
超详细! 生成DataFrame、读取和保存各种格式数据
一、生成DataFrame
import pandas as pd
datas = {
'排名': [1, 2, 3, 4, 5],
'综合得分': [894, 603, 589, 570, 569],
'粉丝数': [309147, 93704, 98757, 124712, 59847],
'获赞数': [12200, 31637, 4987, 1736, 8996]
}
df = pd.DataFrame(datas)
df
结果如下: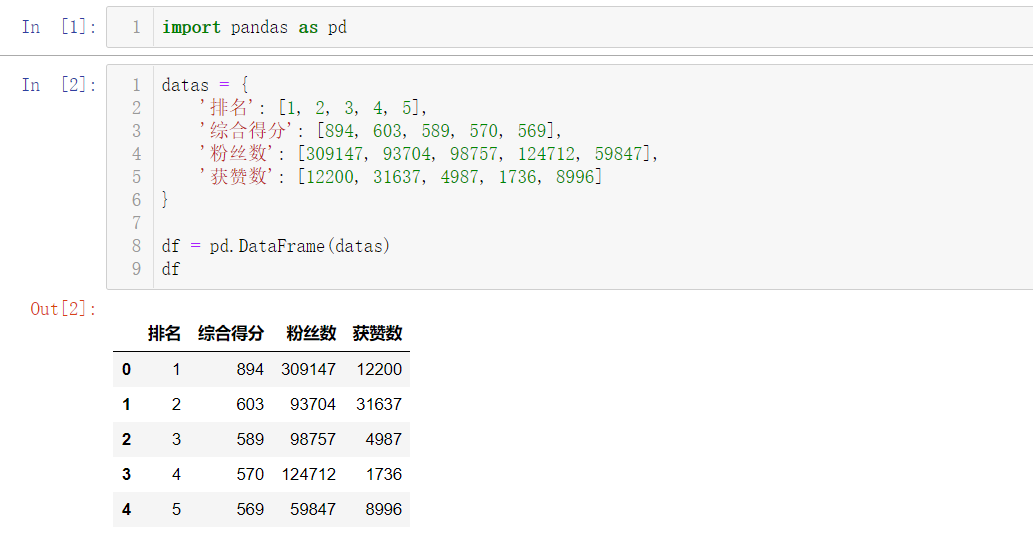
datas1 = [
{'排名': 1, '综合得分': 894, '粉丝数': 309147, '获赞数': 12200},
{'排名': 2, '综合得分': 603, '粉丝数': 93704, '获赞数': 31637},
{'排名': 3, '综合得分': 589, '粉丝数': 98757, '获赞数': 4987},
{'排名': 4, '综合得分': 570, '粉丝数': 124712, '获赞数': 1736},
{'排名': 5, '综合得分': 569, '粉丝数': 59847, '获赞数': 8996}
]
df1 = pd.DataFrame(datas1)
df1
结果如下: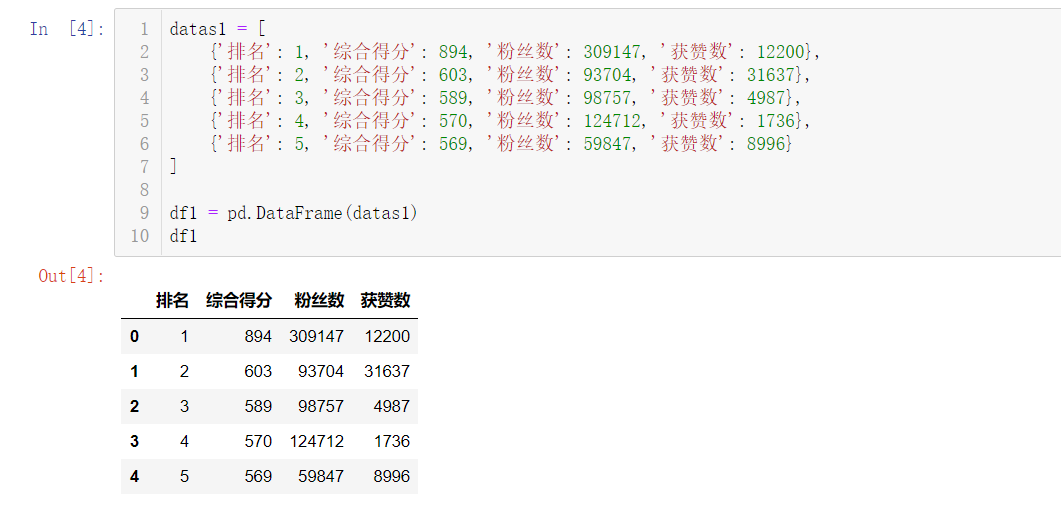
在爬取数据时,保存数据如果用pandas,需要组织数据生成DataFrame,以上两种方法是很常用的,熟练掌握这两种方法在保存爬取下来的数据时很有帮助。
二、读取数据
# 读取 Excel 数据
df2 = pd.read_excel('rank_datas.xlsx')
# 随机抽取5行数据
df2.sample(5)
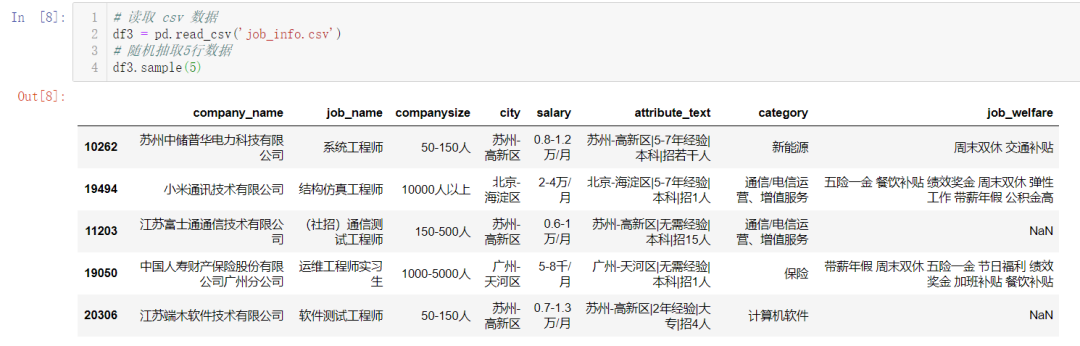
# 读取 csv 数据
df3 = pd.read_csv('job_info.csv')
# 随机抽取5行数据
df3.sample(5)
# 读取 html 数据
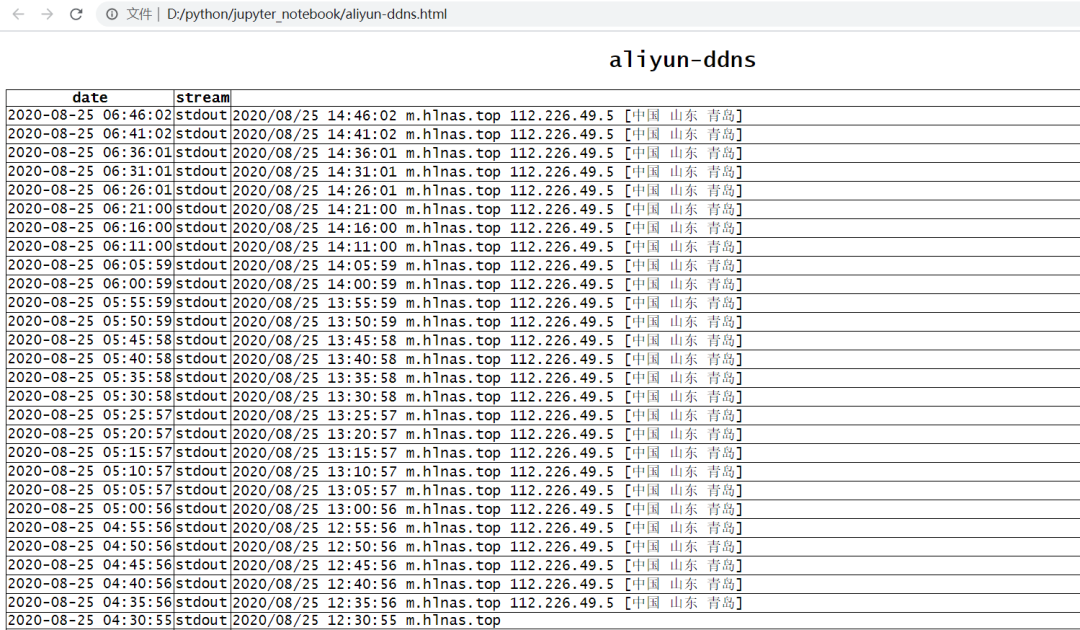
df4 = pd.read_html('aliyun-ddns.html')[0]
# 随机抽取5行数据
df4.sample(5)
结果如下: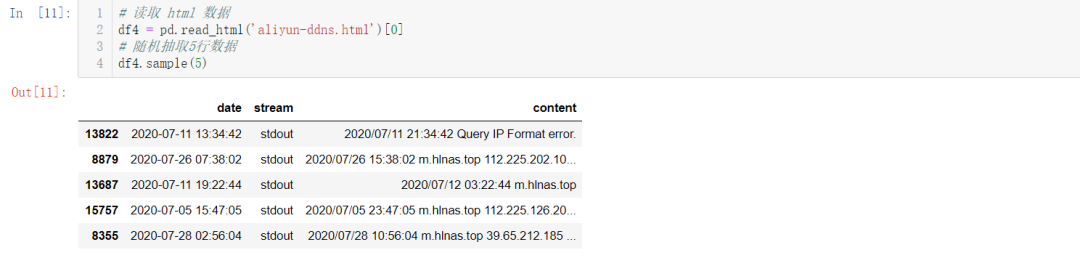 pd.read_html( )这个方法虽然少用,但它的功能非常强大,有时可以用做爬虫,直接抓取网页 Table 表格型数据,得到DataFrame。
pd.read_html( )这个方法虽然少用,但它的功能非常强大,有时可以用做爬虫,直接抓取网页 Table 表格型数据,得到DataFrame。
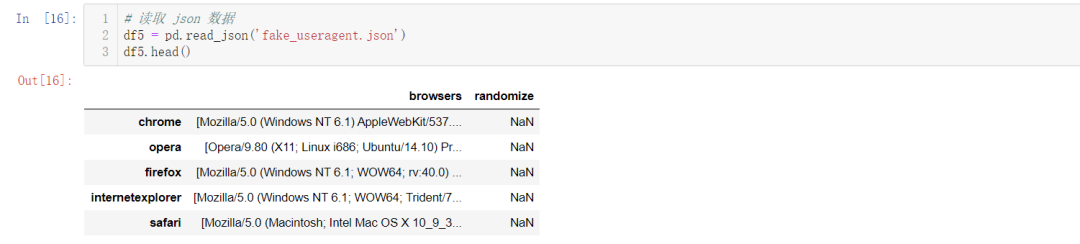
# 读取 json 数据
df5 = pd.read_json('fake_useragent.json')
df5.head()
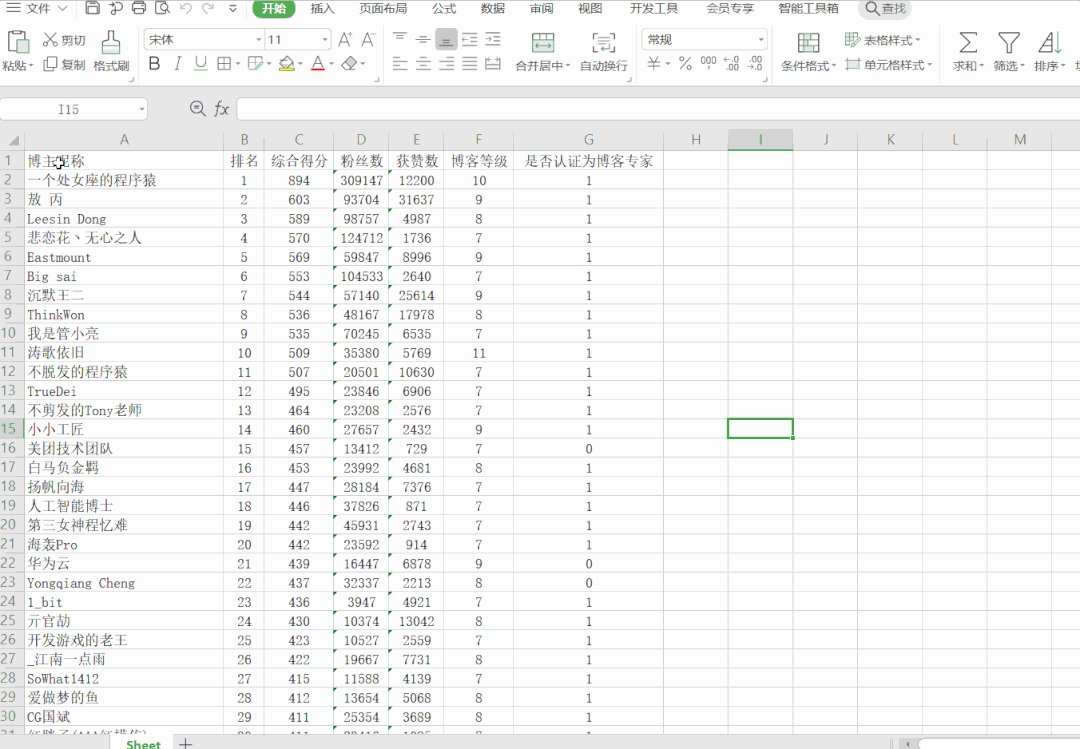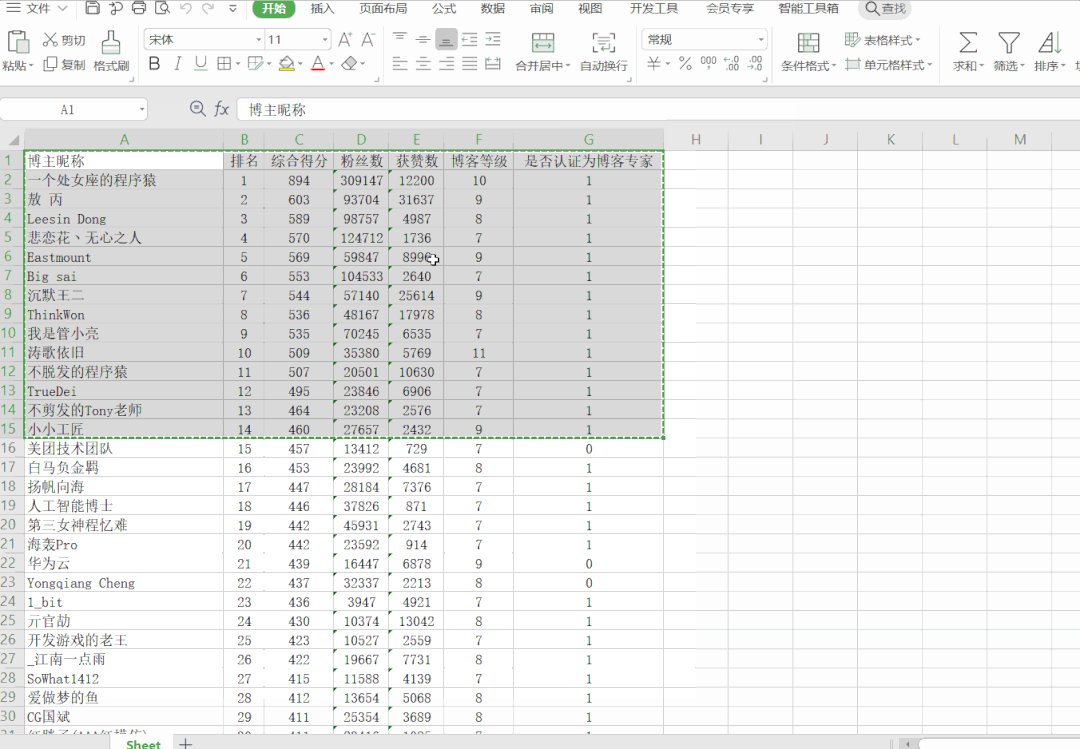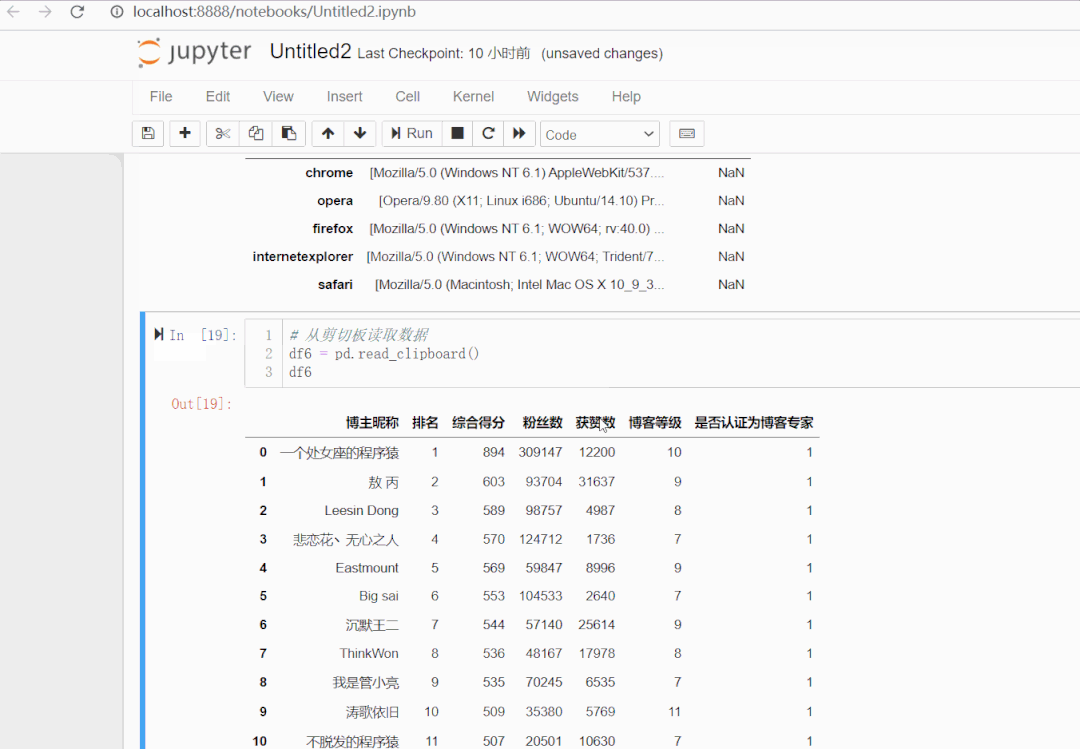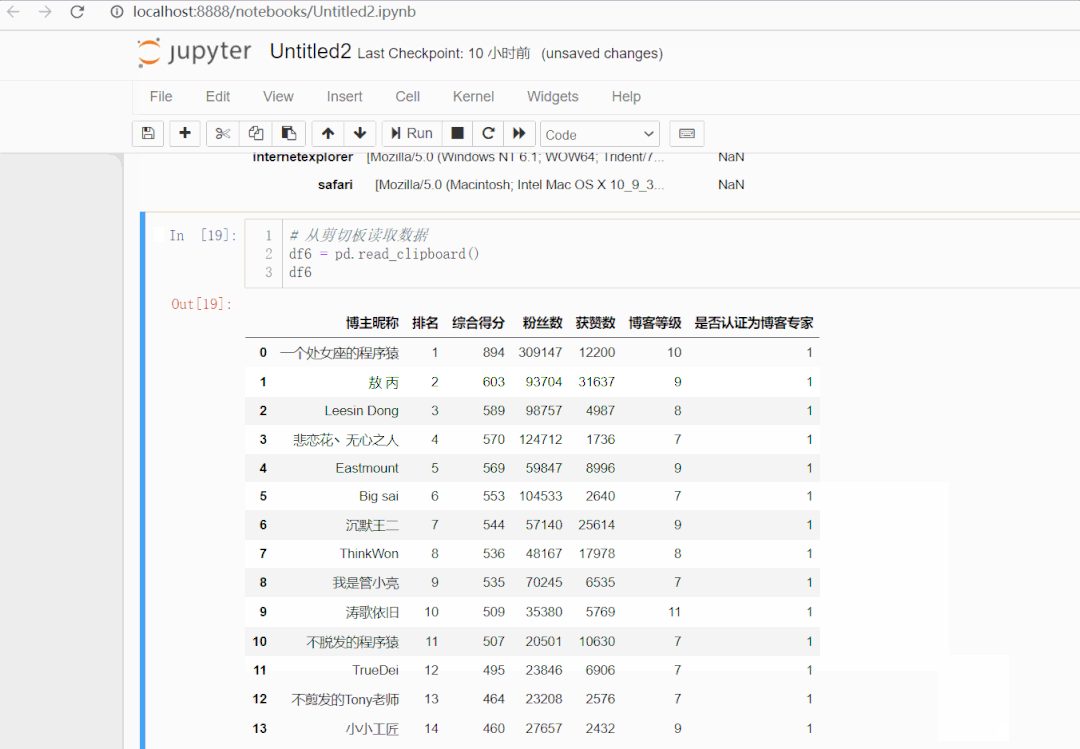
三、保存数据
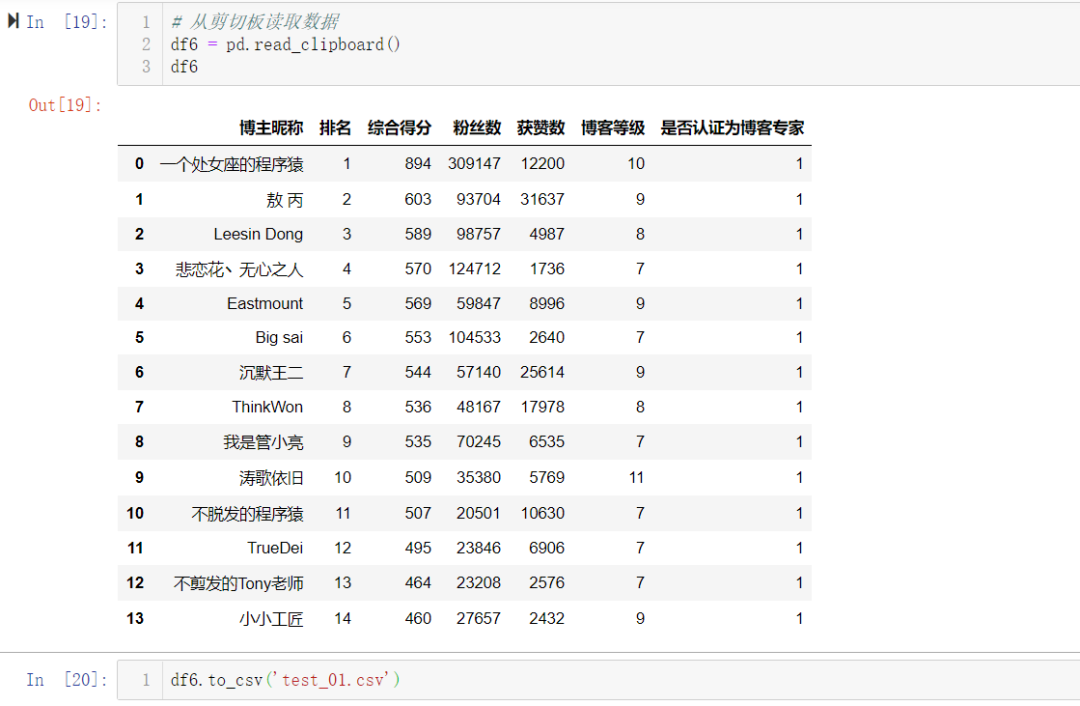
结果如下:
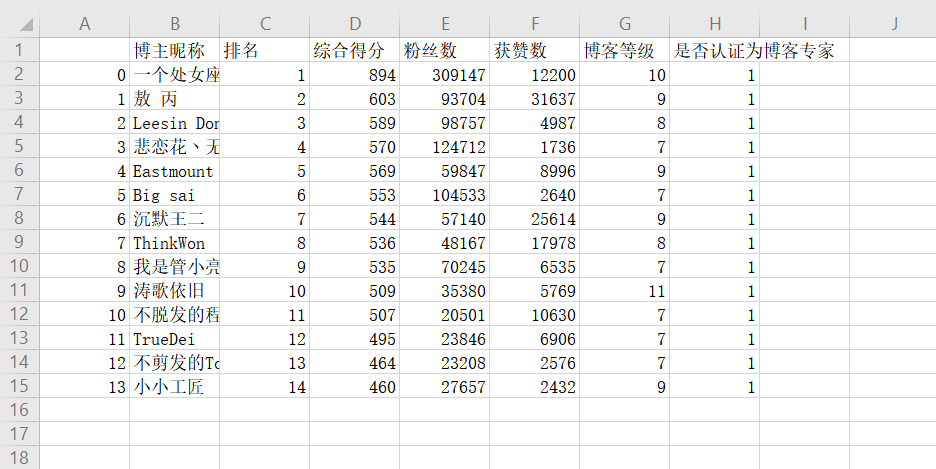
df.to_excel( ):保存到 Excel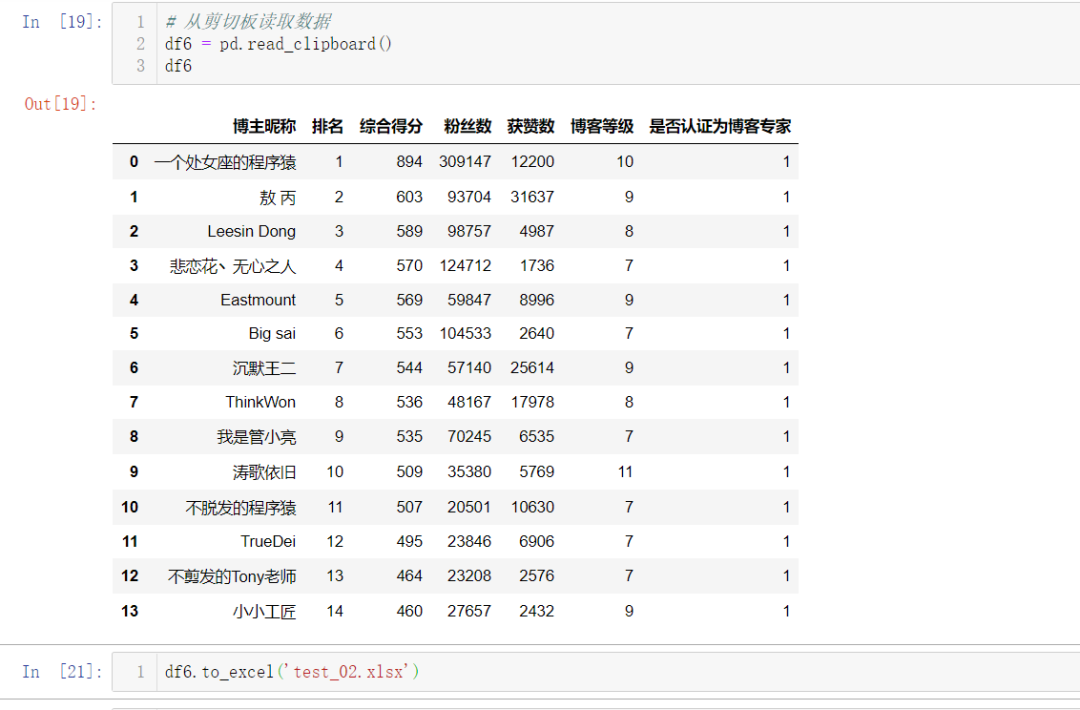
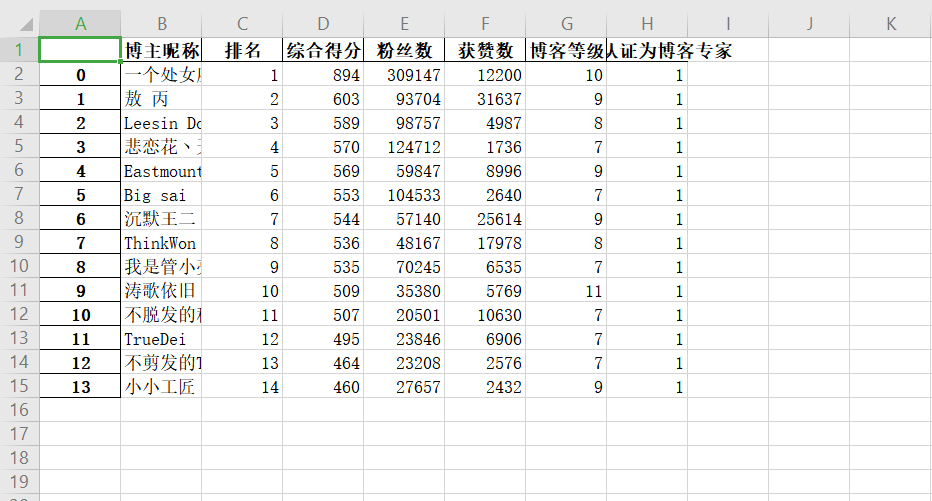
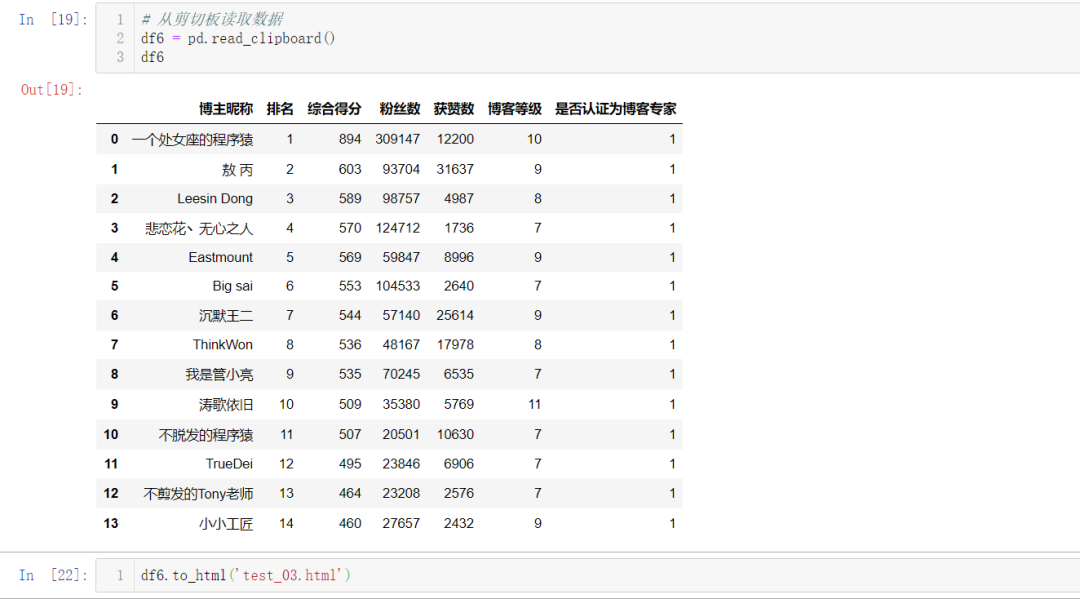
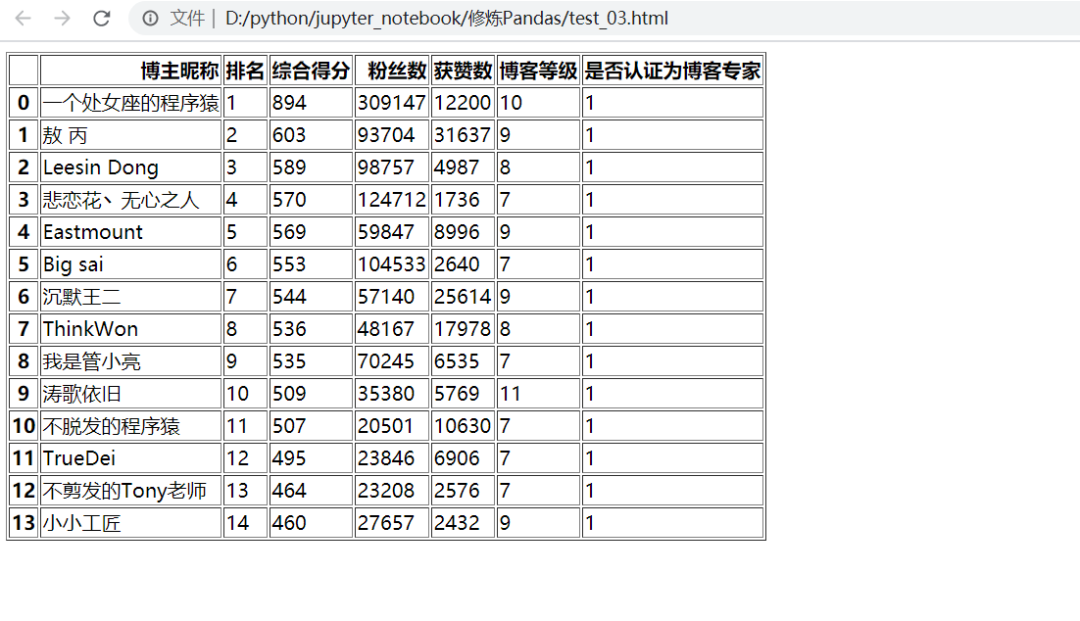
万水千山总是情,点个  行不行
行不行
评论