
[干货]源码级探究Mybatis原理-以查询为例
作为一名Java后端开发者,尤其是国内开发者,从刚参加工作开始就与Mybatis打交道了。
用了这么久的Mybatis难免会心生疑问:
我只是写了个Mapper接口,再配合xml或者注解,把SQL一写,就可以执行数据库操作,这是为何? 都说Mybatis是对JDBC的封装,可是我却看不到JDBC相关的接口和对象,它们到哪里去了? 为什么在Spring中使用Mybatis,不用加@Repository/@Component之类的注解,就可以随用随注入(如:@Autowired)?
❝硬核万字长文,点个在看,转发,多谢啦~
❞
随着工作经验越多,对这些问题的疑惑就会越发强烈。而读源码是解决这些疑问的根本方法。
那么就跟随笔者的脚步,试着用一篇文章,以一个查询为例,从源码角度一步一步揭开Mybatis的神秘面纱。
一、先看一个demo
private SqlSessionFactory sqlSessionFactory;
@Before
public void prepare() throws IOException {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
}
/**
* 通过 SqlSession.getMapper(XXXMapper.class) 接口方式
* @throws IOException
*/
@Test
public void testSelect() throws IOException {
SqlSession session = sqlSessionFactory.openSession(); // ExecutorType.BATCH
try {
BlogMapper mapper = session.getMapper(BlogMapper.class);
Blog blog = mapper.selectBlogById(1);
System.out.println(blog);
} finally {
session.close();
}
}
这是一个非Spring项目的Test用例类,逻辑很直观,就是在测试通过id查询一行记录;在执行查询之间加载配置文件。
执行该测试用例,日志输出如下:
Opening JDBC Connection
Created connection 1325808650.
Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@4f063c0a]
==> Preparing: select * from blog where bid = ?
==> Parameters: 1(Integer)
<== Columns: bid, name, author_id, type
<== Row: 1, RabbitMQ延时消息, 1001, 0
getNullableResult---1NORMAL
<== Total: 1
Blog(bid=1, name=RabbitMQ延时消息, authorId=1001, blogType=0)
我们就通过这个ById查询的案例,对Mybatis运行的过程抽丝剥茧,还原出一个完整的脉络。
二、一图总览全局
❝按照惯例我们用一张简单概括的流程图引领全局,先建立一个宏观的印象。
❞

从图中可以看到,Mybatis主要的工作流程分为以下几步:
加载并解析配置文件 获取SqlSession对象作为与数据库交互的接口 通过Executor对象封装数据库操作,执行SQL操作 调用底层的JDBC接口,与数据库进行真正的交互 向数据库提交参数,并封装返回参数
加载并解析配置文件
在Mybatis启动的时候会去加载配置文件,一般来说文件包含全局配置文件(文件名为 「mybatis-config.xml」) ,以及映射器配置文件(也就是各种Mapper.xml文件);
获取SqlSession对象作为与数据库交互的接口
Mybatis在加载完配置文件之后,会去获取SqlSession对象,这个对象是应用程序与数据库之间的桥梁,封装了程序与数据库之间的连接。
一般来说,一个SqlSession对象中包含了一个Connection,我们都知道Connection是线程不安全的,因此导致SqlSession对象也是线程不安全的。因此如果将SqlSession作为成员变量使用,存在风险。(应当使用SqlSessionTemplate,这部分后面再说)。
❝注意:SqlSession是提供给应用层的一个访问数据库的接口,它并不是真正的SQL执行者,它内部封装了JDBC核心对象,如Statement,ResultSet等。
❞
通过SqlSessionFactory获取SqlSession会话
如果要获取一个SqlSession会话,就需要有会话工厂,即:SqlSessionFactory。它包含了所有的配置信息,而Factory又是通过Builder创建的,这部分后文代码分析中会说。
通过Executor对象封装数据库操作,执行SQL操作
SqlSession持有Executor对象,Executor在执行query、update、insert等操作时,会创建一系列的对象处理参数、处理结果集,核心的对象是StatementHandler,它本质上是对Statement的封装。
三、走进源码,一探究竟
3.1 SqlSessionFactory的创建
❝首先是SqlSession的创建过程;SqlSession需要通过SqlSessionFactory创建,而SqlSessionFactory又是通过SqlSessionFactoryBuilder创建的。
❞
# org.apache.ibatis.session.SqlSessionFactoryBuilder#build
public SqlSessionFactory build(InputStream inputStream) {
return build(inputStream, null, null);
}
事实上,inputStream就是配置文件的文件输入流,它传给了SqlSessionFactoryBuilder的build重载方法,我们看一下这个方法的实现。
public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) {
try {
// 用于解析 mybatis-config.xml,同时创建了 Configuration 对象 >>
XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
// 解析XML,最终返回一个 DefaultSqlSessionFactory >>
return build(parser.parse());
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error building SqlSession.", e);
} finally {
ErrorContext.instance().reset();
try {
inputStream.close();
} catch (IOException e) {
// Intentionally ignore. Prefer previous error.
}
}
}
可以看到,SqlSessionFactoryBuilder底层是通过xml解析方式,对配置文件进行解析,并基于解析的结果构建了SqlSessionFactory的实例,这里返回的是默认的SqlSessionFactory--->DefaultSqlSessionFactory。
public SqlSessionFactory build(Configuration config) {
return new DefaultSqlSessionFactory(config);
}
「注意:此处就已经通过配置文件解析出了Configuration,并通过DefaultSqlSessionFactory构造方法创建了DefaultSqlSessionFactory实例。后文要用!」
❝xml解析过程,感兴趣的读者可以自行研究,简单的说无非就是对xml文件的dom节点进行读取和匹配,获取属性加载到内存,Mybatis自己基于javax的xml操作api封装了一个工具类,「org.apache.ibatis.parsing.XPathParser」 。
❞
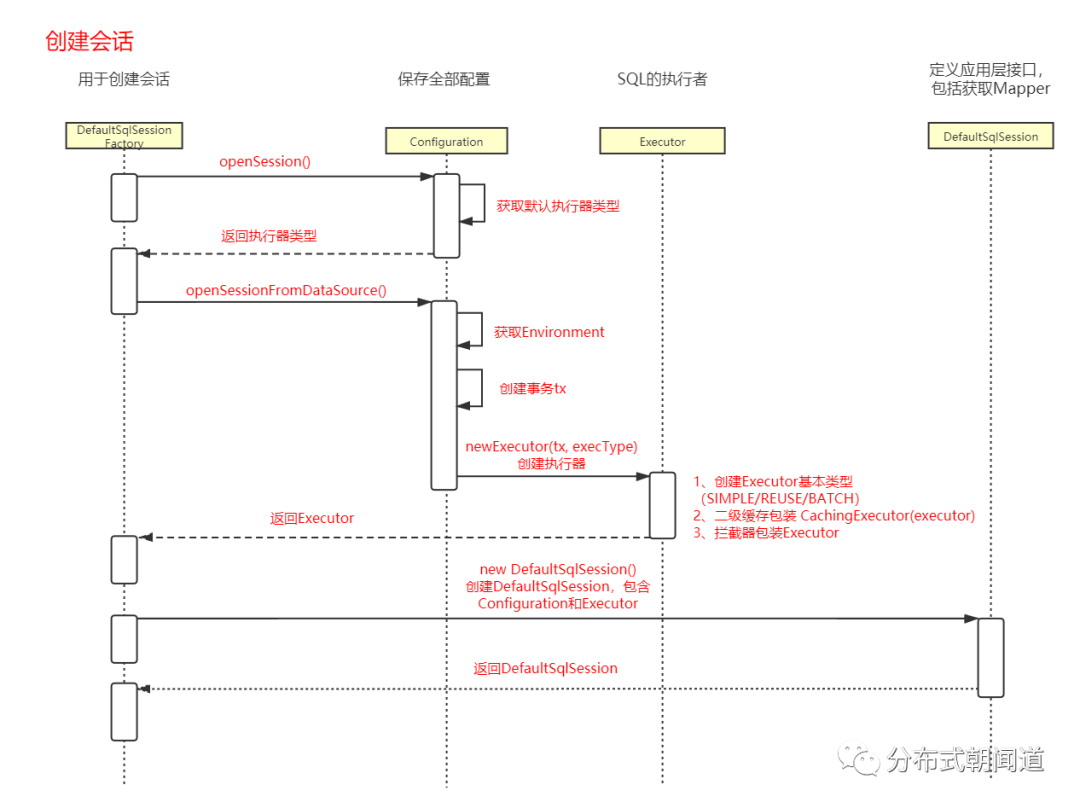
3.2 SqlSession的创建
在使用的demo中,我们通过SqlSessionFactory获取到一个SqlSession实例。
SqlSession session = sqlSessionFactory.openSession();
进入 openSession 方法一探究竟。
# org.apache.ibatis.session.defaults.DefaultSqlSessionFactory#openSession()
public SqlSession openSession() {
return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, false);
}
继续进入 openSessionFromDataSource 方法:
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
final Environment environment = configuration.getEnvironment();
// 获取事务工厂
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
// 创建事务
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
// 根据事务工厂和默认的执行器类型,创建执行器 >>
final Executor executor = configuration.newExecutor(tx, execType);
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
这里的逻辑比较核心,主要做了几件事:
获取到事务工厂; 通过事务工厂创建了事务,如果是使用Spring框架,则由Spring框架开启事务; 根据事务工厂和默认的执行器类型,创建执行器
最后通过DefaultSqlSession的构造方法,创建出DefaultSqlSession实例,它是SqlSession接口的默认实现。
到此,我们就持有了一个SqlSession对象,并且它还持有了一个Executor执行器实例。
代理Mapper对象,执行SQL
回到我们的demo代码中:
@Test
public void testSelect() throws IOException {
SqlSession session = sqlSessionFactory.openSession(); // ExecutorType.BATCH
try {
// 重点看这行代码
BlogMapper mapper = session.getMapper(BlogMapper.class);
Blog blog = mapper.selectBlogById(1);
System.out.println(blog);
} finally {
session.close();
}
}
我们已经拿到了SqlSession,接着通过 「session.getMapper(BlogMapper.class)」; 获取到了BlogMapper接口的实现类。
注意,我说的并不是获取到了BlogMapper,因为大家使用过Mybatis框架都知道BlogMapper是个接口,那么此处拿到的,必然是BlogMapper的实例。
接口的实例,嗯,有点意思了,我们明明只写了个接口,并没有实现这个接口啊?
是不是想到了什么?对,就是动态代理。
此处获取到的Mapper实例,就是Mybatis框架帮我们创建出的代理对象。
❝进入 DefaultSqlSession#getMapper 方法
❞
@Override
public T getMapper(Class type) {
return configuration.getMapper(type, this);
}
ok,继续往下看:
public T getMapper(Class type, SqlSession sqlSession) {
return mapperRegistry.getMapper(type, sqlSession);
}
这里,我们发现Mapper对象是通过 mapperRegistry 这个所谓的Mapper注册中心中获取到的,它的数据结构是一个HashMap:
# org.apache.ibatis.session.Configuration
protected final MapperRegistry mapperRegistry = new MapperRegistry(this);
# org.apache.ibatis.binding.MapperRegistry
public class MapperRegistry {
private final Configuration config;
private final Map, MapperProxyFactory> knownMappers = new HashMap<>();
既然我们能够通过Mapper接口类型get到接口的代理类,那它是多会儿put到Map里的?
仔细想一下应当能够想到,我们此时已经是在sql的执行期了,在这之前必然是配置文件的解析期间执行的put操作。具体代码如下:
/**
* org.apache.ibatis.builder.xml.XMLConfigBuilder#mapperElement
* Mapper解析
* @param parent
* @throws Exception
*/
private void mapperElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
// 不同的定义方式的扫描,最终都是调用 addMapper()方法
// (添加到 MapperRegistry)。这个方法和 getMapper() 对应
// package 包
if ("package".equals(child.getName())) {
String mapperPackage = child.getStringAttribute("name");
configuration.addMappers(mapperPackage);
} else {
String resource = child.getStringAttribute("resource");
String url = child.getStringAttribute("url");
String mapperClass = child.getStringAttribute("class");
if (resource != null && url == null && mapperClass == null) {
// resource 相对路径
ErrorContext.instance().resource(resource);
InputStream inputStream = Resources.getResourceAsStream(resource);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments());
// 解析 Mapper.xml,总体上做了两件事情 >>
mapperParser.parse();
} else if (resource == null && url != null && mapperClass == null) {
// url 绝对路径
ErrorContext.instance().resource(url);
InputStream inputStream = Resources.getUrlAsStream(url);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, url, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url == null && mapperClass != null) {
// class 单个接口
Class mapperInterface = Resources.classForName(mapperClass);
configuration.addMapper(mapperInterface);
} else {
throw new BuilderException("A mapper element may only specify a url, resource or class, but not more than one.");
}
}
}
}
}
通过这段代码我们可以看到,无论是通过指定扫描包路径,还是resources相对路径,或者url绝对路径,或者单个Mapper添加的方式,Mybatis本质上都是通过 「addMapper()方法添加到 MapperRegistry」。
❝继续回到Mapper代理对象创建过程中来。
❞
# org.apache.ibatis.session.Configuration#getMapper
public T getMapper(Class type, SqlSession sqlSession) {
return mapperRegistry.getMapper(type, sqlSession);
}
继续看mapperRegistry.getMapper方法逻辑。
public T getMapper(Class type, SqlSession sqlSession) {
final MapperProxyFactory mapperProxyFactory = (MapperProxyFactory) knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
}
我们发现,通过接口类型从HashMap中取到了一个 「MapperProxyFactory」 Mapper代理工厂的实例。
❝MapperProxyFactory实际上是对Mapper接口的包装,我们只需要看源码就知道了。
❞
public class MapperProxyFactory {
private final Class mapperInterface;
private final Map methodCache = new ConcurrentHashMap<>();
❝构造方法接受一个Mapper的class类型,对其进行封装。
❞
public MapperProxyFactory(Class mapperInterface) {
this.mapperInterface = mapperInterface;
}
获取到MapperProxyFactory实例之后,通过 「mapperProxyFactory.newInstance(sqlSession)」 就创建出了Mapper的代理对象。
public T newInstance(SqlSession sqlSession) {
final MapperProxy mapperProxy = new MapperProxy<>(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}
这里通过SqlSession、Mapper接口、方法缓存(「简单的说就是Mapper的那一堆方法,每次反射创建太耗费性能了,就缓存到一个Map里」)创建出MapperProxy 对象,进一步调用的如下方法:
@SuppressWarnings("unchecked")
protected T newInstance(MapperProxy mapperProxy) {
// 1:类加载器:2:被代理类实现的接口、3:实现了 InvocationHandler 的触发管理类
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}
这里把创建代理对象的操作委托给了MapperProxy,「我们发现,它的核心就是创建代理Mapper的代理对象 (h对象)。」
MapperProxy具体是如何创建的Mapper代理?
我们都知道,动态代理在JDK中是通过实现InvocationHandler接口实现的,那么大胆猜想MapperProxy必然实现了InvocationHandler接口。
public class MapperProxy implements InvocationHandler, Serializable {
果然如此。
我们来看它的invoke方法实现:
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
// toString hashCode equals getClass等方法,无需走到执行SQL的流程
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else {
// 提升获取 mapperMethod 的效率,到 MapperMethodInvoker(内部接口) 的 invoke
// 普通方法会走到 PlainMethodInvoker(内部类) 的 invoke
return cachedInvoker(method).invoke(proxy, method, args, sqlSession);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
可以看到,如果是普通方法,直接执行,不需要特殊处理;
否则就获取匹配的缓存Mapper方法,执行数据库操作。
❝重点看一下 cachedInvoker(method).invoke(proxy, method, args, sqlSession); 逻辑。
❞
private MapperMethodInvoker cachedInvoker(Method method) throws Throwable {
try {
// Java8 中 Map 的方法,根据 key 获取值,如果值是 null,则把后面Object 的值赋给 key
// 如果获取不到,就创建
// 获取的是 MapperMethodInvoker(接口) 对象,只有一个invoke方法
return methodCache.computeIfAbsent(method, m -> {
if (m.isDefault()) {
// 接口的默认方法(Java8),只要实现接口都会继承接口的默认方法,例如 List.sort()
try {
if (privateLookupInMethod == null) {
return new DefaultMethodInvoker(getMethodHandleJava8(method));
} else {
return new DefaultMethodInvoker(getMethodHandleJava9(method));
}
} catch (IllegalAccessException | InstantiationException | InvocationTargetException
| NoSuchMethodException e) {
throw new RuntimeException(e);
}
} else {
// 创建了一个 MapperMethod
return new PlainMethodInvoker(new MapperMethod(mapperInterface, method, sqlSession.getConfiguration()));
}
});
} catch (RuntimeException re) {
Throwable cause = re.getCause();
throw cause == null ? re : cause;
}
}
这里针对Java8接口的默认方法做了些处理,这个地方不用特殊关注,我们重点看else逻辑:
// 创建了一个 MapperMethod
return new PlainMethodInvoker(
new MapperMethod(
mapperInterface,
method,
sqlSession.getConfiguration()));
Mybatis执行sql语句的真正开端:
❝上文中,我们费尽努力,获取到了 「PlainMethodInvoker」 实例,其实到这里,才是Mybatis执行SQL真正的起点。
❞
不要慌,继续跟上我的脚步,我们一鼓作气往后看。
上文中,我们知道Mapper对象实际上是Mapper接口的代理对象,而且是JDK的动态代理。
当执行Mapper的各种数据库操作方法时,实际上是调用的代理对象的方法,也就是invoke方法。
对于Mapper方法而言,其实就是调用的PlainMethodInvoker的invoke方法。
忘了?那么我们再复习一下这部分的代码:
// org.apache.ibatis.binding.MapperProxy#invoke
// 普通方法会走到 PlainMethodInvoker(内部类) 的 invoke
return cachedInvoker(method).invoke(proxy, method, args, sqlSession);
接着来看PlainMethodInvoker的invoke方法:
@Override
public Object invoke(
Object proxy,
Method method,
Object[] args,
SqlSession sqlSession) throws Throwable {
// SQL执行的真正起点
return mapperMethod.execute(sqlSession, args);
}
实际上这里的mapperMethod就是我们Mapper接口或者说XML文件中定义的方法名了。
❝接着就是重头戏,MapperMethod#execute 方法,完整代码我贴这儿了。
❞
// org.apache.ibatis.binding.MapperMethod#execute
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
switch (command.getType()) {
case INSERT: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
case UPDATE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.update(command.getName(), param));
break;
}
case DELETE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.delete(command.getName(), param));
break;
}
case SELECT:
if (method.returnsVoid() && method.hasResultHandler()) {
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) {
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) {
result = executeForMap(sqlSession, args);
} else if (method.returnsCursor()) {
result = executeForCursor(sqlSession, args);
} else {
Object param = method.convertArgsToSqlCommandParam(args);
// 普通 select 语句的执行入口 >>
result = sqlSession.selectOne(command.getName(), param);
if (method.returnsOptional()
&& (result == null || !method.getReturnType().equals(result.getClass()))) {
result = Optional.ofNullable(result);
}
}
break;
case FLUSH:
result = sqlSession.flushStatements();
break;
default:
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
}
重点看那个switch case,不用注释一眼看过去基本上也能看个八九不离十,这里就是通过sql的类型去执行不同的jdbc操作。
❝可以看到,熟悉的操作他来了,通过SqlSession完成一系列的数据库操作。
❞
我们的demo是一个查询操作,那么我们就挑select来看看。
普通select语句的入口如下:
result = sqlSession.selectOne(command.getName(), param);
继续深入:
// DefaultSqlSession#selectOne(java.lang.String, java.lang.Object)
@Override
public T selectOne(String statement, Object parameter) {
// 来到了 DefaultSqlSession
// Popular vote was to return null on 0 results and throw exception on too many.
List list = this.selectList(statement, parameter);
if (list.size() == 1) {
return list.get(0);
} else if (list.size() > 1) {
throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size());
} else {
return null;
}
}
可以看到是通过selectList来完成查询多个和单个。
@Override
public List selectList(String statement, Object parameter) {
// 为了提供多种重载(简化方法使用),和默认值
// 让参数少的调用参数多的方法,只实现一次
return this.selectList(statement, parameter, RowBounds.DEFAULT);
}
继续看多参重载方法:
@Override
public List selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
// 如果 cacheEnabled = true(默认),Executor会被 CachingExecutor装饰
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
核心代码就是executor.query,我们进去看看:
@Override
public List query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameter);
// 一级缓存和二级缓存的CacheKey是同一个
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
这里涉及到一级缓存和二级缓存,不是重点,我们就想看看最终是怎么执行的jdbc操作,那么就只需要继续看query重载。
// org.apache.ibatis.executor.BaseExecutor#query
@Override
public List query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
// 异常体系之 ErrorContext
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
// flushCache="true"时,即使是查询,也清空一级缓存
clearLocalCache();
}
List list;
try {
// 防止递归查询重复处理缓存
queryStack++;
// 查询一级缓存
// ResultHandler 和 ResultSetHandler的区别
list = resultHandler == null ? (List) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 真正的查询流程
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
...省略N行代码...
涉及到缓存的,通通与我无关,只看真正的查询流程 「queryFromDatabase」。
private List queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List list;
// 先占位
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// 三种 Executor 的区别,看doUpdate
// 默认Simple
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
// 移除占位符
localCache.removeObject(key);
}
// 写入一级缓存
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
看到jdbc了,胜利的曙光。
舒服,继续看doQuery方法,看到resultHandler了么,结果处理器,感觉离结果更近了。
// org.apache.ibatis.executor.SimpleExecutor#doQuery
@Override
public List doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
// 注意,已经来到SQL处理的关键对象 StatementHandler >>
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// 获取一个 Statement对象
stmt = prepareStatement(handler, ms.getStatementLog());
// 执行查询
return handler.query(stmt, resultHandler);
} finally {
// 用完就关闭
closeStatement(stmt);
}
}
查询用的Exucutor就是默认的SimpleExecutor,看到了熟悉的prepareStatement获取流程,基本上就到底层jdbc了。那么我们就看看 「prepareStatement(handler, ms.getStatementLog());」
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
Connection connection = getConnection(statementLog);
// 获取 Statement 对象
stmt = handler.prepare(connection, transaction.getTimeout());
// 为 Statement 设置参数
handler.parameterize(stmt);
return stmt;
}
看到这里,就到jdbc层面了,我们看到了熟悉的Connection,获取到connection之后再获取Statement。
这里的Statement就是java.sql的statement接口。
❝org.apache.ibatis.executor.statement.SimpleStatementHandler#query
❞
@Override
public List query(Statement statement, ResultHandler resultHandler) throws SQLException {
String sql = boundSql.getSql();
statement.execute(sql);
return resultSetHandler.handleResultSets(statement);
}
已经获取到了sql,通过Statement去执行sql,再通过resultSetHandler处理结果集。
通过Statement去执行sql
statement.execute(sql);
这里就已经是jdbc层面的操作了,通过与数据库建立的connection提交并执行sql。
通过resultSetHandler处理结果集
❝都到最后了,我们也不慌了,那么就看看org.apache.ibatis.executor.resultset.DefaultResultSetHandler#handleResultSets是如何处理结果集的。
❞
@Override
public List这么一坨代码,只需要重点看
handleResultSet(rsw, resultMap, null, parentMapping);
private void handleResultSet(ResultSetWrapper rsw, ResultMap resultMap, List看看handleRowValues的逻辑 (有点心累),一鼓作气再瞅两眼。
最终,来到了这个地方:
// org.apache.ibatis.executor.resultset.DefaultResultSetHandler
// #handleRowValuesForSimpleResultMap
private void handleRowValuesForSimpleResultMap(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler resultHandler, RowBounds rowBounds, ResultMapping parentMapping)
throws SQLException {
DefaultResultContext行了,不用再往下挖了,看到了熟悉的ResultSet获取结果集的操作,Mybatis执行sql的流程基本就结束了。
底层还是熟悉的JDBC操作。
小结
其实写了这么多,也没啥想总结的,我们通过一个查询操作,完整的把Mybatis从解析文件到执行sql,再到结果集处理都从源码级别剖析了一遍。
那么我们回答一下开头的问题:
我只是写了个Mapper接口,再配合xml或者注解,把SQL一写,就可以执行数据库操作,这是为何?
其实我们获取到的Mapper对象,已经是Mybatis帮我们生成的代理对象了,这个代理对象拥有与jdbc交互的一切必要条件。
都说Mybatis是对JDBC的封装,可是我却看不到JDBC相关的接口和对象,它们到哪里去了?
稍微往上翻翻,我们刚讲了,实际上最底层就是封装的jdbc的接口。
我们看不到但是用到了,并且用起来还很爽,这就是封装的魅力啊。
为什么在Spring中使用Mybatis,不用加@Repository/@Component之类的注解,就可以随用随注入(如:@Autowired)?
这个问题,就放到之后的文章讲解吧,那么就敬请期待下一篇:Mybatis与Spring的爱情故事(从源码层面解析,Mybatis是如何利用Spring扩展点,实现与Spring整合的。)
最后,贴张图,概括一下这个过程。图是借来的,仅供学习讨论,侵删。
❝创建会话工厂SqlSessionFactory
❞

❝创建会话SqlSession
❞
❝创建代理对象
❞

❝调用代理对象,执行SQL流程
❞

那么,不见不散。