
一文理解Kafka如何保证消息顺序性
要想实现消息有序,需要从Producer和Consumer两方面来考虑。
如果对Kafka不了解的话,可以先看这篇博客《一文快速了解Kafka》。
针对消息有序的业务需求,还分为全局有序和局部有序。
全局有序:一个Topic下的所有消息都需要按照生产顺序消费。
局部有序:一个Topic下的消息,只需要满足同一业务字段的要按照生产顺序消费。例如:Topic消息是订单的流水表,包含订单orderId,业务要求同一个orderId的消息需要按照生产顺序进行消费。
全局有序
由于Kafka的一个Topic可以分为了多个Partition,Producer发送消息的时候,是分散在不同 Partition的。当Producer按顺序发消息给Broker,但进入Kafka之后,这些消息就不一定进到哪个Partition,会导致顺序是乱的。
因此要满足全局有序,需要1个Topic只能对应1个Partition。
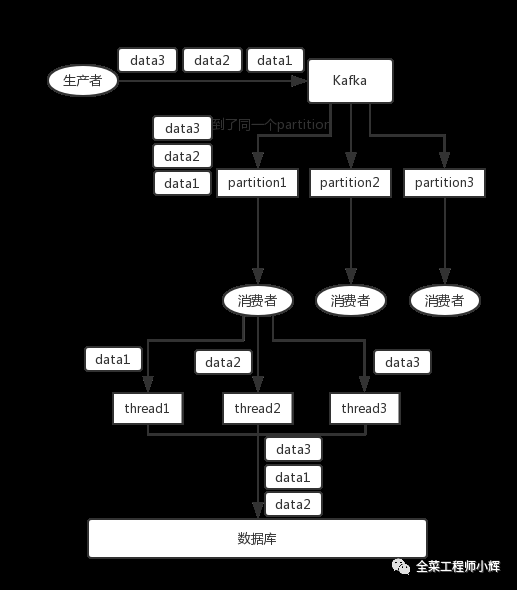
而且对应的consumer也要使用单线程或者保证消费顺序的线程模型,否则会出现下图所示,消费端造成的消费乱序。
局部有序
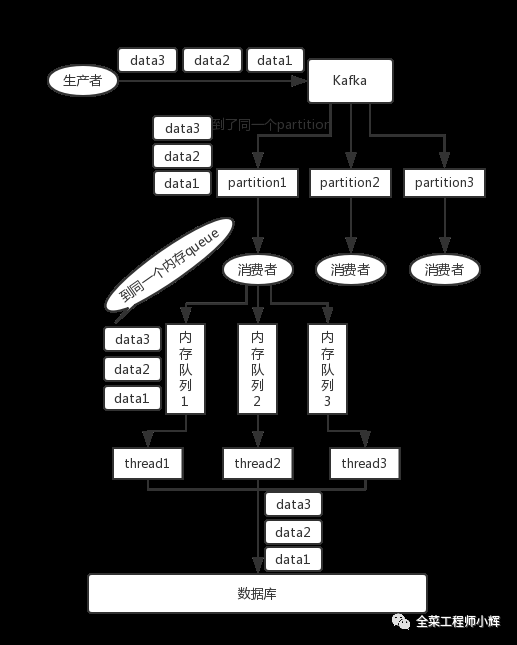
要满足局部有序,只需要在发消息的时候指定Partition Key,Kafka对其进行Hash计算,根据计算结果决定放入哪个Partition。这样Partition Key相同的消息会放在同一个Partition。此时,Partition的数量仍然可以设置多个,提升Topic的整体吞吐量。
如下图所示,在不增加partition数量的情况下想提高消费速度,可以考虑再次hash唯一标识(例如订单orderId)到不同的线程上,多个消费者线程并发处理消息(依旧可以保证局部有序)。
消息重试对顺序消息的影响
对于一个有着先后顺序的消息A、B,正常情况下应该是A先发送完成后再发送B,但是在异常情况下,在A发送失败的情况下,B发送成功,而A由于重试机制在B发送完成之后重试发送成功了。这时对于本身顺序为AB的消息顺序变成了BA。
针对这种问题,严格的顺序消费还需要max.in.flight.requests.per.connection参数的支持。
该参数指定了生产者在收到服务器响应之前可以发送多少个消息。它的值越高,就会占用越多的内存,同时也会提升吞吐量。把它设为1就可以保证消息是按照发送的顺序写入服务器的。
此外,对于某些业务场景,设置max.in.flight.requests.per.connection=1会严重降低吞吐量,如果放弃使用这种同步重试机制,则可以考虑在消费端增加失败标记的记录,然后用定时任务轮询去重试这些失败的消息并做好监控报警。