
什么是链路追踪?分布式系统如何实现链路追踪?
公众号关注“杰哥的IT之旅”, 选择“星标”,重磅干货,第一时间送达!

在分布式系统,尤其是微服务系统中,一次外部请求往往需要内部多个模块,多个中间件,多台机器的相互调用才能完成。在这一系列的调用中,可能有些是串行的,而有些是并行的。在这种情况下,我们如何才能确定这整个请求调用了哪些应用?哪些模块?哪些节点?以及它们的先后顺序和各部分的性能如何呢?
这就是涉及到链路追踪。
什么是链路追踪?
链路追踪是分布式系统下的一个概念,它的目的就是要解决上面所提出的问题,也就是将一次分布式请求还原成调用链路,将一次分布式请求的调用情况集中展示,比如,各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。
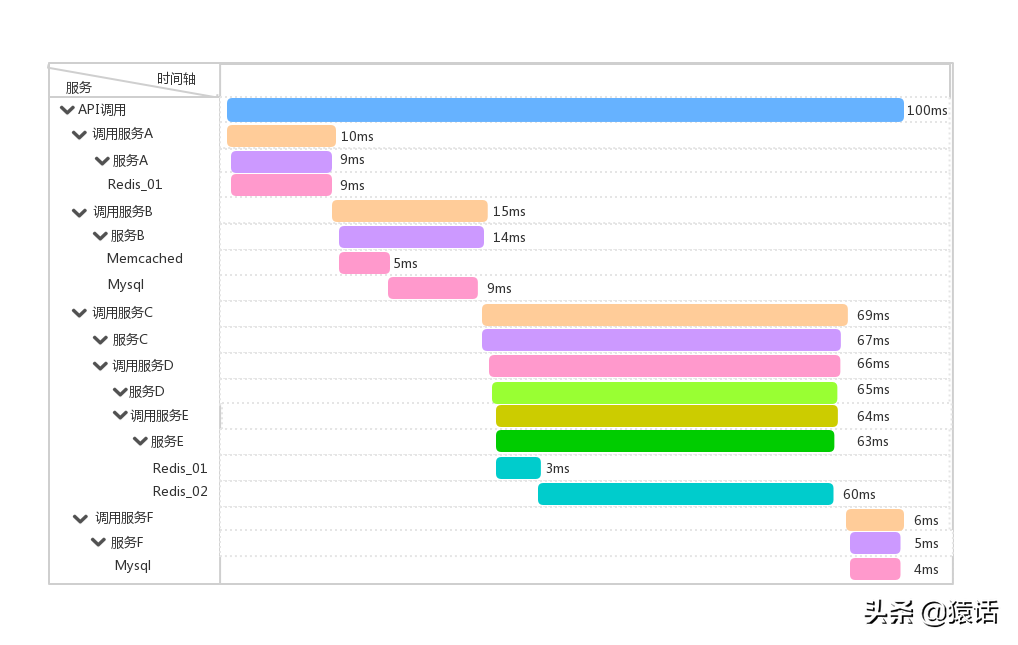
链路追踪的原理
衡量一个接口,我们一般会看三个指标:
1、接口的 RT(Route-Target)你怎么知道?
2、接口是否有异常响应?
3、接口请求慢在哪里?
1、单体架构时代
在创业初期,我们的系统一般是单体架构,如下:
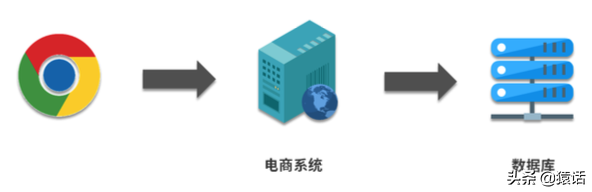
对于单体架构,我们可以使用 AOP(切面编程)来统计这三个指标,如下:
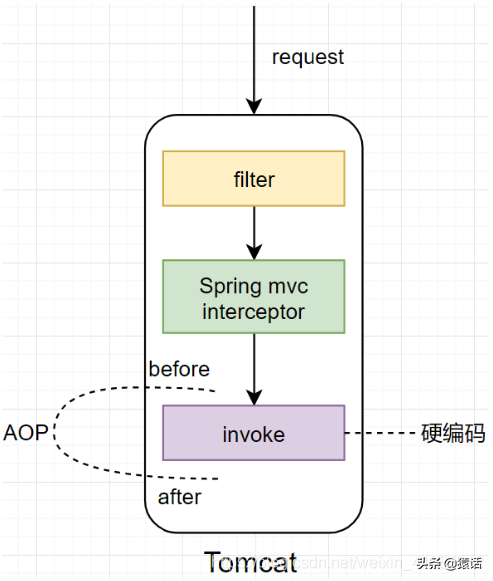
使用 AOP(切面编程),对原本的逻辑代码侵入更少,我们只需要在调用具体的业务逻辑前后分别打印一下时间即可计算出整体的调用时间。另外,使用 AOP(切面编程)来捕获异常也可知道是哪里的调用导致的异常。
2、微服务架构
随着业务的快速发展,单体架构越来越不能满足需要,我们的系统慢慢会朝微服务架构发展,如下:
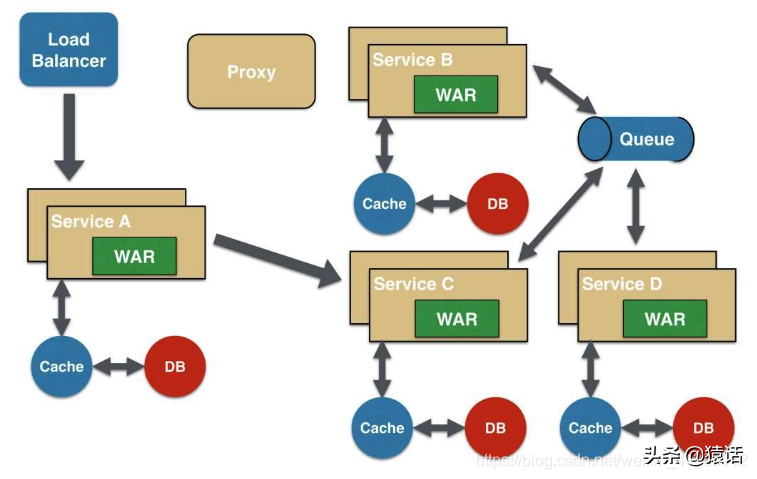
在微服务架构下,当有用户反馈某个页面很慢时,虽然我们知道这个请求可能的调用链是 A -----> C -----> B -----> D,但服务这么多,而且每个服务都有好几台机器,怎么知道问题具体出在哪个服务?哪台机器呢?
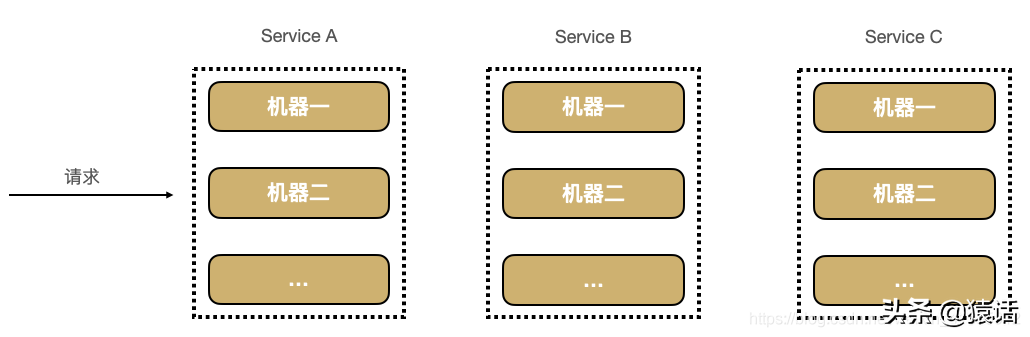
这也是微服务这种架构下的几个痛点:
1、排查问题难度大,周期长
2、特定场景难复现
3、系统性能瓶颈分析较难
分布式调用链就是为了解决以上几个问题而生,它主要的作用如下:
1、自动采取数据
2、分析数据,产生完整调用链:有了请求的完整调用链,问题有很大概率可复现
3、数据可视化:每个组件的性能可视化,能帮助我们很好地定位系统的瓶颈,及时找出问题所在
通过分布式追踪系统,我们能很好地定位请求的每条具体请求链路,从而轻易地实现请求链路追踪,进而定位和分析每个模块的性能瓶颈。
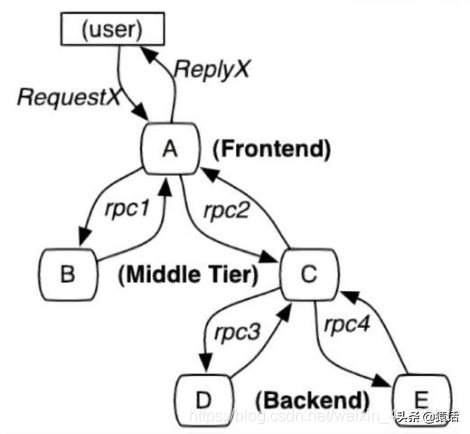
3、分布式调用链标准(OpenTracing)
OpenTracing 是一个轻量级的标准化层,它位于应用程序/类库和追踪或日志分析程序之间。它的出现是为了解决不同的分布式追踪系统 API 不兼容的问题。

OpenTracing 通过提供与平台和厂商无关的 API,使得开发人员能够方便地添加追踪系统,就像单体架构下的AOP(切面编程)一样。
说到这里,大家是否想过 Java 中类似的实现?还记得 JDBC 吧?JDBC 就是通过提供一套标准的接口让各个厂商去实现,程序员即可面对接口编程,不用关心具体的实现。这里的接口其实就是标准。所以,制定一套标准非常重要,可以实现组件的可插拔。

OpenTracing 的数据模型,主要有以下三个:
Trace:一个完整请求链路
Span:一次调用过程(需要有开始时间和结束时间)
SpanContext:Trace 的全局上下文信息,如里面有traceId
为了让大家更好地理解这三个概念,我特意画了一张图:

如图所示,一次下单的完整请求就是一个 Trace。TraceId是这个请求的全局标识。内部的每一次调用就称为一个 Span,每个 Span 都要带上全局的 TraceId,这样才可把全局 TraceId 与每个调用关联起来。这个 TraceId 是通过 SpanContext 传输的,既然要传输,显然都要遵循协议来调用。如图所示,如果我们把传输协议比作车,把 SpanContext 比作货,把 Span 比作路应该会更好理解一些。
理解了这三个概念,接下来我们就看看分布式追踪系统是如何采集图中的微服务调用链。

我们可以看到底层有一个 Collector 一直在默默无闻地收集数据,那么每一次调用 Collector 会收集哪些信息呢。
1、全局 trace_id:这是显然的,这样才能把每一个子调用与最初的请求关联起来
2、span_id: 图中的 0,1,1.1,2,这样就能标识是哪一个调用
3、parent_span_id:比如 b 调用 d 的 span_id 是 1.1,那么它的 parent_span_id 即为 a 调用 b 的 span_id 即 1,这样才能把两个紧邻的调用关联起来。
有了这些信息,Collector 收集的每次调用的信息如下:

根据这些图表信息显然可以据此来画出调用链的可视化视图如下:
于是一个完整的分布式追踪系统就实现了。
以上实现看起来确实简单,但有以下几个问题需要我们仔细思考一下:
1、怎么自动采集 span 数据:自动采集,对业务代码无侵入
2、如何跨进程传递 context
3、traceId 如何保证全局唯一
4、请求量这么多采集会不会影响性能
接下来,我们来看看链路追踪系统 SkyWalking 是如何解决以上四个问题的。
链路追踪系统SkyWalking的原理
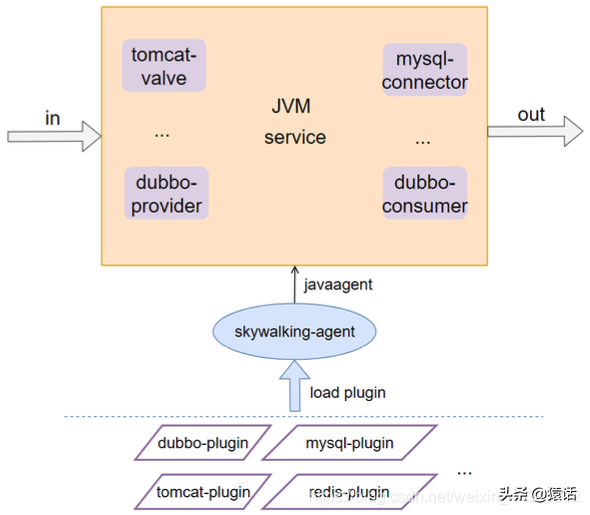
1、怎么自动采集 span 数据
SkyWalking 采用了插件化 + javaagent 的形式来实现了 span 数据的自动采集,这样可以做到对代码的无侵入性。插件化意味着可插拔,扩展性好。如下图所示:
2、如何跨进程传递 context
我们知道数据一般分为 header 和 body,就像 http 有 header 和 body,RocketMQ 也有 MessageHeader,Message Body。body 一般放着业务数据,所以不宜在 body 中传递 context,应该在 header 中传递 context,如图所示:
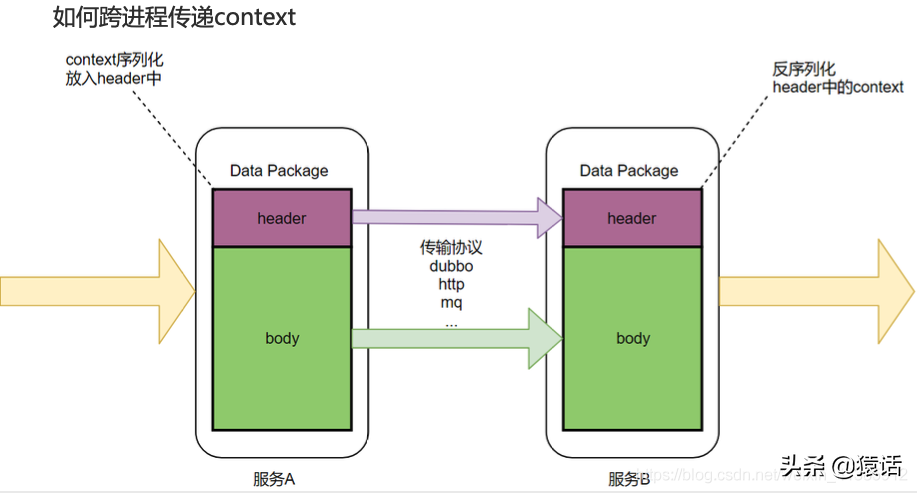
dubbo 中的 attachment 就相当于 header,所以我们把 context 放在 attachment 中,这样就解决了 context 的传递问题。

3、traceId 如何保证全局唯一
要保证全局唯一 ,我们可以采用分布式或者本地生成的 ID。使用分布式的话,需要有一个发号器,每次请求都要先请求一下发号器,会有一次网络调用的开销。所以 SkyWalking 最终采用了本地生成 ID 的方式,它采用了大名鼎鼎的 snowflow 算法,性能很高。

不过 snowflake 算法有一个众所周知的问题:时间回拨,这个问题可能会导致生成的 id 重复。那么 SkyWalking 是如何解决时间回拨问题的呢。

每生成一个 id,都会记录一下生成 id 的时间(lastTimestamp),如果发现当前时间比上一次生成 id 的时间(lastTimestamp)还小,那说明发生了时间回拨,此时会生成一个随机数来作为 traceId。这里可能就有同学要较真了,可能会觉得生成的这个随机数也会和已生成的全局 id 重复,是否再加一层校验会好点。
这里要说一下系统设计上的方案取舍问题了,首先如果针对产生的这个随机数作唯一性校验无疑会多一层调用,会有一定的性能损耗,但其实时间回拨发生的概率很小(发生之后由于机器时间紊乱,业务会受到很大影响,所以机器时间的调整必然要慎之又慎),再加上生成的随机数重合的概率也很小,综合考虑这里确实没有必要再加一层全局唯一性校验。对于技术方案的选型,一定要避免过度设计,过犹不及。
4、请求量这么多,全部采集会不会影响性能?
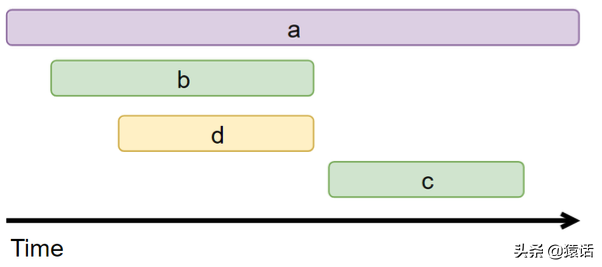
如果对每个请求调用都采集,那毫无疑问数据量会非常大,但反过来想一下,是否真的有必要对每个请求都采集呢?其实没有必要,我们可以设置采样频率,只采样部分数据,SkyWalking 默认设置了 3 秒采样 3 次,其余请求不采样,如图所示:
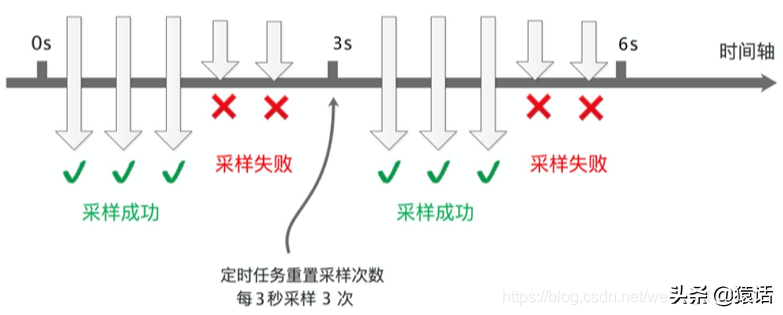
这样的采样频率其实足够我们分析组件的性能了,按 3 秒采样 3 次,这样的频率来采样数据会有啥问题呢。理想情况下,每个服务调用都在同一个时间点,这样的话每次都在同一时间点采样确实没问题。如下图所示:
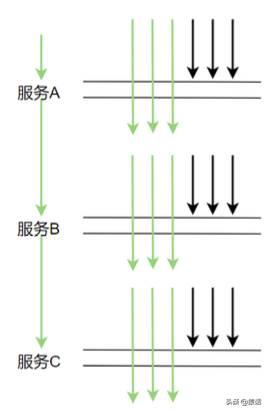
但在生产上,每次服务调用基本不可能都在同一时间点调用,因为期间有网络调用延时等,实际调用情况很可能是下图这样:
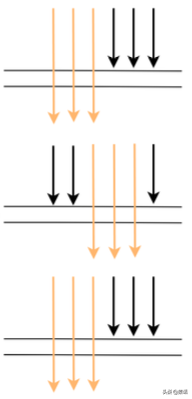
这样的话就会导致某些调用在服务 A 上被采样了,在服务 B,C 上不被采样,也就没法分析调用链的性能。
那么 SkyWalking 是如何解决的呢?
它是这样解决的:如果上游有携带 Context 过来(说明上游采样了),则下游将强制采集数据,这样可以保证链路完整。
SkyWalking 的基础架构
SkyWalking 的基础如下架构,可以说几乎所有的的分布式调用都是由以下几个组件组成的。
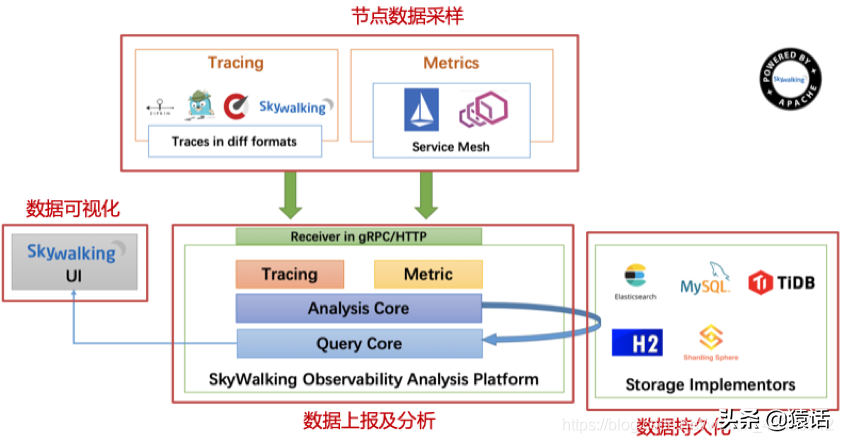
首先当然是节点数据的定时采样,采样后将数据定时上报,将其存储到 ES, MySQL 等持久化层,有了数据自然而然可根据数据做可视化分析。
SkyWalking 的性能如何
如下是官方的测评数据:
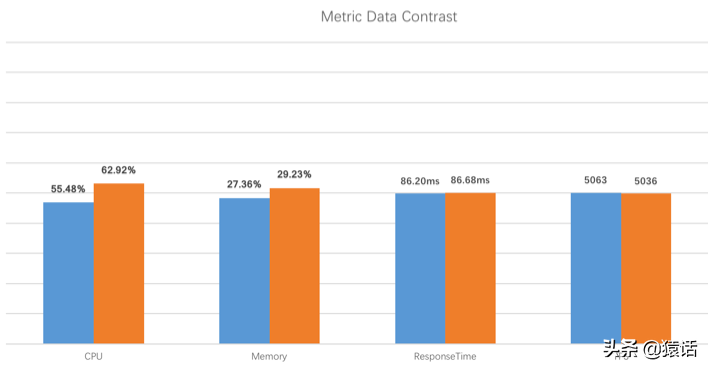
图中蓝色代表未使用 SkyWalking 的表现,橙色代表使用了 SkyWalking 的表现,以上是在 TPS 为 5000 的情况下测出的数据,可以看出,不论是 CPU,内存,还是响应时间,使用 SkyWalking 带来的性能损耗几乎可以忽略不计。
接下来我们再来看 SkyWalking 与另一款业界比较知名的分布式追踪工具 Zipkin、Pinpoint 的对比(在采样率为 1 秒 1 个,线程数 500,请求总数为 5000 的情况下做的对比)。
可以看到在关键的响应时间上, Zipkin(117ms),PinPoint(201ms)远逊于 SkyWalking(22ms)!从性能损耗这个指标上看,SkyWalking 完胜!
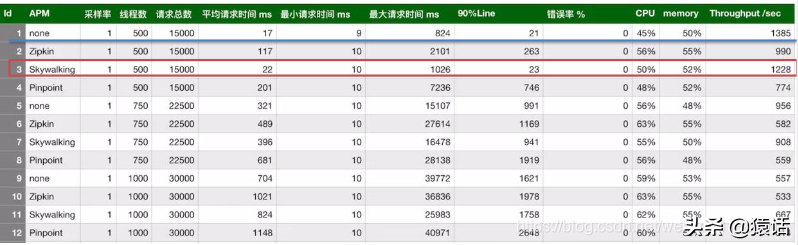
再看下另一个指标:对代码的侵入性如何。
ZipKin 是需要在应用程序中埋点的,对代码的侵入强,而 SkyWalking 采用 javaagent + 插件化这种修改字节码的方式可以做到对代码无任何侵入。除了性能和对代码的侵入性上 SkyWaking 表现不错外,它还有以下优势几个优势:
对多语言的支持,组件丰富:目前其支持 Java、 .Net Core、PHP、NodeJS、Golang、LUA 语言,组件上也支持dubbo, mysql 等常见组件,大部分能满足我们的需求。
扩展性:对于不满足的插件,我们按照 SkyWalking 的规则手动写一个即可,新实现的插件对代码无入侵。
以上虽然主要以SkyWalking为例来介绍链路追踪系统,但是并不是说其他链路追踪系统一点不适用。具体选择什么样的,大家可按实际场景灵活选择。
作者:猿话
来源:https://www.toutiao.com/i6884571378981274123/
m」获取!推荐阅读: 1、成为架构师,必须掌握 10 种常见的架构模式!
2、程序员必知的 7 种软件架构模式
3、一文读懂「分布式架构」
4、Linux 经典的几款收包引擎
5、最全 VxLAN 知识详解
6、什么是堡垒机?为什么需要堡垒机? 关注微信公众号「杰哥的IT之旅」,后台回复「1024」查看更多内容,回复「加群」备注:地区-职业方向-昵称 即可加入读者交流群。
2、程序员必知的 7 种软件架构模式
3、一文读懂「分布式架构」
4、Linux 经典的几款收包引擎
5、最全 VxLAN 知识详解
6、什么是堡垒机?为什么需要堡垒机?
点个[在看],是对杰哥最大的支持!
