
深入理解MySQL底层架构,看这一篇文章就够了!
前面我们已经讲解了,我们的系统是如何与MySQL打交道的?,我们开发的系统与MySQL本身,都维护的有线程池,管理了所有连接。看下图回顾下:
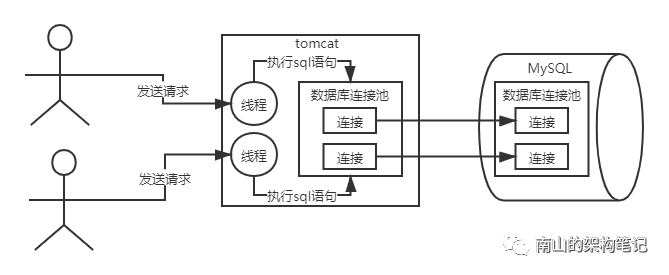
图1 我们的系统是如何与MySQL打交道的?
从上图我们可以看到,我们通过数据库连接,把要执行的SQL语句发送给MySQL数据库进行增删改查就可以了。
然而MySQL数据库内部到底是怎么运转的呢?
1、网络连接让工作线程去具体执行
一般,网络服务器会分配一个线程或线程池去处理网络连接,把网络连接中读取出来的数据交给另外的线程或线程池处理。如下图所示:
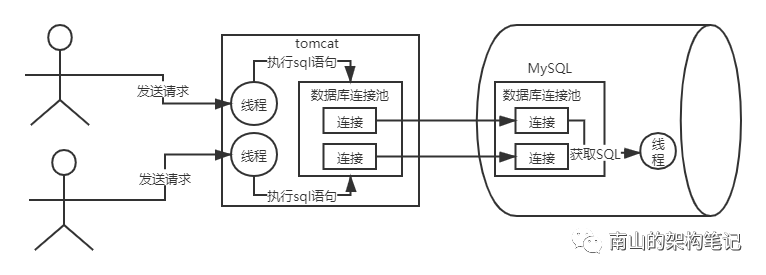
图2 多线程处理网络请求数据
当MySQL内部的工作线程从一个网络连接中读取一个SQL语句后,此时会如何处理这个SQL呢?
2、SQL接口,处理接收到的SQL语句
此时工作线程会把接收到的SQL语句交给一个叫SQL接口的组件执行。SQL接口(SQL interface),是一套执行SQL语句的接口,专门用于执行我们发送给MySQL的那些增删改查的SQL语句。
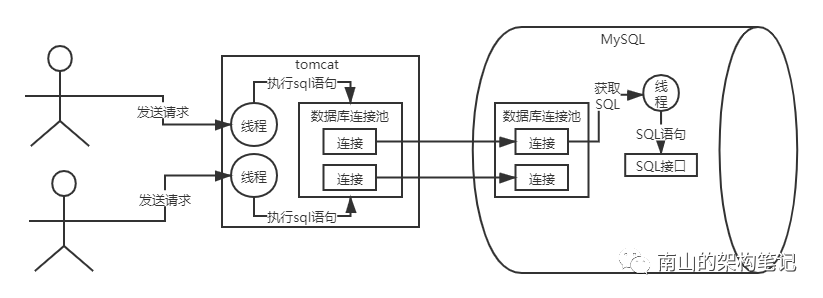
图3 SQL接口
3、查询解析器:让MySQL读懂你的SQL
接下来SQL接口怎么处理SQL语句呢?MySQL必须理解你的SQL语法,才可以去执行,要理解SQL语法,就要靠查询解析器了。
查询解析器(parser),就是负责对SQL语句进行解析的。按照SQL语法,对我们按照SQL语法编写的SQL语句进行解析。比如对select name, age from user where id = 1这个语句。
1、我们要从user表里查询数据;
2、查询"id"字段值等于1的那行语句;
3、对查出来的那行数据提取name,age两个字段;
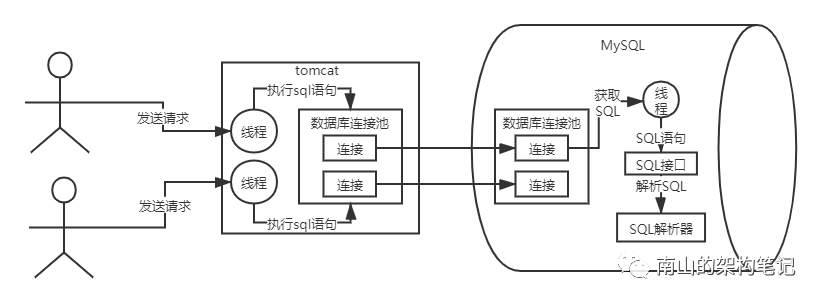
图4 SQL查询解析器
4、查询优化器:选择最优的查询路径
通过SQL解析器解析SQL语句,知道要干什么,那么怎么干性能最高呢?
比如,上面那个查询语句:select name, age from user where id = 1
可以有多种查询方式:
1、直接根据id定位到一行数据,然后从中获取name, age;
2、从表中把所有的id,name, age查出来,根据id过滤出来想要的数据;
上面是两种SQL查询方式(不代表MySQL的实现方式),两种查询方式都可以实现目标,哪种性能更好呢?
这就需要查询优化器告诉你。
查询优化器会告诉你,你应该按照一个什么样的步骤和顺序,去执行哪些操作,才能最快的获取结果。现在的图就变成这样了:
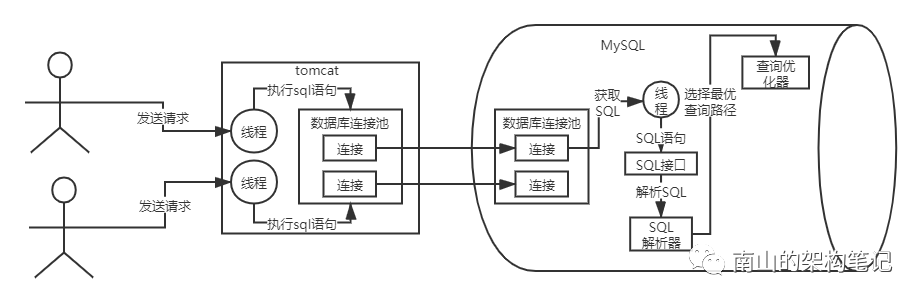
图5 查询优化器
5、执行器;根据执行计划调用存储引擎
查询优化器选择了最优的查询路径,知道了按照一个什么样的顺序和步骤去执行这个SQL语句的计划,然后就需要执行器调用存储引擎的接口把SQL语句的逻辑给执行了。
比如,执行器可能会先调用存储引擎的一个接口,去获取user表中的第一行数据,然后判断这个数据的id字段是否等于我们期望的值,如果不是的话,就继续调用存储引擎的接口,获取user表的下一行数据。
基于上述思路,执行器,就会去根据我们的优化器生成的一套执行计划,不停的调用存储引擎的各种接口去完成SQL语句的执行。
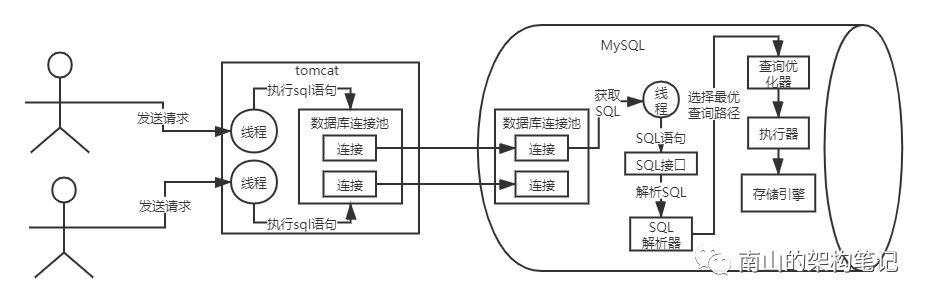
图6 执行器
6、调用存储引擎,真正执行SQL语句
执行器把执行计划交给最底层的存储引擎,就会真正的执行SQL语句了。
执行SQL语句,无非是增删改查数据,那么数据是存放在哪里呢?
数据要么是放在内存里,要么是放在磁盘上,所有存储引擎会按一定的步骤去查询内存缓存的数据,更新磁盘数据,等等。
MySQL的架构设计中,SQL接口,SQL解析器,查询优化器,都是通用的,但存储引擎是有很多种的。比如常见的innoDB,myisam。
互联网公司一般选用innoDB存储引擎。
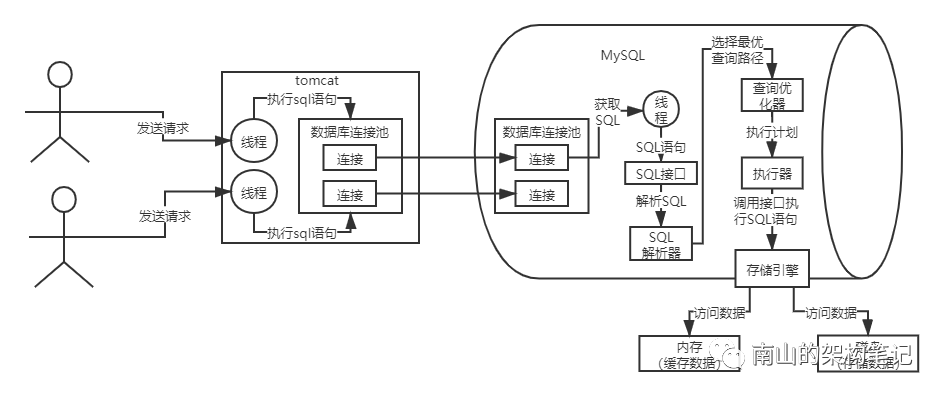
图7 MySQL底层架构
搞清楚了MySQL的底层架构,那么具体执行一条SQL时是怎样的呢?下节我们会讲。
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️