
8k Star!基于 Matplotlib 的数据可视化利器
【导语】:Seaborn 是一个可以实现数据可视化的 Python 库,它是基于 matplotlib 库封装而成的,同时还能兼容 pandas 数据结构。我们可以使用 Seaborn 来制作漂亮的数据图表,操作简单,易于上手。
提示:Seaborn 支持 Python 3.7+ ,已不再支持 Python 2。
简介
1、数据可视化的工具介绍
数据可视化是一种数据科学家将原始数据转化为图表的技术,这些图表能产生许多有价值的信息。图表降低了原始数据的复杂性,使用户更易理解。
有许多完成数据可视化的工具,例如 Tableau、Power BI、ChartBlocks以及其他的无代码工具。这些工具有着各自的用户,也都很强大。然而当我们需要一个良好的平台来处理原始数据时,python 不失为一个好的选择。
虽然这种方法较为复杂,需要的编程知识也更多,但 python 能通过许多操作和转换来完成数据可视化,因此对数据科学家来说是一个理想的选择。Python 最大的一个优点就是它拥有强大的第三方库,来处理数据,比如numpy、pandas、matplotlib、tensorflow。
Matplotlib可能是目前最受认可的绘图库了,不仅适用于python,还适用于R语言等。它的定制化和可操作性使其坐上了头把交椅。然而当使用 matplotlib 时,有些定制化和操作功能很难实现。
基于 matplotlib,开发者创造了一个叫 seaborn 的库。seaborn 与 matplotlib 一样强大,在带来一些新特性的同时还能简化绘图。
在本文中,我们主要关注如何使用 seaborn 绘制高级的图表。你可以依据这些例子创建自己的图表。
2. Seaborn是什么?

Seaborn是 python 中一个可以制作数据图表的库。它是 matplotlib 库的高级封装,同时还能兼容 pandas 数据结构。
Seaborn 能让你快速探索并理解数据。seaborn 的工作方式为:首先捕捉包含所有数据的整个数据结构或数组,随后通过执行绘图和统计数据需要的所有内部函数,将数据转换为信息图。
当你根据自身需求设计图表时,seaborn 能减少复杂性。
Seaborn 的Github主页:
https://github.com/mwaskom/seaborn
安装
pip install seaborn
当安装seaborn时,也会自动安装其他绘图所需要的库,例如 matplotlib,pandas、numpy 和 scipy。此外,在写代码绘图前,我们需要导入一些模块。
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import seaborn as sns
简单使用
1. 绘制你的第一个图表
由于网络问题,在国内使用seaborn的数据集时,注意启用代理,以免无法加载数据集。
在我们开始画图之前,需要使用数据。seaborn的方便之处在于它兼容pandas数据结构。此外,该库自带了
一些内建数据集,你可以直接用代码加载,无需手动下载文件。让我们一起来看看如何加载一个包含航班信息的数据集:
flights_data = sns.load_dataset("flights")
res = flights_data.head()
print(res)
输出结果如下:
| year | month | passengers | |
|---|---|---|---|
| 0 | 1949 | Jan | 112 |
| 1 | 1949 | Feb | 118 |
| 2 | 1949 | Mar | 132 |
| 3 | 1949 | Apr | 129 |
| 4 | 1949 | May | 121 |
当调用load_dataset函数并写入数据集的名称后,神奇的事情发生了,控制台返回了一个数据结构。所有的数据集在这里可见:
Github链接:
https://github.com/mwaskom/seaborn-data
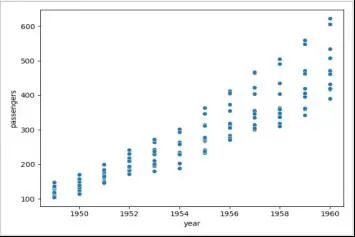
2. 散点图
散点图是一个基于二维数据来显示点的图表。用 seaborn 库来绘制一个散点图只需要几行代码,非常简单。scatterplot 需要的参数是我们绘图需要的数据集,以及x,y轴分别代表什么数据。
flights_data = sns.load_dataset("flights")
sns.scatterplot(data=flights_data, x="year", y="passengers")
plt.show()
绘制的图表如下:
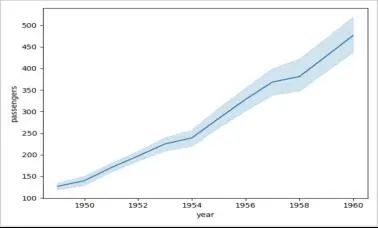
3. 线条图
根据连续或分类数据的变化,画出线条图。它是一种流行且广为人知的图表,易于绘制。与之前相似,我们使用lineplot函数,
指定数据集,以及x,y轴分别代表哪一列数据。seaborn会完成剩余的工作:
flights_data = sns.load_dataset("flights")
sns.lineplot(data=flights_data, x="year", y="passengers")
plt.show()
绘制的图表如下:
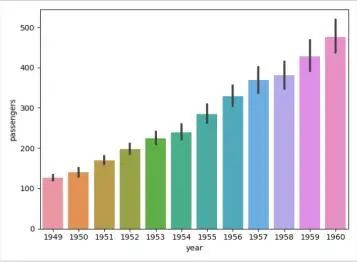
4. 条形图
正如你所推测的那样,条形图可能是最出名的图表类型了。与散点图和线条一样,我们可以用barplot函数绘制条形图:
flights_data = sns.load_dataset("flights")
sns.barplot(data=flights_data, x="year", y="passengers")
plt.show()
绘制的图表如下:
5. 用matplotlib扩展
seaborn建立在matplotlib之上,扩展了它的功能,增加了复杂性。如其所述,却并没有限matplotlib的性能。任何seaborn图表都可以用matplotlib的函数绘制。seaborn在特定的操作中可以提供帮助,允许seaborn利用matplotlib的力量而无需重写函数。例如你如果想用seaborn来自动绘制多个图表,你就可以利用matplotlib中的subplot函数:
diamonds_data = sns.load_dataset('diamonds')
plt.subplot(1, 2, 1)
sns.countplot(x='carat', data=diamonds_data)
plt.subplot(1, 2, 2)
sns.countplot(x='depth', data=diamonds_data)
plt.show()
绘制的图表如下:
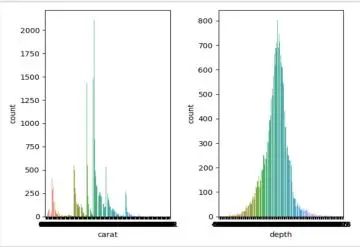
使用subplot功能,我们可以在一个图上绘制多个图表。该函数有三个参数,第一个是行数,第二个是列数,最后一个是图号。我们使用matplotlib与seaborn中的函数,seaborn在每个subplot中绘制一个seaborn图表。
6. 绘制不同风格的漂亮图形
seaborn使我们可以更改图形界面,它提供了五种不同的风格:darkgrid,whitegrid,dark,white,和ticks.
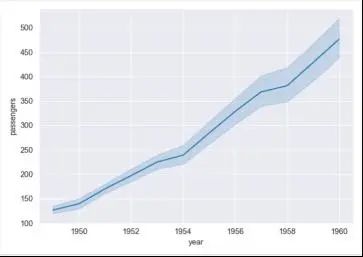
第一个例子深色网格图:
flights_data = sns.load_dataset("flights")
sns.set_style("darkgrid")
sns.lineplot(data = flights_data, x = "year", y = "passengers")
plt.show()
绘制的图表如下:
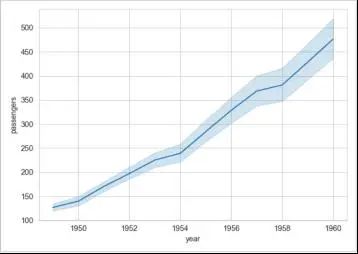
另一个例子白色网格图:
flights_data = sns.load_dataset("flights")
sns.set_style("whitegrid")
sns.lineplot(data=flights_data, x="year", y="passengers")
plt.show()
绘制的图表如下:
很酷的用法
. 下载小费数据集
我们了解seaborn的基本知识后,现在让我们通过在同一数据集上构建多个图表,来进行练习。在我们的例子中,我们将
使用数据集“tips”,你可以使用seaborn直接下载。首先,加载数据集:
tips_df = sns.load_dataset('tips')
res = tips_df.head()
print(res)
输出结果如下:
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Male | No | Sun | Dinner | 4 |
我想打印出数据集的前几行,来了解列和数据本身。通常我会用一些pandas函数修复一些数据问题,比如null值,还可
以加入一些对数据集有用的信息。你可以在下面的链接中阅读更多信息:
pandas使用指南:
https://livecodestream.dev/post/how-to-work-with-pandas-in-python/
让我们在数据集中创建新的一列,以表示小费占总费用的百分比:
tips_df = sns.load_dataset('tips')
tips_df.head()
tips_df["tip_percentage"] = tips_df["tip"] / tips_df["total_bill"]
res = tips_df.head()
print(res)
新的数据结构如下:
| total_bill | tip | sex | smoker | day | time | size | tip_percentage | |
|---|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 | 0.059447 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 | 0.160542 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 | 0.166587 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 | 0.139780 |
| 4 | 24.59 | 3.61 | Male | No | Sun | Dinner | 4 | 0.146808 |
2. 理解tip_percentage
让我们首先看看 tip_percentage 的分布。鉴于此,使用 hisplot 来产生柱状图:
tips_df = sns.load_dataset('tips')
tips_df["tip_percentage"] = tips_df["tip"] / tips_df["total_bill"]
sns.histplot(tips_df["tip_percentage"], binwidth=0.05)
plt.show()
绘制的图表如下:
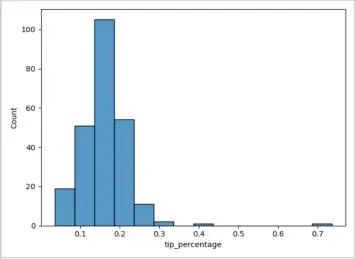
我们必须自定义 binwidth 属性以使其更具可读性,现在我们可以快速理解数据了。大多数客户会给15%至20%的小费,而有些情况下,小费超过70%。这些值是异常的,应该进行检查,以确定这些值是否出错。
3. 观察tip_percentage是否与每天的不同时刻是否有关,也将会很有趣:
tips_df = sns.load_dataset('tips')
tips_df["tip_percentage"] = tips_df["tip"] / tips_df["total_bill"]
sns.histplot(data=tips_df, x="tip_percentage", binwidth=0.05, hue="time")
plt.show()
绘制的图表如下:
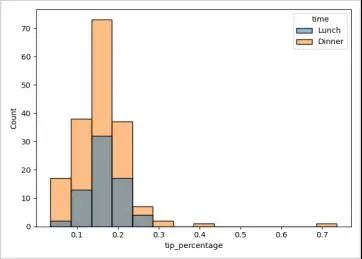
这次我们加载了所有数据集到图表中,而不仅仅是一列,然后给time列设置了hue属性。这将会使图表给每一个time值设置不同的颜色,并为其添加图例。
4. 一周中某天的小费数
另一个有趣的度量标准是根据一周中的某天,知道可以得到小费的总数:
tips_df = sns.load_dataset('tips')
tips_df["tip_percentage"] = tips_df["tip"] / tips_df["total_bill"]
sns.barplot(data=tips_df, x="day", y="tip", estimator=np.sum)
plt.show()
绘制的图表如下:
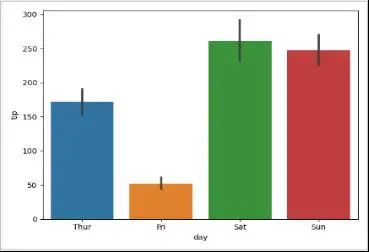
看起来星期五很适合待在家里。
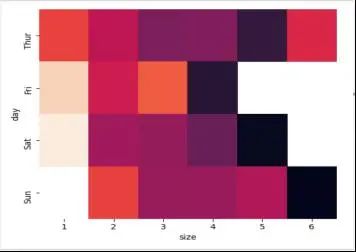
5. 桌子尺寸和日期对小费的影响
有时候我们想要知道多个变量如何共同影响输出。例如,星期几和桌子尺
寸怎样共同影响小费百分比?为了画出最终的图表,我们首先用pandas中的pivot函数预处理数据,随后绘制一个热点图:
tips_df = sns.load_dataset('tips')
tips_df["tip_percentage"] = tips_df["tip"] / tips_df["total_bill"]
pivot = tips_df.pivot_table(
index=["day"],
columns=["size"],
values="tip_percentage",
aggfunc=np.average)
sns.heatmap(pivot)
plt.show()
绘制的图表如下:
结论
当然,我们还可以用 seaborn 做很多事情,通过查看官方文档能看到更多例子。感谢你的阅读!
官方文档地址:http://seaborn.pydata.org/
- EOF -
更多优秀开源项目(点击下方图片可跳转)



开源前哨
日常分享热门、有趣和实用的开源项目。参与维护10万+star 的开源技术资源库,包括:Python, Java, C/C++, Go, JS, CSS, Node.js, PHP, .NET 等
关注后获取
回复 资源 获取 10万+ star 开源资源
分享、点赞和在看
支持我们分享更多优秀开源项目,谢谢!