
盘点开发中那些常用的MySQL优化
点击上方“码农突围”,马上关注
这里是码农充电第一站,回复“666”,获取一份专属大礼包
真爱,请设置“星标”或点个“在看

作者:jian
www.cnblogs.com/jian0110/p/9410981.html
1、大批量插入数据优化
(1)对于MyISAM存储引擎的表,可以使用:DISABLE KEYS 和 ENABLE KEYS 用来打开或者关闭 MyISAM 表非唯一索引的更新。
ALTER TABLE tbl_name DISABLE KEYS;
loading the data
ALTER TABLE tbl_name ENABLE KEYS;
(2)对于InnoDB引擎,有以下几种优化措施:
① 导入的数据按照主键的顺序保存:这是因为InnoDB引擎表示按照主键顺序保存的,如果能将插入的数据提前按照排序好自然能省去很多时间。
比如bulk_insert.txt文件是以表user主键的顺序存储的,导入的时间为15.23秒
mysql> load data infile 'mysql/bulk_insert.txt' into table user;
Query OK, 126732 rows affected (15.23 sec)
Records: 126732 Deleted: 0 Skipped: 0 Warnings: 0
没有按照主键排序的话,时间为:26.54秒
mysql> load data infile 'mysql/bulk_insert.txt' into table user;
Query OK, 126732 rows affected (26.54 sec)
Records: 126732 Deleted: 0 Skipped: 0 Warnings: 0
② 导入数据前执行SET UNIQUE_CHECKS=0,关闭唯一性校验,带导入之后再打开设置为1:校验会消耗时间,在数据量大的情况下需要考虑。
③ 导入前设置SET AUTOCOMMIT=0,关闭自动提交,导入后结束再设置为1:这是因为自动提交会消耗部分时间与资源,虽然消耗不是很大,但是在数据量大的情况下还是得考虑。
2、INSERT的优化
(1)尽量使用多个值表的 INSERT 语句,这种方式将大大缩减客户端与数据库之间的连接、关闭等消耗。(同一客户的情况下),即:
INSERT INTO tablename values(1,2),(1,3),(1,4)
实验:插入8条数据到user表中(使用navicat客户端工具)
insert into user values(1,'test',replace(uuid(),'-',''));
insert into user values(2,'test',replace(uuid(),'-',''));
insert into user values(3,'test',replace(uuid(),'-',''));
insert into user values(4,'test',replace(uuid(),'-',''));
insert into user values(5,'test',replace(uuid(),'-',''));
insert into user values(6,'test',replace(uuid(),'-',''));
insert into user values(7,'test',replace(uuid(),'-',''));
insert into user values(8,'test',replace(uuid(),'-',''));
得到反馈:
[SQL] insert into user values(1,'test',replace(uuid(),'-',''));
受影响的行: 1
时间: 0.033s
[SQL]
insert into user values(2,'test',replace(uuid(),'-',''));
受影响的行: 1
时间: 0.034s
[SQL]
insert into user values(3,'test',replace(uuid(),'-',''));
受影响的行: 1
时间: 0.056s
[SQL]
insert into user values(4,'test',replace(uuid(),'-',''));
受影响的行: 1
时间: 0.008s
[SQL]
insert into user values(5,'test',replace(uuid(),'-',''));
受影响的行: 1
时间: 0.008s
[SQL]
insert into user values(6,'test',replace(uuid(),'-',''));
受影响的行: 1
时间: 0.024s
[SQL]
insert into user values(7,'test',replace(uuid(),'-',''));
受影响的行: 1
时间: 0.004s
[SQL]
insert into user values(8,'test',replace(uuid(),'-',''));
受影响的行: 1
时间: 0.004s
总共的时间为0.171秒,接下来使用多值表形式:
insert into user values
(9,'test',replace(uuid(),'-','')),
(10,'test',replace(uuid(),'-','')),
(11,'test',replace(uuid(),'-','')),
(12,'test',replace(uuid(),'-','')),
(13,'test',replace(uuid(),'-','')),
(14,'test',replace(uuid(),'-','')),
(15,'test',replace(uuid(),'-','')),
(16,'test',replace(uuid(),'-',''));
得到反馈:
[SQL] insert into user values
(9,'test',replace(uuid(),'-','')),
(10,'test',replace(uuid(),'-','')),
(11,'test',replace(uuid(),'-','')),
(12,'test',replace(uuid(),'-','')),
(13,'test',replace(uuid(),'-','')),
(14,'test',replace(uuid(),'-','')),
(15,'test',replace(uuid(),'-','')),
(16,'test',replace(uuid(),'-',''));
受影响的行: 8
时间: 0.038s
得到时间为0.038,这样一来可以很明显节约时间优化SQL
(2)如果在不同客户端插入很多行,可使用INSERT DELAYED语句得到更高的速度,DELLAYED含义是让INSERT语句马上执行,其实数据都被放在内存的队列中。并没有真正写入磁盘。LOW_PRIORITY刚好相反。
(3)将索引文件和数据文件分在不同的磁盘上存放(InnoDB引擎是在同一个表空间的)。
(4)如果批量插入,则可以增加bluk_insert_buffer_size变量值提供速度(只对MyISAM有用)
(5)当从一个文本文件装载一个表时,使用LOAD DATA INFILE,通常比INSERT语句快20倍。
3、GROUP BY的优化
在默认情况下,MySQL中的GROUP BY语句会对其后出现的字段进行默认排序(非主键情况),就好比我们使用ORDER BY col1,col2,col3…所以我们在后面跟上具有相同列(与GROUP BY后出现的col1,col2,col3…相同)ORDER BY子句并没有影响该SQL的实际执行性能。
那么就会有这样的情况出现,我们对查询到的结果是否已经排序不在乎时,可以使用ORDER BY NULL禁止排序达到优化目的。下面使用EXPLAIN命令分析SQL。Java知音公众号内回复“面试题聚合”,送你一份面试题宝典
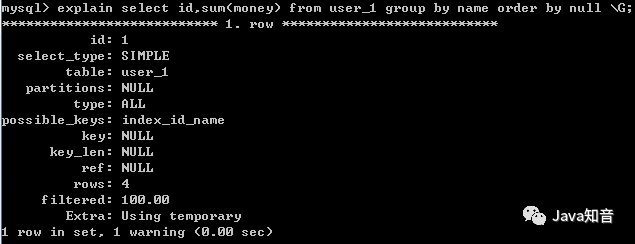
在user_1中执行select id, sum(money) form user_1 group by name时,会默认排序(注意group by后的column是非index才会体现group by的排序,如果是primary key,那之前说过了InnoDB默认是按照主键index排好序的)
mysql> select*from user_1;
+----+----------+-------+
| id | name | money |
+----+----------+-------+
| 1 | Zhangsan | 32 |
| 2 | Lisi | 65 |
| 3 | Wangwu | 44 |
| 4 | Lijian | 100 |
+----+----------+-------+
4 rows in set
不禁止排序,即不使用ORDER BY NULL时:有明显的Using filesort。

当使用ORDER BY NULL禁止排序后,Using filesort不存在
4、ORDER BY 的优化
MySQL可以使用一个索引来满足ORDER BY 子句的排序,而不需要额外的排序,但是需要满足以下几个条件:
(1)WHERE 条件和OREDR BY 使用相同的索引:即key_part1与key_part2是复合索引,where中使用复合索引中的key_part1
SELECT*FROM user WHERE key_part1=1 ORDER BY key_part1 DESC, key_part2 DESC;
(2)而且ORDER BY顺序和索引顺序相同:
SELECT*FROM user ORDER BY key_part1, key_part2;
(3)并且要么都是升序要么都是降序:
SELECT*FROM user ORDER BY key_part1 DESC, key_part2 DESC;
但以下几种情况则不使用索引:
(1)ORDER BY中混合ASC和DESC:
SELECT*FROM user ORDER BY key_part1 DESC, key_part2 ASC;
(2)查询行的关键字与ORDER BY所使用的不相同,即WHERE 后的字段与ORDER BY 后的字段是不一样的
SELECT*FROM user WHERE key2 = ‘xxx’ ORDER BY key1;
(3)ORDER BY对不同的关键字使用,即ORDER BY后的关键字不相同
SELECT*FROM user ORDER BY key1, key2;
5、OR的优化
当MySQL使用OR查询时,如果要利用索引的话,必须每个条件列都使独立索引,而不是复合索引(多列索引),才能保证使用到查询的时候使用到索引。
比如我们新建一张用户信息表user_info
mysql> select*from user_info;
+---------+--------+----------+-----------+
| user_id | idcard | name | address |
+---------+--------+----------+-----------+
| 1 | 111111 | Zhangsan | Kunming |
| 2 | 222222 | Lisi | Beijing |
| 3 | 333333 | Wangwu | Shanghai |
| 4 | 444444 | Lijian | Guangzhou |
+---------+--------+----------+-----------+
4 rows in set
之后创建ind_name_id(user_id, name)复合索引、id_index(id_index)独立索引,idcard主键索引三个索引。
mysql> show index from user_info;
+-----------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-----------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| user_info | 0 | PRIMARY | 1 | idcard | A | 4 | NULL | NULL | | BTREE | | |
| user_info | 1 | ind_name_id | 1 | user_id | A | 4 | NULL | NULL | | BTREE | | |
| user_info | 1 | ind_name_id | 2 | name | A | 4 | NULL | NULL | YES | BTREE | | |
| user_info | 1 | id_index | 1 | user_id | A | 4 | NULL | NULL | | BTREE | | |
+-----------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
4 rows in set
测试一:OR连接两个有单独索引的字段,整个SQL查询才会用到索引(index_merge),并且我们知道OR实际上是把每个结果最后UNION一起的。
mysql> explain select*from user_info where user_id=1 or idcard='222222';
+----+-------------+-----------+------------+-------------+------------------------------+---------------------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------------+------------------------------+---------------------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | user_info | NULL | index_merge | PRIMARY,ind_name_id,id_index | ind_name_id,PRIMARY | 4,62 | NULL | 2 | 100 | Using sort_union(ind_name_id,PRIMARY); Using where |
+----+-------------+-----------+------------+-------------+------------------------------+---------------------+---------+------+------+----------+----------------------------------------------------+
1 row in set
测试二:OR使用复合索引的字段name,与没有索引的address,整个SQL都是ALL全表扫描的
mysql> explain select*from user_info where name='Zhangsan' or address='Beijing';
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | user_info | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 43.75 | Using where |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set
交换OR位置并且使用另外的复合索引的列,也是ALL全表扫描:
mysql> explain select*from user_info where address='Beijing' or user_id=1;
+----+-------------+-----------+------------+------+----------------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+----------------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | user_info | NULL | ALL | ind_name_id,id_index | NULL | NULL | NULL | 4 | 43.75 | Using where |
+----+-------------+-----------+------------+------+----------------------+------+---------+------+------+----------+-------------+
1 row in set
6、优化嵌套查询
使用嵌套查询有时候可以使用更有效的JOIN连接代替,这是因为MySQL中不需要在内存中创建临时表完成SELECT子查询与主查询两部分查询工作。但是并不是所有的时候都成立,最好是在on关键字后面的列有索引的话,效果会更好!
比如在表major中major_id是有索引的:
select * from student u left join major m on u.major_id=m.major_id where m.major_id is null;
而通过嵌套查询时,在内存中创建临时表完成SELECT子查询与主查询两部分查询工作,会有一定的消耗
select * from student u where major_id not in (select major_id from major);
7、使用SQL提示
SQL提示(SQL HINT)是优化数据库的一个重要手段,就是往SQL语句中加入一些人为的提示来达到优化目的。下面是一些常用的SQL提示:
(1)USE INDEX:使用USE INDEX是希望MySQL去参考索引列表,就可以让MySQL不需要考虑其他可用索引,其实也就是possible_keys属性下参考的索引值
mysql> explain select* from user_info use index(id_index,ind_name_id) where user_id>0;
+----+-------------+-----------+------------+------+----------------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+----------------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | user_info | NULL | ALL | ind_name_id,id_index | NULL | NULL | NULL | 4 | 100 | Using where |
+----+-------------+-----------+------------+------+----------------------+------+---------+------+------+----------+-------------+
1 row in set
mysql> explain select* from user_info use index(id_index) where user_id>0;
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | user_info | NULL | ALL | id_index | NULL | NULL | NULL | 4 | 100 | Using where |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set
(2)IGNORE INDEX忽略索引
我们使用user_id判断,用不到其他索引时,可以忽略索引。即与USE INDEX相反,从possible_keys中减去不需要的索引,但是实际环境中很少使用。
mysql> explain select* from user_info ignore index(primary,ind_name_id,id_index) where user_id>0;
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | user_info | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 33.33 | Using where |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set
(3)FORCE INDEX强制索引
比如where user_id > 0,但是user_id在表中都是大于0的,自然就会进行ALL全表搜索,但是使用FORCE INDEX虽然执行效率不是最高(where user_id > 0条件决定的)但MySQL还是使用索引。
mysql> explain select* from user_info where user_id>0;
+----+-------------+-----------+------------+------+----------------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+----------------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | user_info | NULL | ALL | ind_name_id,id_index | NULL | NULL | NULL | 4 | 100 | Using where |
+----+-------------+-----------+------------+------+----------------------+------+---------+------+------+----------+-------------+
1 row in set
之后强制使用独立索引id_index(user_id):
mysql> explain select* from user_info force index(id_index) where user_id>0;
+----+-------------+-----------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | user_info | NULL | range | id_index | id_index | 4 | NULL | 4 | 100 | Using index condition |
+----+-------------+-----------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
1 row in set
总结
(1)很多时候数据库的性能是由于不合适(是指效率不高,可能会导致锁表等)的SQL语句造成,本篇博文只是介绍简单的SQL优化
(2)其中有些优化在真正开发中是用不到的,但是一旦出问题性能下降的时候需要去一一分析。
- END - 最近热文
• 12 岁男孩,一个暑假卖「表情包」,赚了 250 万 • 技术公司与非技术公司的区别,太真实了… • 深圳一公司在开源社区表示“要源码上门自取”,引来百万粉大V突袭公司,结果让人意外! • 李国庆:建议被降级降薪员工主动辞职,网友炸了 • 985高校的学生“夫妻宿舍”令人羡慕,网友:已婚学子的读博福利