TiDB 原理 | TiDB 数据一致性校验实现:Sync-diff-inspector 优化方案
作者介绍
简介
在数据同步的场景下,上下游数据的一致性校验是非常重要的一个环节,缺少数据校验,可能会对商业决策产生非常负面的影响。Sync-diff-inspector 是 PingCAP Data Platform 团队开发的一款一致性校验工具,它能对多种数据同步场景的上下游数据进行一致性校验,如多数据源到单一目的(MySQL 中分库分表到 TiDB 中)、单一源到单一目的( TiDB 表到 TiDB 表)等,在数据校验过程中,其效率和正确性是至关重要的。首先我们看下 Sync-diff-inspector 的架构图,对 Sync-diff-inspector 的作用和实现原理有一个大致的认知。
Sync-diff-inspector 2.0 架构图
Why Sync-diff-inspector 2.0 ?
在 1.0 版本中,我们遇到客户反馈的一些问题,包括:
针对大表进行一致性校验时出现 TiDB 端发生内存溢出。
不支持 Float 类型数据校验的问题。
结果输出对用户不友好,需要对校验结果进行精简。
检验过程中发生 GC,导致校验失败。
采用单线程划分 Chunk,该表中所有已被划分的 Chunk 需要等待该表中所有 Chunk 全部被划分才会开始进行比对,这会导致这段时间内,TiKV 的使用率降低
Checkpoint 功能将校验过的每个 Chunk 的状态写入数据库,所以写入数据库的 IO 成为校验过程的瓶颈。
当 chunk 范围内的 checksum 不同时,直接进行按行比对,消耗大量 IO 资源。
缺少自适应 GC 的功能,导致正在校验的 Snapshot 被 GC,使得校验失败
Sync-diff-inspector 2.0 新特性
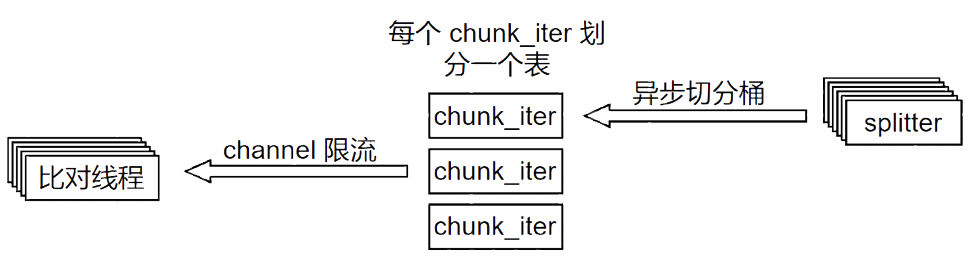
Chunk 划分
chunk 划分过程中可能由于 chunk 的预定大小小于一个桶的大小,需要切分这个桶为若干个 chunk,这是个相对比较慢的过程,因此消费端也就是 chunk 的比对线程会出现等待的情况,资源利用率会降低。这里采用两种处理方法:采用多个桶异步划分来提高资源利用率;有些表没有桶的信息,因此只能把整个表当作一个桶来切分,采用多表划分来提高总体的异步划分桶数。 chunk 的划分也会占用一定的资源,chunk 划分过快会一定程度减慢 chunk 比对的速度,因此这里在消费端通过 channel 来限制多表划分chunk的速度。
Checkpoint 和修复 SQL
如果先写入修复 SQL 的记录,那么此时程序异常退出,这个被写入修复 SQL 但没被 checkpoint 记录的 chunk 会在下一次生成,一般情况下,这个修复 SQL 文件会被重新覆盖。但是由于桶的切分是随机分的,因此尽管切分后的 chunk 个数固定,上一次检查出的不同行在切分后 chunks 的第三个,这次可能跑到了第四个chunk 的范围内。这样就会存在重复的修复 SQL。 如果先写入 checkpoint,那么此时程序异常退出,下一次执行会从该 checkpoint 记录的 chunk 的后面范围开始检验,如果该 chunk 存在修复 SQL 但还没有被记录,那么这个修复 SQL 信息就丢失了。
二分校验和自适应 chunkSize
索引处理
where 处理
((a > 1) OR (a = 1 AND b > 2) OR (a = 1 AND b = 2 AND c > 3))
((a < 1) OR (a = 1 AND b < 2) OR (a = 1 AND b = 2 AND c <= 4))
自适应 GC
处理 Float 列
用户交互优化
将日志写入到日志文件中。
在前台显示进度条,并提示正在比较的表。
记录每个表校验相关结果,包括整体对比时间、对比数据量、平均速度、每张表对比结果和每张表的配置信息。
生成的修复 SQL 信息。
一定时间间隔记录的 checkpoint 信息。
性能提升
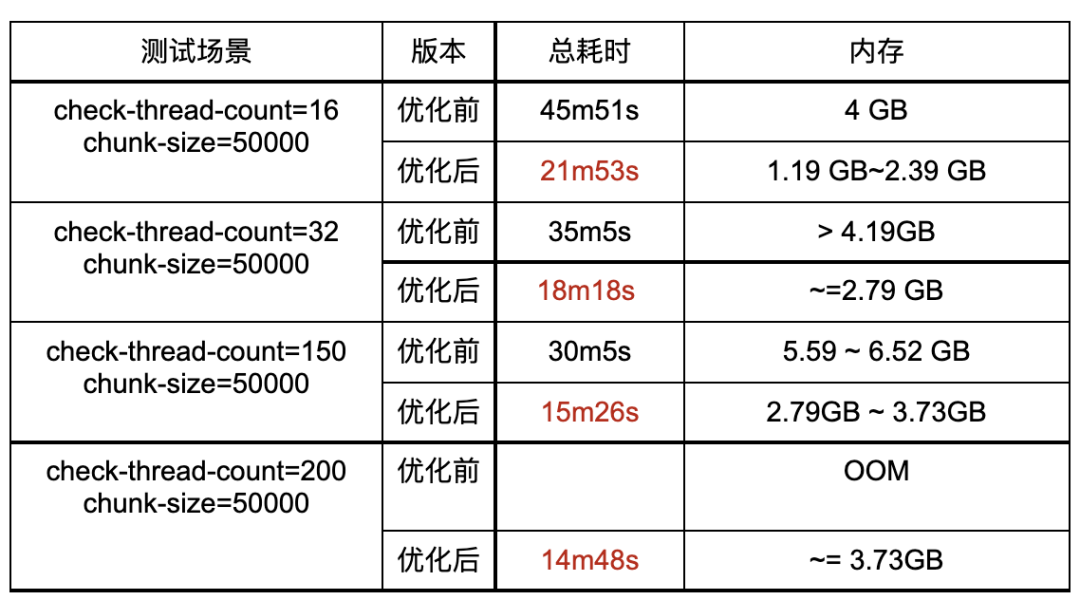
从测试结果可以看出,Sync-diff-inspector 2.0 相比于原版, 校验速度有明显提升,同时在TiDB 端内存占用显著减少。
未来展望
开放性的架构
支持更多类型
更激进的二分 checksum