
如何保证缓存与数据库的双写一致性?

- 前言 -
- Cache Aside Pattern -
读的时候,先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。
- 为什么是删除缓存,而不是更新缓存 -
- 最初级的缓存不一致问题及解决方案 -
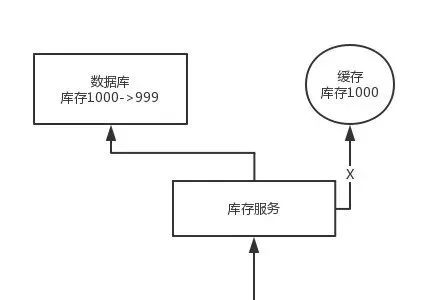
- 比较复杂的数据不一致问题分析 -
- 如何解决? -
解决方案如下:
1、读请求长时阻塞
2、读请求并发量过高
3、多服务实例部署的请求路由
4、热点商品的路由问题,导致请求的倾斜
作者:你是我的海啸
来源:
https://blog.csdn.net/chang384915878

评论