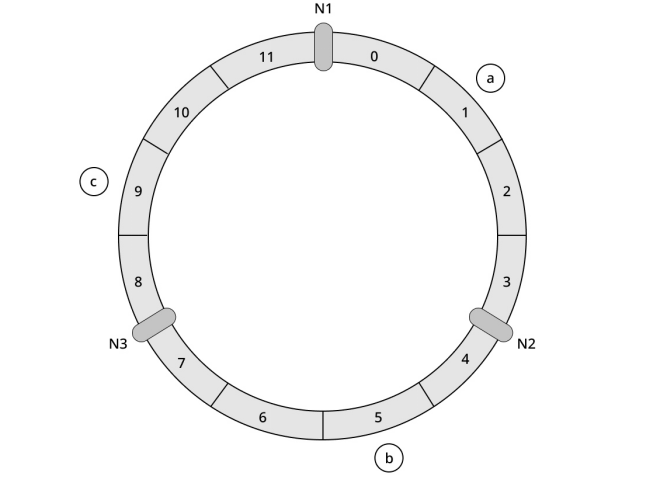
图6
那么数据具体分区到哪个节点上呢?
在一致性哈希算法中,数据存储在按照顺时针方向遇到的第一个节点上。例如图6中,关键字a顺时针方向遇到的第一个节点是N2,所以a存储在节点N2上;同理,关键字b存储在节点N3上,关键字c存储在节点N1上。数据分布方法如图7所示。
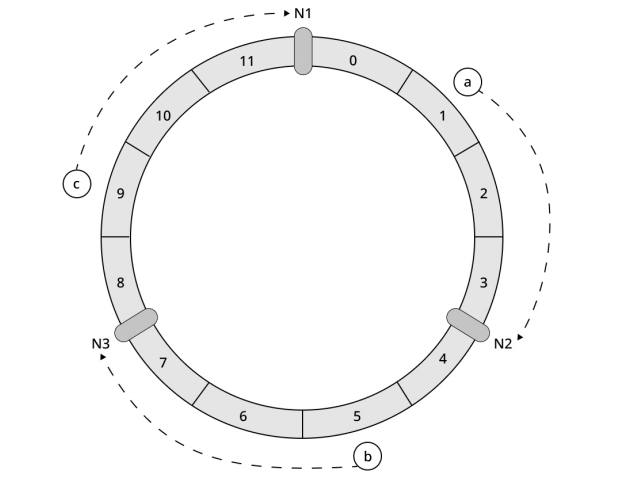
图7
接下来我们继续看一下,向集群中添加一个节点会发生什么。假设集群此时要添加一个节点N4,并添加到如图8所示的哈希环位置。那么,按照顺时针计算的方法,原本存储到节点N2上的关键字a将转移到N4上,其他数据保持不动。
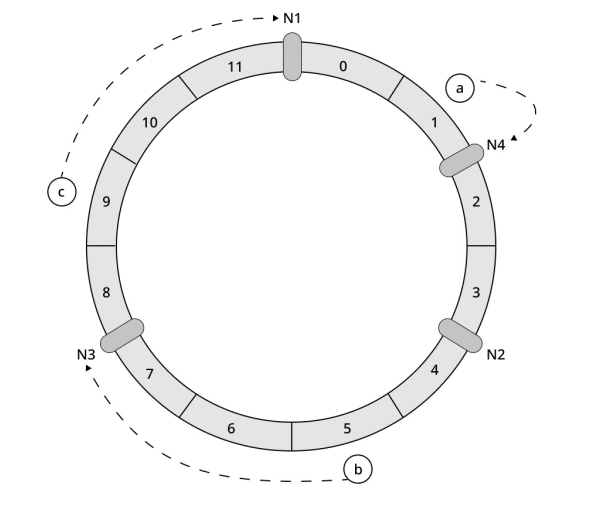
图8
可见,相比于普通的哈希分区添加或删除节点时会导致大量映射失效,一致性哈希很好地处理了这种情况。
对于添加一台服务器这种情况,受影响的仅仅是新节点在哈希环上与相邻的另一个节点之间的数据,其他数据并不会受到影响。例如图8中,只有节点N2上的一部分数据会迁移到节点N4,而节点N1和N3上的数据不需要进行迁移。
一致性哈希对于节点的增减只需要重新分配哈希环上的一部分数据,改善了哈希分区大规模迁移的缺点。此外,一致性哈希也不需要修改哈希函数,直接将新节点指定到哈希环上的某个位置即可。相比简单的哈希分区,一致性哈希有着更好的可扩展性和可管理性。
但是,一致性哈希仍然有明显的缺点,当系统节点太少时,还是容易产生数据分布不均的问题。另外,一个较为严重的缺点是,当一个节点发生异常需要下线时,该节点的数据全部转移到顺时针方向的节点上,从而导致顺时针方向节点存储大量数据,大量负载会倾斜到该节点。
解决这个问题的方法是引入虚拟节点(Virtual Node),虚拟节点并不是真实的物理服务器,虚拟节点是实际节点在哈希环中的副本,一个物理节点不再只对应哈希环上一个点,而是对应多个节点。我们假设一个物理节点要映射到哈希环中的三个点,引入虚拟节点后的哈希环如图9所示。
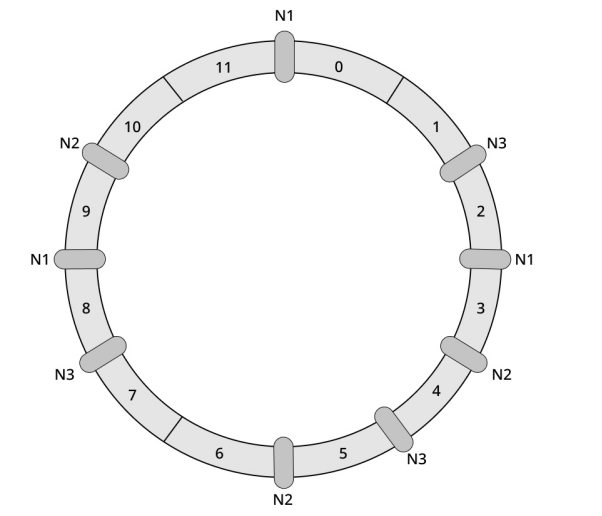
图9
可以很直观地发现,虚拟节点越多,数据分布就越均匀。当节点发生异常被迫下线时,数据会分摊给其余的节点,避免某个节点独自承担存储和处理数据的压力。
如果系统中有不同配置、不同性能的机器,那么虚拟节点也很有用。例如,系统中有一台机器的性能是其他机器的两倍,那么我们可以让这台机器映射出两倍于其他机器的节点数,让它来承担更多的负载。
不过,在不额外存储数据的情况下,一致性哈希依然无法高效地进行范围查询。任何范围查询都会发送到多个节点上。
以上内容来源于《深入理解分布式系统》一书,作者唐伟志曾工作于腾讯微信事业部,在分布式系统方面有着深入的研究。

▊ 《深入理解分布式系统》
唐伟志 著
解读经典分布式理论
分析重点分布式算法
分享分布式系统案例
本书主要讲解分布式系统常用的基础知识、算法和案例,经笔者对文献海洋中晦涩艰深的原理和算法进行提炼,辅以图示和代码,并结合实际经验进行分析总结而成。通过阅读本书,读者可以快速、轻松地掌握分布式系统的基本原理,以及Paxos或Raft共识算法,并通过典型的案例学习如何设计大型分布式系统。
本书首先介绍什么是分布式系统、分布式系统带来的挑战,以及如何对分布式系统进行建模,这部分内容偏向概念性介绍。接着介绍了分布式数据的基础知识,包括数据分区技术、数据复制技术、CAP定理、一致性模型和隔离级别,尝试厘清一些十分容易混淆的术语,比如一致性、线性一致性、最终一致性和一致性算法等。本书还介绍了分布式系统的核心算法——Paxos和Raft算法,不仅补充了大量图示进行讲解,还从零实现了一个Paxos算法。此外,本书分析了常见的分布式事务,并讨论了分布式系统中的时间问题,整理了一些实际发生的编程陷阱。最后结合一些对工业界产生重大影响的论文或开源系统,学习前人在设计大型分布式系统时的思路、取舍和创新。
(扫码了解本书详情)

该书的涉及具体语言时,使用 Go 描述或实现的。 福利时间 今日世界读书日,送给粉丝该书 5 本。 赠送规则:老规矩,留言聊聊 Go 的那些事(留言太随意,中奖概率会降低),
根据点赞数取前 10 位,同时结合过往对本公众号的支持(留言、转发、点赞、
在看等),从中选出 5 位送出。
开奖时间:2022年4月27日9点。
也欢迎大家购买支持