
详解:元数据管理实践
什么是元数据?元数据MetaData狭义的解释是用来描述数据的数据,广义的来看,除了业务逻辑直接读写处理的那些业务数据,所有其它用来维持整个系统运转所需的信息/数据都可以叫作元数据。比如数据表格的Schema信息,任务的血缘关系,用户和脚本/任务的权限映射关系信息等等。
管理这些附加MetaData信息的目的,一方面是为了让用户能够更高效的挖掘和使用数据,另一方面是为了让平台管理人员能更加有效的做好系统的维护管理工作。

出发点很好,但通常这些元数据信息是散落在平台的各个系统,各种流程之中的,而它们的管理也可能或多或少可以通过各种子系统自身的工具,方案或流程逻辑来实现。那么我们所说的元数据管理平台又是用来做什么的?是不是所有的信息都应该或者有必要收集到一个系统中来进行统一管理呢,具体又有哪些数据应该被纳入到元数据管理平台的管理范围之中呢?下面我们就来探讨一下相关的内容。
元数据管理平台管什么
数据治理的第一步,就是收集信息,很明显,没有数据就无从分析,也就无法有效的对平台的数据链路进行管理和改进。所以元数据管理平台很重要的一个功能就是信息的收集,至于收集哪些信息,取决于业务的需求和我们需要解决的目标问题。

信息收集再多,如果不能发挥作用,那也就只是浪费存储空间而已。所以元数据管理平台还需要考虑如何以恰当的形式对这些元数据信息进行展示,进一步的,如何将这些元数据信息通过服务的形式提供给周边上下游系统使用,真正帮助大数据平台完成质量管理的闭环工作。
应该收集那些信息,虽然没有绝对的标准,但是对大数据开发平台来说,常见的元数据信息包括:
数据的表结构Schema信息
数据的空间存储,读写记录,权限归属和其它各类统计信息
数据的血缘关系信息
数据的业务属性信息
下面我们针对这四项内容再具体展开讨论一下
数据的表结构Schema信息
数据的表结构信息,这个很容易理解了,狭义的元数据信息通常多半指的就是这部分内容了,它也的确属于元数据信息管理系统中最重要的一块内容。
不过,无论是SQL还是NoSQL的数据存储组件,多半自身都有管理和查询表格Schema的能力,这也很好理解如果没有这些能力的话,这些系统自身就没法良好的运转下去了不是。比如,Hive自身的表结构信息本来就存储在外部DB数据库中,Hive也提供类似 show table,describe table之类的语法对这些信息进行查询。那么我们为什么还要多此一举,再开发一个元数据管理系统对这些信息进行管理呢?
这么做,可能的理由很多,需要集中管理可以是其中一个理由,但更重要的理由,是因为本质上,这些系统自身的元数据信息管理手段通常都是为了满足系统自身的功能运转而设计的。也就是说,它们并不是为了数据质量管理的目的而存在的,由于需求定位不同,所以无论从功能形态还是从交互手段的角度来说,它们通常也就无法直接满足数据质量管理的需求。
举个很简单的例子,比如我想知道表结构的历史变迁记录,很显然多数系统自身是不会设计这样的功能的。而且一些功能就算有,周边上下游的其它业务系统往往也不适合直接从该系统中获取这类信息,因为如果那样做的话,系统的安全性和相互直接的依赖耦合往往都会是个问题。

所以,收集表结构信息,不光是简单的信息汇总,更重要的是从平台管理和业务需求的角度出发来考虑,如何整理和归纳数据,方便系统集成,实现最终的业务价值。
数据的存储空间,读写记录,权限归属和其它各类统计信息
这类信息,可能包括但不限于:数据占据了多少底层存储空间,最近是否有过修改,都有谁在什么时候使用过这些数据,谁有权限管理和查阅这些数据等等。此外,还可以包括类似昨天新增了多少个表格,删除了多少表格,创建了多少分区之类的统计信息。
在正常的工作流程中,多数人可能不需要也不会去关心这类信息。但是落到数据质量管理这个话题上时,这些信息对于系统和业务的优化,数据的安全管控,问题的排查等工作来说,又往往都是不可或缺的重要信息,所以通常这类信息也可以从Audit审计的角度来归类看待。
与表结构信息类似,对于这类Audit审计类信息的采集和管理,通常具体的底层数据存储管理组件自身的功能也无法直接满足我们的需求,需要通过专门的元数据管理平台中统一进行采集,加工和管理。
数据的血缘关系信息
血缘信息或者叫做Lineage的血统信息是什么,简单的说就是数据之间的上下游来源去向关系,数据从哪里来到哪里去。知道这个信息有什么用呢?用途很广,举个最简单的例子来说,如果一个数据有问题,你可以根据血缘关系往上游排查,看看到底在哪个环节出了问题。此外我们也可以通过数据的血缘关系,建立起生产这些数据的任务之间的依赖关系,进而辅助调度系统的工作调度,或者用来判断一个失败或错误的任务可能对哪些下游数据造成影响等等。
分析数据的血缘关系看起来简单,但真的要做起来,并不容易,因为数据的来源多种多样,加工数据的手段,所使用的计算框架可能也各不相同,此外也不是所有的系统天生都具备获取相关信息的能力。而针对不同的系统,血缘关系具体能够分析到的粒度可能也不一样,有些能做到表级别,有些甚至可以做到字段级别。
以hive表为例,通过分析hive脚本的执行计划,是可以做到相对精确的定位出字段级别的数据血缘关系的。而如果是一个MapReduce任务生成的数据,从外部来看,可能就只能通过分析MR任务输出的Log日志信息来粗略判断目录级别的读写关系,从而间接推导数据的血缘依赖关系了。
数据的业务属性信息
前面三类信息,一定程度上都可以通过技术手段从底层系统自身所拥有的信息中获取得到,又或着可以通过一定的流程二次加工分析得到。与之相反,数据的业务属性信息,通常与底层系统自身的运行逻辑无关,多半就需要通过其他手段从外部获取了。
那么,业务属性信息都有哪些呢?最常见的,比如,一张数据表的统计口径信息,这张表干什么用的,各个字段的具体统计方式,业务描述,业务标签,脚本逻辑的历史变迁记录,变迁原因等等,此外,你也可能会关心对应的数据表格是由谁负责开发的,具体数据的业务部门归属等等。
上述信息如果全部需要依靠数据开发者的自觉填写,不是不行,但是显然不太靠谱。毕竟对于多数同学来说,对于完成数据开发工作核心链路以外的工作量,很自然的反应就是能不做就不做,越省事越好。如果没有流程体系的规范,如果没有产生实际的价值,那么相关信息的填写很容易就会成为一个负担或者是流于形式。
所以,尽管这部分信息往往需要通过外部手段人工录入,但是还是需要尽量考虑和流程进行整合,让它们成为业务开发必不可少的环节。比如,一部分信息的采集,可以通过整体数据平台的开发流程规范,嵌入到对应数据的开发过程中进行,例如历史变迁记录可以在修改任务脚本或者表格schema时强制要求填写;业务负责人信息,可以通过当前开发人员的业务线和开发群组归属关系自动进行映射填充;字段统计方式信息,尽可能通过标准的维度指标管理体系进行规范定义。
总体来说,数据的业务属性信息,必然首先是为业务服务的,因此它的采集和展示也就需要尽可能的和业务环境相融合,只有这样才能真正发挥这部分元数据信息的作用。
元数据管理相关系统方案介绍
Apache Atlas
社区中开源的元数据管理系统方案,常见的比如Hortonworks主推的Apache Atlas,它的基本架构思想如下图所示
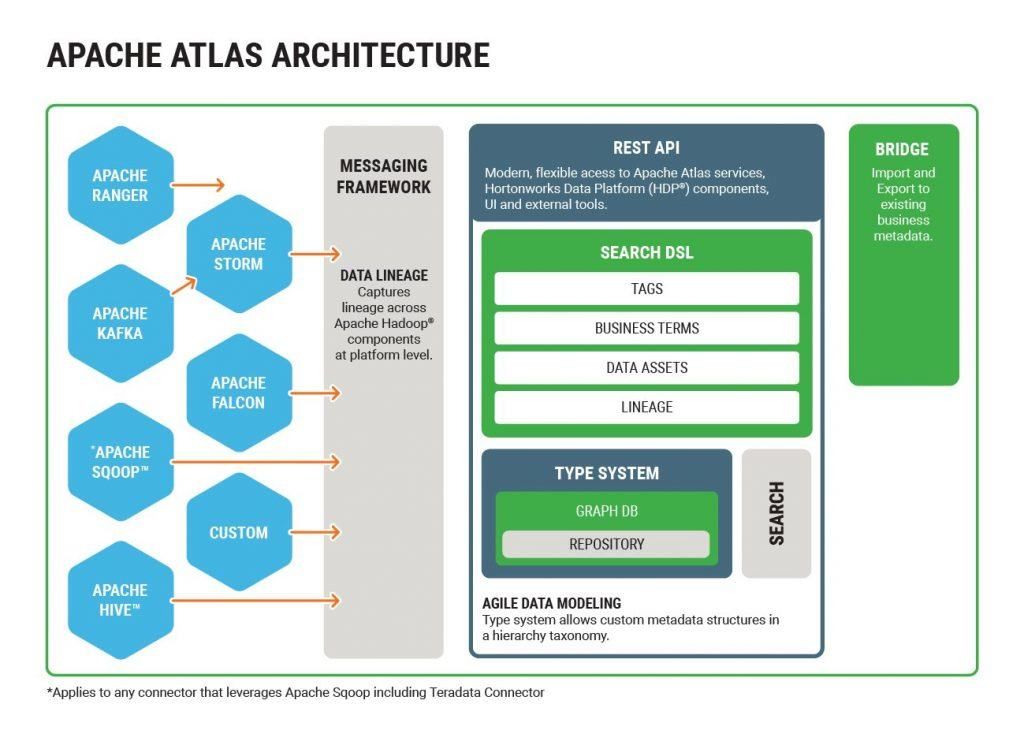
Atlas的架构方案应该说相当典型,基本上这类系统大致都会由元数据的收集,存储和查询展示三部分核心组件组成。此外,还会有一个管理后台对整体元数据的采集流程以及元数据格式定义和服务的部署等各项内容进行配置管理。
对应到Atlas的实现上,Atlas通过各种hook/bridge插件来采集几种数据源的元数据信息,通过一套自定义的Type 体系来定义元数据信息的格式,通过搜索引擎对元数据进行全文索引和条件检索,除了自带的UI控制台意外,Atlas还可以通过Rest API的形式对外提供服务。
Atlas的整体设计侧重于数据血缘关系的采集以及表格维度的基本信息和业务属性信息的管理。为了这个目的,Atlas设计了一套通用的Type体系来描述这些信息。主要的Type基础类型包括DataSet和Process,前者用来描述各种数据源本身,后者用来描述一个数据处理的流程,比如一个ETL任务。
Atlas现有的Bridge实现,从数据源的角度来看,主要覆盖了Hive,HBase,HDFS和Kafka,此外还有适配于Sqoop, Storm和Falcon的Bridge,不过这三者更多的是从Process的角度入手,最后落地的数据源还是上述四种数据源。
具体Bridge的实现多半是通过上述底层存储,计算引擎各自流程中的Hook机制来实现的,比如Hive SQL的Post Execute Hook,HBase的Coprocessor等,而采集到的数据则通过Kafka消息队列传输给Atlas Server或者其它订阅者进行消费。
在业务信息管理方面,Atlas通过用户自定义Type 属性信息的方式,让用户可以实现数据的业务信息填写或者对数据打标签等操作,便于后续对数据进行定向过滤检索。
最后,Atlas可以和Ranger配套使用,允许Ranger通过Atlas中用户自定义的数据标签的形式来对数据进行动态授权管理工作,相对于基于路径或者表名/文件名的形式进行静态授权的方式,这种基于标签的方式,有时候可以更加灵活的处理一些特定场景下的权限管理工作。
总体而言,Atlas的实现,从结构原理的角度来说,还算是比较合理的,但从现阶段来看,Atlas的具体实现还比较粗糙,很多功能也是处于可用但并不完善的状态。此外Atlas在数据审计环节做的工作也不多,与整体数据业务流程的集成应用方面的能力也很有限。Atlas项目本身很长时间也都处于Incubator状态,因此还需要大家一起多努力来帮助它的改进。
Cloudera Navigator Data Management
另外一个比较常见的解决方案是Cloudera CDH发行版中主推的Navigator,相比Atlas而言,Navigator的整体实现更加成熟一些,更像一个完整的解决方案,不过,Navigator并不是开源的,也难怪,毕竟要卖钱的的东西,也就更有动力去完善 ;)
Navigator的产品定位是Data Management数据管理,本质上也是通过管理元数据来管理数据,但周边工具和配套设施相对完善,和Cloudera Manager管理后台的产品集成工作也做得比较彻底。相比Atlas来说,Navigator的整体组件架构也更加复杂一些。Navigator的大致组件架构如下图所示
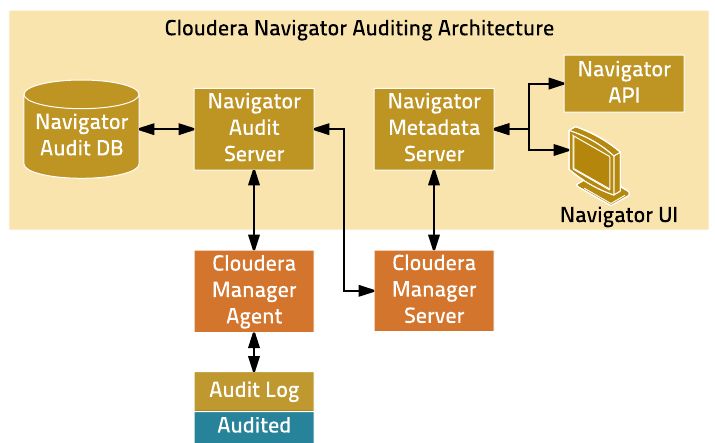
Navigator定位为数据管理,所以对数据的审计管理方面的工作也会做得更多一些,除了采集和管理Hive/Impala等表格的血缘信息,Navigator也可以配置采集包括HDFS的读写操作记录,Yarn/Spark/Pig等作业的运行统计数据在内的信息。Navigator同时还为用户提供了各种统计分析视图和查询管理工具来分析这些数据。
从底层实现来看,Navigator同样通过Hook或着Plugin插件的形式从各种底层系统的运行过程中获取相关信息。但与Atlas不同的是,Navigator的元数据采集传输处理流程并没有把这些信息写入到消息队列中,而是主要通过这些插件写入到相关服务所在的本地Log文件中,然后由Cloudera Manager在每台服务节点上部署的Agent来读取,过滤,分析处理并传输这些信息给Audit Server。
此外Navigator还通过独立的Metadata Server来收集和分析一些非Log来源的元数据信息,并统一对外提供元数据的配置管理服务。用户还可以通过配置Policy策略,让Metadata Server自动基于用户定义的规则,替用户完成数据的Tag标签打标工作,进而提升数据自动化自治管理的能力。
总体而言,Navigator和Cloudera Manger的产品集成工作做得相对完善,如果你使用CDH发行版全家福套件来管理你的集群的话,使用Navigator应该是一个不错的选择。不过,如果是自主管理的集群或者自建的大数据开发平台,深度集成定制的Navigator就很难为你所用了,但无论如何,对于自主开发的元数据管理系统来说,Navigator的整体设计思想也还是值得借鉴的。
蘑菇街元数据管理系统实践
蘑菇街大数据平台的元数据管理系统,大体的体系架构思想和上述系统也比较类似,不过,客观的说我们的系统的开发是一个伴随着整体开发平台的需求演进而渐进拓展的过程,所以从数据管理的角度来说,没有上述两个系统那么关注数据格式类型系统的普遍适用性。比如Schema这部分信息的管理,就主要侧重于表格类信息的管理,比如Hive,HBase等,而非完全通用的类型系统。但相对的,在对外服务方面,我们也会更加注重元数据管理系统和业务系统应用需求的关联,架构大同小异,下面主要简单介绍一下产品交互形态和一些特殊的功能特效设定等。
如图所示,是我们的元数据管理系统的产品后台针对Hive表格元数据信息的部分查询界面,主要为用户提供表格的各种基础schema信息,业务标签信息,血缘关系信息,样本数据,以及底层存储容量星系,权限和读写修改记录等审计信息。

除了表格元数据信息管理以外,我们的元数据管理系统主要的功能之一是“业务组”的管理,业务组的设计目标是贯穿整个大数据开发平台的,做为大数据开发平台上开发人员的自主管理单元组织形式。将所有的数据和任务的管理工作都下放到业务组内部由业务组管理员管理。
从元数据管理系统的角度来说,业务组的管理,包括数据和任务与业务组的归属关系映射,业务组内角色的权限映射关系等,此外,为了适应业务的快速变化,也给用户提供的数据资产的归属关系转移等功能。
总体来说,业务组的管理功能,更多的是需要和大数据开发平台的其它组件相结合,比如和集成开发平台IDE相结合,在开发平台中提供基于业务组的多租户开发环境管理功能,再比如与调度系统相结合,根据任务和数据的业务组归属信息,在任务调度时实施计算资源的配额管理等。
最后,关于数据的血缘关系跟踪,再多说两句。在Atlas和navigator中,主要通过计算框架自身支持的运行时hook来获得数据相关元数据和血缘相关信息,比如hive的hook是在语法解析阶段,storm的hook是在topology submit阶段。

这么做的优点是血缘的追踪分析是基于真实运行任务的信息进行分析的,如果插件部署全面,也不太会有遗漏问题,但是这种方式也有很多不太好解决的问题,比如
如何更新一个历史上有依赖后来不再依赖的血缘关系
对于一个还未运行的任务,不能提前获取血缘信息
临时脚本或者错误的脚本逻辑对血缘关系数据的污染
简单总结一下,就是基于运行时的信息来采集血缘关系,由于缺乏静态的业务信息辅助,如何甄别和更新血缘关系的生命周期和有效性会是一个棘手的问题,一定程度上也限制了应用的范围。
我们的做法是,血缘信息的采集不是在运行时动进行的,而是在脚本保存时进行的。由于开发平台统一管理了所有用户的任务脚本,所以,我们可以对脚本进行静态的分析,加上脚本本身业务信息,执行情况和生命周期对开发平台是可知的。所以一定程度上能解决上述提到的几个问题。
当然,这种方案也有自己的短板需要克服,比如:如果脚本管控不到位,血缘关系分析可能覆盖不全;血缘关系是基于最新的脚本的静态的逻辑关系,无法做到基于某一次真实的运行实例进行分析。不过,这些短板对我们来说从需求的角度来说都不是很核心的问题,又或者通过周边系统的配套建设可以在一定程度上加以解决克服的。
本文转自网络,由于无法追述来源,如有侵删。
推荐阅读: