
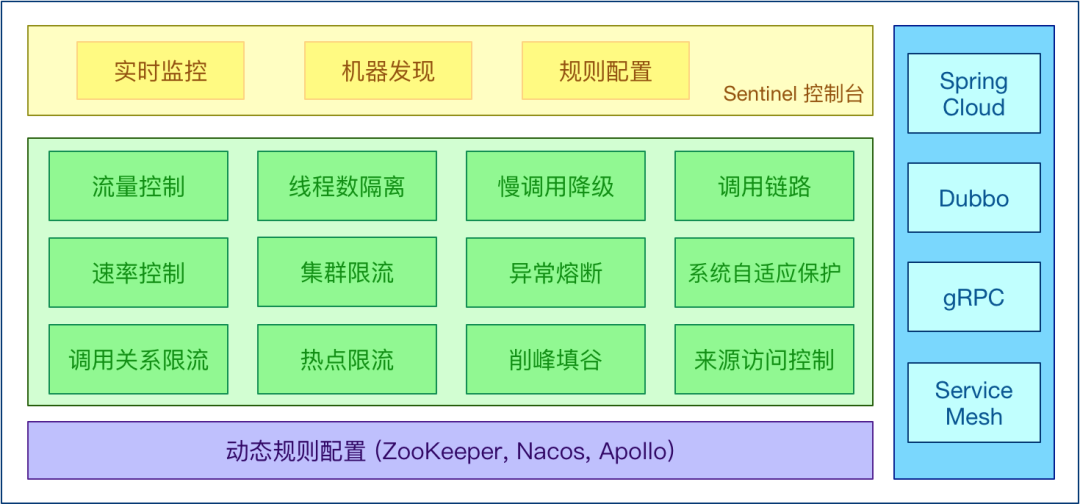
面试官:说一下限流、熔断、高可用?好多人一脸懵!

日常生活中,有哪些需要限流的地方?
像我旁边有一个国家景区,平时可能根本没什么人前往,但是一到五一或者春节就人满为患,这时候景区管理人员就会实行一系列的政策来限制进入人流量, 为什么要限流呢?假如景区能容纳一万人,现在进去了三万人,势必摩肩接踵,整不好还会有事故发生,这样的结果就是所有人的体验都不好,如果发生了事故景区可能还要关闭,导致对外不可用,这样的后果就是所有人都觉得体验糟糕透了。
限流的思想就是,在保证可用的情况下尽可能多增加进入的人数,其余的人在外面排队等待,保证里面的一万人可以正常游玩。
回到网络上,同样也是这个道理,例如某某明星公布了恋情,访问从平时的50万增加到了500万,系统最多可以支撑200万访问,那么就要执行限流规则,保证是一个可用的状态,不至于服务器崩溃导致所有请求不可用。
限流思路
对系统服务进行限流,一般有如下几个模式:
熔断
系统在设计之初就把熔断措施考虑进去。当系统出现问题时,如果短时间内无法修复,系统要自动做出判断,开启熔断开关,拒绝流量访问,避免大流量对后端的过载请求。
系统也应该能够动态监测后端程序的修复情况,当程序已恢复稳定时,可以关闭熔断开关,恢复正常服务。常见的熔断组件有Hystrix以及阿里的Sentinel,两种互有优缺点,可以根据业务的实际情况进行选择。
服务降级
将系统的所有功能服务进行一个分级,当系统出现问题需要紧急限流时,可将不是那么重要的功能进行降级处理,停止服务,这样可以释放出更多的资源供给核心功能的去用。
例如在电商平台中,如果突发流量激增,可临时将商品评论、积分等非核心功能进行降级,停止这些服务,释放出机器和CPU等资源来保障用户正常下单,而这些降级的功能服务可以等整个系统恢复正常后,再来启动,进行补单/补偿处理。除了功能降级以外,还可以采用不直接操作数据库,而全部读缓存、写缓存的方式作为临时降级方案。学习资料:Java进阶视频资源
延迟处理
这个模式需要在系统的前端设置一个流量缓冲池,将所有的请求全部缓冲进这个池子,不立即处理。然后后端真正的业务处理程序从这个池子中取出请求依次处理,常见的可以用队列模式来实现。这就相当于用异步的方式去减少了后端的处理压力,但是当流量较大时,后端的处理能力有限,缓冲池里的请求可能处理不及时,会有一定程度延迟。后面具体的漏桶算法以及令牌桶算法就是这个思路。
特权处理
这个模式需要将用户进行分类,通过预设的分类,让系统优先处理需要高保障的用户群体,其它用户群的请求就会延迟处理或者直接不处理。
缓存、降级、限流区别
缓存,是用来增加系统吞吐量,提升访问速度提供高并发。
降级,是在系统某些服务组件不可用的时候、流量暴增、资源耗尽等情况下,暂时屏蔽掉出问题的服务,继续提供降级服务,给用户尽可能的友好提示,返回兜底数据,不会影响整体业务流程,待问题解决再重新上线服务
限流,是指在使用缓存和降级无效的场景。比如当达到阈值后限制接口调用频率,访问次数,库存个数等,在出现服务不可用之前,提前把服务降级。只服务好一部分用户。
限流的算法
限流算法很多,常见的有三类,分别是计数器算法、漏桶算法、令牌桶算法,下面逐一讲解。
计数器算法
简单粗暴,比如指定线程池大小,指定数据库连接池大小、nginx连接数等,这都属于计数器算法。
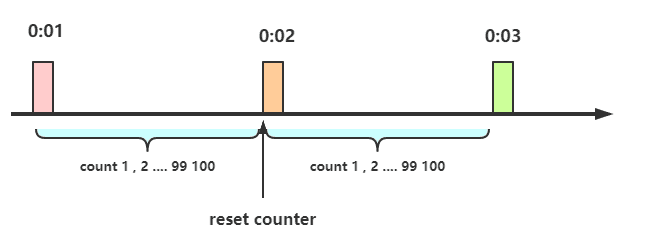
计数器算法是限流算法里最简单也是最容易实现的一种算法。举个例子,比如我们规定对于A接口,我们1分钟的访问次数不能超过100个。那么我们可以这么做:在一开 始的时候,我们可以设置一个计数器counter,每当一个请求过来的时候,counter就加1,如果counter的值大于100并且该请求与第一个请求的间隔时间还在1分钟之内,那么说明请求数过多,拒绝访问;如果该请求与第一个请求的间隔时间大于1分钟,且counter的值还在限流范围内,那么就重置 counter,就是这么简单粗暴。
漏桶算法
漏桶算法思路很简单,水(请求)先进入到漏桶里,漏桶以一定的速度出水,当水流入速度过大会超过桶可接纳的容量时直接溢出,可以看出漏桶算法能强行限制数据的传输速率。

削峰:有大量流量进入时,会发生溢出,从而限流保护服务可用
缓冲:不至于直接请求到服务器,缓冲压力 消费速度固定 因为计算性能固定
令牌桶算法
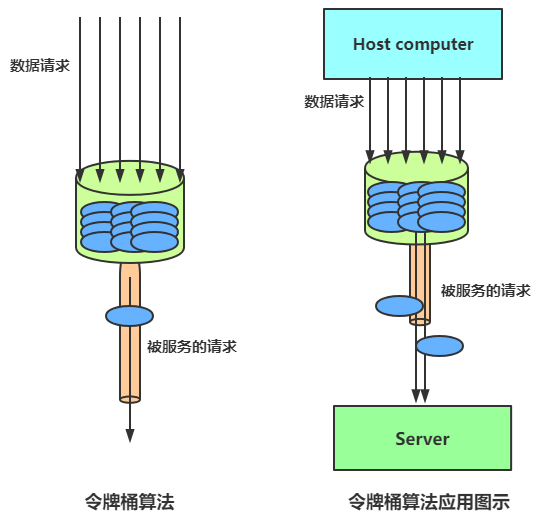
令牌桶与漏桶相似,不同的是令牌桶桶中放了一些令牌,服务请求到达后,要获取令牌之后才会得到服务,举个例子,我们平时去食堂吃饭,都是在食堂内窗口前排队的,这就好比是漏桶算法,大量的人员聚集在食堂内窗口外,以一定的速度享受服务,如果涌进来的人太多,食堂装不下了,可能就有一部分人站到食堂外了,这就没有享受到食堂的服务,称之为溢出,溢出可以继续请求,也就是继续排队,那么这样有什么问题呢?
如果这时候有特殊情况,比如有些赶时间的志愿者啦、或者高三要高考啦,这种情况就是突发情况,如果也用漏桶算法那也得慢慢排队,这也就没有解决我们的需求,对于很多应用场景来说,除了要求能够限制数据的平均传输速率外,还要求允许某种程度的突发传输。这时候漏桶算法可能就不合适了,令牌桶算法更为适合。如图所示,令牌桶算法的原理是系统会以一个恒定的速度往桶里放入令牌,而如果请求需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌可取时,则拒绝服务。
并发限流
简单来说就是设置系统阈值总的QPS个数,这些也挺常见的,就拿Tomcat来说,很多参数就是出于这个考虑,例如
配置的acceptCount 设置响应连接数, maxConnections设置瞬时最大连接数, maxThreads 设置最大线程数,在各个框架或者组件中,并发限流体现在下面几个方面:
限制总并发数(如数据库连接池、线程池) 限制瞬时并发数(nginx的limit_conn模块,用来限制瞬时并发连接数) 限制时间窗口内的平均速率(如Guava的RateLimiter、nginx的limit_req模块,限制每秒的平均速率) 其他的还有限制远程接口调用速率、限制MQ的消费速率。 另外还可以根据网络连接数、网络流量、CPU或内存负载等来限流。
有了并发限流,就意味着在处理高并发的时候多了一种保护机制,不用担心瞬间流量导致系统挂掉或雪崩,最终做到有损服务而不是不服务;但是限流需要评估好,不能乱用,否则一些正常流量出现一些奇怪的问题而导致用户体验很差造成用户流失。学习资料:Java进阶视频资源
接口限流
接口限流分为两个部分,一是限制一段时间内接口调用次数,参照前面限流算法的计数器算法, 二是设置滑动时间窗口算法。
接口总数
控制一段时间内接口被调用的总数量,可以参考前面的计数器算法,不再赘述。
接口时间窗口
固定时间窗口算法(也就是前面提到的计数器算法)的问题是统计区间太大,限流不够精确,而且在第二个统计区间 时没有考虑与前一个统计区间的关系与影响(第一个区间后半段 + 第二个区间前半段也是一分钟)。为了解决上面我们提到的临界问题,我们试图把每个统计区间分为更小的统计区间,更精确的统计计数。

在上面的例子中,假设QPS可以接受100次查询/秒, 前一分钟前40秒访问很低,后20秒突增,并且这个持续了一段时间,直到第二分钟的第40秒才开始降下来,根据前面的计数方法,前一秒的QPS为94,后一秒的QPS为92,那么没有超过设定参数,但是!但是在中间区域,QPS达到了142,这明显超过了我们的允许的服务请求数目,所以固定窗口计数器不太可靠,需要滑动窗口计数器。
计数器算法其实就是固定窗口算法, 只是它没有对时间窗口做进一步地划分,所以只有1格;由此可见,当滑动窗口的格子划分的越多,也就是将秒精确到毫秒或者纳秒, 那么滑动窗口的滚动就越平滑,限流的统计就会越精确。
需要注意的是,消耗的空间就越多。
限流实现
这一部分是限流的具体实现,简单说说,毕竟长篇代码没人愿意看。
guava实现
引入包
<dependency>
<groupId>com.google.guavagroupId>
<artifactId>guavaartifactId>
<version>28.1-jreversion>
dependency>
核心代码
LoadingCache counter = CacheBuilder.newBuilder().
expireAfterWrite(2, TimeUnit.SECONDS)
.build(new CacheLoader() {
@Override
public AtomicLong load(Long secend) throws Exception {
// TODO Auto-generated method stub
return new AtomicLong(0);
}
});
counter.get(1l).incrementAndGet();
令牌桶实现
稳定模式(SmoothBursty:令牌生成速度恒定)
public static void main(String[] args) {
// RateLimiter.create(2)每秒产生的令牌数
RateLimiter limiter = RateLimiter.create(2);
// limiter.acquire() 阻塞的方式获取令牌
System.out.println(limiter.acquire());;
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(limiter.acquire());;
System.out.println(limiter.acquire());;
System.out.println(limiter.acquire());;
System.out.println(limiter.acquire());;
System.out.println(limiter.acquire());;
System.out.println(limiter.acquire());;
}
RateLimiter.create(2) 容量和突发量,令牌桶算法允许将一段时间内没有消费的令牌暂存到令牌桶中,用来突发消费。学习资料:Java进阶视频资源
渐进模式(SmoothWarmingUp:令牌生成速度缓慢提升直到维持在一个稳定值)
// 平滑限流,从冷启动速率(满的)到平均消费速率的时间间隔
RateLimiter limiter = RateLimiter.create(2,1000l,TimeUnit.MILLISECONDS);
System.out.println(limiter.acquire());;
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(limiter.acquire());
System.out.println(limiter.acquire());
System.out.println(limiter.acquire());
System.out.println(limiter.acquire());
System.out.println(limiter.acquire());
System.out.println(limiter.acquire());
超时
boolean tryAcquire = limiter.tryAcquire(Duration.ofMillis(11));
在timeout时间内是否能够获得令牌,异步执行
分布式系统限流
Nginx + Lua实现
可以使用resty.lock保持原子特性,请求之间不会产生锁的重入
https://github.com/openresty/lua-resty-lock
使用lua_shared_dict存储数据
local locks = require "resty.lock"
local function acquire()
local lock =locks:new("locks")
local elapsed, err =lock:lock("limit_key") -- 互斥锁 保证原子特性
local limit_counter =ngx.shared.limit_counter -- 计数器
local key = "ip:" ..os.time()
local limit = 5 -- 限流大小
local current =limit_counter:get(key)
if current ~= nil and current + 1> limit then -- 如果超出限流大小
lock:unlock()
return 0
end
if current == nil then
limit_counter:set(key, 1, 1) -- 第一次需要设置过期时间,设置key的值为1,
-- 过期时间为1秒
else
limit_counter:incr(key, 1) -- 第二次开始加1即可
end
lock:unlock()
return 1
end
ngx.print(acquire())来源:cnblogs.com/Courage129/p/14423707.html
有收获,点个在看
