
这十个事件,让“永不宕机”变成了一个笑话

源 / InfoQ 文/
这一年,那些“崩溃”过的互联网企业。
互联网技术发展到了 2022 年,理论上来说是可以做到“永不宕机”的。但过去的 2021 年,宕机事故看起来一点也没有减少。
随着“国民级应用”增多,大家对技术的依赖程度越来越高,面临的风险比以往任何时候都多。宕机影响的不仅是内部用户,连带还会影响到客户和合作伙伴的收入、信誉和生产力等各个方面。
宕机事故不可预测,因此它也被称为系统中的“黑天鹅”。当前大型互联网系统架构日趋复杂,稳定性风险也在升高,系统中一定会有一些黑天鹅潜伏着,只是还没被发现。然而墨菲定律告诉我们“该出错的终究会出错”。我们整理了 2021 年发生的十个重大宕机事件,并总结了故障原因。这些故障大部分是人为造成的,并且依然是我们在系统建设中需要特别注意的地方。
1 国内宕机事件:交待清楚故障原因也是一种能力
B 站崩溃,让年轻人无心睡觉
7 月 13 日晚间,视频网站哔哩哔哩(B 站)出现服务器宕机事故,无法登陆的用户涌向其它站点,连锁导致了一系列宕机事故。“B 站崩了”、“豆瓣崩了”、“A 站也崩了”、“晋江崩了”等接连冲上了热搜。
据数据显示,当时 B 站月活用户为 2.23 亿,其中 35 岁及以下的用户比重超过 86%。显然这些年轻人非常能熬夜,虽然宕机发生在深夜,但是大家吵吵闹闹地分析原因甚至还惊动了消防局。有网友认为“B 站崩了是因为有火情发生”,上海消防回复说:“经了解,位于上海市政立路 485 号国正中心内的哔哩哔哩弹幕网 B 站(总部)未出现火情,未接到相关报警。具体情况以站方公布为准。”
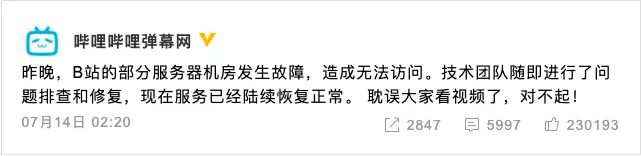
半夜 2 点之后,B 站终于发了一个非常简短的说明:“部分服务器机房发生故障,造成无法访问。”
只是 B 站这个解释,像是什么都说了,又像是什么都没说。
富途证券服务中断,创始人发 2000 字硬核长文解释技术故障
10 月 9 日凌晨,互联网券商富途证券 App 出现故障,用户无法登录进行交易。到了下午,富途证券发布了相关说明并致歉。富途证券表示,事故原因为“运营商机房电力闪断导致的多机房网络故障”,公司已于第一时间联系运营商进行修复,并在 2 小时内陆续恢复核心服务。
这次宕机本来并未引起证券行业之外的关注,但是随后富途创始人李华(叶子哥)的文章却让这次宕机事件火出了圈。11 日中午,技术出身的李华发布了一篇 2000 字长文,向用户致歉,文章里更多的篇幅却是从技术角度解释为什么会“宕机”。
虽然和 B 站一样是因为服务器机房故障,李华却从容灾设计的各个环节给了大家详细的说明。
李华表示,富途的证券系统中从行情到交易、从服务器到交易网关到网络传输都有做双路或多路的冗余设计。不同的子系统设计会有所不同。以行情为例,单向传输为主、对时延的敏感度也不是那么高,富途很早就作了多区域多 IDC 的容灾设计;尤其像美股行情,涉及到越洋传输,为避免中断,富途选择了全球顶级的两家行情供应商分别提供行情源,分别从美国、香港多地多点接入,当这些都不可用时,富途还保留了富途美国 IDC 直传的能力。不考虑其他的冗余设计,光是因为行情源的冗余,富途一年增加的成本过千万港元。
李华指出,在实时热备的多路冗余交易系统的设计上会面临着两种选择。一是较差的交易性能更大的订单延时但更好容灾能力的跨 IDC 多路冗余方案,二是更好的交易性能较小的订单提交延时单一 IDC 的多路冗余方案,但 IDC 本身会成为故障的单点。这也间接导致了一定要做出选择。在李华看来,考虑到 IDC 的建设标准,IDC 的大级别事故是罕见的,尤其是在电力故障方面。经过综合推演之后,富途选择了更好性能的方案二,也因此留下了 IDC 的单点故障隐患。这次事故恰恰就是 IDC 出了问题,而且是最不应该出现问题的电力系统出了问题,不间断电源和柴油发电机都没能发挥应有的作用。
李华的硬核文章也得到了很多富途证券用户的支持和鼓励。

西安“一码通”半个月崩溃两次
2021 年 12 月 20 日,西安“一码通”因访问量过大导致系统崩溃。当时西安市大数据资源管理局称,“一码通”注册用户已达 4695.2 万人,日均扫码量超 800 万人次。由于在各公共场所加大了扫码查验,同时开展多轮全员核酸检测,“一码通”每秒访问量达到以往峰值的 10 倍以上,并建议市民非必要不展码、亮码。
2022 年 1 月 4 日上午 9 时,西安“一码通”第二次崩溃。西安市开启新一轮核酸筛查,许多西安网友反应,“西安一码通”系统再次崩溃,无法显示疫情防控码。话题 # 西安一码通 # 一度冲上微博热搜第一。西安市相关部门公开回应称,因访问量太大,全市“一码通”均出现无法正常显示的问题。当天下午西安“一码通”已经逐步恢复正常使用。
据了解,西安“一码通”是 2020 年 2 月西安市针对疫情防控牵头开发的大数据平台,业主单位是西安市大数据资源管理局。据工信部官网 1 月 4 日的报道,12 月 30 日 -31 日,工信部曾对陕西省通信管理局展开疫情防控工作调研,并要求西安“一码通”加强技术改进和网络扩容,确保不拥塞宕机。
碰巧的是,2022 年 1 月 10 日上午 8:30 左右,不少用户反映“粤康码”打不开了。上午 10:00 之后,情况逐渐得到缓解。随后,“粤康码”App 发布了一个很专业的官方说明。
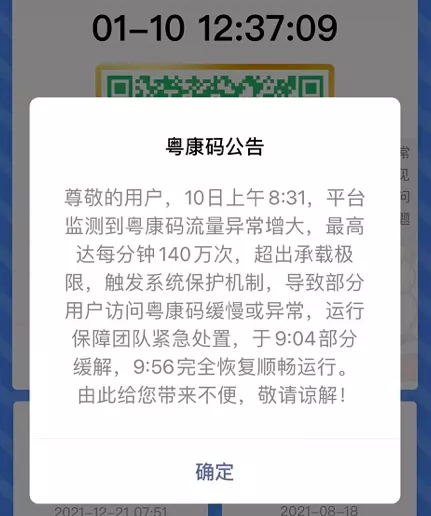
今天(10 日)上午 8:31,平台监测到粤康码流量异常增大,最高达每分钟 140 万次,超出承载极限,触发系统保护机制,导致部分用户访问粤康码缓慢或者异常,运行保障团队紧急处置,于 9:04 部分缓解,9:56 完全恢复顺畅运行。由此给您带来不便,敬请谅解!
2 国际宕机事件:小 Bug 引起大麻烦
Facebook 史上最严重宕机,市值一夜蒸发三千亿
10 月 4 日,美国社交媒体 Facebook、Instagram 和即时通讯软件 WhatsApp 出现大规模宕机,此次宕机长达近 7 个小时,刷新了 Facebook 自 2008 年以来的最长宕机时长。
WhatsApp 和 Facebook Messenger 两款“微信”类即时通信产品,分别在全球范围拥有 20 亿用户和 13 亿用户,社交平台 Instagram 用户数也达到了 10 亿用户,也就是说这次宕机影响了超 30 亿用户。宕机期间,绝望的用户涌向了 Twitter、Discord、Signal 和 Telegram,又导致这些应用程序的服务器纷纷崩溃。
Facebook 事后发表了故障报告,表示在一项日常维护工作中,工程师们发出一条用于评估全球骨干网容量可用性的指令,但意外切断了骨干网络中的所有连接,这实质上就是断开了 Facebook 全球数据中心之间的连接。服务中断之后,Facebook 的工程师们因无法通过正常方式访问 Facebook 数据中心进行修复,导致故障持续了 7 个小时之久。
据悉,这次事故让脸书一夜之间市值蒸发约 473 亿美元 (约合 3049 亿元人民币)。
Roblox 发生超长宕机,表示关键业务坚决不上云
10 月 28 日,Roblox 发生了一次长达 73 小时的宕机事故。Roblox 是目前在全球范围内备受欢迎的在线游戏平台,日活跃用户超过 5000 万,其中许多人的年龄在 13 岁或以下。值得一提的是,Roblox 还被认为是“元宇宙”(metaverse)的关键参与者。
Roblox 随后发布了非常详细的故障报告。在报告中,Roblox 的技术人员解释到,Roblox 程序运行在他们自己的数据中心中。为了管理自己众多的服务器,Roblox 使用了开源 Consul 进行服务发现、健康检查。Roblox 表示宕机主要是因启用了 Consul 里的流式传输功能代替长轮询机制,但流式传输功能存在 bug,最终导致性能下降而引起系统崩溃。宕机 54 个小时后才排查出故障原因,通过禁止流式传输功能,逐渐恢复了系统的服务能力。
在这样的服务中断之后,很多人很自然地询问 Roblox 是否会考虑迁移到公共云,让第三方管理 Roblox 的基础计算、存储和网络服务。
Roblox 技术人员表示,与使用公有云相比,自建数据中心能够显着控制成本。此外,拥有自己的硬件并构建自己的边缘基础设施能使 Roblox 最大限度地减少性能变化并管理全球玩家的延时。但也并不拘泥于任何特定的方法:“我们将公共云用于对我们的玩家和开发人员最有意义的用例,例如突发容量、大部分 DevOps 工作流程以及大部分内部分析。但对于对性能和延迟至关重要的工作负载,我们选择在本地构建和管理自己的基础架构。这样才能使我们能够建立一个更好的平台。”
Salesforce 工程师走捷径修 Bug 引起全球大宕机
Salesforce 是目前最受欢迎的云软件应用程序之一。据报道该软件应用程序已被全球大约 150,000 个组织中的数百万名员工使用。Salesforce 提供的服务涉及客户关系管理的各个方面,从普通的联系人管理、产品目录到订单管理、机会管理、销售管理等。用户无需花费大量资金和人力用于记录的维护、储存和管理,所有的记录和数据都储存在 Salesforce.com 上面。
5 月 11 日,Salesforce 的服务开始不可用,宕机持续了 5 个小时。事后,Salesforce 公司组织了一次客户简报会,完整披露了事件情况与相关工程师的操作流程。虽然 Salesforce 向来以高度自动化的内部业务流程为傲,但其中不少环节仍然只能手动操作完成——DNS 正是其中之一。工程师使用的配置脚本执行一项配置变更,变更后需要重启服务器生效,不幸的是,脚本更新发生超时失败。随后更新又在 Salesforce 各数据中心内不断部署,超时点也被不断引爆...... 对这位决心绕开既有管理政策、意外肇事的工程师本人,Salesforce 表示“我们已经对这位员工做出了适当处理。”
3 云计算相关服务提供商:一旦出岔子,“爆炸半径”就很大!
云计算巨头 OVH 数据中心失火,360 万个网站被迫下线
3 月份,欧洲云计算巨头 OVH 位于法国斯特拉斯堡的机房近日发生严重火灾,该区域总共有 4 个数据中心 (Strasbourg Data Center),发生起火的 SBG2 数据中心被完全烧毁,另有一个数据中心 SBG1 的建筑物部分受损。当地报纸称 115 位消防员投入 6 个小时才将其扑灭。经过长达 6 个小时的持续燃烧,SBG2 内的数据应该会损失惨重。
这场大火对欧洲范围内的众多网站造成严重影响。据悉,总共有跨 464000 个域的多达 360 万个网站下线。
受到此次大火影响的客户包括欧洲航天局的数据与信息访问服务 ONDA 项目,此项目负责为用户托管地理空间数据并在云端构建应用程序。Rust 旗下的游戏工作室 Facepunch Studios 证实,有 25 台服务器被烧毁,他们的数据已在这场大火中全部丢失。即使数据中心重新上线后,也无法恢复任何数据。其他客户还包括法国政府,其 data.gouv.Fr 网站也被迫下线。另外还有加密货币交易所 Deribit,以及负责跟踪 DDoS 僵尸网络与其他网络滥用问题的信息安全威胁情报厂商 Bad Packets......
其中还有些人很不走运:“不!!!我靠!!!我的服务器在机架 70C09 上,我就是个普通客户,我没有任何灾难恢复计划……”
搞瘫全球大半个互联网,Fastly 是何方神圣?
6 月 8 日,当全球各地数以亿计的互联网用户登陆自己平日经常登陆的网站时,发现页面无法打开,并出现了“503 Errors”的错误提示,包括亚马逊、Twitter、Reddit、Twitch、HBO Max、Hulu、PayPal、Pinterest 以及包括纽约时报、CNN 等在内的各种类型的网站均悉数中招。
大约持续了一个小时之后,人们才发现这场大规模故障是由 CDN 服务公司 Fastly 引起的。Fastly 通过其官方推特和博客称,“我们发现一个服务配置的更改引发了全球服务的短暂中断,目前已将这一配置关闭,我们全球服务网络已恢复正常。”

于 2011 年成立的 Fastly 是全球为数不多的大型 CDN 供应商之一,可加快用户浏览速度和体验。有意思的是,出问题之后 Fastly 的股价在当天出现大涨,因为通过这起事件,投资者意识到,这家总部位于旧金山,员工数不到 1000 人的小公司,对互联网世界有着举足轻重的影响力。
谷歌云全球宕机 2 小时
11 月 16 日,据国外媒体报道,全球最大的云服务提供商之一谷歌云(Google Cloud)出现了宕机,导致许多依赖于谷歌云的大型公司网站中断服务。
中断持续约 2 个小时,其中包括家得宝、Spotify 等公司都接到用户关于服务中断的反馈,另外 Etsy 和 Snap 的服务也发生网络故障。此外本次宕机对谷歌自家服务影响颇深,YouTube、Gmail、Google Search 均停止了工作。
据悉此事件是谷歌云用户错误配置外部代理负载平衡 (GCLB) 所导致,算是一个漏洞,在 6 个月前被引入,极少数情况下,该漏洞允许损坏的配置文件被推送到 GCLB。11 月 12 日,一位 Google 工程师就发现此漏洞。谷歌原计划于 11 月 15 日推出补丁,但是不巧的是还没修复完,服务中断就发生了。
AWS 一个月内发生 3 次宕机
在 2021 年的最后一个月,AWS 发生了 3 次宕机。第一次宕机发生美国东部时间 7 日,从上午 10 点 45 分持续到下午 2 点 22 分,包括迪斯尼、奈飞、Robinhood、Roku 等大量热门网站和应用都发生了网络中断。同时,亚马逊的 Alexa AI 助理、Kindle 电子书、亚马逊音乐、Ring 安全摄像头等业务也受到影响。
12 月 10 日,AWS 公布了本次宕机的原因:某内部客户端的意外行为导致连接活动激增,使内部网络和主 AWS 网络之间的联网设备不堪重负,从而导致这些网络之间的通信延迟。这些延迟增加了在网络之间通信的服务延迟和错误,从而导致更多的连接尝试和重试,最终引发持续的堵塞和性能问题。
12 月第二次宕机发生在 16 日上午 7 点 43 分左右,包括 Twitch、Zoom、PSN、Xbox Live、Doordash、Quickbooks Online 和 Hulu 等在线服务均受到影响。AWS 随后公布了故障原因:由于主网络中某自动化软件原因,错误得将一些流量转移到主干网,结果影响了一些互联网应用的连接。
12 月第三次宕机发生在 23 日美国东部时间 7 点 30 分左右,包括 Slack、Epic Games、加密货币交易所 Coinbase Global、游戏公司 Fortnite 、约会应用程序 Grindr 和交付公司 Instacart。对于此次中断,AWS 初步调查称是数据中心供电的问题。
最后,希望 2022 年大家都不会经历宕机~
end

顶级程序员:topcoding
做最好的程序员社区:Java后端开发、Python、大数据、AI
一键三连「分享」、「点赞」和「在看」