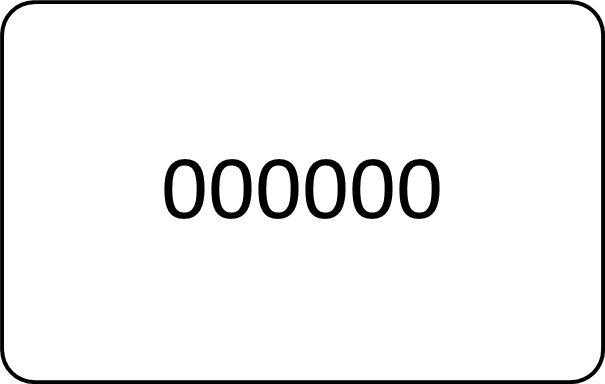导读:数据与数据应用中的许多概念彼此有着千丝万缕的联系,同时也有着概念上的偏重与区别,这里先从数据应用领域中的常见概念聊起。

有不少朋友脑子里可能会直接冒出一个词“数字”——“数字就是数据”,我相信会有一些朋友斩钉截铁地说。一些朋友会在稍作思考后回答“数字和字符、字母,这些都是数据”。不知道你现在是不是正在纠结哪个回答更正确,亦或第二个回答更合理一些,我们先放一放。先看下面这组例子:也许你可能会问,“这到底是什么意思?”不错,这就是我们在认识数据的过程中存在的一个很要命的问题,几乎在我们出发时就拦住了我们的去路。我们回过头再想想刚才的问题可能会得到比较令自己和他人信服的回答:“承载了信息的东西”才是数据,换句话说,不管是石头上刻的画,或者是小孩子在沙滩上歪歪扭扭写出的字迹,或者是嬉皮士们在墙上的涂鸦,只要它表达一些确实的含义,那么这种符号就可以被认为是数据。而没有承载信息的符号就不是数据。这个观点似乎看上去要比前面的回答理性得多,也科学得多,但是这个观点真的不需要补充了吗?我们假设这两个例子都有一些比较特殊的场景,假设第一组里出现的6个0其实是时分秒的简写,000000表示00点00分00秒,而如果写作112349则表示11点23分49秒,那么它是不是也是数据呢?假设第二组出现的4个1和2个a其实是一组密码,4个1代表一个被约定的地点,aa代表一种被约定的事件,那这组数字和字母的意义也有了相应的解读,那么它是不是也是数据呢?不难看出,一些符号如果想要被认定为数据,那就必须承载一定的信息。而信息很可能是因场景而定,因解读者的认知而定,所以一些符号是不是可以被当做数据,有相当的因素是取决于解读者的主观视角的。不知道这个观点你是不是认可,总之这点很重要。说到这里,我的同事娟娟非常认真且煞有介事地跟我说:“我觉得数字、字母、图像,这些都是数据,跟信息不信息的没什么关系。”看着她认真地跟我抬杠,我觉得蛮好,至少在认识数据过程中积极思考只有好处。信息一词,在没有学术背景的情况下其实有着很多解释,例如,广播中的声音、互联网上的消息、通讯系统中传输和处理的语音对象、甚至是小区和校园的消息看板,也就是人类社会传播的一切内容。1948年,数学家香农(Claude Elwood Shannon)在题为《通信的数学理论》的论文中指出:“信息是用来消除随机不定性的东西”。这句话如果举个例子说明,大概可以想象这样一个场景。
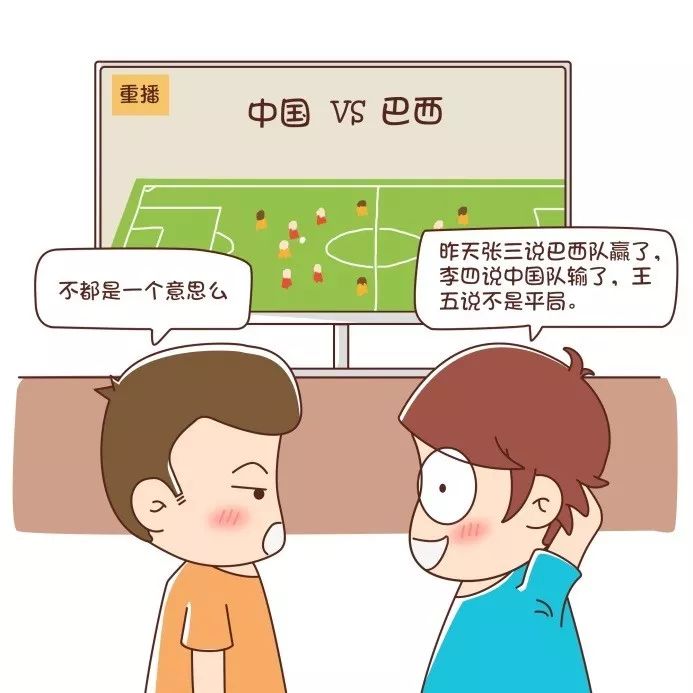
我说了两句话:“我今年33岁。”“我明年34岁。”那么第一句话如果是为了对不了解我的人介绍我的年龄的话而可以算作信息的话,第二句话则不是信息。至少你会觉得说了第一句以后,后面这句简直就是废话,因为这个从第一句话完全可以推导出来。前提是只要他们都是说实话的人,那么对于我来说,也就只有张三的话能算信息,李四和王五说的则不能算作信息。甚至连张三说的“昨天巴西队赢了”这句话是否能够被算作信息,我们都要表示怀疑,因为这也有点“废话”的意味——但凡对足球运动有点认识的人都几乎可以认定,即便你不告诉我昨天巴西队赢了,我也能猜个八九不离十,因为可能性实在是太大太大了,大到几乎是一定的,几乎是毋庸置疑的。国足的粉丝们请放下手中的臭鸡蛋和烂西红柿,听我把例子讲完。现在对信息是什么清晰多了吧?我们可以粗略地认为,信息就是那些把我们不清楚的事情阐明的描述,而已经明确或者知晓的东西让我们再“知晓”一遍,这些被知会的内容就不再是信息了。这个概念是很有用的,我们后面在讲信息论的时候也会再做定量的说明,现在只做一个定性的了解。数据和信息是我们在数据挖掘和机器学习领域天天要打交道的基础,也是我们研究的主要对象。所以对数据和信息有个比较一致性的认识对后面咱们讨论问题是非常有好处的。算法这个名称大家应该不陌生,如果你是一个信息相关专业的本科学生,至少在本科一年级或者二年级就接触过不少算法了。随便打开一个人力资源网站去搜索“算法工程师”,好的算法工程师的年薪能到三五十万甚至上百万。算法是什么?算法可以被理解为“计算的方法和技巧”,在计算机中,算法大多数指的就是一段或者几段程序,告诉计算机用什么样的逻辑和步骤来处理数据和计算,然后得到处理的结果。科班出身的信息相关专业的朋友看到这里就会觉得比较亲切了,经典的算法有很多,如“冒泡排序”算法,这几乎是所有学习高级语言和“数据结构”课程的入门必学;再如“八皇后问题”算法,这几乎也是在讲穷举计算时的经典保留算法案例(就是在国际象棋棋盘上放8个能够横、竖、斜无限制前进的皇后,让它们之间互相不能攻击,求有多少种解);以及MD5算法、ZIP2压缩算法等各种不胜枚举的算法。下图所示为八皇后问题的一组解,经过穷举是可以求出所有92组解的。应该说算法是数据加工的灵魂。如果说数据和信息是原始的食材,数据分析的结论是菜肴,那么算法就是烹调过程;如果说数据是玉璞,数据中蕴含的知识是价值连城的美碧,那么算法就是玉石打磨和加工的机床和工艺流程。算法在高级语言发展了很多年之后,更多地被封装成了独立的函数或者独立的类,开放接口供人调用,然而算法封装得再好也是不能不假思索地使用就能获益的东西,要知道,这些封装只是在一定程度上避免了重复发明轮子而已。大家不要以为算法全都是算法工程师的事情,跟普通的程序员或者分析人员无关,算法说到底是对处理逻辑理解的问题。
《孙子兵法·作战篇》有云,“不尽知用兵之害者,则不能尽知用兵之利”,意思是说,不对用兵打仗的坏处与弊端进行充分了解同样不可能对用兵打仗的好处有足够的认识。算法的应用是一个辩证的过程,不仅在于不同算法间的比较和搭配使用有着辩证关系,在同一个算法中,不同的参数和阈值设置同样会带来大相径庭的结果,甚至影响数据解读的科学性。这一点请大家务必有所注意。
统计、概率、数据挖掘,这几个词经常伴随出现,尤其是统计和概率两个概念,几乎就像自然界的伴生矿一样分不了家,有很多出版社都出版过叫做《概率统计》的书籍。本文不准备从学术的角度对统计和概率做严格的区分,在平时工作中用的统计大多为计数功能,如在使用Excel时会用到COUNT、SUM、AVERAGE等统计函数;如软件开发中,在用SQL语言对数据库的某些字段进行计数(count)、求和(sum)、求平均(avg)等函数。而概率的应用大多则是根据样本的数量以及占比得到“可能性”和“分布比例”等描述数值。当然,概率的用法远不止这些,在数据挖掘中同样用到大量概率相关的算法。数据挖掘这个词很多时候是和机器学习一起出现的,现在网上对这两个词的关系也是莫衷一是。有的说数据挖掘包含机器学习,有的说机器学习是数据挖掘发展的更高阶段。在笔者看来,数据挖掘和机器学习这样的词汇命名应该是信息科学自然进化和衍生出来的,带有一定的约定俗成的色彩,人们的看法见仁见智也在情理之中。首先我认为没有必要一定要给两个词汇划一个界限,或者一定要对它们做严格的概念区分,因为区分的标准到目前本就没有科学而无争议的界定,况且能不能分清一个算法属于数据挖掘的范畴还是机器学习的范畴对于算法本身使用是没有任何影响的,这两个词大家如果想听解释的话,不妨只从字面意思去理解就已经足够了。数据挖掘——首先是有一定量的数据作为研究对象,挖掘——顾名思义,说明有一些东西并不是放在表面上一眼就能看明白,要进行深度的研究、对比、甄别等工作,最终从中找到规律或知识,“挖掘”这个词用得很形象。机器学习——先想想人类学习的目的是什么,是掌握知识,掌握能力,掌握技巧,最终能够进行比较复杂或者高要求的工作。那么类比一下机器,我们让机器学习,不管学习什么,最终目的都是让它独立或至少半独立地进行相对复杂或者高要求的工作。这里提到的机器学习更多是让机器帮助人类做一些大规模的数据识别、分拣、规律总结等人类做起来比较花时间的事情。但是请注意,与数据挖掘一起出现的这个机器学习概念和我们说的“人工智能”还是相差甚远,因为这里面对“智能”的考究程度实在是太低了。另一个经常和大数据一起出现的词汇是商业智能,也就是我们平时简称的BI(Business Intelligence)。商业智能——业界比较公认的说法是在1996年最早由加特纳集团(Gartner Group)提出的一个商业概念,通过应用基于事实的支持系统来辅助商业决策的制定。商业智能技术提供使企业迅速分析数据的技术和方法,包括收集、管理和分析数据,将这些数据转化为有用的信息。如果这个书本式的概念读起来还是比较费解,那么就听一个形象的比喻。公司在日常运营过程中是需要做很多决策的,无时无刻都存在于公司的各个方面,而决策不管是股东大会讨论还是企业领导、部门领导直接发布行政命令,最终可能是很多因素共同影响做出的结果,无论其来自主观还是客观。这些决策可以如何得出呢?可以由领导直接凭经验决定;可以群策群力开会决定;可以问询行业专家;甚至可以找个算卦先生来占卜……从概念来说都是属于辅助决策。而显然,我们都期望不论最终是如何做出的这些决策和命令,它们都应该是更为理性、科学、正确的。
但是如何帮助他们做出更为理性、科学、正确的决策呢?商业智能整体就是研究这样一个课题,到目前为止,业界普遍比较认可的方式就是基于大量的数据所做的规律性分析。因而,市面上成熟的商业智能软件大多都是基于数据仓库做数据建模和分析,以及数据挖掘和报表的。可以说,商业智能是一个具体的、大的应用领域,也是数据挖掘和机器学习应用的一个天然亲密的场景。而且商业智能这个解决问题的理念其实不仅仅可以应用于商业,还可以应用于国防军事、交通优化、环境治理、舆情分析、气象预测等。小结
数据的认识和数据的应用是大数据与机器学习的基础,数据、信息、算法、概率、数据挖掘、商业智能,这些是大数据最为核心的基础概念与要素。当我们对这些概念有了清楚的认识,并能够清楚说出这些概念之间的辩证关系时,我们就已经在数据大门的里面了,怎么样,是不是很简单?
关于作者:高扬,金山软件西山居资深大数据架构师与大数据专家,有多年编程经验和多年大数据架构设计与数据分析、处理经验,目前负责西山居的大数据产品市场战略与产品战略。专注于大数据系统架构以及变现研究。擅长数据挖掘、数据建模、关系型数据库应用以及大数据框架Hadoop、Spark、Cassandra、Prestodb等的应用。卫峥,西山居软件架构师,多年的软件开发和架构经验,精通C/C++、Python、Golang、JavaScript等多门编程语言,近几年专注于数据处理、机器学算法的研究、应用与服务研发。尹会生,西山居高级系统工程师。曾任新浪研发中心技术经理、北京尚观科技高级讲师。擅长企业集群解决方案和内核调优经验,并提供高性能和高可用性集群咨询服务。近4年专注于Hadoop集群、Spark集群在推荐系统和BI相关领域的解决方案。万娟,星盘科技有限公司UI设计师平面,对VI设计、包装、海报设计等、商业插画、App交互、网页设计等有独到认识。多次参与智能家居和智能音箱等项目的UI设计。多次参加国际和国内艺术和工业设计比赛,并获奖。从小酷爱绘画,理想是开一个属于自己的画室。本文摘编自《白话大数据与机器学习》,经出版方授权发布。
推荐语:以降低学习曲线和阅读难度为宗旨,重点讲解了统计学、数据挖掘算法、实际应用案例、数据价值与变现,以及高级拓展技能,清晰勾勒出大数据技术路线与产业蓝图。读书 | 书单 | 干货 | 讲明白 | 神操作 | 手把手大数据 | 云计算 | 数据库 | Python | 爬虫 | 可视化AI | 人工智能 | 机器学习 | 深度学习 | NLP5G | 中台 | 用户画像 | 数学 | 算法 | 数字孪生