
面试官:说说分布式锁,进程锁,线程锁的区别?
你知道的越多,不知道的就越多,业余的像一棵小草!
你来,我们一起精进!你不来,我和你的竞争对手一起精进!
编辑:业余草
cnblogs.com/intsmaze/p/6384105.html
推荐:https://www.xttblog.com/?p=5165
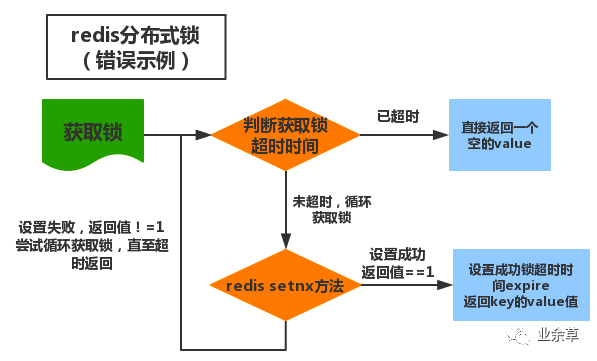
线程锁,进程锁,分布式锁
分布式锁是什么,怎么实现
❝具体实现方案参考:手把手教你 SpringBoot 分布式锁的实现
❞
分布式锁的痛点
分布式锁与业务的平衡
分布式锁用于hbase存储系统
数据库访的负载压力
分布式锁的实现选择
评论