
Elasticsearch 高基数聚合性能提升3倍,改动了什么?
1、上问题
这是来自球友实战问题。
大致需求介绍如下:
约 3600 万的数据,其中关键字段如下所示:
| _id | creator |
|---|---|
| doc_1 | [张三,李四,王五,赵六] |
| doc_2 | [陈胜,吴广,张三] |
用 cardinality 聚合统计,creator 的个数有约 1300 万。
问题:但在高基数(high cardinality)的情形下,性能不理想。
2、概念解读:什么是高基数?
为了更精确解读,这里直接拿:Elastic 官方博客只字不差的翻译。
The performance of terms aggregations can be greatly impacted by the cardinality of the field that is being aggregated.
Cardinality refers to the uniqueness of values stored in a particular field.
High cardinality means that a field contains a large percentage of unique values.
Low cardinality means that a field contains a lot of repeated values.
For example, a field storing country names will be relatively low cardinality since there are less than two hundred countries in the world. Alternatively, a field storing IBAN numbers or email addresses is high cardinality since there may be millions of unique values stored.
terms 聚合的性能可能会受到所聚合字段的基数的极大影响。
基数(Cardinality)是指存储在特定字段中的值的唯一性。
高基数:意味着一个字段包含很大比例的唯一值。
举例:电子邮件地址可能会有数千万+唯一值,属于高基数。(换了举例)
低基数:意味着一个字段包含很多重复的值。
举例:因为世界上少于200个国家,国家名称就是低基数。
3、问题本质
经反复讨论,本质问题:高基数业务场景下,聚合慢,达不到预期。
我记得刚入职场,我向导师的导师(辈分应该是:师爷)当面请教一个问题,我说了很长,他实在听不下去了,就说了一句:“你的问题是什么?”,一语惊醒梦中人,我一直记到今天。
后面当我再向别人请教问题的时候,我都提前打好草稿、列好提纲,快速且直接说出重点、交流效率提升不少。
毫不夸张的说,能用简短的话描述清楚问题,问题就能基本解决了一大半。
4、怎么改进呢?
经反复讨论,结合球友之前的实践,思路如下:
第一 :对于字段值,存储Hash值(写入时处理)。
第二 :基于Hash 做聚合和统计分析操作。
5、Elasticsearch 有 Hash 值类型吗?
早期版本(7.X 之前)没有,但是 7.X 之后有。
如下借助 mapper-murmur3 插件实现:
插件地址:
https://www.elastic.co/guide/en/elasticsearch/plugins/7.2/mapper-murmur3.html
murmur3 需要着重介绍一下:
维基百科解读:MurmurHash 是一种非加密型哈希函数,适用于一般的哈希检索操作。
由 Austin Appleby 在 2008年发明, 并出现了多个变种,都已经发布到了公有领域(public domain)。
与其它流行的哈希函数相比,对于规律性较强的 key,MurmurHash的随机分布特征表现更良好。
Redis 在实现字典时用到了两种不同的哈希算法,MurmurHash 便是其中一种(另一种是djb),在 Redis 中应用十分广泛,包括数据库、集群、哈希键、阻塞操作等功能都用到了这个算法。
发明算法的作者被邀到 google 工作,该算法最新版本是 MurmurHash3 , 基于MurmurHash2改进了一些小瑕疵,使得速度更快,实现了 32 位(低延时)、128 位 HashKey,尤其对大块的数据,具有较高的平衡性与低碰撞率。
6、mapper-murmur3 插件实践一把
第一步:插件安装
bin/elasticsearch-plugin install mapper-murmur3
第二步:导入Demo测试
PUT my_index
{
"mappings": {
"properties": {
"my_field": {
"type": "keyword",
"fields": {
"hash": {
"type": "murmur3"
}
}
}
}
}
}
PUT my_index/_doc/1
{
"my_field": "This is a document"
}
PUT my_index/_doc/2
{
"my_field": "This is a document"
}
GET my_index/_search
{
"aggs": {
"my_field_cardinality": {
"terms": {
"field": "my_field.hash"
},
"aggs": {
"top_sales_hits": {
"top_hits": {
"size": 2
}
}
}
}
}
}
聚合结果如下:
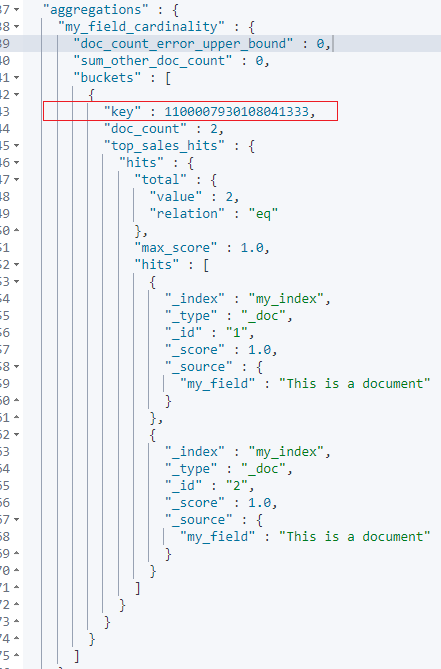
这时候,就能比较清晰的看出murmur3的作用:
属于 Mapping的特定字段类型。 可以和keyword类型组合当做复合类型使用。 _source 不存储结果值。 只在聚合后才能看到结果。
7、加了 mapper-murmur3 Hash 后效果如何呢?
球友实践反馈如下:

8、在相对低基数聚合性能如何呢?
实战一把。
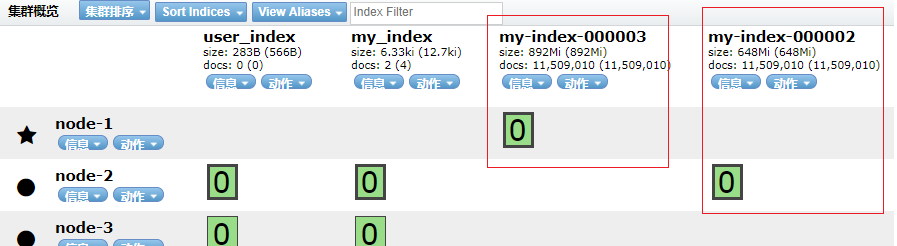
8.1 模拟生成 1000W+数据。
文本文件输入了 39415 name信息(随机生成)。通过 python-dsl 随机生成写入 ES集群。
写入结果如下所示:
索引1:
PUT my-index-000002
{
"mappings": {
"properties": {
"creator":{
"type":"keyword"
}
}
}
}
索引2:
PUT my-index-000003
{
"mappings": {
"properties": {
"creator": {
"type": "keyword",
"fields": {
"hash": {
"type": "murmur3"
}
}
}
}
}
}
8.2 低基数有多低?
POST my-index-000002/_search
{
"size": 0,
"aggs": {
"count_aggs": {
"cardinality": {
"field": "creator"
}
}
}
}
去重后的结果:39415。 原始数据量:11509010。 占比:0.342%
虽然高、低基数没有明确数据量多少的定义,但,这明显是低基数。
8.2 聚合结果对比
POST my-index-000002/_search
{
"aggs": {
"terms_agg": {
"terms": {
"field":"creator",
"size":3,
"shard_size":1000
}
}
}
}
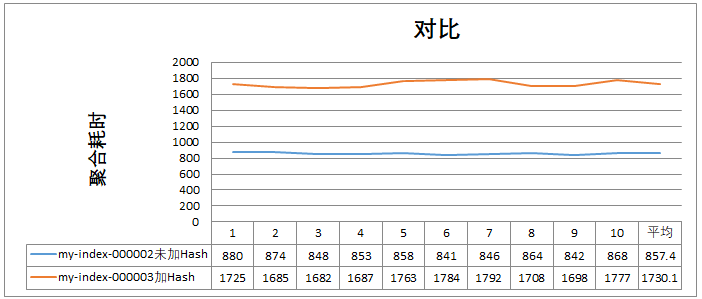
如上所示 ,未加Hash的索引聚合要被加了Hash 的快一倍!
这也初步说明:Hash 在低基数聚合没有效果。
9、小结
以上验证和测试仅供参考,实际选型需要结合业务场景实际,进行充分验证后再做定夺。
类似高基数聚合业务场景,你实践中的优化点是什么?欢迎留言交流。
参考:
https://www.elastic.co/cn/blog/improving-the-performance-of-high-cardinality-terms-aggregations-in-elasticsearch
https://cloud.tencent.com/developer/article/1421924
加微信:elastic6(仅有少量坑位了),和 BAT 大佬一起精进 Elastic 技术!
推荐阅读:
更短时间更快习得更多干货!