
【Python实战案例】读取Excel批量替换Word局部信息
一个word办公自动化的私活
最近接到一个单子,需要我将word文档中的关键信息(红色字体内容)替换为一个excel文档中的一行数据,并能够批量化的将excel文档中的每个数据依据这个word模板生成对应数量的word文件。
做了一下午,总算拿到佣金,还是挺开心的
接下来看看,先看下数据源和要替换的word模板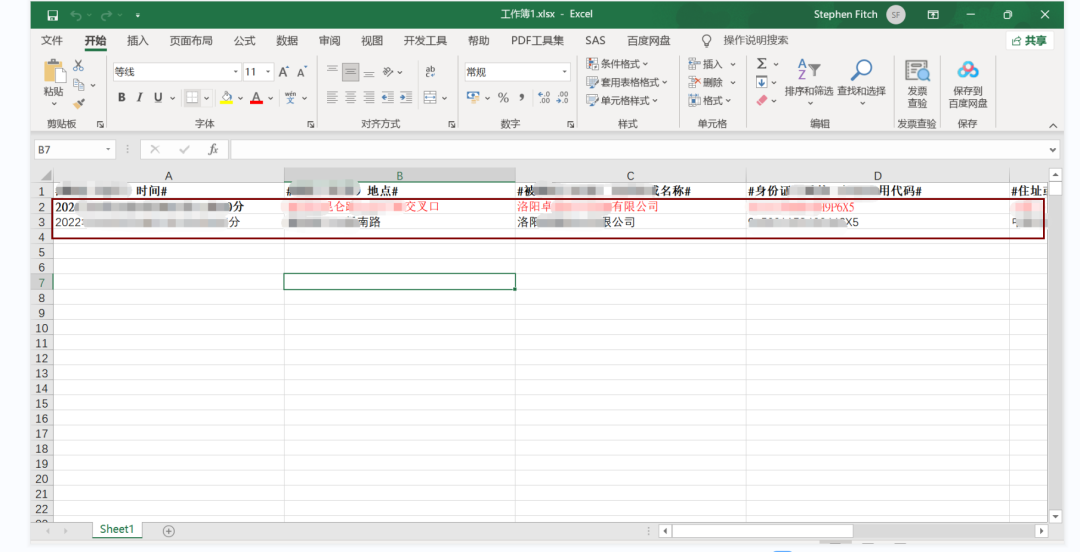 (数据源)
(数据源)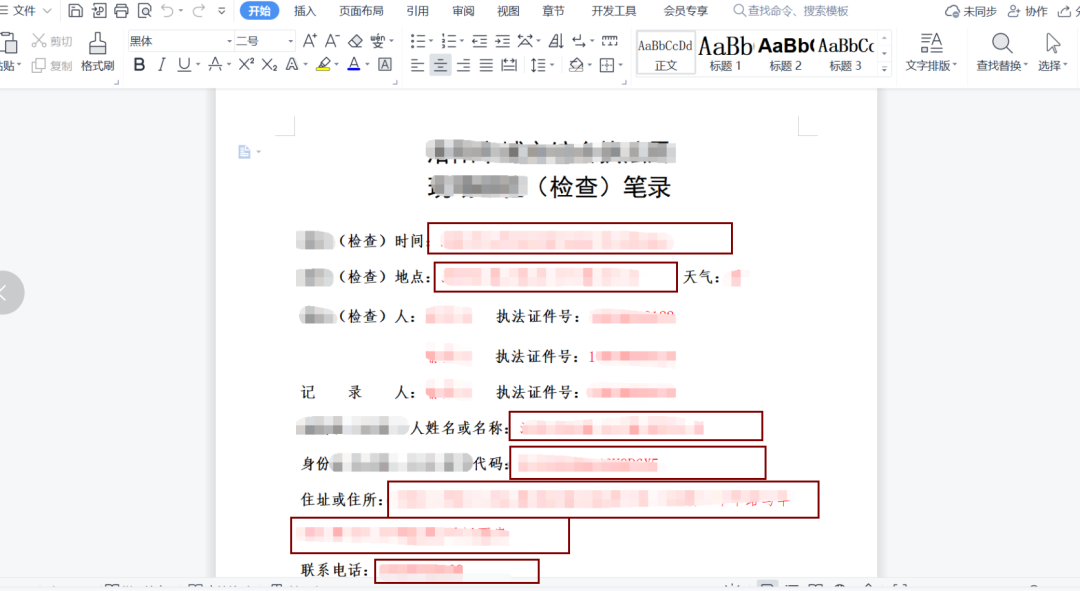 (word模板)
(word模板)
主要原理
这里主要的原理是我使用了专门处理word的python扩展包python-docx,然后提取段落,对段落中执行文档的编号进行遍历,由于格式是固定的,那么只要对每个段落对象进行计数,然后按照对应计数来进行数组定位,并把从excel中读取到的字段值进行替换就可以达到批量生成模板数据的要求了。
看下代码:
from docx import Document
import docx
import pandas as pd
df = pd.read_excel(r'工作簿1.xlsx')
#读取excel数据
for i in df.index:
# 实例化一个文件对象
doc = Document(r'1XXXXXXXXXXX模版.docx')
tm = df.loc[i,"#XXXXXX 时间#"]
plc = df.loc[i,"#XXXXX 地点#"]
chp = df.loc[i,'#被XXXXX 姓名或名称#']
ids = df.loc[i,'#XXXX 社会XXXX码#']
adr = df.loc[i,'#住XXXXX所#']
ph = df.loc[i,'#联XXXX话#']
cp = df.loc[i,'#现XXXXX人#']
idp = df.loc[i,'#身XXXX号#']
# 定位信息节点:
doc_paras = doc.paragraphs
count = 0
for para in doc_paras[3:14]:
print("段落"+str(count))
if count == 9:
col1 = para.text.split(":")
col1[2] = idp
col1[1] = col1[1].split(" ")
col1[1][0] = cp
col2 = col1[0]+":"+col1[1][0]+" "+col1[1][1]+":"+str(col1[2])
para.text = col2
elif count==0:
col = para.text.split(":")
col[1] = tm
res = ":".join(col)
para.text = res
print(para.text)
elif count==1:
col1 = para.text.split(" ")
col2 = col1[0].split(":")
col2[1] = plc
col3 = col2[0]+":"+col2[1]+" "+col1[1]
para.text = col3
print(para.text)
elif count==5:
col1 = para.text.split(":")
col1[1] = chp
col2 = col1[0]+":"+col1[1]
para.text = col2
print(para.text)
elif count==6:
col1 = para.text.split(":")
col1[1] = ids
col2 = col1[0]+":"+col1[1]
para.text = col2
print(para.text)
elif count==7:
col1 = para.text.split(":")
col1[1] = adr
col2 = col1[0]+":"+col1[1]
para.text = col2
print(para.text)
elif count==8:
col1 = para.text.split(":")
col1[1] = ph
col2 = col1[0]+":"+str(col1[1])
para.text = col2
print(para.text)
count+=1
doc.save(rf'new{i}.doc')
最终实现了所有对应数据的替换,python在处理word方面的办公自动化比起excel来,一点也不差,而且可以和excel进行结合,产生更多不可思议的高效功能。

图中红色框就是被替换的程序,这段代码将来会用在他们的很多部门,预计能够批量产生几百上千个类似表格,悬赏人对我感谢之情溢于言表。
最后,推荐蚂蚁老师的《零基础入门Python到办公自动化》课程
评论