谷歌大脑Quoc发布Primer,从操作原语搜索高效Transformer变体
新智元报道
新智元报道
来源:arXiv
编辑:LRS
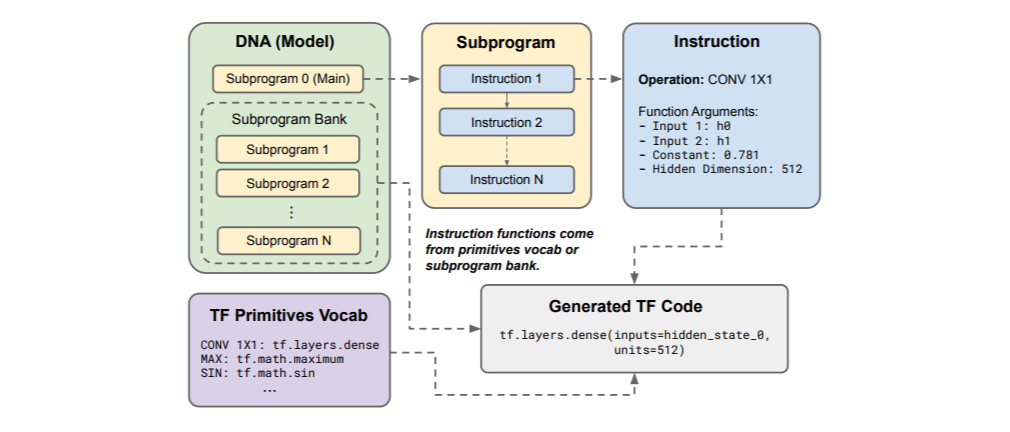
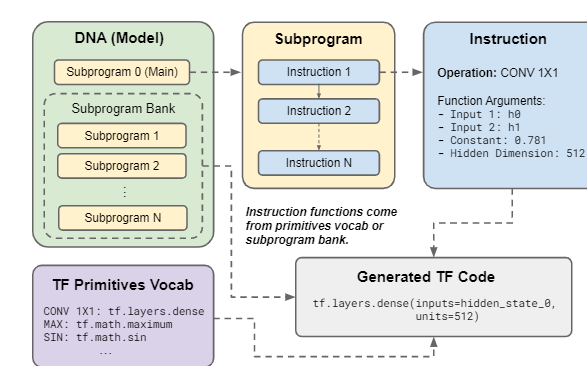
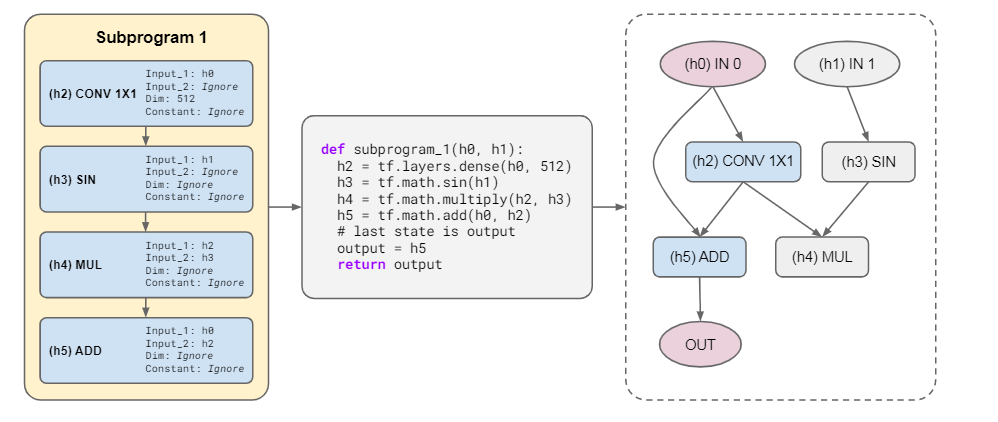
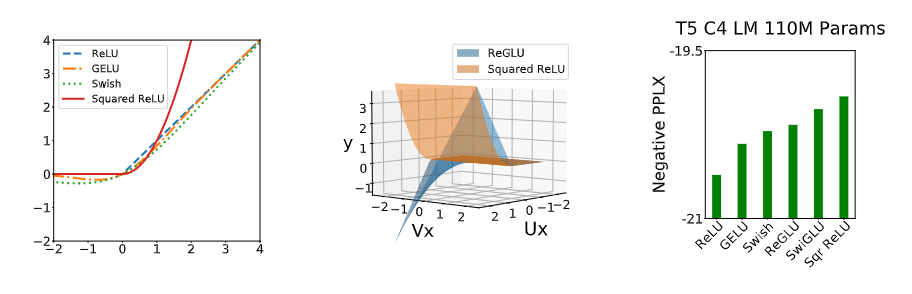
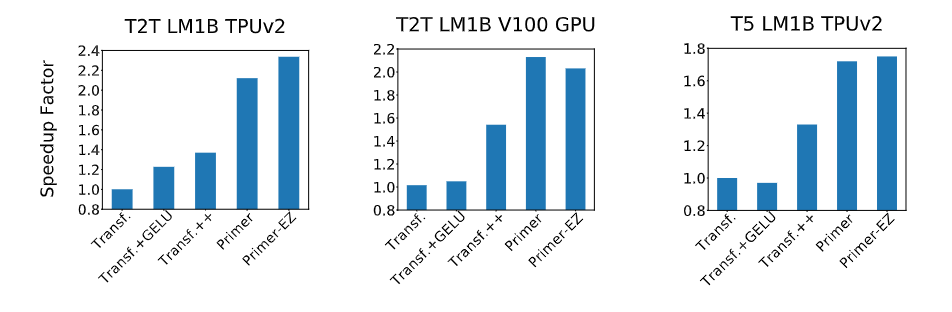
【新智元导读】调参、改激活函数提高模型性能已经见怪不改了。最近Google Brain的首席Quoc发布了一个搜索框架,能够自动搜索高效率的Transformer变体,并找到一些有效的模型Primer,其中ReLU加个平方竟然能提升最多性能!


参考资料:
https://arxiv.org/abs/2109.08668

评论
 下载APP
下载APP新智元报道
来源:arXiv
编辑:LRS
参考资料:
https://arxiv.org/abs/2109.08668